大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全家桶1年46,售后保障稳定
文章目录
增益模型因果与推论(Causal Inference)
常用的点击率预测模型,称为响应模型(response model),即预测用户看到商品后点击的概率。在智能营销的发放优惠券场景下也可以使用这种模型,即用户看到优惠券后购买商品的概率。但在这种场景下,很自然会想到,用户是本来就有购买的意愿还是因为发放了优惠券诱使用户购买?对有发放优惠券这种有成本的营销活动,我们希望模型触达的是优惠券敏感的用户,即发放的优惠券促使用户购买,而对优惠券不敏感的用户——无论是否发券都会购买——最好不要发券,节省成本。营销活动中,对用户进行干预称为treatment,例如发放优惠券是一次treatment。我们可以将用户分为以下四类:
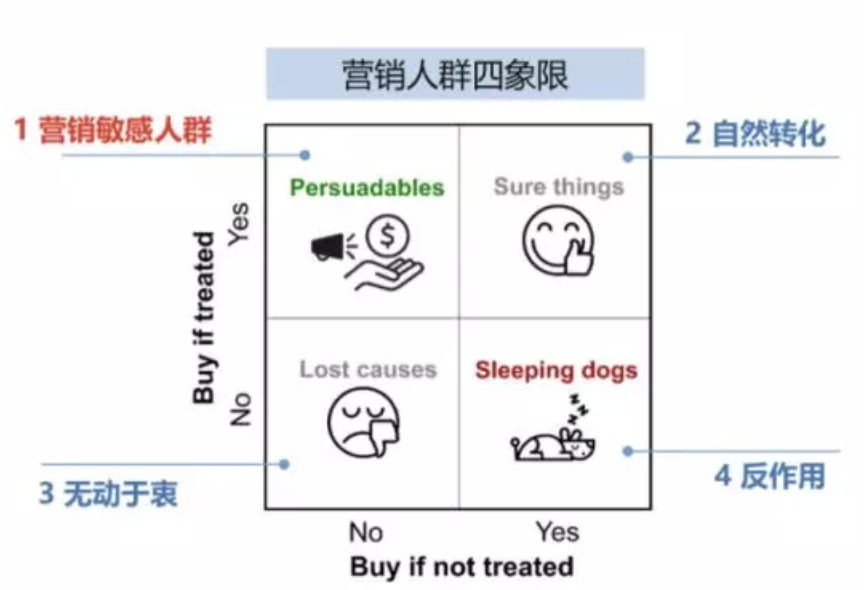

- persuadables不发券就不购买、发券才会购买的人群,即优惠券敏感人群
- sure thing:无论是否发券,都会购买,自然转化
- lost causes:无论是否发券都不会购买,这类用户实在难以触达到,直接放弃
- sleeping dogs:与persuadables相反,对营销活动比较反感,不发券的时候会有购买行为,但发券后不会再购买。
建模时主要针对persuadables人群,并且要避免sleeping dogs人群。如果使用reponse model,则难以区分这几类人群,因为模型只预测是否购买,但人群的区分需要明确是否因为发放优惠券才导致了购买行为,这是一个因果推论问题(causal inference)。在优惠券发放Demo一节可以看到,response model(一个预测模型)可以取得很好的效果(转化率很高),但转化的用户中persuadable的比例相当少,并不是营销中的target。
营销活动中,我们要预测的是某种干预(treatment)的增量,这种模型称为增益模型(uplift model)。设 G G G表示某种干预策略(如是否推送广告), X \boldsymbol{X} X表示用户特征, Y = 1 Y=1 Y=1表示用户输出的正向结果(如下单或点击):
- Reponse model: P ( Y = 1 ∣ X ) P(Y = 1 | \boldsymbol{X}) P(Y=1∣X),看过广告之后购买的概率
- uplift model: P ( Y = 1 ∣ X , G ) P(Y = 1 | \boldsymbol{X}, G) P(Y=1∣X,G),因为广告而购买的概率
增益模型的表示
假设有 N N N个用户, Y i ( 1 ) Y_i(1) Yi(1)表示我们对用户 i i i干预后的结果,比如给用户 i i i发放优惠券后(干预)用户下单(结果), Y i ( 0 ) Y_i(0) Yi(0)表示没有对用户干预的情况下用户的输出结果,比如没有给用户 i i i发放优惠券(干预),用户下单(结果)。用户 i i i的因果效应(causal effect)的计算如下:
τ i = Y i ( 1 ) − Y i ( 0 ) (1) \tau_i = Y_i(1) – Y_i(0) \tag{1} τi=Yi(1)−Yi(0)(1)
增益模型的目标就是最大化 τ i \tau_i τi,这是一个增量,即有干预策略相对于无干预策略的提升,简单讲就是干预前后结果的差值。实际使用时会取所有用户的因果效应期望的估计值来衡量整个用户群的效果,称为条件平均因果效应(Conditional Average Treatment Effect, CATE):
C A T E : τ ( X i ) = E [ Y i ( 1 ) ∣ X i ] − E [ Y i ( 0 ) ∣ X i ] (2) CATE: \tau(X_i) = E\left[Y_i(1) | X_i\right] – E\left[Y_i(0) | X_i\right] \tag{2} CATE:τ(Xi)=E[Yi(1)∣Xi]−E[Yi(0)∣Xi](2)
上式中 X i X_i Xi是用户 i i i的特征,所谓的conditional指基于用户特征。
(2)式是理想的uplift计算形式,实际上,对用户 i i i我们不可能同时观察到使用策略(treatment)和未使用策略(control)的输出结果,即不可能同时得到 Y i ( 1 ) Y_i(1) Yi(1)和 Y i ( 0 ) Y_i(0) Yi(0)。因为对某个用户,我们要么发优惠券,要么不发。将(2)式修改一下:
Y i o b s = W i Y i ( 1 ) + ( 1 − W i ) Y i ( 0 ) (3) Y_i^{obs} = W_i Y_i(1) + (1-W_i)Y_i(0) \tag{3} Yiobs=WiYi(1)+(1−Wi)Yi(0)(3)
其中 Y i o b s Y_i^{obs} Yiobs是用户 i i i可以观察到的输出结果, W i W_i Wi是一个二值变量,如果对用户 i i i使用了策略, W i = 1 W_i = 1 Wi=1,否则 W i = 0 W_i = 0 Wi=0.
