大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
本文是笔者在学习cycleGAN的代码时,发现其实现了根据需求选择不同调整学习率方法的策略,遂查资料了解pytorch各种调整学习率的方法。主要参考:https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
1 综述
1.1 lr_scheduler综述
torch.optim.lr_scheduler模块提供了一些根据epoch训练次数来调整学习率(learning rate)的方法。一般情况下我们会设置随着epoch的增大而逐渐减小学习率从而达到更好的训练效果。
而torch.optim.lr_scheduler.ReduceLROnPlateau则提供了基于训练中某些测量值使学习率动态下降的方法。
学习率的调整应该放在optimizer更新之后,下面是一个参考蓝本:
>>> scheduler = ...
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()
注意: 在PyTorch 1.1.0之前的版本,学习率的调整应该被放在optimizer更新之前的。如果我们在 1.1.0 及之后的版本仍然将学习率的调整(即 scheduler.step())放在 optimizer’s update(即 optimizer.step())之前,那么 learning rate schedule 的第一个值将会被跳过。所以如果某个代码是在 1.1.0 之前的版本下开发,但现在移植到 1.1.0及之后的版本运行,发现效果变差,需要检查一下是否将scheduler.step()放在了optimizer.step()之前。
1.2 optimizer综述
为了了解lr_scheduler,我们先以Adam()为例了解一下优化器(所有optimizers都继承自torch.optim.Optimizer类):
语法:
class torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
参数:
- params (iterable):需要优化的网络参数,传进来的网络参数必须是
Iterable(官网对这个参数用法讲的不太清楚,下面有例子清楚的说明param具体用法)。- 如果优化一个网络,网络的每一层看做一个parameter group,一整个网络就是parameter groups(一般给赋值为
net.parameters()),补充一点,net.parameters()函数返回的parameter groups实际上是一个变成了generator的字典; - 如果同时优化多个网络,有两种方法:
- 将多个网络的参数合并到一起,当成一个网络的参数来优化(一般赋值为
[*net_1.parameters(), *net_2.parameters(), ..., *net_n.parameters()]或itertools.chain(net_1.parameters(), net_2.parameters(), ..., net_n.parameters())); - 当成多个网络优化,这样可以很容易的让多个网络的学习率各不相同(一般赋值为
[{'params': net_1.parameters()}, {'params': net_2.parameters()}, ..., {'params': net_n.parameters()})。
- 将多个网络的参数合并到一起,当成一个网络的参数来优化(一般赋值为
- 如果优化一个网络,网络的每一层看做一个parameter group,一整个网络就是parameter groups(一般给赋值为
- lr (float, optional):学习率;
- betas (Tuple[float, float], optional) – coefficients used for computing running averages of gradient and its square (default: (0.9, 0.999));
- eps (float, optional) – term added to the denominator to improve numerical stability (default: 1e-8);
- weight_decay (float, optional) – weight decay (L2 penalty) (default: 0);
- amsgrad (boolean, optional) – whether to use the AMSGrad variant of this algorithm from the paper On the Convergence of Adam and Beyond (default: False)。
两个属性:
- optimizer.defaults: 字典,存放这个优化器的一些初始参数,有:
'lr','betas','eps','weight_decay','amsgrad'。事实上这个属性继承自torch.optim.Optimizer父类; - optimizer.param_groups:列表,每个元素都是一个字典,每个元素包含的关键字有:
'params','lr','betas','eps','weight_decay','amsgrad',params类是各个网络的参数放在了一起。这个属性也继承自torch.optim.Optimizer父类。
由于上述两个属性都继承自所有优化器共同的基类,所以是所有优化器类都有的属性,并且两者字典中键名相同的元素值也相同(经过lr_scheduler后lr就不同了)。
下面是用法示例:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import LambdaLR
import itertools
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
self.conv2 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
net_2 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
print("******************optimizer_1*********************")
print("optimizer_1.defaults:", optimizer_1.defaults)
print("optimizer_1.param_groups长度:", len(optimizer_1.param_groups))
print("optimizer_1.param_groups一个元素包含的键:", optimizer_1.param_groups[0].keys())
print()
optimizer_2 = torch.optim.Adam([*net_1.parameters(), *net_2.parameters()], lr = initial_lr)
# optimizer_2 = torch.opotim.Adam(itertools.chain(net_1.parameters(), net_2.parameters())) # 和上一行作用相同
print("******************optimizer_2*********************")
