大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
shufflenetv1
知识的搬运工又来了
论文地址:shufflenetv1论文地址
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices。
shufflenet是一篇关于降低深度学习计算量的论文,其可以运行在手机等移动设备端,发表在了CVPR2018上
摘要
此论文是一篇效率很高的cnn框架,可以运行在移动设备端,(例如,10-150 MFLOPs)而设计的,该结构利用分组逐点卷积(pointwise group convolution)和通道重排(channel shuffle)两种新的运算方法,ShuffleNet比AlexNet实现了约13倍的实际加速
介绍
我们会发现,例如在Xception和ResNeXt,由于运算代价高昂的11卷积,在极小的网络中效率变得非常低,于是就采用了分组逐点卷积来降低11卷积的计算复杂度。为了克服分组卷积带来的副作用,我们提出了一种新的通道重排操作来帮助信息在特征通道间流动。
创新点
1.设置了分组卷积的通道重排
2.设置了shuffleNet单元
通道重排
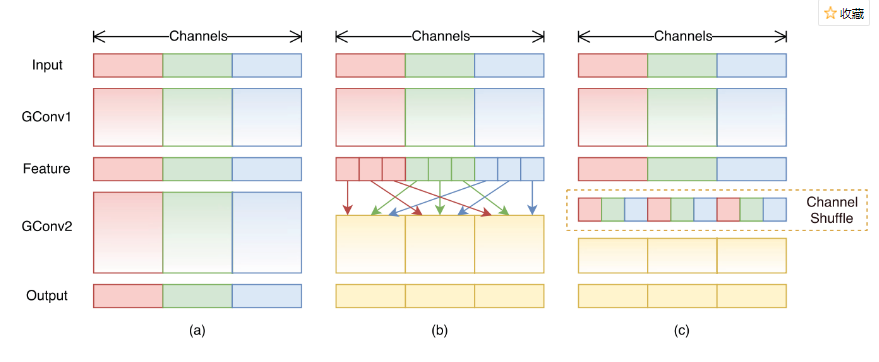

上图中,a是常规的分组卷积,但是其存在的问题是当分组比较多时,各个通道的信息就被隔离开来,此属性会阻塞通道组之间的信息流并削弱表征能力,所以我们做出了b方式的改进,将分组卷积卷积好的特征图进行通道重排,就是将分组后的特征图分成若干份,然后随机按照某一规则进行组合,组合好之后送入到下一次的卷积中,c是b的美观版本。
shuffleNet单元
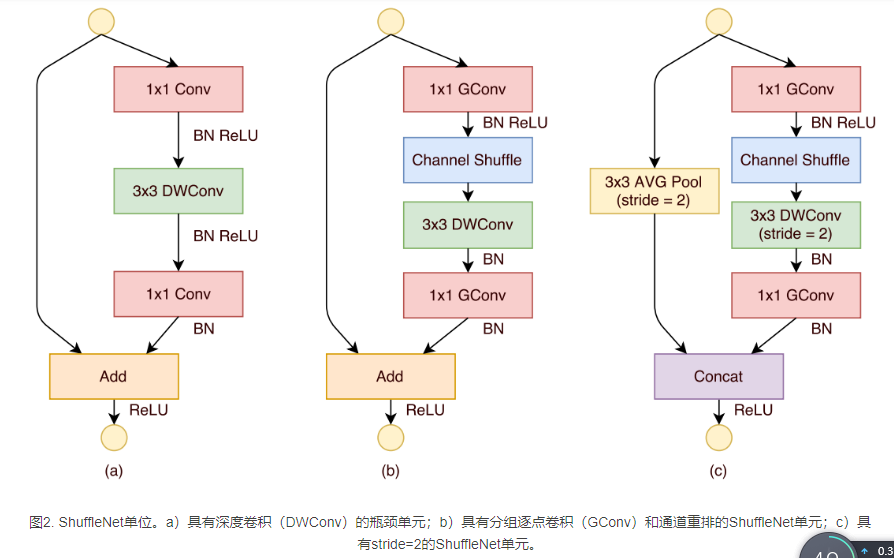
利用通道重排设计出一种专门为小型网络设计的单元块,图中a图是一种由dw卷积的残差瓶颈结构,首先进行了11卷积+BN+RELU,然后进行33dw卷积,BN+relu,最后连接了11卷积+BN,再最后接了残差连接进行了Add操作。
b:是我们设计出的string==1的shufflenet单元,首先进行了11的Gconv(分组卷积),然后接了通道重排,然后是33dw卷积,但是后边我们并没有接relu,最后再add操作。
c:我们设计出了string==2的shufflenet单元,其在残差边上使用了33的平均池化,注意最后是concat操作,而不是add操作,这样可以不增加计算量的前提下扩大特征维度,(add是通道数值相加,concat是通道堆叠)
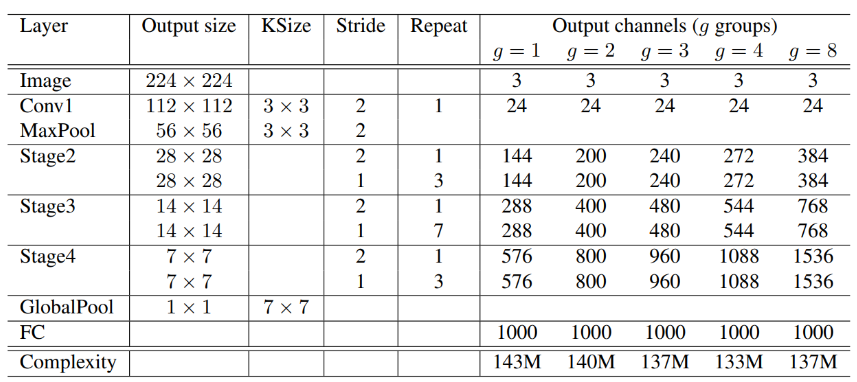
模型总体结构
代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from collections import OrderedDict
from torch.nn import init
def conv3x3(in_channels, out_channels, stride=1,
padding=1, bias=True, groups=1):
"""3x3 convolution with padding """
return nn.Conv2d(
in_channels,
out_channels,
kernel_size=3,
stride=stride,
padding=padding,
bias=bias,
groups=groups)
