大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
一、 朴素贝叶斯
1、概率基础知识:
条件概率是指事件A在另外一个事件B已经发生条件下的发生概率。 条件概率表示为: P(A|B), 读作“在B条件下A的概率”。
若只有两个事件A, B, 那么:
P ( A B ) = P ( A ∣ B ) P ( B ) = P ( B ∣ A ) P ( A ) P(AB) = P(A|B)P(B)=P(B|A)P(A) P(AB)=P(A∣B)P(B)=P(B∣A)P(A)
P ( A ∣ B ) = P ( A B ) P ( B ) P(A|B) = \frac{P(AB)}{P(B)} P(A∣B)=P(B)P(AB)
那么:
P ( A ∣ B ) = P ( B ∣ A ) ∗ P ( A ) P ( B ) P(A|B) = \frac{P(B|A)*P(A)}{P(B)} P(A∣B)=P(B)P(B∣A)∗P(A)
全概率公式: 表示若事件A1,A2,…,An构成一个完备事件组且都有正概率,则对任意一个事件B都有公式成立。

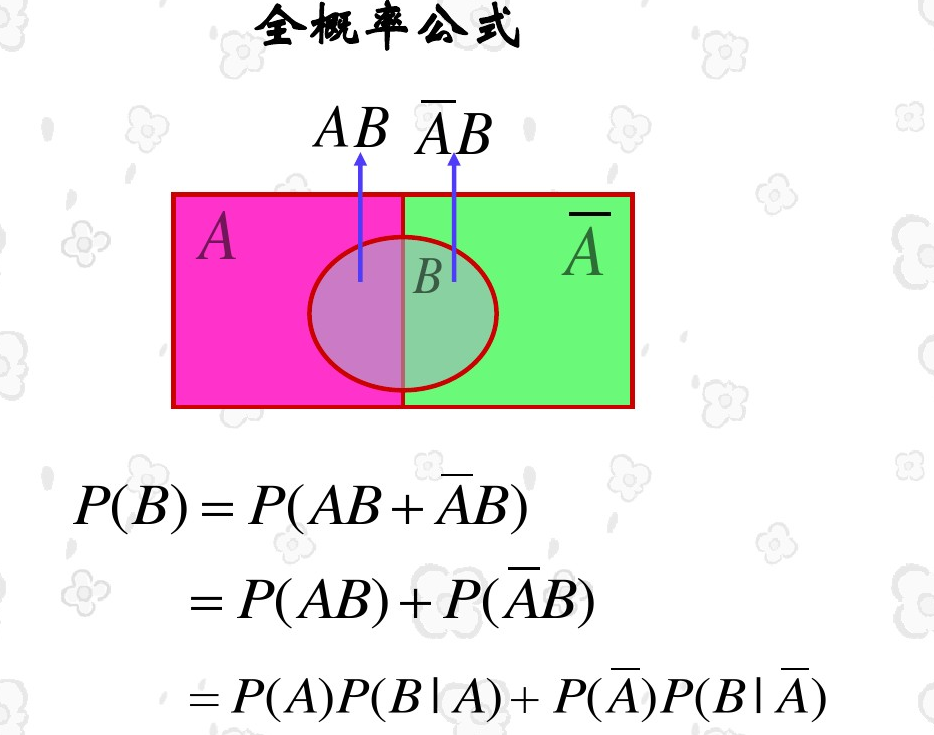
P ( B ) = P ( A 1 B ) + P ( A 2 B ) + . . . + P ( A n B ) = ∑ P ( A i B ) = ∑ P ( B ∣ A i ) ∗ P ( A i ) \begin{aligned} P(B) &= P(A_1B)+P(A_2B)+…+P(A_nB) \\ &=\sum{}P(A_iB) \\ &=\sum{}P(B|A_i)*P(A_i) \end{aligned} P(B)=P(A1B)+P(A2B)+...+P(AnB)=∑P(AiB)=∑P(B∣Ai)∗P(Ai)
贝叶斯公式是将全概率公式带入到条件概率公式当中, 对于事件Ak和事件B有:
P ( A k ∣ B ) = P ( B ∣ A k ) ∗ P ( A k ) ∑ P ( B ∣ A i ) ∗ P ( A i ) P(A_k|B)=\frac{P(B|A_k)*P(A_k)}{\sum{}P(B|A_i)*P(A_i)} P(Ak∣B)=∑P(B∣Ai)∗P(Ai)P(B∣Ak)∗P(Ak)
对于 P ( A k ∣ B ) P(A_k|B) P(Ak∣B)来说, 分母 ∑ P ( B ∣ A i ) ∗ P ( A i ) ∑P(B|A_i)*P(A_i) ∑P(B∣Ai)∗P(Ai) 为一个固定值, 因为我们只需要比较 P ( A k ∣ B ) P(A_k|B) P(Ak∣B)的大小,
所以可以将分母固定值去掉, 并不会影响结果。 因此, 可以得到下面公式:
P ( A k ∣ B ) = P ( A k ) ∗ P ( B ∣ A k ) P(A_k|B)=P(A_k)*P(B|A_k) P(Ak∣B)=P(Ak)∗P(B∣Ak)
$P(A_k) $先验概率, P ( A k ∣ B ) P(A_k|B) P(Ak∣B) 后验概率, P ( B ∣ A k ) P(B|A_k) P(B∣Ak) 似然函数
先验*似然=后验
