大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
序列化/反序列化机制
将对象转化为字节来进行存储称之为序列化;将字节还原会对象的过程称之为反序列化
java中的序列化反序列化机制:需要利用原生流来实现,Serializable(该对象可以进行序列化/反序列化),static/transient(被修饰之后不能序列化/反序列化),serialVersionUID(版本号,如果版本号对上了再进行序列化/反序列,如果对不上,不进行序列化/反序列化)
原生机制缺点:
- 效率低
- 占用空间比较大:将类以及对象中的信息全部输出
- 兼容性较差:只能支持java使用
Avro-大数据通用的序列化器
简介
Apache Avro(以下简称 Avro)是一种与编程语言无关的序列化格式。Doug Cutting 创建了这个项目,目的是提供一种共享数据文件的方式。
Avro 数据通过与语言无关的 schema 来定义。schema 通过 JSON 来描述,数据被序列化成二进制文件或 JSON 文件,不过一般会使用二进制文件。Avro 在读写文件时需要用到 schema,schema 一般会被内嵌在数据文件里。
是Apache的开源项目。(天然支持Hadoop)
利用固定格式的文件(.avsc)来实现不同平台之间的解析操作。
Avro支持类型
Avro简单格式列表(8种)
| 原生类型 | 说明 |
|---|---|
| null | 表示没有值 |
| boolean | 表示一个二级制布尔值 |
| int | 表示32位有符号整数 |
| long | 表示64位有符号整数 |
| float | 表示32位单精度浮点数 |
| double | 表示64位双精度浮点数 |
| bytes | 表示8位无符号字节序列 |
| string | 表示字符序列 |
Avro复杂格式列表(6种)
| 复杂类型 | 属性 | 说明 |
|---|---|---|
| Records | type name | record |
| name(必有属性) | a JSON string | |
| type (必有属性) | a schema/a string of defined record | |
| fields(必有属性) | a JSON array, listing fields (required) | |
| namespace | a JSON string that qualifies the name(optional) | |
| doc | a JSON string providing documentation to the user of this schema (optional) | |
| aliases | a JSON array of strings, providing alternate names for this record (optional) | |
| default | a default value for field when lack | |
| order | ordering of this field. | |
| Enum | type name | enum |
| name(必有属性) | a JSON string | |
| symbols(必有属性) | a JSON array, listing symbols, as JSON strings (required). All symbols in an enum must be uniqu | |
| namespace | a JSON string that qualifies the name(optional) | |
| doc | a JSON string providing documentation to the user of this schema (optional) | |
| aliases | a JSON array of strings, providing alternate names for this record (optional) | |
| Arrays | type name | array |
| items | the schema of the array’s items | |
| Maps | type name | map |
| values | the schema of the map’s values( eg:{“type”: “map”, “values”: “long”} ) | |
| Fixed | type name | fixed |
| name(必有属性) | a string naming this fixed (required) | |
| namespace | a JSON string that qualifies the name(optional) | |
| aliases | a JSON array of strings, providing alternate names for this record (optional) | |
| size | aan integer, specifying the number of bytes per value (required) |
Test.avsc文件 所有格式实例
说明:Test.avsv文件,利用avro的插件可生成对应的Test类,这个类可以利用avro的API序列化/反序列化
{
"namespace": "avro.domain",
"type": "record",
"name": "Test",
"fields": [
{
"name": "stringVar", "type": "string"},
{
"name": "bytesVar", "type": ["bytes", "null"]},
{
"name": "booleanVar", "type": "boolean"},
{
"name": "intVar", "type": "int", "order":"descending"},
{
"name": "longVar", "type": ["long", "null"], "order":"ascending"},
{
"name": "floatVar", "type": "float"},
{
"name": "doubleVar", "type": "double"},
{
"name": "enumVar", "type": {