print("optimizer_2.defaults:", optimizer_2.defaults)
print("optimizer_2.param_groups长度:", len(optimizer_2.param_groups))
print("optimizer_2.param_groups一个元素包含的键:", optimizer_2.param_groups[0].keys())
print()
optimizer_3 = torch.optim.Adam([{
"params": net_1.parameters()}, {
"params": net_2.parameters()}], lr = initial_lr)
print("******************optimizer_3*********************")
print("optimizer_3.defaults:", optimizer_3.defaults)
print("optimizer_3.param_groups长度:", len(optimizer_3.param_groups))
print("optimizer_3.param_groups一个元素包含的键:", optimizer_3.param_groups[0].keys())
输出为:
******************optimizer_1*********************
optimizer_1.defaults: {'lr': 0.1, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False}
optimizer_1.param_groups长度: 1
optimizer_1.param_groups一个元素包含的键: dict_keys(['params', 'lr', 'betas', 'eps', 'weight_decay', 'amsgrad'])
******************optimizer_2*********************
optimizer_2.defaults: {'lr': 0.1, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False}
optimizer_2.param_groups长度: 1
optimizer_2.param_groups一个元素包含的键: dict_keys(['params', 'lr', 'betas', 'eps', 'weight_decay', 'amsgrad'])
******************optimizer_3*********************
optimizer_3.defaults: {'lr': 0.1, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False}
optimizer_3.param_groups长度: 2
optimizer_3.param_groups一个元素包含的键: dict_keys(['params', 'lr', 'betas', 'eps', 'weight_decay', 'amsgrad'])
注意:
lr_scheduler更新optimizer的lr,是更新的optimizer.param_groups[n][‘lr’],而不是optimizer.defaults[‘lr’]。
2 lr_scheduler调整策略:根据训练次数
torch.optim.lr_scheduler中大部分调整学习率的方法都是根据epoch训练次数,这里介绍常见的几种方法,其他方法以后用到再补充。
要了解每个类的更新策略,可直接查看官网doc中的源码,每类都有个get_lr方法,定义了更新策略。
2.1 torch.optim.lr_scheduler.LambdaLR
语法:
class torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)
更新策略:
n e w _ l r = λ × i n i t i a l _ l r new\_lr = \lambda \times initial\_lr new_lr=λ×initial_lr
其中 n e w _ l r new\_lr new_lr是得到的新的学习率, i n i t i a l _ l r initial\_lr initial_lr是初始的学习率, λ \lambda λ是通过参数lr_lambda和epoch得到的。
参数:
- optimizer (Optimizer):要更改学习率的优化器;
- lr_lambda(function or list):根据epoch计算 λ \lambda λ的函数;或者是一个
list的这样的function,分别计算各个parameter groups的学习率更新用到的 λ \lambda λ; - last_epoch (int):最后一个epoch的index,如果是训练了很多个epoch后中断了,继续训练,这个值就等于加载的模型的epoch。默认为-1表示从头开始训练,即从epoch=1开始。
注意:
在将optimizer传给scheduler后,在shcduler类的__init__方法中会给optimizer.param_groups列表中的那个元素(字典)增加一个key = "initial_lr"的元素表示初始学习率,等于optimizer.defaults['lr']。
下面举例说明:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import LambdaLR
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = LambdaLR(optimizer_1, lr_lambda=lambda epoch: 1/(epoch+1))
print("初始化的学习率:", optimizer_1.defaults['lr'])
for epoch in range(1, 11):
# train
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
scheduler_1.step()
输出:
初始化的学习率: 0.1
第1个epoch的学习率:0.100000
第2个epoch的学习率:0.050000
第3个epoch的学习率:0.033333
第4个epoch的学习率:0.025000
第5个epoch的学习率:0.020000
第6个epoch的学习率:0.016667
第7个epoch的学习率:0.014286
第8个epoch的学习率:0.012500
第9个epoch的学习率:0.011111
第10个epoch的学习率:0.010000
下面解析关键行:
第1~3行
import一些包。
第7~13行
简单定义一个网络类,并没有实现网络应有的功能,只是用来定义optimizer的。
第15行
实例化一个网络。
第17行
实例化一个Adam对象。
第18行
实例化一个LambdaLR对象。lr_lambda是根据epoch更新lr的函数。
第20行
打印出初始的lr。optimizer_1.defaults保存的是初始的参数。
第22~28行
模仿训练的epoch。
第25~26行
更新网络参数(这里省略了loss.backward())。
第27行
打印这一个epoch更新参数所用的学习率,由于我们只给optimizer_1传了一个net.parameters(),所以optimizer_1.param_groups长度为1。