在条件独立的假设下,条件平均因果效应的期望估计值是:
τ ( X i ) = E [ Y i o b s ∣ X i = x , W = 1 ] − E [ Y i o b s ∣ X i = x , W = 0 ] (4) \tau(X_i) = E\left[Y_i^{obs} | X_i = x, W = 1\right] – E\left[Y_i^{obs} | X_i = x, W = 0\right] \tag{4} τ(Xi)=E[Yiobs∣Xi=x,W=1]−E[Yiobs∣Xi=x,W=0](4)
上式要满足条件独立(CIA)的条件,即用户特征与干预策略是相互独立的。
{ Y i ( 1 ) , Y i ( 0 ) } ⊥ W i ∣ X i \lbrace Y_i(1), Y_i(0) \rbrace \perp W_i | X_i {
Yi(1),Yi(0)}⊥Wi∣Xi
实践上,满足CIA这样条件的样本的可以通过AB实验获取,因为时随机实验,可以保证用户(特征)与干预策略是相互独立的。
增益模型要优化 τ ( X i ) \tau(X_i) τ(Xi),值越高越好。然而一个用户不能同时观察到使用干预策略和不使用干预策略的结果,因此 τ ( X i ) \tau(X_i) τ(Xi)是难以直接优化的。但如果通过AB实验,可以获得使用干预策略和不使用干预策略两组人群,如果两组人群的特征分布一致,可以通过模拟两组人群的 τ ( X i ) \tau(X_i) τ(Xi)得到个体用户的 τ ( X i ) \tau(X_i) τ(Xi)。因此增益模型依赖AB实验的数据。
下面介绍三种增益模型建模方法。
差分响应模型(Two-Model Approach)
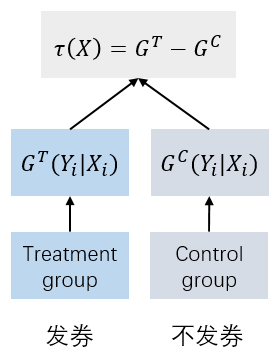
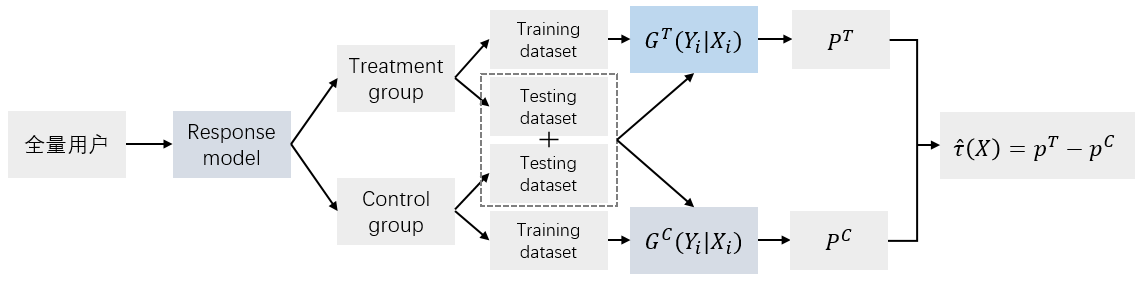
差分响应模型很直觉。分别对AB实验的实验组和对照组数据独立建模,预测时分别实验组模型和对照组模型预测用户的分数,两个模型预测分数相减就得到了uplift score。
实验组是使用干预策略的用户(treatment),对照组是未使用干预策略的用户(control),正样本都是下单用户。即分别使用两个模型优化 E [ Y i T ∣ X i T ] E\left[Y_i^T | X_i^T\right] E[YiT∣XiT]和 E [ Y j C ∣ X j C ] E\left[Y_j^C | X_j^C\right] E[YjC∣XjC],得到两个模型,分别是 G T G_T GT和 G C G_C GC。 Y i T Y_i^T YiT和 X i T X_i^T XiT分别是实验组用户 i i i的输出结果和特征, Y j C Y_j^C YjC和 X j C X_j^C XjC类似。
分别训练好两个模型之后,计算 E [ Y T ∣ X T ] − E [ Y C ∣ X C ] E\left[Y^T | X^T\right] – E\left[Y^C | X^C\right] E[YT∣XT]−E[YC∣XC]就得到了条件平均因果效应分数。这里因果效应分数是计算出来的而不是通过模型直接优化出来的,所以本质上,这还是传统的响应模型。
以优惠券发放为例,目标是用户是否下单。训练时取实验组的用户训练,正样本是下单用户,负样本是未下单用户,预测结果是每个用户下单的概率。类似地,对照组也可以使用另一个模型预测出每个用户下单的概率。两个组的用户下单概率求平均,即可得到 E [ Y T ∣ X T ] E\left[Y^T | X^T\right] E[YT∣XT]和 E [ Y C ∣ X C ] E\left[Y^C | X^C\right] E[YC∣XC],两者相减即得到 τ ( X ) \tau(X) τ(X)。
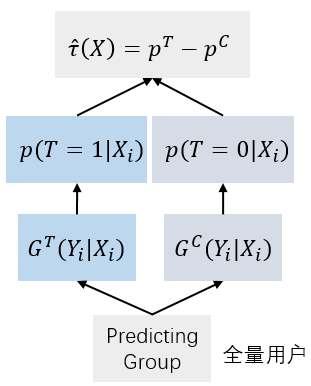
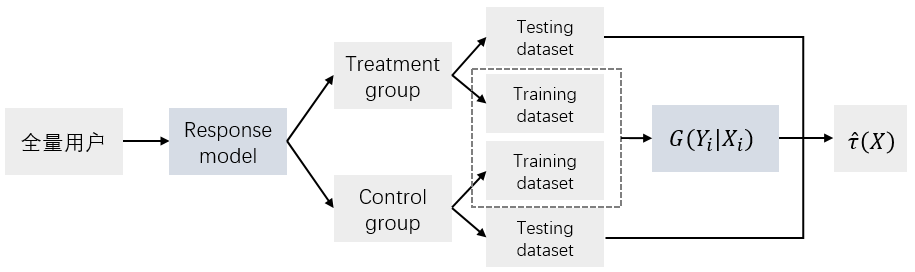
预测时,对用户分别使用 G T G_T GT和 G C G_C GC预测,两个模型预测的分数相减即得到预测用户 i i i的 τ ( X i ) \tau(X_i) τ(Xi),最后根据 τ ( X i ) \tau(X_i) τ(Xi)的高低决定是否发券。
训练时流程如下图。
预测时流程如下图,每个待预测用户都分别用 G T G_T GT和 G C G_C GC预测一遍。