def conv1x1(in_channels, out_channels, groups=1):
"""1x1 convolution with padding - Normal pointwise convolution When groups == 1 - Grouped pointwise convolution when groups > 1 """
return nn.Conv2d(
in_channels,
out_channels,
kernel_size=1,
groups=groups,
stride=1)
def channel_shuffle(x, groups):
batchsize, num_channels, height, width = x.data.size()
channels_per_group = num_channels // groups# groups是分的组数
# reshape
x = x.view(batchsize, groups,
channels_per_group, height, width)
# transpose
# - contiguous() required if transpose() is used before view().
# See https://github.com/pytorch/pytorch/issues/764
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batchsize, -1, height, width)
return x
class ShuffleUnit(nn.Module):
def __init__(self, in_channels, out_channels, groups=3,
grouped_conv=True, combine='add'):
super(ShuffleUnit, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.grouped_conv = grouped_conv
self.combine = combine
self.groups = groups
self.bottleneck_channels = self.out_channels // 4
# define the type of ShuffleUnit
if self.combine == 'add':
# ShuffleUnit Figure 2b
self.depthwise_stride = 1
self._combine_func = self._add
elif self.combine == 'concat':
# ShuffleUnit Figure 2c
self.depthwise_stride = 2
self._combine_func = self._concat
# ensure output of concat has the same channels as
# original output channels.
self.out_channels -= self.in_channels
else:
raise ValueError("Cannot combine tensors with \"{}\"" \
"Only \"add\" and \"concat\" are" \
"supported".format(self.combine))