第28行
更新学习率。
补充:
cycleGAN中使用torch.optim.lr_scheduler.LambdaLR实现了前niter个epoch用initial_lr为学习率,之后的niter_decay个epoch线性衰减lr,直到最后一个epoch衰减为0。详情参考:https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/blob/master/models/networks.py的第52~55行。
2.2 torch.optim.lr_scheduler.StepLR
语法:
class torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
更新策略:
每过step_size个epoch,做一次更新:
n e w _ l r = i n i t i a l _ l r × γ e p o c h / / s t e p _ s i z e new\_lr = initial\_lr \times \gamma^{epoch // step\_size} new_lr=initial_lr×γepoch//step_size
其中 n e w _ l r new\_lr new_lr是得到的新的学习率, i n i t i a l _ l r initial\_lr initial_lr是初始的学习率, s t e p _ s i z e step\_size step_size是参数step_size, γ \gamma γ是参数gamma。
参数:
- optimizer (Optimizer):要更改学习率的优化器;
- step_size(int):每训练step_size个epoch,更新一次参数;
- gamma(float):更新lr的乘法因子;
- last_epoch (int):最后一个epoch的index,如果是训练了很多个epoch后中断了,继续训练,这个值就等于加载的模型的epoch。默认为-1表示从头开始训练,即从epoch=1开始。
下面举例说明:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import StepLR
import itertools
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = StepLR(optimizer_1, step_size=3, gamma=0.1)
print("初始化的学习率:", optimizer_1.defaults['lr'])
for epoch in range(1, 11):
# train
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
scheduler_1.step()
输出为:
初始化的学习率: 0.1
第1个epoch的学习率:0.100000
第2个epoch的学习率:0.100000
第3个epoch的学习率:0.100000
第4个epoch的学习率:0.010000
第5个epoch的学习率:0.010000
第6个epoch的学习率:0.010000
第7个epoch的学习率:0.001000
第8个epoch的学习率:0.001000
第9个epoch的学习率:0.001000
第10个epoch的学习率:0.000100
2.3 torch.optim.lr_scheduler.MultiStepLR
语法:
class torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)
更新策略:
每次遇到milestones中的epoch,做一次更新:
n e w _ l r = i n i t i a l _ l r × γ b i s e c t _ r i g h t ( m i l e s t o n e s , e p o c h ) new\_lr = initial\_lr \times \gamma^{bisect\_right(milestones, epoch)} new_lr=initial_lr×γbisect_right(milestones,epoch)
其中 n e w _ l r new\_lr new_lr是得到的新的学习率, i n i t i a l _ l r initial\_lr initial_lr是初始的学习率, γ \gamma γ是参数gamma, b i s e c t _ r i g h t ( m i l e s t o n e s , e p o c h ) bisect\_right(milestones, epoch) bisect_right(milestones,epoch)就是bisect模块中的bisect_right函数,返回值是把epoch插入排序好的列表milestones式的位置。
参数:
- optimizer (Optimizer):要更改学习率的优化器;
- milestones(list):递增的list,存放要更新lr的epoch;
- gamma(float):更新lr的乘法因子;
- last_epoch (int):最后一个epoch的index,如果是训练了很多个epoch后中断了,继续训练,这个值就等于加载的模型的epoch。默认为-1表示从头开始训练,即从epoch=1开始。
下面举例说明:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import MultiStepLR
import itertools
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = MultiStepLR(optimizer_1, milestones=[3, 7], gamma=0.1)
print("初始化的学习率:", optimizer_1.defaults['lr'])
for epoch in range(1, 11):
# train
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
scheduler_1.step()
输出为:
初始化的学习率: 0.1
第1个epoch的学习率:0.100000
第2个epoch的学习率:0.100000
第3个epoch的学习率:0.100000
第4个epoch的学习率:0.010000
第5个epoch的学习率:0.010000
第6个epoch的学习率:0.010000
第7个epoch的学习率:0.010000
第8个epoch的学习率:0.001000
第9个epoch的学习率:0.001000
第10个epoch的学习率:0.001000
2.4 torch.optim.lr_scheduler.ExponentialLR
语法:
class torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)
更新策略:
每个epoch都做一次更新:
n e w _ l r = i n i t i a l _ l r × γ e p o c h new\_lr = initial\_lr \times \gamma^{epoch} new_lr=initial_lr×γepoch
其中 n e w _ l r new\_lr new_lr是得到的新的学习率, i n i t i a l _ l r initial\_lr initial_lr是初始的学习率, γ \gamma γ是参数gamma.