"type": "enum", "name": "Suit", "symbols" : ["SPADES ", "HEARTS", "DIAMONDS", "CLUBS"]}},
{
"name": "strArrayVar", "type": {
"type": "array", "items": "string"}},
{
"name": "intArrayVar", "type": {
"type": "array", "items": "int"}},
{
"name": "mapVar", "type": {
"type": "map", "values": "long"}},
{
"name": "fixedVar", "type": {
"type": "fixed", "size": 16, "name": "md5"}}
]
}
利用AVRO定义avdl文件,生成类
avdl文件用于avro生成协议方法的。
实现步骤:
- 创建maven项目
- 添加pom依赖
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<!--日志依赖-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.6.4</version>
<scope>compile</scope>
</dependency>
<dependency>
<!-- avro的依赖 -->
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-ipc</artifactId>
<version>1.7.5</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
</plugin>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.7.5</version>
<executions>
<execution>
<id>schemas</id>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
<goal>protocol</goal>
<goal>idl-protocol</goal>
</goals>
<configuration>
<!--存放avsc文件的地址-->
<sourceDirectory>${
project.basedir}/src/main/avro/</sourceDirectory>
<!--生成源码的地址-->
<outputDirectory>${
project.basedir}/src/main/java/</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
- 在src\main\avro目录下新建一个后缀为avsc的文件,比如User.avsc文件
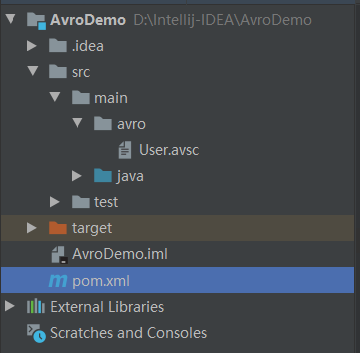

- 根据avro格式要求以及业务要求编辑这个文件(这里只做简单的示范)
{
"namespace":"avro.pojo",
"type":"record",
"name":"User",
"fields":
[
{"name":"name","type":"string"},
{"name":"age","type":"int"}
]
}
- 生成代码
eclipse:(项目名右键)
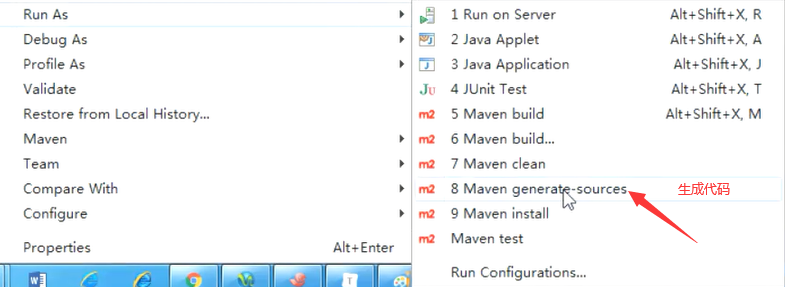 idea:
idea:
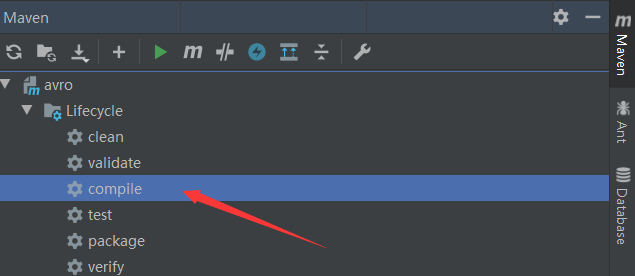 就会在指定的目录下生成类:
就会在指定的目录下生成类:
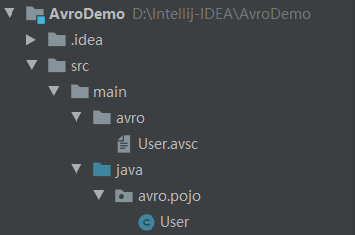
这里生成的代码就不贴了,可以自己生成之后进行查看!
对实体类简单的调用
// User user = new User();
// user.setName("鲁智深");
// user.setAge(18);
// User user = new User("史进", 80);
// User user = User.newBuilder().setName("公孙胜").setAge(150).build();
// 利用原对象构建新对象
// 实际上底层是调用的clone方法来进行克隆
User user = User.newBuilder(new User("李逵", 80)).setAge(70).build();
System.out.println(user);
序列化
public void write() throws IOException {
User user = new User("Amy", 40);
DatumWriter<User> dw = new SpecificDatumWriter<>(User.class);
DataFileWriter<User> dfw = new DataFileWriter<>(dw);
// 指定写出文件
dfw.create(user.getSchema(), new File("1.txt"));
dfw.append(user);
dfw.append(new User("Sam", 70));
dfw.append(new User("Bob", 70));
dfw.close();
}
反序列化
public void read() throws IOException {
DatumReader<User> dr = new SpecificDatumReader<>(User.class);
DataFileReader<User> dfr = new DataFileReader<>(new File("1.txt"), dr);
// 提供了迭代机制来迭代读取数据
// while(dfr.hasNext()){
//
// User user = dfr.next();
// System.out.println(user);
// }
// Lambda表达式
// dfr.forEach(u -> System.out.println(u));
// 对象方法的传递
dfr.forEach(System.out::println);
dfr.close();
}
Avro天然支持RPC
Avro是基于Netty的
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/200766.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