# Use a 1x1 grouped or non-grouped convolution to reduce input channels
# to bottleneck channels, as in a ResNet bottleneck module.
# NOTE: Do not use group convolution for the first conv1x1 in Stage 2.
self.first_1x1_groups = self.groups if grouped_conv else 1
self.g_conv_1x1_compress = self._make_grouped_conv1x1(
self.in_channels,
self.bottleneck_channels,
self.first_1x1_groups,
batch_norm=True,
relu=True
)
# 3x3 depthwise convolution followed by batch normalization
self.depthwise_conv3x3 = conv3x3(
self.bottleneck_channels, self.bottleneck_channels,
stride=self.depthwise_stride, groups=self.bottleneck_channels)
self.bn_after_depthwise = nn.BatchNorm2d(self.bottleneck_channels)
# Use 1x1 grouped convolution to expand from
# bottleneck_channels to out_channels
self.g_conv_1x1_expand = self._make_grouped_conv1x1(
self.bottleneck_channels,
self.out_channels,
self.groups,
batch_norm=True,
relu=False
)
@staticmethod
def _add(x, out):
# residual connection
return x + out
@staticmethod
def _concat(x, out):
# concatenate along channel axis
return torch.cat((x, out), 1)
def _make_grouped_conv1x1(self, in_channels, out_channels, groups,
batch_norm=True, relu=False):
modules = OrderedDict()
conv = conv1x1(in_channels, out_channels, groups=groups)
modules['conv1x1'] = conv
if batch_norm:
modules['batch_norm'] = nn.BatchNorm2d(out_channels)
if relu:
modules['relu'] = nn.ReLU()
if len(modules) > 1:
return nn.Sequential(modules)
else:
return conv
def forward(self, x):
# save for combining later with output
residual = x
if self.combine == 'concat':
residual = F.avg_pool2d(residual, kernel_size=3,
stride=2, padding=1)
out = self.g_conv_1x1_compress(x)
out = channel_shuffle(out, self.groups)
out = self.depthwise_conv3x3(out)
out = self.bn_after_depthwise(out)
out = self.g_conv_1x1_expand(out)
out = self._combine_func(residual, out)
return F.relu(out)
class ShuffleNet(nn.Module):
"""ShuffleNet implementation. """
def __init__(self, groups=3, in_channels=3, num_classes=1000):
"""ShuffleNet constructor. Arguments: groups (int, optional): number of groups to be used in grouped 1x1 convolutions in each ShuffleUnit. Default is 3 for best performance according to original paper. in_channels (int, optional): number of channels in the input tensor. Default is 3 for RGB image inputs. num_classes (int, optional): number of classes to predict. Default is 1000 for ImageNet. """
super(ShuffleNet, self).__init__()
self.groups = groups
self.stage_repeats = [3, 7, 3]
self.in_channels = in_channels
self.num_classes = num_classes
# index 0 is invalid and should never be called.
# only used for indexing convenience.
if groups == 1:
self.stage_out_channels = [-1, 24, 144, 288, 567]
elif groups == 2:
self.stage_out_channels = [-1, 24, 200, 400, 800]
elif groups == 3:
self.stage_out_channels = [-1, 24, 240, 480, 960]
elif groups == 4:
self.stage_out_channels = [-1, 24, 272, 544, 1088]
elif groups == 8:
self.stage_out_channels = [-1, 24, 384, 768, 1536]
else:
raise ValueError(
"""{} groups is not supported for 1x1 Grouped Convolutions""".format(num_groups))
# Stage 1 always has 24 output channels
self.conv1 = conv3x3(self.in_channels,
self.stage_out_channels[1], # stage 1
stride=2)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# Stage 2
self.stage2 = self._make_stage(2)
# Stage 3
self.stage3 = self._make_stage(3)
# Stage 4
self.stage4 = self._make_stage(4)
# Global pooling:
# Undefined as PyTorch's functional API can be used for on-the-fly
# shape inference if input size is not ImageNet's 224x224
# Fully-connected classification layer
num_inputs = self.stage_out_channels[-1]
self.fc = nn.Linear(num_inputs, self.num_classes)
self.init_params()
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal(m.weight, mode='fan_out')
if m.bias is not None:
init.constant(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant(m.weight, 1)
init.constant(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal(m.weight, std=0.001)
if m.bias is not None:
init.constant(m.bias, 0)
def _make_stage(self, stage):
modules = OrderedDict()
stage_name = "ShuffleUnit_Stage{}".format(stage)