参数:
- optimizer (Optimizer):要更改学习率的优化器;
- gamma(float):更新lr的乘法因子;
- last_epoch (int):最后一个epoch的index,如果是训练了很多个epoch后中断了,继续训练,这个值就等于加载的模型的epoch。默认为-1表示从头开始训练,即从epoch=1开始。
下面举例说明:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import ExponentialLR
import itertools
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = ExponentialLR(optimizer_1, gamma=0.1)
print("初始化的学习率:", optimizer_1.defaults['lr'])
for epoch in range(1, 11):
# train
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
scheduler_1.step()
输出为:
初始化的学习率: 0.1
第1个epoch的学习率:0.100000
第2个epoch的学习率:0.010000
第3个epoch的学习率:0.001000
第4个epoch的学习率:0.000100
第5个epoch的学习率:0.000010
第6个epoch的学习率:0.000001
第7个epoch的学习率:0.000000
第8个epoch的学习率:0.000000
第9个epoch的学习率:0.000000
第10个epoch的学习率:0.000000
2.5 torch.optim.lr_scheduler.CosineAnnealingLR
语法:
class torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)
更新策略:
让lr随着epoch的变化图类似于cos:
n e w _ l r = e t a _ m i n + ( i n i t i a l _ l r − e t a _ m i n ) × ( 1 + c o s ( e p o c h T _ m a x π ) ) new\_lr = eta\_min + (initial\_lr-eta\_min) \times (1+cos(\frac{epoch}{T\_max}\pi)) new_lr=eta_min+(initial_lr−eta_min)×(1+cos(T_maxepochπ))
其中 n e w _ l r new\_lr new_lr是得到的新的学习率, i n i t i a l _ l r initial\_lr initial_lr是初始的学习率, e t a _ m i n eta\_min eta_min是参数eta_min表示最小学习率, T _ m a x T\_max T_max是参数T_max表示cos的周期的1/4。
参数:
- optimizer (Optimizer):要更改学习率的优化器;
- T_max(int):lr的变化是周期性的,T_max是周期的 1 4 \frac{1}{4} 41;
- eta_min(float):lr的最小值,默认为0;
- last_epoch (int):最后一个epoch的index,如果是训练了很多个epoch后中断了,继续训练,这个值就等于加载的模型的epoch。默认为-1表示从头开始训练,即从epoch=1开始。
下面举例说明:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import CosineAnnealingLR
import itertools
import matplotlib.pyplot as plt
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = CosineAnnealingLR(optimizer_1, T_max=20)
print("初始化的学习率:", optimizer_1.defaults['lr'])
lr_list = [] # 把使用过的lr都保存下来,之后画出它的变化
for epoch in range(1, 101):
# train
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
lr_list.append(optimizer_1.param_groups[0]['lr'])
scheduler_1.step()
# 画出lr的变化
plt.plot(list(range(1, 101)), lr_list)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title("learning rate's curve changes as epoch goes on!")