模型优缺点
差分响应模型简单粗暴,还很直觉。但只是模拟了 τ ( X i ) \tau(X_i) τ(Xi),没有真正优化 τ ( X i ) \tau(X_i) τ(Xi)。两个独立的模型分开训练容易累积误差(两个独立模型的误差会累加传递到最终的uplift score)。不过考虑到实现简单迅速,实践中可以作为baseline使用。
差分响应模型升级版(One-Model Approach)
差分响应模型的训练数据和模型都是各自独立的,可以分别在训练数据层面上打通以及在模型层面上打通,得到升级版的差分响应模型。
在实验组和对照组的用户特征中,加入与 T T T有关的特征,实现数据层面的打通,即实验组和对照组合并,使用同一个模型训练。这是阿里文娱提到的一种方法,但我感觉这样无法满足用户特征样与条件策略独立的假设。
Class Transformation Method
另外一种更严谨的可以实现实验组对照组数据打通和模型打通的方法叫做class transformation method,可以直接优化 τ ( X i ) \tau(X_i) τ(Xi)。
定义一个变量 G ∈ { T , C } G \in \lbrace T, C \rbrace G∈{
T,C}, G = T G=T G=T表示有干预,即实验组(treatment), G = C G=C G=C表示无干预,即对照组(control)。uplift分数 τ \tau τ可以表示为:
τ ( X ) = P ( Y = 1 ∣ X , G = T ) − P ( Y = 1 ∣ X , G = C ) = P T ( Y = 1 ∣ X ) − P C ( Y = 1 ∣ X ) (5) \begin{aligned} \tau(\boldsymbol{X}) &= P(Y=1 | \boldsymbol{X}, G=T) – P(Y=1 | \boldsymbol{X}, G=C) \\ &= P^T (Y=1 | \boldsymbol{X}) – P^C (Y=1 | \boldsymbol{X}) \end{aligned} \tag{5} τ(X)=P(Y=1∣X,G=T)−P(Y=1∣X,G=C)=PT(Y=1∣X)−PC(Y=1∣X)(5)
上式中 X \boldsymbol{X} X表示用户特征, P T P^T PT表示用户在实验组中下单的概率(输出结果为positive), P C P^C PC表示用户在对照组中下单的概率(输出结果也为positive),uplift score就是两个概率的差值。
为了统一表示实验组和对照组都下单的情况( Y = 1 Y=1 Y=1),再定义一个变量 Z Z Z, Z ∈ { 0 , 1 } Z \in \lbrace 0, 1 \rbrace Z∈{
0,1}:
Z = { 1 if G = T and Y = 1 1 if G = C and Y = 0 0 otherwise \begin{aligned} Z = \begin{cases} 1 & \text{if $G = T$ and $Y = 1$} \\ 1 & \text{if $G = C$ and $Y = 0$} \\ 0 & \text{otherwise} \end{cases} \end{aligned} Z=⎩⎪⎨⎪⎧110if G=T and Y=1if G=C and Y=0otherwise
下面证明优化(5)式相当于优化 P ( Z = 1 ∣ X ) P (Z=1 | \boldsymbol{X}) P(Z=1∣X)。
假设干预策略 G G G与用户相互独立,即 G G G独立于 X \boldsymbol{X} X: P ( G ∣ X ) = P ( G ) P(G | \boldsymbol{X}) = P(G) P(G∣X)=P(G),(5)式可以转写为:
P ( Z = 1 ∣ X ) = P ( Z = 1 ∣ X , G = T ) P ( G = T ∣ X ) + P ( Z = 1 ∣ X , G = C ) P ( G = C ∣ X ) = P ( Y = 1 ∣ X , G = T ) P ( G = T ∣ X ) + P ( Y = 0 ∣ X , G = C ) P ( G = C ∣ X ) = P T ( Y = 1 ∣ X ) P ( G = T ) + P C ( Y = 0 ∣ X ) P ( G = C ) (6) \begin{aligned} P (Z=1 | \boldsymbol{X}) &= P(Z=1 | \boldsymbol{X}, G = T) P(G=T | \boldsymbol{X}) + P(Z=1 | \boldsymbol{X}, G = C) P(G=C | \boldsymbol{X}) \\ &= P(Y=1 | \boldsymbol{X}, G = T) P(G=T | \boldsymbol{X}) + P(Y=0 | \boldsymbol{X}, G = C) P(G=C | \boldsymbol{X}) \\ &= P^T(Y=1 | \boldsymbol{X}) P(G=T) + P^C(Y=0 | \boldsymbol{X}) P(G=C) \end{aligned} \tag{6} P(Z=1∣X)=P(Z=1∣X,G=T)P(G=T∣X)+P(Z=1∣X,G=C)P(G=C∣X)=P(Y=1∣X,G=T)P(G=T∣X)+P(Y=0∣X,G=C)P(G=C∣X)=PT(Y=1∣X)P(G=T)+PC(Y=0∣X)P(G=C)(6)
注意到 P ( G = T ) P(G=T) P(G=T)和 P ( G = C ) P(G=C) P(G=C)是可以通过AB实验控制的,在随机化实验中,如果实验组和对照组的人数是相等的,那么 P ( G = T ) = P ( G = C ) = 1 2 P(G=T) = P(G=C) = \frac{1}{2} P(G=T)=P(G=C)=21 ,即一个用户被分在实验组(有干预策略)和被分在对照组(无干预策略)的概率是相等的。 在该假设下,(6)式可以改写为:
2 P ( Z = 1 ∣ X ) = P T ( Y = 1 ∣ X ) + P C ( Y = 0 ∣ X ) = P T ( Y = 1 ∣ X ) + 1 − P C ( Y = 1 ∣ X ) (7) \begin{aligned} 2P(Z=1|\boldsymbol{X}) &= P^T(Y=1 | \boldsymbol{X}) + P^C(Y=0 | \boldsymbol{X}) \\ &= P^T(Y=1 | \boldsymbol{X}) + 1 – P^C(Y=1 | \boldsymbol{X}) \end{aligned} \tag{7} 2P(Z=1∣X)=PT(Y=1∣X)+PC(Y=0∣X)=PT(Y=1∣X)+1−PC(Y=1∣X)(7)
由(7)式可得:
τ ( X ) = P T ( Y = 1 ∣ X ) − P C ( Y = 1 ∣ X ) = 2 P ( Z = 1 ∣ X ) − 1 (8) \begin{aligned} \tau(\boldsymbol{X}) &= P^T(Y=1 | \boldsymbol{X}) – P^C(Y=1 | \boldsymbol{X}) \\ &= 2P(Z=1|\boldsymbol{X}) -1 \end{aligned} \tag{8} τ(X)=PT(Y=1∣X)−PC(Y=1∣X)=2P(Z=1∣X)−1(8)
(8)式就是要计算的uplift score,此时只有 Z Z Z一个变量,可以直接对 Z = 1 Z=1 Z=1这建模,相当于优化 P ( Z = 1 ∣ X ) P(Z=1|\boldsymbol{X}) P(Z=1∣X),而不需要分别对实验组( P T P^T PT)和对照组( P C P^C PC)单独建模。而 P ( Z = 1 ∣ X ) P(Z=1|\boldsymbol{X}) P(Z=1∣X)可以通过任何分类模型得到,所以这个方法称为Class Transformation Method. 实际上, Z = 1 Z=1 Z=1就是实验组中下单的用户和对照组中未下单的用户,因此可以直接将实验组和对照组用户合并,使用一个模型建模,实现了数据层面和模型层面的打通。预测时,模型预测的结果就是uplift score,这点与差分响应模型不同。
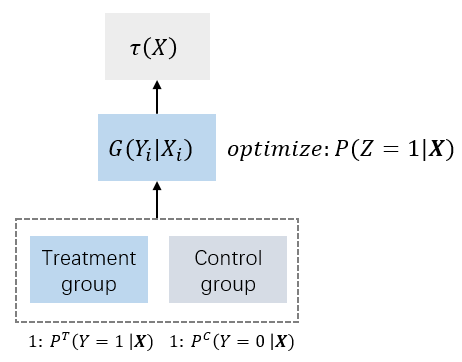
Class Transformation的两个假设
注意到该方法有两个假设,
- G G G与 X \boldsymbol{X} X相互独立
