大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
(一)前言
最近正在看利用“深度学习”解方程(大概吧,其实只是利用了neural network的自动微分特性(AD)),在看一些文章的同时,将文章中提到的开源代码用起来和复现一些基本方程求解能够加快我学习的进度,这里将持续贴出一些方程和代码的求解过程。当然非常希望同学和朋友们可以给我指出错误,最后如果能够坚持下去,这个系列的工作会分享到github,同时如果对各个开源程序有所帮助那就更好了!
由于会参考到很多文章,所以将这个系列当作一个读文章的过程也很不错。
(二)物理神经网络(PINN)解读
1. PINN基本背景
2019年,布朗大学应用数学系研究团队提出了PINN,并发表在《计算物理学期刊》(Journal of Computational Physics)。自从发表,PINN成为了AI物理领域最常见的一个关键词。从下图可见,当前的引用量已经达到了1674。


figure cite:Google scholar
2. 算法描述
PINN,即物理信息神经网络,也就是将物理方程作为限制加入到神经网络之中使得拟合得到的结果更加满足物理规律。这个限制如何实现呢?也就是将物理方程迭代前后的差值就爱到Neural Network中的损失函数之中,让这个物理方程每次都能够得到训练。那么神经网络在训练迭代的过程之中优化的就不仅仅是网络自己的损失函数,还包括了物理方程每次迭代的差值,使得最后训练出来的模型满足某种设定的物理规律。
3. PINN文章解读
考虑下面的问题:
u t + N ( u ; λ ) = 0 (1) u_t + N(u;\lambda) = 0 \tag{1} ut+N(u;λ)=0(1)
其中, u ( x , t ) u(x,t) u(x,t)是要求的解, N ( u ; λ ) N(u;\lambda) N(u;λ)是关于这个解的非线性操作算子(比如偏导数), λ \lambda λ是待定参数。
那么问题就来了:
- Data-driven solutions of partial differential equations:参数 λ \lambda λ已知的时候,如何求的未知的解 u ( x , t ) u(x,t) u(x,t)
- Data-driven discovery of partial differential equations:参数 λ \lambda λ未知的时候,如何求解 u ( x , t ) u(x,t) u(x,t)的同时确定参数 λ \lambda λ
