大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
Word2vec中两个重要模型是:CBOW和Skip-gram模型
首先Wordvec的目标是:将一个词表示成一个向量
这里首先说下我对CBOW模型的理解
这是主要是举个例子简化下
首先说下CBOW的三层结构:输入层,投影层(中间层),输出层
假设语料库有10个词: 【今天,我,你,他,小明,玩,北京,去,和,好】
现在有这样一句话:今天我和小明去北京玩
很显然,对这个句子分词后应该是:
今天 我 和 小明 去 北京 玩
对于小明而言,选择他的前三个词和后三个词作为这个词的上下文
接下来,将这些分别全部表示成一个one-hot向量(向量中只有一个元素值为1,其他都是0)
则向量如下:
今天:[1, 0, 0, 0, 0, 0, 0, 0, 0, 0] 记为x1
我 :[0, 1, 0, 0, 0, 0, 0, 0, 0, 0] 记为x2
和 :[0, 0, 0, 0, 0, 0, 0, 0, 1, 0] 记为x3
去 :[0, 0, 0, 0, 0, 0, 0, 1, 0, 0] 记为x4
北京:[0, 0, 0, 0, 0, 0, 1, 0, 0, 0] 记为x5
玩 :[0, 0, 0, 0, 0, 0, 1, 0, 0, 0] 记为x6
此外,小明的向量表示如下:
小明 :[0, 0, 0, 0, 1, 0, 0, 0, 0, 0] 可以看出来,向量的维度就是语料库中词的个数
接下来,将这6个向量求和,作为神经网络模型的输入,即
X = x1 + x2 + x3 + x4 + x5 + x6 = [1, 1, 0, 0, 0, 1, 1, 1, 1, 0]则X就是输入层,即输入层是由小明的前后三个词生成的一个向量,为1*10维(这里的10是语料库中词语的个数)
我们这里是根据一个词语的上下文来预测这个词究竟是哪个,这个例子中就是根据小明这个词的前后三个词来预测小明这个位置出现各个词的概率,因为训练数据中这个词就是小明,所以小明出现的概率应该是最大的, 所以我们希望输出层的结果就是小明对应的向量
所以本例中,输出层期望的数据实际就是小明这个词构成的向量(可以认为是训练数据的标签) 即:
小明 :[0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
那么神经网络模型可以画成如下形状

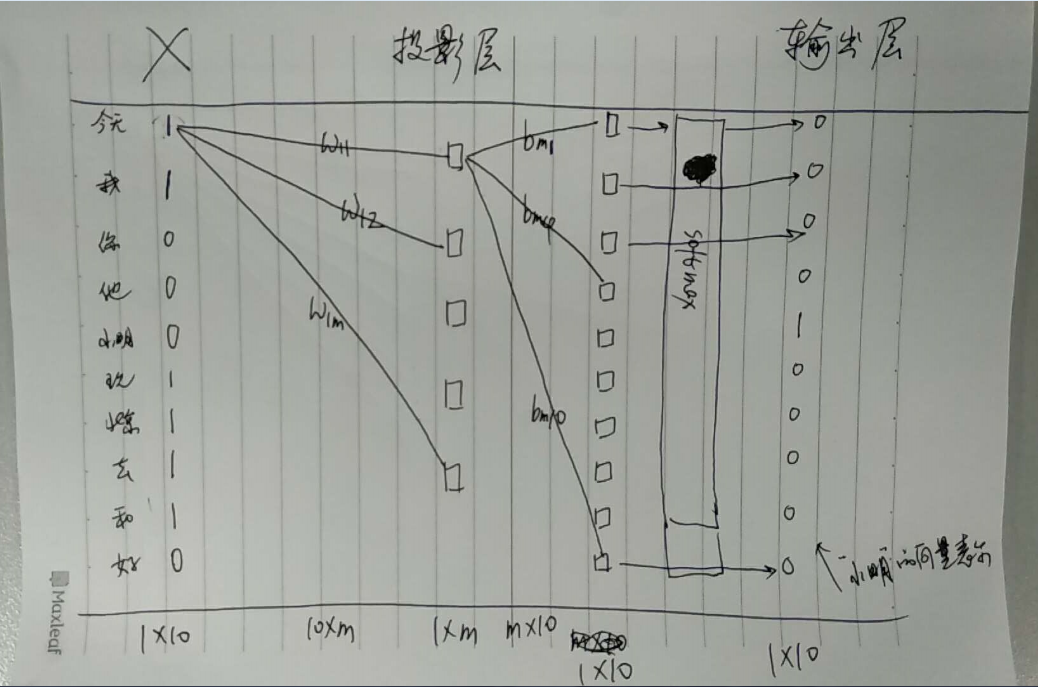
这里我们可以随意设定投影层的维度,即m的值,则:
输入层和投影层的连线就可以构成一个参数矩阵1, 即w,该矩阵的维度为10*m(这里10是语料库中词语的个数), 可以随机初始化这个矩阵的参数值
投影层和输出层的连线就可以构成一个参数矩阵2,即b, 该矩阵的维度为m*10, 可以随机初始化这个矩阵的参数值
这样最终的输出层的维度1*10 = (1*10) * (10*m) * (m*10)
参数矩阵1为:w
参数矩阵2为:b
那么模型的目标函数是什么呢?
就是损失函数,就是实际输出和期望输出的差值,我可以定义为平方差
首先,期望输出就是“小明” 对应的向量
Y_ = [0, 0, 0, 0, 1, 0, 0, 0, 0, 0] 这个可以认为是训练数据的标签
实际输出就是根据输入X以及两个参数矩阵w和b计算后输入到softmax函数所得的结果:
即将 X * w * b的值 输入到softmax函数得到实际的输出
Y = [y1, y2, y3, y4, y5, y6, y7, y8, y9, y10]
则损失函数可以定义为:
J(θ) = (y1-0)*(y1-0) + (y2-0)*(y2-0) + (y3-0)*(y3-0) + (y4-0)*(y4-0) + (y5-1)*(y5-1) + (y6-0)*(y6-0) + (y7-0)*(y7-0) + (y8-0)*(y8-0) + (y9-0)*(y9-0) + (y10-0)*(y10-0) 这里实际就是计算的两个向量的距离,当然你可以采用别的算法
这个损失函数是关于w和b的函数, 目标就是极小化损失函数
采用梯度下降法来不断调整w和b的值(即不断给w和b的参数值一个增量), 当模型的输出满足某个设定的条件时,则停止训练
注意: 模型输出的结果不会刚好就是一个one-hot向量, 可以认为趋近于0的就是0,趋近于1的就是1,当然为1的肯定只有一个元素
为了加快训练速度,可以一个批次一起训练,将多个句子的损失函数求和来训练
最终训练结束后,就要将一个词表示成一个向量,那么怎么表示呢?
输入X中第一个元素的值为1, 这表示的其实就是“今天” 这个词,那么“今天”就用它对应的连线上的权重参数来表示
今天 = [w11, w12... w1m]我 = [w21, w22... w2m]至于为什么要这样表示,至今没有人能解释
但是注意:这里只能将X中元素为1的词表示成向量,即只能将句子中出现的词表示成向量,即“小明”的前后三个词
然后说下我对Skip-gram模型的理解
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/197818.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