- P ( G = T ) = P ( G = C ) = 1 2 P(G=T) = P(G=C) = \frac{1}{2} P(G=T)=P(G=C)=21
第一个假设很好理解,实践中保证用户特征与干预策略无关即可。第二个假设过于严格,难以在实践中每次都满足。但是可以通过重采样使得数据满足该假设,即使不满足(经常会有对照组数量远远小于实验组的情况),根据(6)式,训练数据的不平衡影响的只是 P ( G = T ) P(G=T) P(G=T)和 P ( G = C ) P(G=C) P(G=C)的权重(原来的权重是1:1),如果模型结果有意义,并且如果在测试集和线上表现良好,那么也不一定非要满足 P ( G = T ) = P ( G = C ) = 1 2 P(G=T) = P(G=C) = \frac{1}{2} P(G=T)=P(G=C)=21的假设,实践中都是结果导向。
Modeling Uplift Directly
除了Class Transformation可以直接对uplift建模外,还有另外一种直接优化uplift的方法,主要用于树模型,该方法直接修改树模型的特征分裂计算方法。常用的特征分裂指标是信息增益(information gain): Δ g a i n = i n f o a f t e r ( D ) − i n f o b e f o r ( D ) \Delta_{gain} = info_{after}(D) – info_{befor}(D) Δgain=infoafter(D)−infobefor(D),可以直接改为: Δ g a i n = D a f t e r ( P T , P C ) − D b e f o r ( P T , P C ) \Delta_{gain} = D_{after}(P^T, P^C) – D_{befor}(P^T, P^C) Δgain=Dafter(PT,PC)−Dbefor(PT,PC)。
其中 D b e f o r ( P T , P C ) D_{befor}(P^T, P^C) Dbefor(PT,PC)和 D a f t e r ( P T , P C ) D_{after}(P^T, P^C) Dafter(PT,PC)分别是分裂前后treatment和control样本的分布,可以用KL散度(KL divergence)、欧氏距离或者卡方距离来刻画这样的分布。
该方法可以直接对uplift建模,理论上精度会很高,但实际应用上除了修改分裂规则外,还需修改loss函数、剪枝算法等,成本较高。
增益模型的评估
响应模型可以通过一个测试数据集来计算precision,recall和AUC,但因为增益模型中不可能同时观察到同一用户在不同干预策略下的响应,因此无法直接计算上述评价指标。增益模型通常都是通过划分十分位数(decile)来对齐实验组和对照组数据,间接评估,而不是在一个测试集上直接评估。
uplift 柱状图
测试集上,实验组和对照组的用户分别按照uplift由高到低排序,划分为十等份,即十分位(decile),分别是top 10%用户,top 20%用户……top 100%用户。分别对实验组和对照组中每个十分位内的用户求 E [ Y T ∣ X T ] E\left[Y^T | X^T\right] E[YT∣XT]和 E [ Y C ∣ X C ] E\left[Y^C | X^C\right] E[YC∣XC],即预测分数的均值,然后相减,作为这个十分位bin内的uplift,绘制柱状图,如下图(这个图是由低到高排序,排序反了):
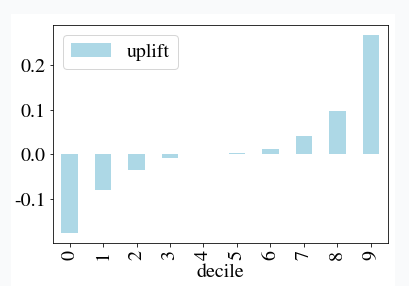
这种方法只能定性分析,无法计算出一个具体的值来整体评价模型的好坏。
Qini曲线(Qini curve)
可以在uplift bars的基础上绘制曲线,类似AUC来评价模型的表现,这条曲线称为Qini curve,计算每个百分比的Qini系数,最后将这些Qini系数连接起来,得到一条曲线。Qini系数计算如下:
Q ( ϕ ) = n t , y = 1 ( ϕ ) N t − n c , y = 1 ( ϕ ) N c (9) Q(\phi) = \frac{n_{t,y=1}(\phi)}{N_t} – \frac{n_{c,y=1}(\phi)}{N_c} \tag{9} Q(ϕ)=Ntnt,y=1(ϕ)−Ncnc,y=1(ϕ)(9)