特征条件独立假设在分类问题中,常常需要把一个事物分到某个类别中。 一个事物又有许多属性,即x=(x1,x2,···,xn)。常常类别也是多个, 即 y = ( y 1 , y 2 , ⋅ ⋅ ⋅ , y k ) 。 P ( y 1 ∣ x ) , P ( y 2 ∣ x ) , … , P ( y k ∣ x ) y=(y_1,y_2,···,y_k)。P(y_1|x),P(y_2|x),…,P(y_k|x) y=(y1,y2,⋅⋅⋅,yk)。P(y1∣x),P(y2∣x),…,P(yk∣x), 表示x属于某个分类的概率,那么,我们需要找出其中最大的那个概率P(yk|x), 根据上一步得到的公式可得:
P ( y k ∣ x ) = P ( y k ) ∗ P ( x ∣ y k ) P(y_k|x) = P(y_k)*P(x|y_k) P(yk∣x)=P(yk)∗P(x∣yk)
就样本x有n个属性: x = ( x 1 , x 2 , ⋅ ⋅ ⋅ , x n ) x=(x_1,x_2,···,x_n) x=(x1,x2,⋅⋅⋅,xn)
所以: P ( y k ∣ X ) = P ( y k ) ∗ P ( x 1 , x 2 , ⋅ ⋅ ⋅ , x n ∣ y k ) P(y_k|X) =P(y_k) * P(x_1,x_2,···,x_n|y_k) P(yk∣X)=P(yk)∗P(x1,x2,⋅⋅⋅,xn∣yk)
条件独立假设,就是各条件之间互不影响
所以样本的联合概率就是连乘: P ( x 1 , x 2 , ⋅ ⋅ ⋅ , x n ∣ y k ) = ∏ P ( x i ∣ y k ) P(x_1,x_2,···,x_n|y_k) = ∏P(x_i|y_k) P(x1,x2,⋅⋅⋅,xn∣yk)=∏P(xi∣yk)
最终公式为: P ( y k ∣ x ) = P ( y k ) ∗ ∏ P ( x i ∣ y k ) P(y_k|x) =P(y_k) * ∏P(x_i|y_k) P(yk∣x)=P(yk)∗∏P(xi∣yk)
根据公式 P ( y k ∣ x ) = P ( y k ) ∗ ∏ P ( x i ∣ y k ) P(y_k|x) =P(y_k) * ∏P(x_i|y_k) P(yk∣x)=P(yk)∗∏P(xi∣yk), 就可以做分类问题了
朴素贝叶斯公式:
P ( y k ∣ x ) = P ( y k ) ∗ ∏ P ( x i ∣ y k ) P(y_k|x) =P(y_k) * ∏P(x_i|y_k) P(yk∣x)=P(yk)∗∏P(xi∣yk)
【例2】一起汽车撞人逃跑事件,已知只有两种颜色的车,比例为蓝色15% 绿色85%,目击者指证是蓝车,但根据现场分析,当时那种条件目击者看正确车的颜色的可能性是
80%,那么,肇事的车是蓝车的概率到底是多少()
答案:
设A={目击者看到车是蓝色的}, B={车的实际颜色是蓝色}
P(A)=80%×15%+20%×85%=29%
即: 车是蓝色(15%)×目击者看正确(80%)+车是绿色(85%)×目击
者看错了(20%)
P(AB)=80%×15%=12%
即: 车是蓝色(15%)×目击者看正确(80%)
P(B|A)=P(AB)/P(A)=12%/29%≈41%
2、朴素贝叶斯模型流程:
**朴素贝叶斯的基本方法:**在统计数据的基础上,依据条件概率公式,计算当前特征的样本属于某个分类的概率,选最大的概率分类
对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别:
①计算流程:
(1) x = { a 1 , a 2 , . . . . , a m } x =\{a_1,a_2,….,a_m\} x={
a1,a2,....,am}为待分类项, 每个a为x的一个特征属性
(2)有类别集合$C= {y_1,y_2,…,y_n} $
(3)计算 P ( y 1 ∣ x ) , P ( y 2 ∣ x ) , . . . , P ( y n ∣ x ) P(y_1|x),P(y_2|x),…,P(y_n|x) P(y1∣x),P(y2∣x),...,P(yn∣x)
(4)如果 P ( y k ∣ x ) = m a x { P ( y 1 ∣ x ) , P ( y 2 ∣ x ) , . . . , P ( y n ∣ x ) } P(y_k|x) = max\{P(y_1|x),P(y_2|x),…,P(y_n|x)\} P(yk∣x)=max{
P(y1∣x),P(y2∣x),...,P(yn∣x)}
如何计算第3步中的各个条件概率?
课堂案例-2
1、 找到一个已知分类的待分类项集合,这个集合叫做训练样本集。
2、 统计得到在各类别下各个特征属性的条件概率估计。 即:
$P(a_1|y_1),P(a_2,y_2),…,P(a_m|y_1) $
3、 如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导:
P ( y i ∣ x ) = P ( x ∣ y i ) P ( y i ) P ( x ) P(y_i|x)=\frac{P(x|y_i)P(y_i)}{P(x)} P(yi∣x)=P(x)P(x∣yi)P(yi)
因为分母对于所有类别为常数, 因为我们只要将分子最大化皆可。 又因为各特征属性是条
件独立的, 所以有:
$P(y_k|x) =P(y_k) * ∏P(x_i|y_k) $
P ( x ∣ y i ) P ( y i ) = P ( a i ∣ y i ) P ( a 2 ∣ y i ) . . . P ( a m ∣ y i ) P ( y i ) = P ( y i ) ∏ j = 1 m P ( a j ∣ y i ) P(x|y_i)P(y_i)=P(a_i|y_i)P(a_2|y_i)…P(a_m|y_i)P(y_i)=P(y_i)\prod_{j=1}^mP(a_j|y_i) P(x∣yi)P(yi)=P(ai∣yi)P(a2∣yi)...P(am∣yi)P(yi)=P(yi)j=1∏mP(aj∣yi)
例题:


②三个阶段:
第一阶段——准备阶段, 根据具体情况确定特征属性, 对每个特征属性进行适当划分, 然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段, 其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段——分类器训练阶段, 这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计, 并将结果记录。 其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段, 根据前面讨论的公式可以由程序自动计算完成。
第三阶段——应用阶段。 这个阶段的任务是使用分类器对待分类项进行分类, 其输入是分类器
和待分类项, 输出是待分类项与类别的映射关系。这一阶段也是机械性阶段, 由程序完成。
3、拉普拉斯平滑
