大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
JStorm 是一个类似Hadoop MapReduce的系统, 用户按照指定的接口实现一个任务,然后将这个任务递交给JStorm系统,JStorm将这个任务跑起来,并且按7 * 24小时运行起来,一旦中间一个Worker 发生意外故障, 调度器立即分配一个新的Worker替换这个失效的Worker。
因此,从应用的角度,JStorm应用是一种遵守某种编程规范的分布式应用。从系统角度, JStorm是一套类似MapReduce的调度系统。 从数据的角度,JStorm是一套基于流水线的消息处理机制。
实时计算现在是大数据领域中最火爆的一个方向,因为人们对数据的要求越来越高,实时性要求也越来越快,传统的Hadoop MapReduce,逐渐满足不了需求,因此在这个领域需求不断。
Storm组件和Hadoop组件对比
| Storm | Hadoop | |
|---|---|---|
| 角色 | Nimbus | JobTracker |
| Supervisor | TaskTracker | |
| Worker | Child | |
| 应用名称 | Topology | Job |
| 编程接口 | Spout/Bolt | Mapper/Reducer |
Spout
在逻辑上,一个Topology 是由一些Spout(消息的发送者)和Bolt(消息的处理者)组成图状结构
每个Spouts 都可以发射多个消息流,要实现这样的效果,可以使用OutFieldsDeclarer.declareStream 来定义多个Stream,然后使用SpoutOutputCollector 来发射指定的Stream。
bolt
所有的拓扑处理都会在bolt中进行,bolt里面可以做任何etl,比如过滤,函数,聚合,连接,写入数据库系统或缓存等,一个bolt可以做简单的事件流转换,如果是复杂的流转化,往往需要多个bolt参与,这就是流计算,每个bolt都进行一个业务逻辑处理,bolt也可以emit多个流到下游,通过declareStream方法声明输出的schema。
Bolt里面主要的方法是execute方法,每次处理一个输入的tuple,bolt里面也可以发射新的tuple使用OutputCollector类,bolt里面每处理一个tuple必须调用ack方法以便于storm知道某个tuple何时处理完成。Strom里面的IBasicBolt接口可以自动
调用ack。
优点
在Storm和JStorm出现以前,市面上出现很多实时计算引擎,但自Storm和JStorm出现后,基本上可以说一统江湖: 究其优点:
- 开发非常迅速:接口简单,容易上手,只要遵守Topology、Spout和Bolt的编程规范即可开发出一个扩展性极好的应用,底层RPC、Worker之间冗余,数据分流之类的动作完全不用考虑
- 扩展性极好:当一级处理单元速度,直接配置一下并发数,即可线性扩展性能
- 健壮强:当Worker失效或机器出现故障时, 自动分配新的Worker替换失效Worker
- 数据准确性:可以采用Ack机制,保证数据不丢失。 如果对精度有更多一步要求,采用事务机制,保证数据准确。
应用场景
JStorm处理数据的方式是基于消息的流水线处理, 因此特别适合无状态计算,也就是计算单元的依赖的数据全部在接受的消息中可以找到, 并且最好一个数据流不依赖另外一个数据流。
因此,常常用于
- 日志分析,从日志中分析出特定的数据,并将分析的结果存入外部存储器如数据库。目前,主流日志分析技术就使用JStorm或Storm
- 管道系统, 将一个数据从一个系统传输到另外一个系统, 比如将数据库同步到Hadoop
- 消息转化器, 将接受到的消息按照某种格式进行转化,存储到另外一个系统如消息中间件
- 统计分析器, 从日志或消息中,提炼出某个字段,然后做count或sum计算,最后将统计值存入外部存储器。中间处理过程可能更复杂。
- 实时推荐系统, 将推荐算法运行在jstorm中,达到秒级的推荐效果
在实际应用中,一般会通过spout与其他系统集成,例如RocketMQ这样的消息队列。对于处理完成的数据,也可以选择输出到db或在bolt中直接导向其他系统做进一步处理
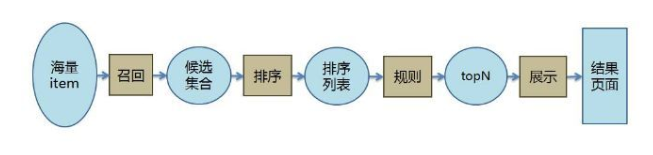

(召回环节,又叫匹配环节,是从海量商品库里得到的一个候选商品集合)
第一,对用户的行为日志进行利用 JStorm 实时收集,并定时更新基于 item 的协同过滤内容。
第二,对直播间内容进行利用 JStorm 实时收集,实时为直播间打上分类标签、topic、主题词等标签,并定时更新用户画像内容。
第三,对用户 query 日志利用 JStorm 实时收集,定时计算用户 query 的 CTR。
最后,当用户进行刷新时,利用召回策略进行召回,再根据排序策略选择 top N 呈现给用户。
推荐系统一般是实时数据统计,离线数据统计加权得到的结果
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/203682.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