ϕ \phi ϕ是按照uplift score由高到低排序的用户数量占实验组或对照组用户数量的比例,如 ϕ = 0.1 \phi = 0.1 ϕ=0.1,表示实验组或对照组中前10%的用户。 n t , y = 1 ( ϕ ) n_{t,y=1}(\phi) nt,y=1(ϕ)表示在 ϕ \phi ϕ下,实验组中输出结果为1(下单)的用户数量,类似地, n c , y = 1 ( ϕ ) n_{c,y=1}(\phi) nc,y=1(ϕ)表示在同样的百分数下,对照组中输出结果为1(下单)的用户数量。 N t N_t Nt和 N c N_c Nc分别表示实验组和对照组的总用户数。
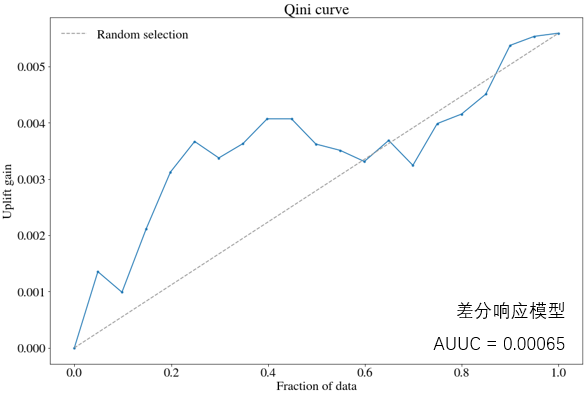
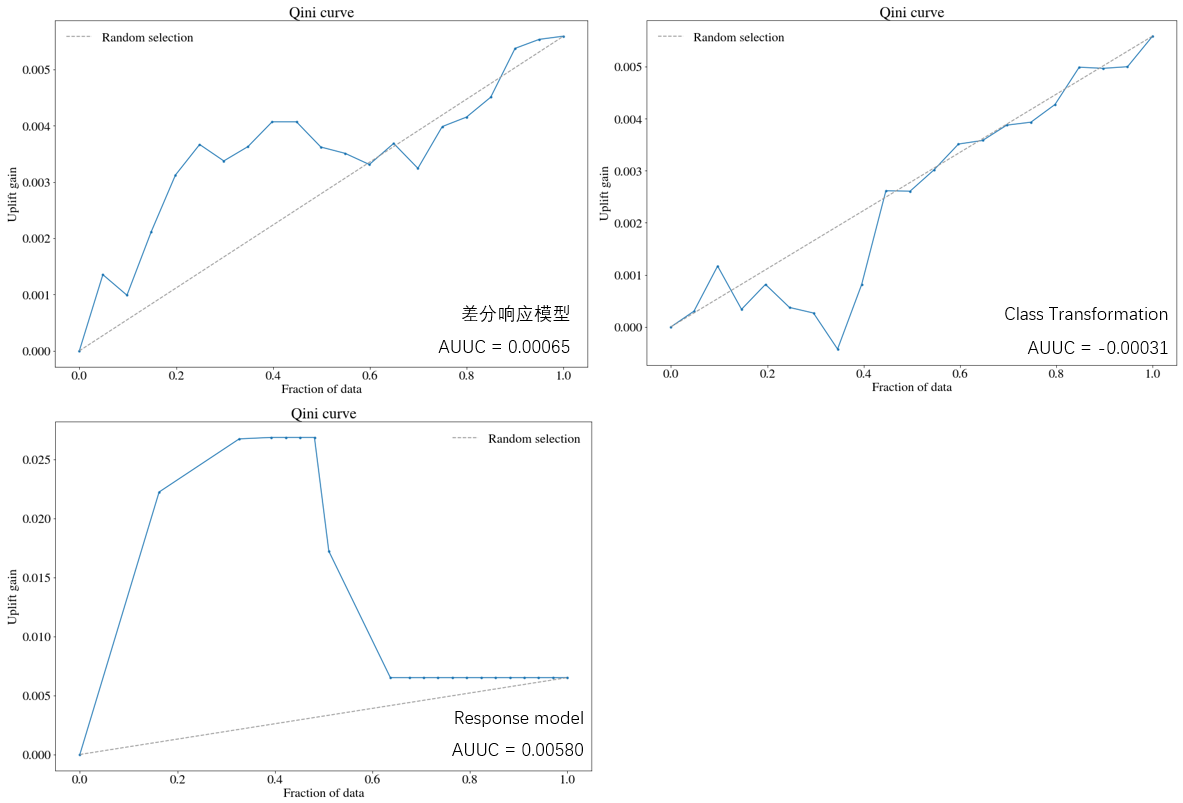
如上图,横轴等于0.2时,对应的纵轴大概是0.0032(uplift score),表示当uplift score等于0.0032时,可以覆盖前20%的用户数量,从图上看,这部分用户就是persuadable用户。
图中虚线是随机的base曲线,Qini曲线与随机random曲线之间的面积作为评价模型的指标,面积越大越好,面积越大,表示模型结果远超过随机选择的结果,与AUC类似,这个指标称为AUUC(Area Under Uplift Curve)。
Qini系数分母是实验组和对照组的全体用户数,如果两组用户数量差别比较大,结果容易失真。另一种累积增益曲线可以避免这个问题。
累积增益曲线(Cumulative Gain curve)
累积增益曲线计算如下:
G ( ϕ ) = ( n t , 1 ( ϕ ) n t ( ϕ ) − n t , 1 ( ϕ ) n t ( ϕ ) ) ( n t ( ϕ ) + n c ( ϕ ) ) (10) G(\phi) = \left( \frac{n_{t, 1}(\phi)}{n_t(\phi)} – \frac{n_{t, 1}(\phi)}{n_t(\phi)} \right) \left(n_t(\phi) + n_c(\phi) \right) \tag{10} G(ϕ)=(nt(ϕ)nt,1(ϕ)−nt(ϕ)nt,1(ϕ))(nt(ϕ)+nc(ϕ))(10)
各符号含义与Qini系数符号含义相同。其中 n t ( ϕ ) n_t(\phi) nt(ϕ)表示在 ϕ \phi ϕ百分比下,实验组(treatment)的用户数量, n c ( ϕ ) n_c(\phi) nc(ϕ)是在 ϕ \phi ϕ百分比下,对照组(control)的用户数量。与Qini系数相比,累积增益的分母是百分比 ϕ \phi ϕ下的实验组或对照组人数,并乘以 n t ( ϕ ) + n c ( ϕ ) n_t(\phi) + n_c(\phi) nt(ϕ)+nc(ϕ)作为全局调整系数,避免实验组和对照组用户数量不平衡导致的指标失真问题。
可以将累积增益曲线与random line之间的面积作为评价模型表现的指标。
优惠券发放Demo
这里有一个优惠券发放的例子 。这是一次优惠券发放活动,对用户以短信方式发放5折优惠券,本次活动实验组(treatement,短信方式发送5折优惠券),对照组(不发券)37701名用户,注意到实验组和对照组不满足 P ( T ) = P ( C ) = 1 2 P(T) = P(C) = \frac{1}{2} P(T)=P(C)=21的条件。
这个例子还有一点特别,这其实是在一个预测模型上再做一次uplift modeling。本身实验组和对照组的数据是通过一个XGB模型预测出来的用户,该模型预测用户领取优惠券后是否会下单。根据模型预测结果,筛选一批高于某个阈值的用户,分成实验组和对照组。因此这次AB结果本身可以看出这个预测模型的uplift score。
这个预测模型的AB实验中,实验组转化率是2.69%,对照组转化率是2.28%,两组的转化率远高于以往运营随机筛选或根据条件筛选用户的转化率。但是,注意到这个预测模型的uplift score只有0.0041(2.69%-2.28%)。说明预测模型筛选出来的用户本身就有下单意愿,并不一定是因为发放优惠券而下单,所以实验组中的用户persuadable的比例应该不是很高。
在一个预测模型上再做uplift modeling相当于是在下单意愿高的用户中再筛选persuadable用户,其实实践上没有太大必要。但是作为一个例子,数据还是比较完美的,而且实验组和对照都通过同一个预测模型筛选而来,然后再随机分组,是满足uplift modeling条件的。