为了解决零概率的问题,法国数学家拉普拉斯最早提出用加1的方法估计没有出现过的现象的概率,所以加法平滑也叫做拉普拉斯平滑。假定训练样本很大时,每个分量x的计数加1造成的估计概率变化可以忽略不计,但可以方便有效的避免零概率问题。
公式 P ( y k ∣ x ) = P ( y k ) ∗ ∏ P ( x i ∣ y k ) P(y_k|x) =P(y_k) * ∏P(x_i|y_k) P(yk∣x)=P(yk)∗∏P(xi∣yk), 是一个多项乘法公式, 其中有一项数值为0, 则整个公式就为
0, 显然不合理, 避免每一项为零的做法就是, 在分子、 分母上各加一个数值。
P ( y ) = ∣ D y ∣ + 1 ∣ D ∣ + N P(y)=\frac{|D_y|+1}{|D|+N} P(y)=∣D∣+N∣Dy∣+1
∣ D y ∣ |D_y| ∣Dy∣表示分类y的样本数,|D|样本总数,N是样本总数加上分类总数
P ( x i ∣ D y ) = ∣ D y , x i ∣ + 1 ∣ D y ∣ + N i P(x_i|D_y) = \frac{|D_y,x_i|+1}{|D_y|+N_i} P(xi∣Dy)=∣Dy∣+Ni∣Dy,xi∣+1
∣ D y , x i ∣ |D_y,x_i| ∣Dy,xi∣表示分类y属性i的样本数, ∣ D y ∣ |D_y| ∣Dy∣表示分类y的样本数, Ni表示i属性的可能的取值数
例子:
假设在文本分类中,有3个类,C1、C2、C3,在指定的训练样本中, 某个词语K1,在各个类中观测计数分别为0, 990, 10, K1的概率为0, 0.99,0.01,对这三个量使用拉普拉斯平滑的计算方法如下:
1/1003 = 0.001, 991/1003=0.988, 11/1003=0.011
在实际的使用中也经常使用加 λ \lambda λ( 1 ≥ λ ≥ 0 1≥\lambda≥0 1≥λ≥0) 来代替简单加1。 如果对N个计数都加上 λ \lambda λ, 这时分母也要记得加上 N ∗ λ N*\lambda N∗λ。
二、 半朴素贝叶斯分类器
概念
在朴素的分类中, 我们假定了各个属性之间的独立,这是为了计算方便,防止过多的属性之间的依赖导致的大量计算。这正是朴素的含义,虽然朴素贝叶斯的分类效果不错,但是属性之间毕竟是有关联的, 某个属性依赖于另外的属性, 于是就有了半朴素贝叶斯分类器:
因此, 对某个样本x 的预测朴素贝叶斯公式就由如下:
h ( x ) = m a x ( P ( c ) ∏ i = 1 d P ( X i ∣ c ) ) h(x)=max(P(c)\prod_{i=1}^dP(X_i|c)) h(x)=max(P(c)i=1∏dP(Xi∣c))
修正为如下的半朴素贝叶斯分类器公式:
h ( x ) = m a x ( P ( c ) ∏ i = 1 d P ( X i ∣ p a i ) ) h(x)=max(P(c)\prod_{i=1}^dP(X_i|pa_i)) h(x)=max(P(c)i=1∏dP(Xi∣pai))
从上式中, 可以看到类条件概率 P(xi | c) 修改为了 xi 依赖于分类c 和 一个依赖属性pai
上述超父ODE算法: SPODE。 显然, 这个算法是每个属性值只与其他唯一 一个有依赖关
系。 基于它之上, 又提出另一种基于集成学习机制, 更为强大的独依赖分类器, AODE,
算法思路很简单, 就是在SPODE算法的基础上在外面包一个循环, 就是尝试将每个属性
