大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
SpringApplication的初始化
之前已经分析了引导类上的@SpringBootApplication注解,
接下来继续分析main方法,只调用了一句SpringApplication.run(SpringbootApplication.class, args),就启动了web容器,我们看看run方法里面做了什么
public static ConfigurableApplicationContext run(Class<?>[] primarySources, String[] args) {
return new SpringApplication(primarySources).run(args);
}
可以看到,这里初始化了SpringApplication并且执行了它的run方法。
从SpringApplication的构造方法开始看,SpringApplication的构造方法主要做了四件事:
- 配置源
- 推断web应用类型
- 应用上下文初始器和应用事件监听
- 推导引用主类
源码如下:
@SuppressWarnings({
"unchecked", "rawtypes" })
public SpringApplication(ResourceLoader resourceLoader, Class<?>... primarySources) {
this.resourceLoader = resourceLoader;
Assert.notNull(primarySources, "PrimarySources must not be null");
//1.配置源
this.primarySources = new LinkedHashSet<>(Arrays.asList(primarySources));
//2.推断web应用类型
this.webApplicationType = WebApplicationType.deduceFromClasspath();
//3.应用上下文初始器和应用事件监听
setInitializers((Collection) getSpringFactoriesInstances(ApplicationContextInitializer.class));
setListeners((Collection) getSpringFactoriesInstances(ApplicationListener.class));
//4.推导引用主类
this.mainApplicationClass = deduceMainApplicationClass();
}
配置源
配置springApplication的启动类,以java的方式配置我们是很熟悉的,直接用:SpringApplication.run(MySpringBootApplication.class, args);,其中MySpringBootApplication.class就是构造方法第二个参数的primarySources
通过XML的方式配置:
SpringApplication springApplication = new SpringApplication();
springApplication.setSources();
springApplication.run(args);
其实就是通过setSources方法,添加参数来配置,参数可以是类名,包名以及XML路径
那么Spring Boot是怎么加载这两种数据源的呢,我们可以看看primarySources这个set集合什么时候用到的:
public Set<Object> getAllSources() {
Set<Object> allSources = new LinkedHashSet<>();
if (!CollectionUtils.isEmpty(this.primarySources)) {
allSources.addAll(this.primarySources); // java方式配置的源
}
if (!CollectionUtils.isEmpty(this.sources)) {
allSources.addAll(this.sources); //xml方式配置的源
}
return Collections.unmodifiableSet(allSources);
}
private void prepareContext(ConfigurableApplicationContext context, ConfigurableEnvironment environment,
//.....忽略代码
// Load the sources
Set<Object> sources = getAllSources();
Assert.notEmpty(sources, "Sources must not be empty");
load(context, sources.toArray(new Object[0]));
listeners.contextLoaded(context);
}
prepareContext这个方法在SpringApplication的run方法里面调用的,可以看到,获取到的sources又传给了load方法,继续跟进:
protected void load(ApplicationContext context, Object[] sources) {
if (logger.isDebugEnabled()) {
logger.debug("Loading source " + StringUtils.arrayToCommaDelimitedString(sources));
}
BeanDefinitionLoader loader = createBeanDefinitionLoader(getBeanDefinitionRegistry(context), sources);
if (this.beanNameGenerator != null) {
loader.setBeanNameGenerator(this.beanNameGenerator);
}
if (this.resourceLoader != null) {
loader.setResourceLoader(this.resourceLoader);
}
if (this.environment != null) {
loader.setEnvironment(this.environment);
}
loader.load();
}
嗯。。。继续跟进:
protected BeanDefinitionLoader createBeanDefinitionLoader(BeanDefinitionRegistry registry, Object[] sources) {