3.1 连续时间模型
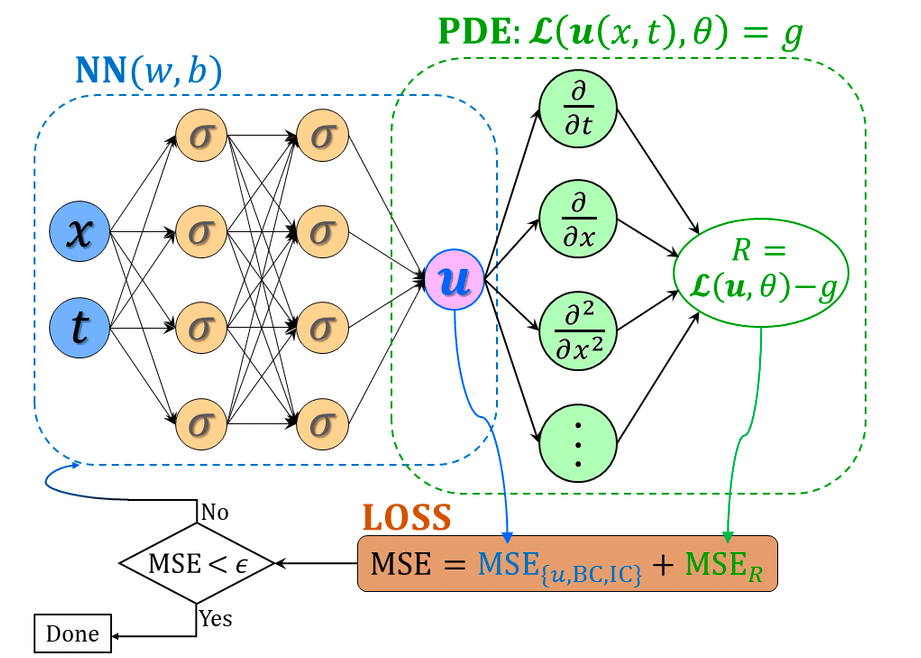
figure cite:https://bbs.huaweicloud.com/blogs/detail/263776
f ( t , x ) = u t + N [ u ] (2) f(t,x) = u_t + N[u] \tag{2} f(t,x)=ut+N[u](2)
使用神经网络来逼近 u ( x ) u(x) u(x)和 f ( x ) f(x) f(x),且这两个网络共享参数,(基于神经网络自动微分的功能,链式法则)(这个点我在后面会用一个简单的例子来说明)
具体操作:首先定义一个网络来拟合u(x),然后 f ( t , x ) f(t,x) f(t,x)可以接在 u ( x , t ) u(x,t) u(x,t)的后面再加上一些操作算子。为了优化网络我们定义一个均方损失函数:
M S E = M S E u + M S E f (3) MSE = MSE_u + MSE_f \tag{3} MSE=MSEu+MSEf(3)
其中
M S E u = 1 N u ∑ i = 1 N u ∣ u ( t u i , x u i ) − u i ∣ 2 (4) MSE_u = \frac{1}{N_u}\sum_{i=1}^{N_u}\vert u(t_u^i,x_u^i) – u^i \vert ^2 \tag{4} MSEu=Nu1i=1∑Nu∣u(tui,xui)−ui∣2(4)
M S E f = 1 N f ∑ i = 1 N f ∣ u ( t f i , x f i ) ∣ 2 (5) MSE_f = \frac{1}{N_f}\sum_{i=1}^{N_f}\vert u(t_f^i,x_f^i) \vert ^2 \tag{5} MSEf=Nf1i=1∑Nf∣u(tfi,xfi)∣2(5)
式子4表示在初始和边界条件处神经网络的拟合值 u ( t u i , x u i ) u(t_u^i,x_u^i) u(tui,xui)与真实值的均方误差;
式子5表示的是神经网络与真实物理规律的均方误差。
3.2 离散时间模型
=这个数学有些强硬,待到做到后面有机会回来补充!!!=
假设有一个q阶的龙格-库塔方程(百度百科-龙格库塔法):