作为超父属性来构建SPODE, 请看下面的公式, 在SPODE外面包了一个循环, 然后求它
们的和作为当前预测样本的分类:
h ( x ) = m a x ( ∑ j = 1 d P ( c , x j ) ∏ i = 1 d P ( x i ∣ c , x j ) ) h(x)=max(\sum_{j=1}^dP(c,x_j)\prod_{i=1}^dP(x_i|c,x_j)) h(x)=max(j=1∑dP(c,xj)i=1∏dP(xi∣c,xj))
1.SOPDE方法。 这种方法是假定所有的属性都依赖于共同的一个父属性。
2.TAN方法。 每个属性依赖的另外的属性由最大带权生成树来确定。
(1) 先求每个属性之间的互信息来作为他们之间的权值。
(2) 构件完全图。 权重是刚才求得的互信息。然后用最大带权生成树算法求得此图的最大带权的生成树。
(3) 找一个根变量, 然后依次将图变为有向图。
(4) 添加类别y到每个属性的的有向边。
3 . 朴素贝叶斯与两种半朴素贝叶斯分类器所考虑的属性依赖关系, 假定每个属性仅依赖于
其他最多一个属性, 称其依赖的这个属性为其超父属性, 这种关系称为: 独依赖估计
(ODE) 。
三、朴素贝叶斯的面试题
1、 朴素贝叶斯与LR的区别?
简单来说:朴素贝叶斯是生成模型,根据已有样本进行贝叶斯估计学习出先验概率P(Y)和条件概率P(X|Y),进而求出联合分布概率P(XY),最后利用贝叶斯定理求解P(Y|X), 而LR是判别模型,根据极大化对数似然函数直接求出条件概率P(Y|X);朴素贝叶斯是基于很强的条件独立假设(在已知分类Y的条件下,各个特征变量取值是相互独立的),而LR则对此没有要求;朴素贝叶斯适用于数据集少的情景,而LR适用于大规模数据集。
2、朴素贝叶斯“朴素”在哪里?
简单来说:利用贝叶斯定理求解联合概率P(XY)时,需要计算条件概率P(X|Y)。在计算P(X|Y)时,朴素贝叶斯做了一个很强的条件独立假设(当Y确定时,X的各个分量取值之间相互独立),即P(X1=x1,X2=x2,…Xj=xj|Y=yk) = P(X1=x1|Y=yk)P(X2=x2|Y=yk)…*P(Xj=xj|Y=yk)。
3、 在估计条件概率P(X|Y)时出现概率为0的情况怎么办?
简单来说:引入λ,当λ=1时称为拉普拉斯平滑。
4、 朴素贝叶斯的优缺点
优点:对小规模的数据表现很好,适合多分类任务,适合增量式训练。
缺点:对输入数据的表达形式很敏感(离散、连续,值极大极小之类的)。
重点:
面试的时候怎么回答朴素贝叶斯呢?
首先朴素贝斯是一个生成模型(很重要),其次它通过学习已知样本,计算出联合概率,再求条件概率。
生成模式和判别模式的区别:
生成模式:由数据学得联合概率分布,求出条件概率分布P(Y|X)的预测模型;
常见的生成模型有:朴素贝叶斯、隐马尔可夫模型、高斯混合模型、文档主题生成模型(LDA)、限制玻尔兹曼机
判别模式:由数据学得决策函数或条件概率分布作为预测模型
常见的判别模型有:K近邻、SVM、决策树、感知机、线性判别分析(LDA)、线性回归、传统的神经网络、逻辑斯蒂回归、boosting、条件随机场
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/203461.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