# First ShuffleUnit in the stage
# 1. non-grouped 1x1 convolution (i.e. pointwise convolution)
# is used in Stage 2. Group convolutions used everywhere else.
grouped_conv = stage > 2
# 2. concatenation unit is always used.
first_module = ShuffleUnit(
self.stage_out_channels[stage-1],
self.stage_out_channels[stage],
groups=self.groups,
grouped_conv=grouped_conv,
combine='concat'
)
modules[stage_name+"_0"] = first_module
# add more ShuffleUnits depending on pre-defined number of repeats
for i in range(self.stage_repeats[stage-2]):
name = stage_name + "_{}".format(i+1)
module = ShuffleUnit(
self.stage_out_channels[stage],
self.stage_out_channels[stage],
groups=self.groups,
grouped_conv=True,
combine='add'
)
modules[name] = module
return nn.Sequential(modules)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
# global average pooling layer
x = F.avg_pool2d(x, x.data.size()[-2:])
# flatten for input to fully-connected layer
x = x.view(x.size(0), -1)
x = self.fc(x)
return F.log_softmax(x, dim=1)
if __name__ == "__main__":
model = ShuffleNet()
最后总结
为了评估分组逐点卷积的重要性,我们比较了具有相同复杂度的ShuffleNet模型,其组数从1到8不等。如果组数等于1,则不涉及分组逐点卷积,则ShuffleNet单元成为一个“Xception-like”结构。为了更好地理解,我们还将网络的宽度扩展到3种不同的复杂性,并分别比较它们的分类性能。结果如表2所示。
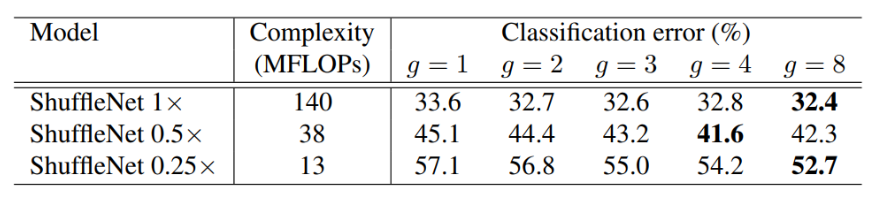
表2. 分类误差VS组数g(较小的数字代表更好的性能)
从结果中我们可以看出,有分组卷积(g>1)的模型始终比没有分组逐点卷积(g=1)的模型表现得更好,较小的模型往往从分组中获益更多。
表2还显示,对于某些模型((如ShuffleNet 0.5×),当组数变得相对较大时(例如g=8),分类分数饱和甚至下降。随着组数的增加(因此特征图的范围更广),每个卷积滤波器的输入通道变得更少,这可能会损害表示能力。有趣的是,我们也注意到,对于如ShuffleNet 0.25×这样较小的模型,**较大的组数往往会得到更好的一致性结果,这表明更宽的特征图为较小的模型带来了更多的好处。**我们在每次卷积之后都添加了一个批归一化层,使端到端的训练更加容易。**由于ShuffleNet的高效设计,我们可以在给定的计算预算下使用更多的通道,从而通常可以获得更好的性能。**浅模型仍然是明显好于相应的MobileNet,这意味着ShuffleNet的有效性主要是高效结构的结果,而不是深度。**根据经验,g=3通常在准确性和实际推理时间之间有一个适当的平衡。shufflenet比mobilenet效果要好
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/197877.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