差分响应模型
实验组和对照组分别建模,使用lightGBM模型,分别取80%数据为训练集,20%数据为测试集。两个模型在测试集上的表现如下(未调参):
| 模型 | 类别 | Precision | Recall | f1-score | support |
|---|---|---|---|---|---|
| G T G_T GT | 0 | 0.98 | 0.97 | 0.98 | 7785 |
| G T G_T GT | 1 | 0.16 | 0.20 | 0.18 | 215 |
| G C G_C GC | 0 | 0.98 | 0.99 | 0.98 | 8737 |
| G C G_C GC | 1 | 0.13 | 0.07 | 0.09 | 190 |
方便起见,将实验组和对照组20%的测试数据合并作为整个uplift model的测试集,流程如下。使用的数据集是经过了response model预测后的结果,相当于先筛选了一批下单概率高的用户,因为实验组和对照组用户都来自于同一个response model,可以认为两组用户特征分布式相同的。实际应用时,要注意实验组和对照组的用户特征分布是否一致。
对uplift分数 τ ^ ( X ) \hat{\tau}(X) τ^(X)排序,得到uplift bar,如下图所示。横轴是测试集中每个用户uplift的十分位数(decile),共10个bin;纵轴是每个bin的uplift均值。由于uplift排序是从低到高,因此这个uplift bar看起来是反的(正常应该是从高到底排)。
Class Transformation Method
训练和测试过程如下图所示。从实验组和对照组筛选出 Z = 1 Z=1 Z=1的用户作为正样本,其余的作为负样本。同样使用lightGBM模型(未调参)。
传统响应模型
为了对比,这里生成了一份传统响应模型的结果。注意这个对比其实没有什么意义,因为这些数据本身就是一个响应模型预测的结果,再预测一次的意义不大。
响应模型使用LightGBM,正样本是下单用户,负样本是未下单用户,处理流程如下。将实验组(treatment group)切分为训练集和测试集,训练集用于训练预测模型,之后用该模型预测实验组的测试集作为 P T P^T PT,预测整个对照组的数据作为 P C P^C PC,然后计算uplift score。注意到这里实验组的测试集数量是远远少于对照组数量的,所以两边的数据量不均衡。这种方法计算出来的uplift score是模拟分数。
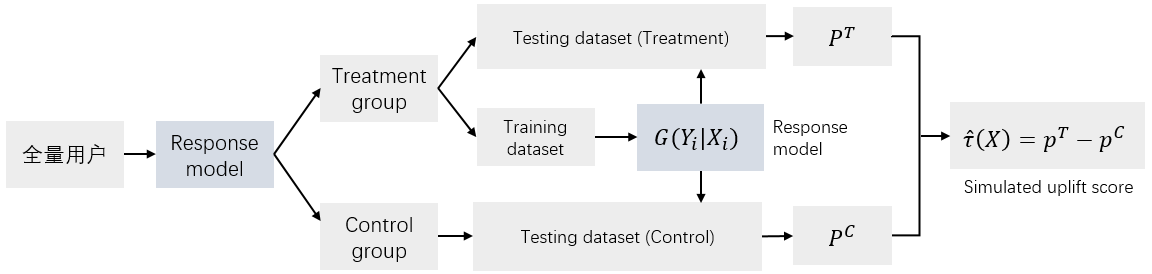
模型评估
Qini曲线图如下。
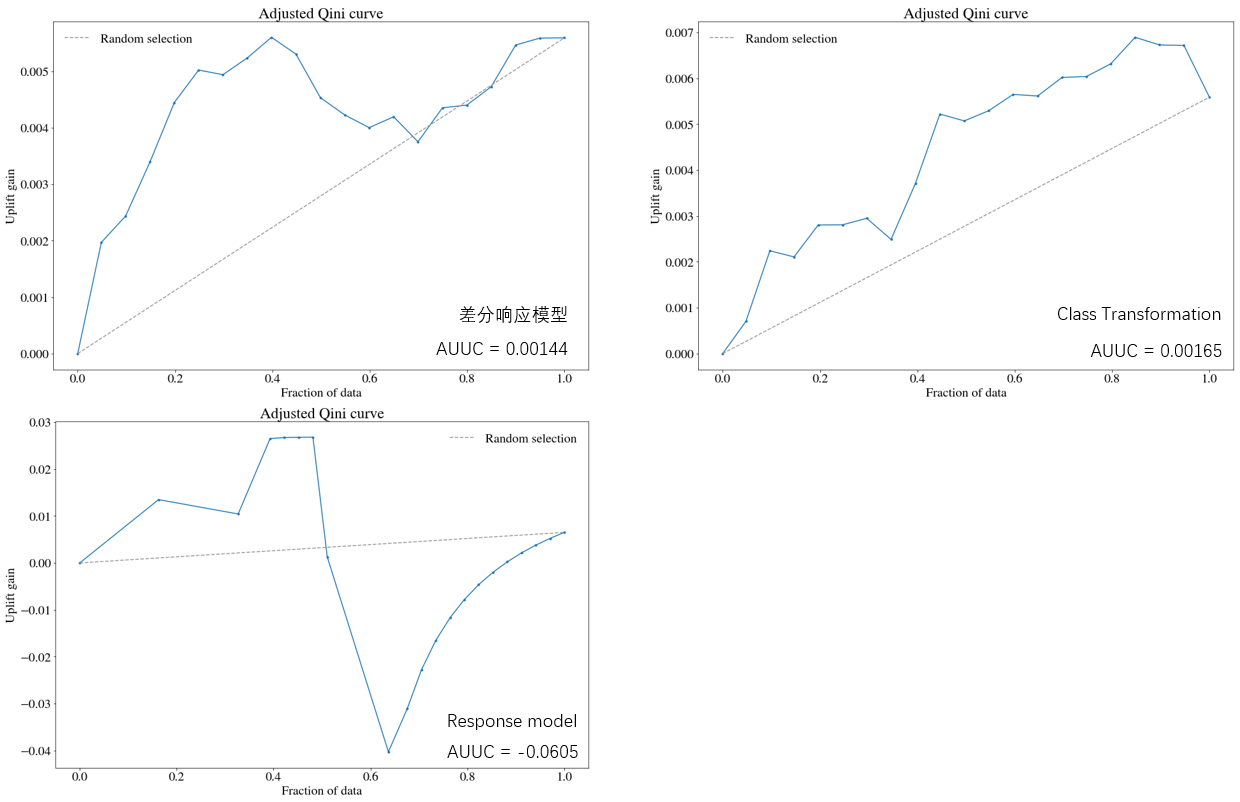
Adjusted Qini曲线如下。
Adjusted Qini是为了避免实验组和对照组数据不均衡而导致Qini系数失真而设计的。计算方式如下:
A Q i n i = n t , 1 ( ϕ ) N t − n c , 1 ( ϕ ) n t ( ϕ ) n c ( ϕ ) N t AQini = \frac{n_{t,1}(\phi)}{N_t} – \frac{n_{c,1}(\phi) n_t(\phi)}{n_c(\phi)N_t} AQini=Ntnt,1(ϕ)−nc(ϕ)Ntnc,1(ϕ)nt(ϕ)
累积增益曲线如下:
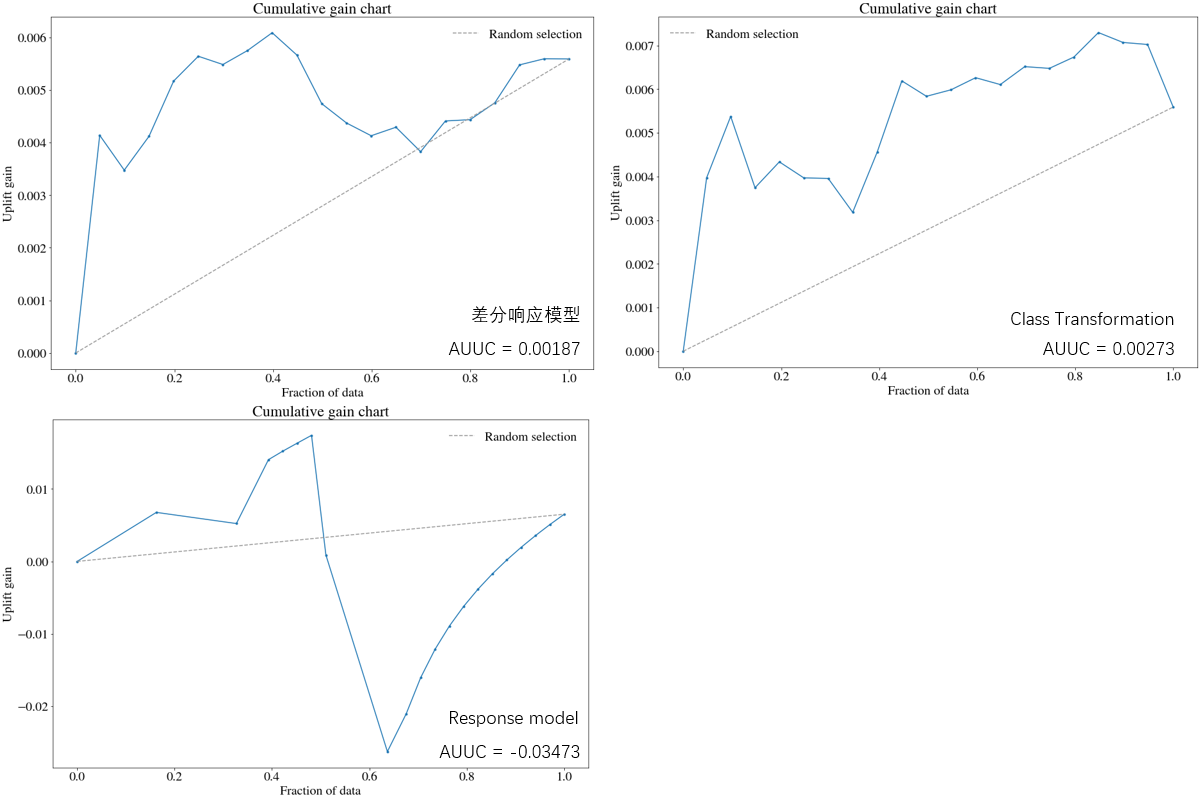
在Qini曲线下,差分响应模型的总体效果要好一些。而在累积增益曲线下,Class Transformation模型的总体效果要好一些。实验组和对照组数据不平衡的情况下,Qini系数可能有偏差,但本次对比的实验数据两组用户数量是接近的,这个问题还在研究中。
Python Uplift Modeling工具包:Pylift
Pylift是uplift建模的Python工具包。Pylift在sklearn的基础上针对uplift modeling对各模型做了一些优化,同时集成了一套uplift评价指标体系。所以Pylift内核还是sklearn,在sklearn外面封装了一套API,针对树模型做了uplift优化,可以通过Pylift实现直接的uplift modeling.
