大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
Factorizing YAGO Scalable Machine Learning for Linked Data
关联数据的可扩展机器学习分解
发表于 WWW 2012 – Session: Creating and Using Links between Data Objects
摘要:语义Web的链接开放数据(LOD)云中已经发布了大量的结构化信息,而且它们的规模仍在快速增长。然而,由于LOD的大小、部分数据不一致和固有的噪声,很难通过推理和查询访问这些信息。本文提出了一种高效的LOD数据关系学习方法,基于稀疏张量的因子分解,该稀疏张量由数百万个实体、数百个关系和数十亿个已知事实组成的数据。此外,本文展示了如何将本体论知识整合到因子分解中以提高学习结果,以及如何将计算分布到多个节点上。通过实验表明,我们的方法在与关联数据相关的几个关系学习任务中取得了良好的结果。
我们在语义Web上进行大规模学习的方法是基于RESCAL,这是一种张量因子分解,它在各种规范关系学习任务中显示出非常好的结果,如链接预测、实体解析或集体分类。与其他张量分解相比,RESCAL的主要优势在于:当应用于关系数据时,它可以利用集体学习效应。集体学习是指在跨越多个互连的实体和关系中自动开发属性和关系相关性。众所周知,将集体学习方法应用于关系数据可以显著改善学习结果。例如,考虑预测美利坚合众国总统的党籍的任务。自然而然地,总统和他的副总统的党籍是高度相关的,因为两人大部分都是同一党的成员。这些关系可以通过一种集体学习的方法来推断出这个领域中某个人的正确党籍。RESCAL能够检测这种相关性,因为它被设计为解释二元关系数据的固有结构。因为属性和复杂关系通常是由中介节点如空白节点连接的或抽象的实体建模时根据RDF形式主义,RESCAL的这种集体学习能力是语义网学习的一个非常重要的特性。下面的章节将更详细地介绍RESCAL算法,将讨论RDF(S)数据如何在RESCAL中被建模为一个张量,并将介绍一些对算法的新扩展。
语义Web数据建模
让关系域由实体和二元关系类型组成。使用RESCAL,将这些数据建模为一个大小为n×n×m的三向张量X,其中张量的两个模态上的项对应于话语域的组合实体,而第三个模态拥有m不同类型的关系。张量项Xijk= 1表示存在第k个关系(第i个实体,第j个实体)。否则,对于不存在的或未知的关系,Xijk被设置为零。通过这种方式,RESCAL通过假设缺失的三元组很可能不是真的来解决从积极的例子中学习的问题,这种方法在高维但稀疏的领域中是有意义的。图1a显示了这种建模方法的说明。每个额片Xk=X:,:,k (X)可以解释为对应关系k的关系图的邻接矩阵。
设一个关系域由n个实体和m个关系组成。使用RESCAL,将这类数据建模为一个大小为n×n×m的三向张量X,其中张量的两个模态上的项对应于话语域的组合实体,而第三个模态包含m种不同类型的关系。张量项Xijk= 1表示存在第k个关系(第i个实体,第j个实体)。否则,对于不存在的或未知的关系,Xijk被设置为零。通过这种方式,RESCAL通过假设缺失的三元组很可能不是真的来解决从积极的例子中学习的问题,这种方法在高维但稀疏的领域中是有意义的。图1a显示了这种建模方法的说明。每个切片Xk=X:,:,k 可以解释为对应关系k的关系图的邻接矩阵。
