大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
EVT:Extreme Value Theory;预测小概率时间发生的可能,如大洪水,评估海事安全等。
EVT 中心思想是概率分布,可给出事件发生概率的数学公式。
例如常用的高斯分布,通常绝大多数数据不会偏离均值很多,但是对分布两端的极端值很难预测;属于小概率事件,事件越极端发生概率越低;此时计算发生概率可使用以往此类极端事件发生情况拟合曲线。
使用EVT流式检测异常值:Anomaly Detectionin Streams with Extreme Value Theory
检测流中的极端值问题可表述为,Xt是一段时间内的观测值,设置阈值zq,对任何>=0的时间 t,可观测到Xt > zq 的概率小于q(q很小)
之前常用的方法需要假设:正常数据发生有很高概率而异常发生概率很低,需要假设数据分布;而极值理论不需要假设样本数据的分布,通过理论结果推测低概率区域并找出异常点,这种单参数的方法适用于稳定样本和移动的样本。
在数学上,X是随机变量,F代表积累分布函数;F(X)=P(X<=x);函数F的尾部分布为F(X)=1-F(X)=P(X>x);用Xi代表随机变量和结果,通过上下文可明确它们的意思。对一个随机变量X和给定的概率q,记zq为它在1-q层的分位数,zq是最小值,P(X<=zq)>=1-q,P(X>zq)<q。
EVT的目的是找到极端事件的规律;极端事件有相同分布而不同于其原有分布。例如温度和潮汐的最大值几乎有相同分布而与潮汐和温度的分布不相同,这种分布称为极值分布EVD,形式如下:
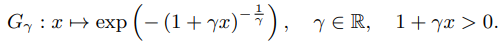

所有正常标准分布的极值都符合EVD分布,极值系数 γ 依赖于原始分布规则。
例如,X1…Xn 是n个变量,符合高斯正态分布,Mn为X中的极大值集合,Mn符合EVD分布,γ 由初始分布决定(这里是高斯分布,值为0)
对于多数概率分布,当事件趋向于极值时其概率会下降,
例如当X 大于某值是P(X > x)的概率,随着x增大其概率P趋近于0。
F(x) = P(X>x) 代表 X 的分布的尾部,实际上只有三种尾部形状和 Gγ 匹配对应的函数。

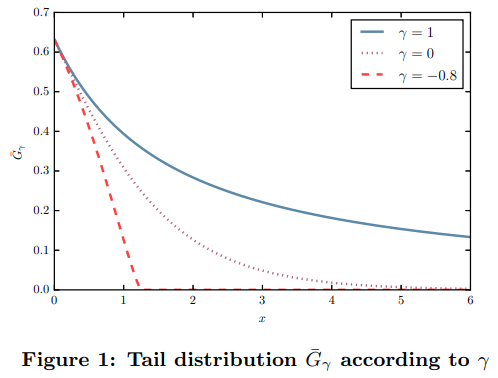
根据上述现象,可不受初始规则影响而准确的计算概率。使初始分布正式化,中心极限定理表述了正态分布中 n 个变量的均值汇聚到分布中;极值理论对极值表述了同样的结果。
极值理论可在原始数据分布非常复杂的情况下,仍可估计极端事件(异常等)。如下图,蓝色线段表示的是一个未知分布,但是红色虚线则可以进行拟合推动其分布。定义一个异常概率 q (这是本算法中的唯一参数),存在一个可能的值 Zq 使 P(X > Zq) < q ,估计 Gγ 拟合红虚线。
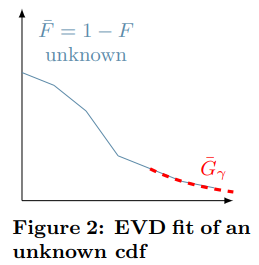
对未知输入分布的尾部训练EVD分布,就可以估算出潜在极端事件的概率;实际中,通过给定一个概率 q,可通过P(X > Zq) < q, 计算出zq,q 为概率,Zq为阈值,γ 值的估计是未解决的问题。