plt.show()
输出结果过长不再展示,下面展示lr的变化图:
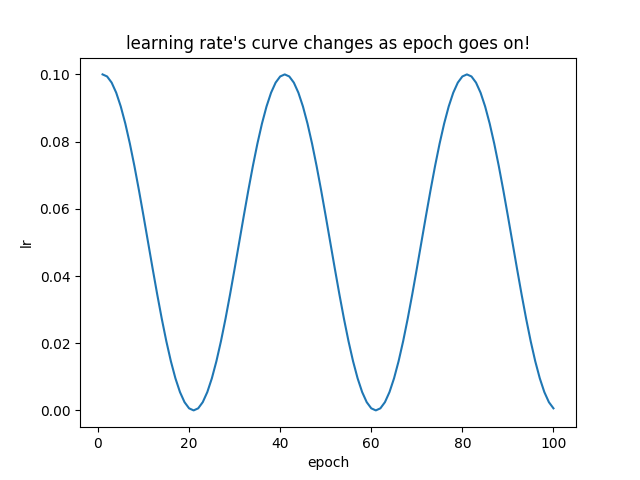

可以看到lr的变化类似于cos函数的变化图。
2.6 torch.optim.lr_scheduler.CyclicLR
2.7 torch.optim.lr_scheduler.OneCycleLR
2.8 torch.optim.lr_scheduler.CosineAnnealingWarmRestarts
3 lr_scheduler调整策略:根据训练中某些测量值
不依赖epoch更新lr的只有torch.optim.lr_scheduler.ReduceLROnPlateau。
语法:
class torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)
更新策略:
给定一个metric,当metric停止优化时减小学习率。
n e w _ l r = λ × o l d _ l r new\_lr = \lambda \times old\_lr new_lr=λ×old_lr
其中 n e w _ l r new\_lr new_lr是得到的新的学习率, o l d _ l r old\_lr old_lr是上一次优化使用的学习率, λ \lambda λ是通过参数factor。
参数:
- optimizer (Optimizer):要更改学习率的优化器;
- mode(str):只能是
‘min’或'max',默认’min':‘min'模式下,当metric不再下降时减小lr;'max'模式下,当metric不再增长时减小lr;
- factor(float):lr减小的乘法因子,默认为0.1;
- patience(int):在metric停止优化
patience个epoch后减小lr,例如,如果patience=2,那metric不再优化的前两个epoch不做任何事,第三个epoch后metric仍然没有优化,那么更新lr,默认为10; - verbose(bool):如果为
True,在更新lr后print一个更新信息,默认为False; - threshold (float) – Threshold for measuring the new optimum, to only focus on significant changes. Default: 1e-4.
- threshold_mode (str) – One of rel, abs. In rel mode, dynamic_threshold = best * ( 1 + threshold ) in ‘max’ mode or best * ( 1 – threshold ) in min mode. In abs mode, dynamic_threshold = best + threshold in max mode or best – threshold in min mode. Default: ‘rel’.
- cooldown (int) – Number of epochs to wait before resuming normal operation after lr has been reduced. Default: 0.
- min_lr (float or list) – A scalar or a list of scalars. A lower bound on the learning rate of all param groups or each group respectively. Default: 0.
- eps (float) – Minimal decay applied to lr. If the difference between new and old lr is smaller than eps, the update is ignored. Default: 1e-8.
下面举例说明:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import ReduceLROnPlateau
import itertools
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = ReduceLROnPlateau(optimizer_1, mode='min', factor=0.1, patience=2)
print("初始化的学习率:", optimizer_1.defaults['lr'])
for epoch in range(1, 15):
# train
test = 2
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
scheduler_1.step(test)
输出为:
初始化的学习率: 0.1
第1个epoch的学习率:0.100000
第2个epoch的学习率:0.100000
第3个epoch的学习率:0.100000
第4个epoch的学习率:0.100000
第5个epoch的学习率:0.010000
第6个epoch的学习率:0.010000
第7个epoch的学习率:0.010000
第8个epoch的学习率:0.001000
第9个epoch的学习率:0.001000
第10个epoch的学习率:0.001000
第11个epoch的学习率:0.000100
第12个epoch的学习率:0.000100
第13个epoch的学习率:0.000100
第14个epoch的学习率:0.000010
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/201101.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