官网的示例代码如下。
from pylift import TransformedOutcome
up = TransformedOutcome(df1, col_treatment='Treatment', col_outcome='Converted')
up.randomized_search() # 对所有参数grid search,十分耗时,使用时注意限制参数searching的数量
up.fit(**up.rand_search_.best_params_)
up.plot(plot_type='aqini', show_theoretical_max=True) # 绘制aqini曲线
print(up.test_results_.Q_aqini)
所有模型的实现都通过类TransformedOutcome操作,通过传参来指定模型。默认的模型是XGBRegressor. 如果使用其他模型,通过参数sklearn_model指定,如下:
up = TransformedOutcome(df, col_treatment='Treatment', col_outcome='Converted', sklearn_model=RandomForestRegressor)
参数col_treatment是指数据集df中区分是否是treatment group的字段,通过0/1二值区分,col_treatment相当于label字段,如有转化是1,无转化是0.
Pylift另一个方便之处是提供了计算uplift评价指标的函数。如果是使用TransformedOutcome生成的结果,直接输入up.plot(plot_type='qini')即可绘制qini曲线。如果是自己的数据,可以通过下述方式来绘制曲线:
from pylift.eval import UpliftEval
upev = UpliftEval(treatment, outcome, predictions)
upev.plot(plot_type='aqini')
其中treatment标识是否treatment group,list格式;outcome相当于label,list格式;predictions是预测的uplift score分数,注意这是uplift score,如果不是uplift score需要自己先将uplift score计算好。上一小节模型评估中的图均是通过UpliftEval绘制的。
plot_type参数是绘制曲线的类型,可以绘制以下六种曲线:
qini:qini曲线aqini:修正后的qini曲线,更适应treatment group和control group数据不均衡的数据cuplift:累积uplift曲线uplift:uplift曲线,不累积cgains:累积gain曲线balance:每个百分比下,实验组目标人数除以所有人数
通过以下方式计算曲线面积:
upev.Q_aqini # aqini曲线与random line之间的面积
upev.q1_qini # qini曲线与理想曲线之间的面积
upev.q2_cgains # cgains曲线与最佳实践曲线之间的面积
理想曲线与最佳实践曲线可以参考Pylift官网。
Pylift用于实验很方便,但因为还是基于sklearn,当达到千万量级的数据量时,还是需要考虑分布式。
总结
个人理解,增益模型实际上是一大类模型框架,本质上可以用传统响应模型或其他机器学习模型嵌入增益模型的框架,但是预测结果并不是一个概率,模型评价方式也有变化。
训练样本收集
增益模型建模强依赖于AB实验,数据要求很高。建模时要求实验组和对照组样本数量一样(实践中不一定有这个严格要求)。而且实验组和对照组的样本特征分布要一致,例如,训练数据不能是实验组预测后的结果、对照组随机选择的结果这样的组合,因为这样不满足干预策略与用户特征相互独立的假设( P ( G ∣ X ) = P ( G ) P(G | \boldsymbol{X}) = P(G) P(G∣X)=P(G))。故实验组中还需要预留一部分随机选择的用户,与对照组中的用户作为模型迭代的数据,或者实验组与对照组都先经过某个策略或模型的筛选。
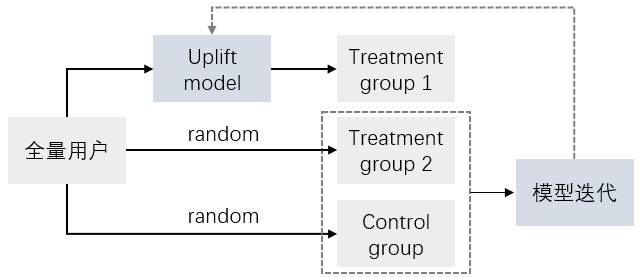
多维度建模与个性化广告推送
上述所有模型都是针对 G = T G=T G=T或者 G = C G=C G=C,即干预策略只有一种,对于发券,相当于一个treatment只有一种折扣,对于广告push,一个treatment也只能有一种内容。而treatment可以用多种维度,如不同渠道发放不同折扣的优惠券,不同场景推送不同内容的push。传统的response model以转化为多分类问题解决,但uplift modeling难以简单转化为多分类问题。
此外,个性化广告推送也依赖长期和短期的用户行为特征构建。不同营销场景下的用户特征可以共用,可以构建统一的线上线下特征平台。
Reference
- Causal Inference and Uplift Modeling: A review of the literature
- Uplift modeling for clinical trial data
- https://pylift.readthedocs.io/en/latest/introduction.html
- Pylift: A Fast Python Package for Uplift Modeling
- 阿里文娱智能营销增益模型 ( Uplift Model ) 技术实践
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/200757.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