一种现存的训练尾部分布的方法是Peaks-Over_Threshold(POT)方法,也称作第二极值理论。
累积分布函数F,当且仅当下面函数的 σ 存在,x 属于自然数,1 + x * γ > 0。
极值理论(EVT)认为不同事物符合不同的数据分布,但不同事物的极端事件满足相同的分布,这个分布称为极值分布。而 SPOT 应用 EVT 第二理论,即极值相对于一个阈值超出的部分满足帕累托分布(GPD):
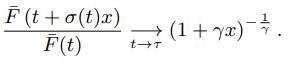
这个结果显示超过阈值 t 记作 X- t,符合 GPD分布,参数有γ,σ。GPD分布还需要第三个参数 μ,这里设置为空。相比对X的极值训练EVD分布,POT是对超出阈值 t 的值 X-t 训练GPD分布(使用帕累托分布去拟合)。
使用极大似然估计计算 γ 和 σ 值,分位数阈值 Zq 使用下式计算(公式 (1)):
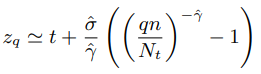
最大似然估计式子:
Yi = Xi – t,即所有大于 t 值得Xi 减去 t 的差值的集合。
在严格的GPD分布中,即 Yi 符合GPD分布,最大似然估计相比其他估计有更好的融合性质。
Grimshaw 策略是将两个变量优化问题转为一个变量等式;l(γ, σ) = log(γ, σ),要找 l 的极值,就是找 l(γ, σ) 的导数为 0 的解,根据 Grimshaw 策略如果得到解,则变量 x = γ / σ 是标量等式 u(x) * v(x) = 1 的解,而 u(x),v(x) 如下:
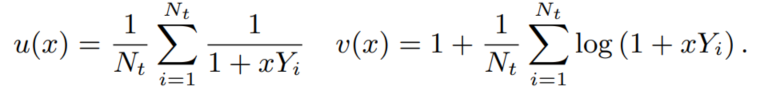
由等式可知 γ = v(x) – 1,σ = γ / x,这个等式的解只能给出 l(γ, σ) 最大的可能解,所有要得到所有的根去计算对应的似然值,用最好的(γ, σ) 作为最终的估计值。
搜索所有根的值,1 + x * Yi 必须是严格的正数,因为 Yi 为正,所有 x 的范围 (-(1 / YM), +∞),YM 是 Yi 中的最大值,通过下面的公式计算上边界值 Xmax 以搜索根的值:
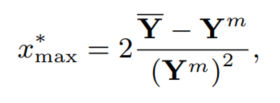
Ym = min(Yi),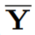 为 Yi 均值,根的数量未知,要找到使似然值最大的解。
为 Yi 均值,根的数量未知,要找到使似然值最大的解。
极值理论,通过POT方法估计 Zq,P(X > zq) < q,对X的分布不需要假设,不需要明确分布类型。
首先是初始化步骤,通过n个观察值X1…Xn 计算阈值 Zq。之后细化两个流式算法,通过输入数据更新Zq,并作为决策边界。本文提出SPOT用于稳态数据,DSPOT用于流动部分。最后可使用一些理论和技术改进,使更新边界更快更好。

POT初始返回一个阈值 Zq,用 Zq 定义正常边界;POT 初始化值更像是一个校准的步骤。
流式异常检测使用下一个观察值检测异常和定义异常阈值 zq。
首先是初始化步骤,通过 n 个观察值 X1…Xn 计算阈值 Zq。细化两个流式算法,通过输入数据更新Zq值,并作为决策边界。本文提出SPOT用于稳态数据,DSPOT用于流动部分。最后可使用一些理论和技术改进,使更新边界更快更好。