return new BeanDefinitionLoader(registry, sources);
}
好像到头了,进入BeanDefinitionLoader类的构造方法里看一下:
BeanDefinitionLoader(BeanDefinitionRegistry registry, Object... sources) {
Assert.notNull(registry, "Registry must not be null");
Assert.notEmpty(sources, "Sources must not be empty");
this.sources = sources;
this.annotatedReader = new AnnotatedBeanDefinitionReader(registry);
this.xmlReader = new XmlBeanDefinitionReader(registry);
if (isGroovyPresent()) {
this.groovyReader = new GroovyBeanDefinitionReader(registry);
}
this.scanner = new ClassPathBeanDefinitionScanner(registry);
this.scanner.addExcludeFilter(new ClassExcludeFilter(sources));
}
可以看到,分别通过AnnotatedBeanDefinitionReader和XmlBeanDefinitionReader这两个类来读取并将配置源加载为Spring Bean。这也说明了,在springboot的配置阶段,可以有两个数据源。
推断Web应用类型和主引导类
Spring Boot 不仅可以用作一个WEB工程,也可以作为非WEB工程来使用,那么springboot是如何推断应用类型的呢,答案是根据当前应用ClassPath中是否存在相关实现类来推断Web应用类型,类型在枚举类WebApplicationType中定义,总共有三种类型:
Web Reactive:枚举类型为WebApplicationType.REACTIVE ,对应的类路径:org.springframework. web.reactive.DispatcherHandler
Web Servlet: 枚举类型为WebApplicationType.SERVLET,对应的类路径:org.springframework.web.servlet.DispatcherServlet
非 Web: 枚举类型为WebApplicationType.NONE
在WebApplicationType中通过deduceFromClasspath方法判断类型:
static WebApplicationType deduceFromClasspath() {
//当类路径下存在Web Reactive 类路径并且不存在WebApplicationType.SERVLET类路径是才会启用
//WEB Reactive容器
if (ClassUtils.isPresent(WEBFLUX_INDICATOR_CLASS, null) && !ClassUtils.isPresent(WEBMVC_INDICATOR_CLASS, null)
&& !ClassUtils.isPresent(JERSEY_INDICATOR_CLASS, null)) {
return WebApplicationType.REACTIVE;
}
//当类路径中都不存在时,会启用非WEB类型
for (String className : SERVLET_INDICATOR_CLASSES) {
if (!ClassUtils.isPresent(className, null)) {
return WebApplicationType.NONE;
}
}
//默认启用tomcat容器
return WebApplicationType.SERVLET;
}
应用上下文初始器和应用事件监听
调用了下面两个方法实现了初始化上下文和事件监听:
setInitializers((Collection) getSpringFactoriesInstances(ApplicationContextInitializer.class));
setListeners((Collection) getSpringFactoriesInstances(ApplicationListener.class));
这两个的初始化都大同小异,所以只需要挑其中一个来看就行了,这里就看初始化应用上下文吧,首先通过getSpringFactoriesInstances(ApplicationContextInitializer.class)返回了一个集合,从这个方法的名字看大概可以猜到,是通过工厂模式初始化应用上下文,到底是不是这样,进去看一下:
private <T> Collection<T> getSpringFactoriesInstances(Class<T> type, Class<?>[] parameterTypes, Object... args) {
ClassLoader classLoader = getClassLoader();
// Use names and ensure unique to protect against duplicates
Set<String> names = new LinkedHashSet<>(SpringFactoriesLoader.loadFactoryNames(type, classLoader));
List<T> instances = createSpringFactoriesInstances(type, parameterTypes, classLoader, args, names);
AnnotationAwareOrderComparator.sort(instances);
return instances;
}
首先看一下通过SpringFactoriesLoader.loadFactoryNames(type, classLoader)这个方法,获取了一个set集合,传入了两个参数,第一个是ApplicationContextInitializer.class,第二个是类加载器,进入方法看一下:
/** * Load the fully qualified class names of factory implementations of the * given type from {@value #FACTORIES_RESOURCE_LOCATION}, using the given * class loader. * @param factoryType the interface or abstract class representing the factory * @param classLoader the ClassLoader to use for loading resources; can be * {@code null} to use the default * @throws IllegalArgumentException if an error occurs while loading factory names * @see #loadFactories */
public static List<String> loadFactoryNames(Class<?> factoryType, @Nullable ClassLoader classLoader) {
String factoryTypeName = factoryType.getName();
return loadSpringFactories(classLoader).getOrDefault(factoryTypeName, Collections.emptyList());
}
通过注释我们可以了解到,这个方法是从#FACTORIES_RESOURCE_LOCATION中获取继承ApplicationContextInitializer的这个类的所有类的全限定类名,其中#FACTORIES_RESOURCE_LOCATION 就是一个字符串常量: META-INF/spring.factories
这个spring.factories的内容如下:
# Initializers
org.springframework.context.ApplicationContextInitializer=\
org.springframework.boot.autoconfigure.SharedMetadataReaderFactoryContextInitializer,\
org.springframework.boot.autoconfigure.logging.ConditionEvaluationReportLoggingListener
通过解析这个文件里的内容来获取全限定类名,最终返回一个string类型的集合,也就是我们最开始看到的那个Set<String> names;
然后传递给createSpringFactoriesInstances方法生成实例,最后再排序
private <T> List<T> createSpringFactoriesInstances(Class<T> type, Class<?>[] parameterTypes,
ClassLoader classLoader, Object[] args, Set<String> names) {
List<T> instances = new ArrayList<>(names.size());
for (String name : names) {
try {
Class<?> instanceClass = ClassUtils.forName(name, classLoader);
Assert.isAssignable(type, instanceClass);
Constructor<?> constructor = instanceClass.getDeclaredConstructor(parameterTypes);
T instance = (T) BeanUtils.instantiateClass(constructor, args);
instances.add(instance);
}
catch (Throwable ex) {
throw new IllegalArgumentException("Cannot instantiate " + type + " : " + name, ex);
}
}
return instances;
}
推导引用主类
前面说过,我们一般写SpringBoot的启动类代码,会按照下面的方式:
@SpringBootApplication
public class MySpringBootApplication {
public static void main(String[] args) {
SpringApplication.run(MySpringBootApplication.class, args);
}
}
我们可以很明显的知道主类就是MySpringBootApplication,但是,SpringBoot有多种启动方式,而且SpringApplication.run第一个参数是可变的,也就是说,我可以在其他的类的main方法中调用SpringApplication.run方法启动MySpringBootApplication,那么那个类就是主类,而不是MySpringBootApplication:
public class App {
public static void main(String[] args) {
SpringApplication
.run(MySpringBootApplication.class,args);
}
}
在SpringBoot的构造方法中调用了推导引用主类的方法:
private Class<?> deduceMainApplicationClass() {
try {
StackTraceElement[] stackTrace = new RuntimeException().getStackTrace();
for (StackTraceElement stackTraceElement : stackTrace) {
if ("main".equals(stackTraceElement.getMethodName())) {
return Class.forName(stackTraceElement.getClassName());
}
}
}
catch (ClassNotFoundException ex) {
// Swallow and continue
}
return null;
}
debug看一下:
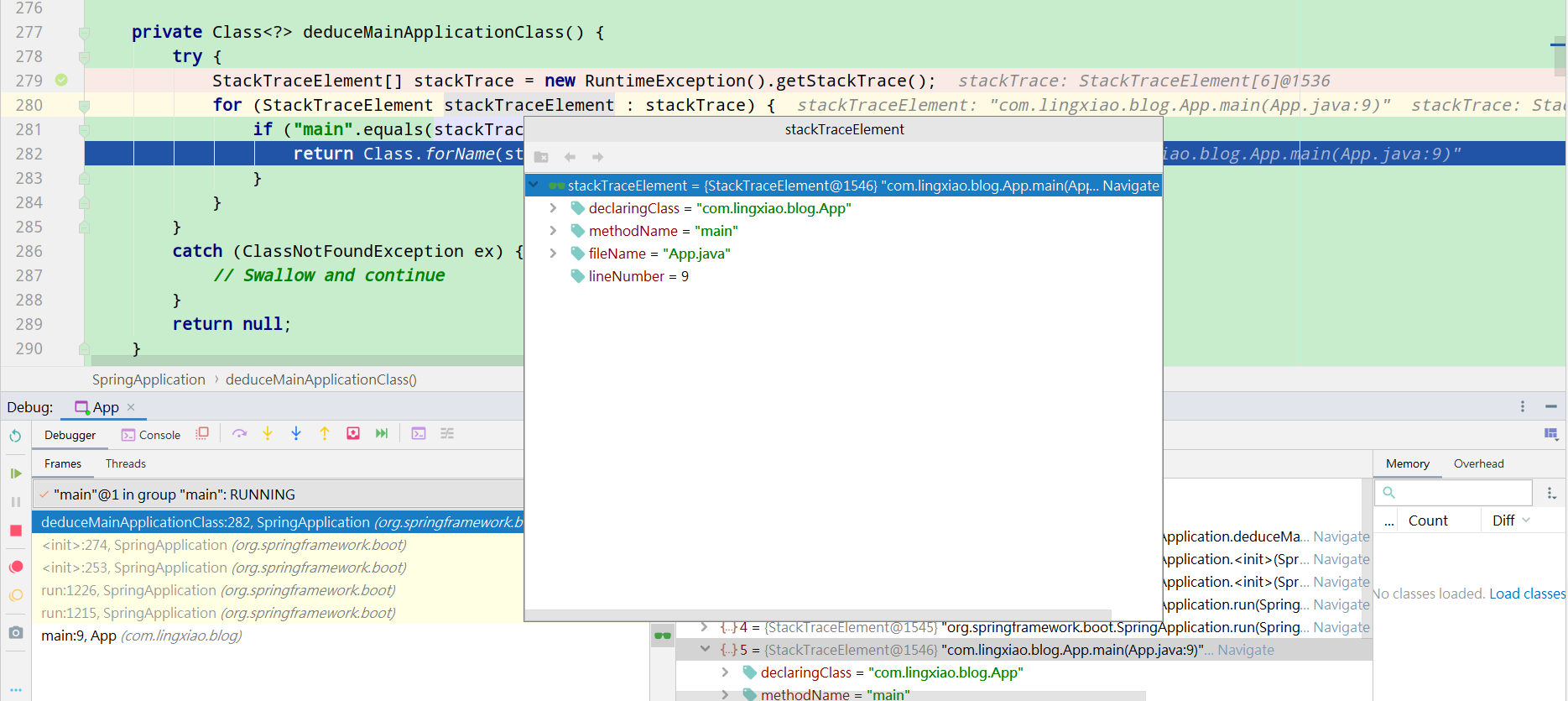

可以看到的是,SpringBoot是通过异常堆栈来遍历判断出main方法,发现类名为App的类中方法名是main,从而推导出App就是主类。
所以SpringBoot的启动主类,是由它自己推导的,而不是我们传给它的。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/197855.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