u n + c i = u n − Δ ∑ j = 1 q a i j N [ u n + c j ] , i = 1 , . . . . , q u^{n+c_i} = u^n – \Delta \sum_{j=1}^{q}a_{ij}N[u^{n+c_j}] , \; i=1,….,q un+ci=un−Δj=1∑qaijN[un+cj],i=1,....,q u n + 1 = u n − Δ ∑ j = 1 q b j N [ u n + c j ] (6) u^{n+1} = u^n – \Delta \sum_{j=1}^{q}b_{j}N[u^{n+c_j}] \tag{6} un+1=un−Δj=1∑qbjN[un+cj](6)
这里 u n + c j ( x ) = u ( t n + c j Δ t , x ) , j = 1 , 2. , . . . , q u^{n+c_j}(x) = u(t^n +c_j\Delta t,x) , \; j = 1,2.,…,q un+cj(x)=u(tn+cjΔt,x),j=1,2.,...,q.这个通用形式通过参数 { a i j , b j , c j } \{a_{ij} , b_j,c_j\} {
aij,bj,cj}融合了显式和隐式的解,那么式7可以表示为下面简单的形式
u n = u i n , i = 1 , . . . , q u^n = u_i^n , \; i = 1,…,q un=uin,i=1,...,q u n = u q + 1 n (7) u^n = u^{n}_{q+1} \tag{7} un=uq+1n(7)
我们首先设计一个多输出的神经网络拟合
[ u n + c 1 ( x ) , . . . , u n + c q ( x ) , u n + 1 ( x ) ] [u^{n+c_1}(x),…,u^{n+c_q}(x),u^{n+1}(x)] [un+c1(x),...,un+cq(x),un+1(x)]
然后这个先验假设结果和方程7就构成了一个物理信息神经网络:
[ u 1 n ( x ) , . . . , u q n ( x ) , u q + 1 n ( x ) ] [u^{n}_1(x),…,u^{n}_q(x),u^{n}_{q+1}(x)] [u1n(x),...,uqn(x),uq+1n(x)]
3.3 论文结果展示
(1) Schrodinger equation:薛定谔方程
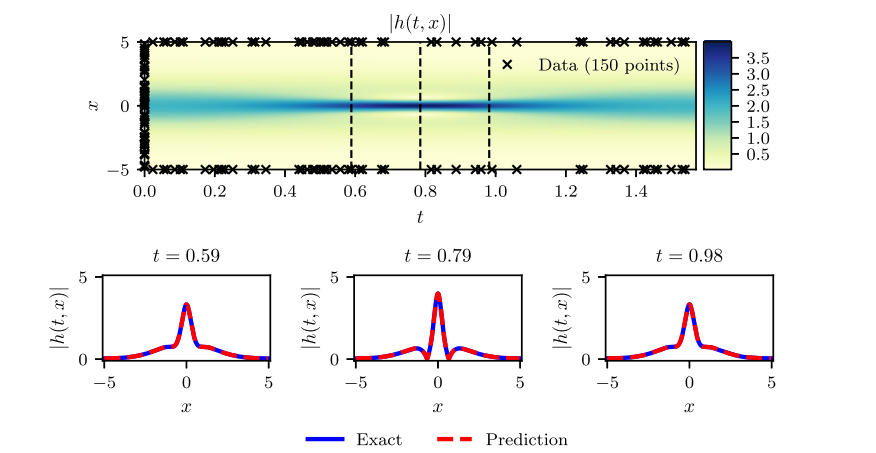
figure cite: (M.Raissi.etc,Journal of Computational Physics,2019)