POT初始返回一个阈值 Zq,使用 Zq 定义正常边界;
初始化更像是一个校准的步骤,流式异常检测使用下一个观察值检测,异常和定义异常阈值 Zq。
POT 不需要存储所有时间序列,只要峰值即可。
在流中检测异常事件,首先使用POT估计前 n 个值,获得初始阈值 Zq;对于所有下一个观测值就可以标注事件或更新阈值。如果一个值超过了阈值 Zq, 就认为其异常,不使用其更新模型。另一种情况,Xi 大于初始阈值还属于正常值(峰值样例)。在峰值样例中,添加到峰值集合,更新Zq。SPOT假设 Xi 分布不随时间变化,但可能太严格了。
DSPOT 使 SPOT 不使用 Xi 绝对值而是相对值运行。
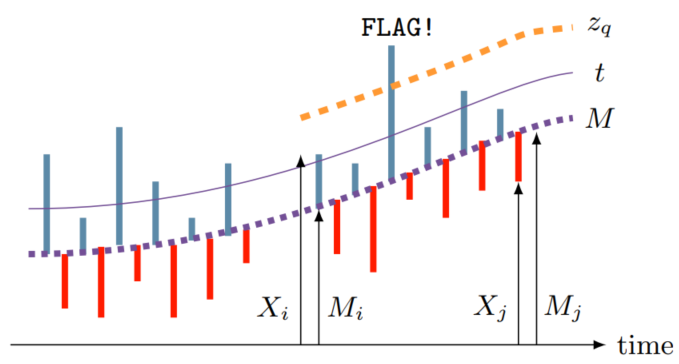 使用变量的差值, Mi 是 i 时刻的均值,Mi 是移动平均,d 是当前样本的前 d 个正常观测值,d 是一个窗口参数。假设 Xi 来自相同的静态分布。
使用变量的差值, Mi 是 i 时刻的均值,Mi 是移动平均,d 是当前样本的前 d 个正常观测值,d 是一个窗口参数。假设 Xi 来自相同的静态分布。
数值优化:减少参数选择的搜索
u(x) * v(x) = 1 的可能的解在下面两个区间内:
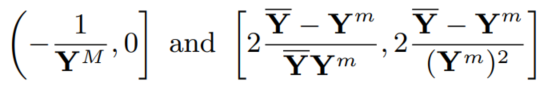
如果 x 是公式的解,则满足条件: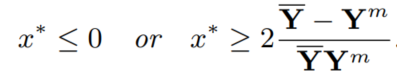
最大化似然函数优化:使用 L-BFGS-B 解 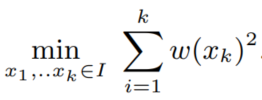
初始化 t 值,要确保 t 小于 Zq,t 的概率小于 1 – q,实际中设 t 为一个高的经验分位数 98%
SPOT的步骤可以分为两步:
(1)calibration,或者叫初始化。根据已有的数据计算t和阈值Zq。
(2)流式更新阈值Zq,并把它当做决策边界判断异常。大于Zq的为异常,报出去;
在t和zq之间的为peaks,用于更新GPD模型和Zq;小于t的为正常数据,不处理;
DSPOT:用与局部平均M的相对值代替原先的绝对值进行SPOT。该算法认为这个相对值的分布不随时间变化,即这个相对值满足SPOT的前提条件。
DSPOT算法流程
先取前d个数计算M(初始化M)
再取n个数计算相对值X’, 拟合模型得到初始阈值zq(初始化阈值zq)
流式更新模型:
如果新来的相对值大于zq,判断为异常,不更新模型(特指极值分布模型),不更新M值。
如果新来的相对值是peak(大于t),更新模型,更新M;
否则,只更新M,不更新模型。
参考:
极值理论(Extreme Value Theory) (360doc.com)
基于极值理论的流数据实时异常检测(SPOT/DSPOT, KDD’17) – 知乎
基于极值理论的单变量时间序列流式异常检测算法SPOT/DSPOT_m0_37935211的博客-CSDN博客
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/200917.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