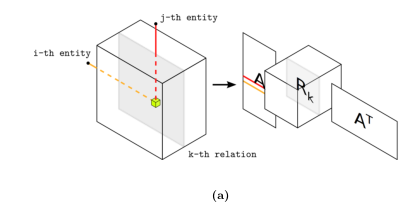

为RDF(S)数据创建这样一个张量表示非常简单。实体由数据中所有资源、类和空白节点的集合给出,而关系集由包含实体-实体关系的所有谓词组成。对于每个现有的三元组(第i个实体、第k个关系、第j个实体),对应的条目Xijk被设置为1,否则它被设置为0。由于原始的RESCAL模型假设三种模式中的两种是由实体定义的,因此这个过程受限于资源。然而,LOD云中的许多信息都是以文字值的形式给出的。因此,我们在第3.5节中提出了对RESCAL的有效扩展,这样实体的属性,即文字值,可以包含在分解中。
给定一个规模为n×n×m的张量X,RESCAL计算X的因数分解,使得X的每个切片Xk被因数分解成矩阵积
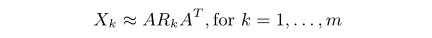
其中A是n×r矩阵,Rk是一个完整的、非对称的r×r矩阵,r是给定的参数,指定潜在成分或因子的数量,n是实体数量。通过求解优化问题,计算出因子矩阵A和Rk
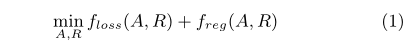
其中:
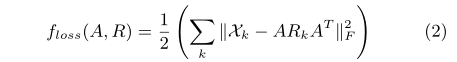
freg是正则化项
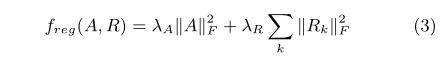
这是为了防止模型的过拟合。
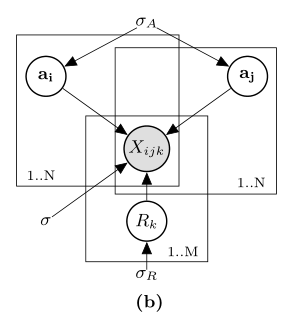
RESCAL可以看作是一个多关系数据的潜在变量模型。(1)通过隐特征向量ai、aj和Rk对观测变量Xijk进行解释。图1b的图形模型说明了这种解释。在该模型中,ai和aj是第i和第j个实体用潜分量表示,即A的列,这些潜分量是通过因子分解得到的,用来解释观测变量。此外,A的另一种解释是将实体嵌入到向量 空间,其中实体在该空间中的相似性反映了它们在关系领域中的相似性。另一方面,Rk模拟了第k个关系中潜在成分的相互作用。
为了求解(1)提出了一个有效的交替最小二乘算法,它迭代地更新A和Rk,直到满足收敛准则。在下文中,我们将该算法称为RESCAL-ALS。详细地说,A和R的更新通过
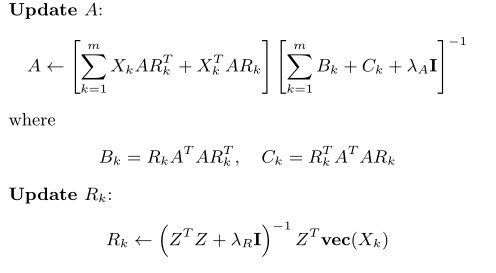
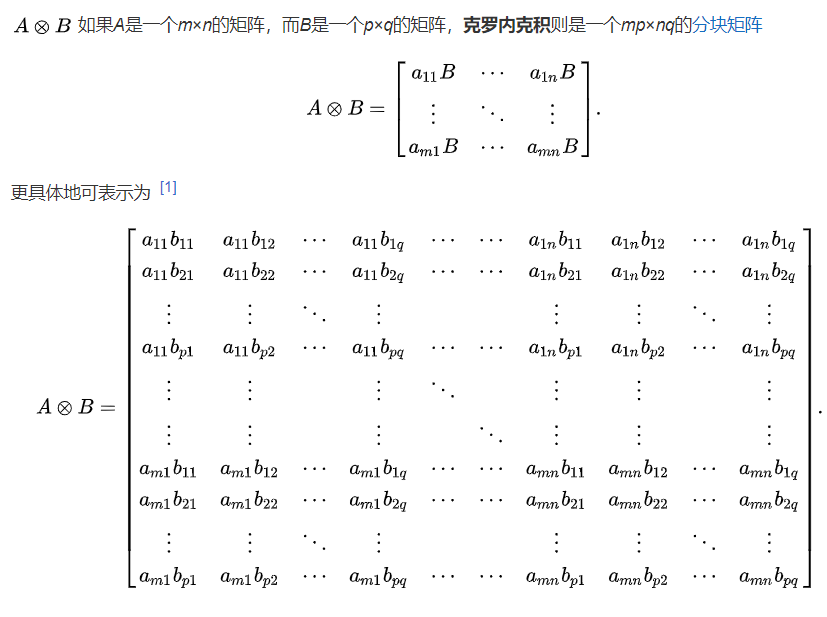
其中Z=AT⊗AT和⊗为克罗内克积。
然而,以这种形式计算Rk的更新步骤对于大规模数据来说很棘手,因为它涉及r2×n2矩阵Z。幸运的是,与ASALSAN算法类似,可以使用A的QR分解来显著简化Rk的更新步骤。基本思想是对每个Rk最小化一个等价于(2)的函数,即
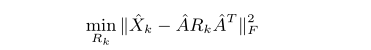
其中A=QTˆA为A的QR分解结果,ˆXk=QTXkQ。在更新Rk时使用ˆXk和ˆA代替A和Xk,这一步现在只依赖于潜在分量的数量,因为ˆA和ˆXk只是r×r矩阵。
远古论文,没有找到其实验结果,论文中剩余部分为对于集体学习和模型复杂度的讨论。
论文地址:https://www.dbs.ifi.lmu.de/~tresp/papers/p271.pdf
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/200839.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