顶部是 ∣ h ( t , x ) ∣ |h(t,x)| ∣h(t,x)∣沿着初始和边界条件的训练数据份分布,以及随机生成的20000个采样点序列;下面是精确数值解和我们神经网络预测的结果的对比图,红色表示预测结果,蓝色是精确解。此处对应的L2误差(最小二乘误差)是 1.97.1 0 − 3 1.97 . 10^{-3} 1.97.10−3
(2) Allen-Cahn方程:
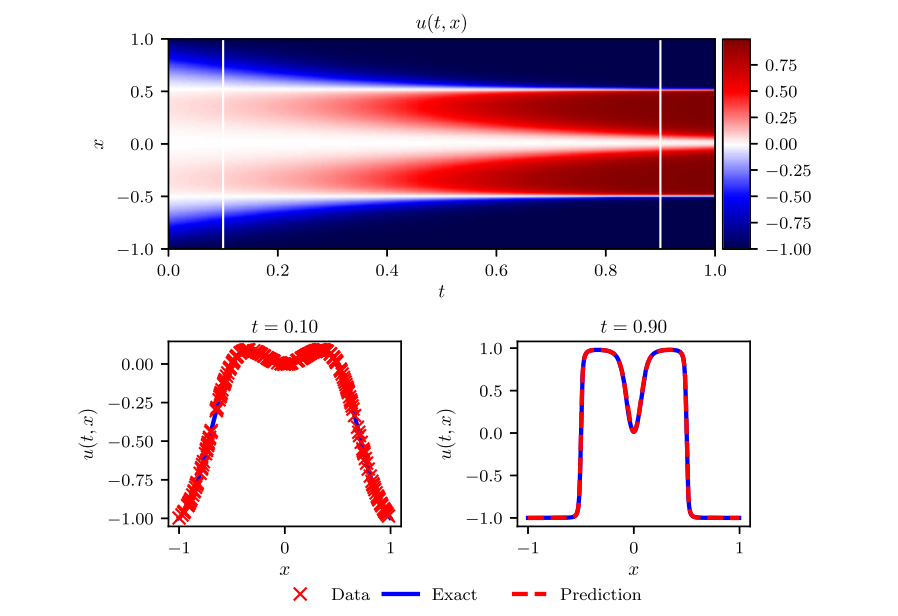
figure cite: (M.Raissi.etc,Journal of Computational Physics,2019)
(3) Navier-Stokes方程(什么是纳维-斯托克斯方程?):
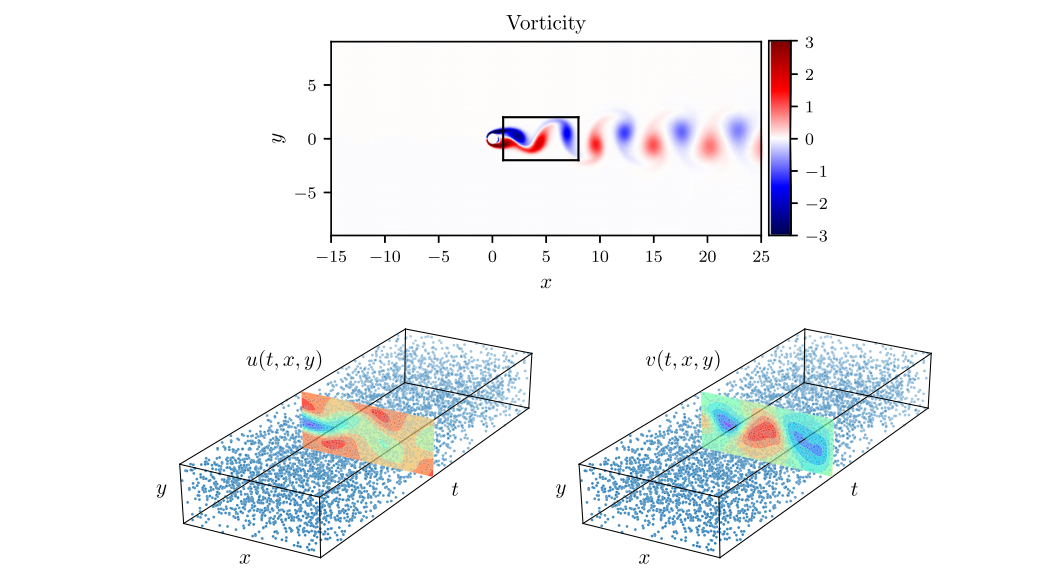
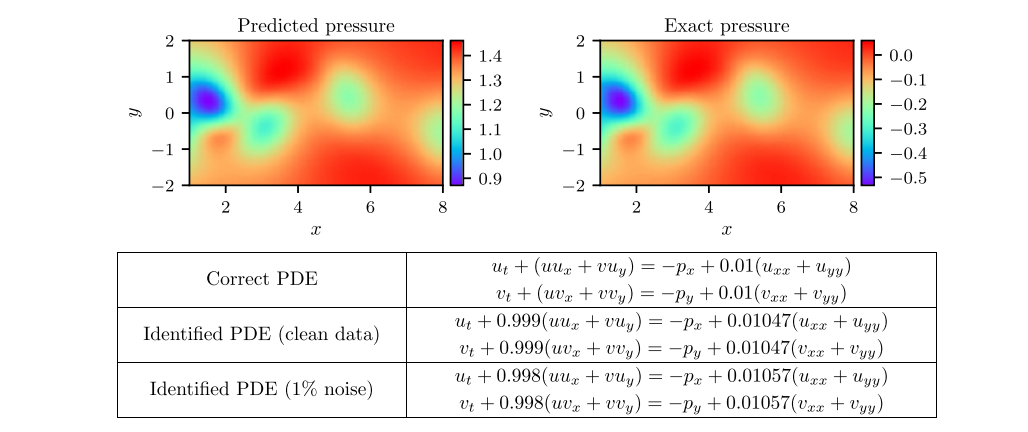
figure cite: (M.Raissi.etc,Journal of Computational Physics,2019)
(4) KdV 方程:
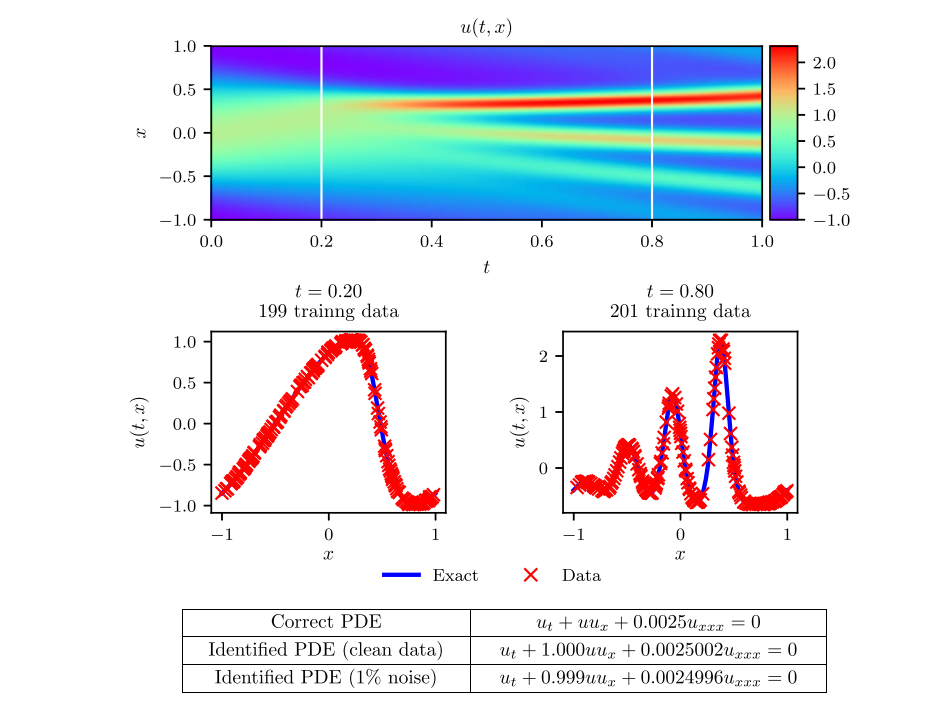
4. 总结
详细内容参考原文,因为我认为读这篇文章的关键是:
-
Why?
PINN:物理信息神经网络是在神经网络通用近似理论的基础上,通过加入偏导数等算子给数值模拟加上了物理约束,从而使得整个网络具有模拟物理规则的作用。关键点在于:通用近似理论 + 物理信息的传递(导数算子+残差构建)+NN的自动微分(AD) -
How?
怎么构建网络去优化?简单的全连接神经网络甚至已经能很好地进行通用近似了!!! -
What?
用PINN可以做什么?解偏微分方程,在各种不同的领域中都有涉及。对于我个人而言,我在读地球物理,其中的波动方程、程函方程、格林函数等等都是有待攻克的领域,当然也已经有很多人有了很多的发现,但是基于前人研究也会有更多的见解
参考:
【1】博客分析:物理神经网络(PINN)解读
【2】PINN论文:Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations
【3】当神经网络遇上物理: PINNs原理解析
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/203460.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
