大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
注:hive其他语法在hive官网有说明,建议初学者,去官网学习一手的资料,
官网:https://cwiki.apache.org/confluence/display/Hive/Home#Home-UserDocumentation
Create Table
官网说明
Hive建表方式共有三种:
- 直接建表法
- 查询建表法
- like建表法
首先看官网介绍
’[]’ 表示可选,’|’ 表示二选一
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
LIKE existing_table_or_view_name
[LOCATION hdfs_path];
data_type
: primitive_type
| array_type
| map_type
| struct_type
| union_type -- (Note: Available in Hive 0.7.0 and later)
primitive_type
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| DOUBLE PRECISION -- (Note: Available in Hive 2.2.0 and later)
| STRING
| BINARY -- (Note: Available in Hive 0.8.0 and later)
| TIMESTAMP -- (Note: Available in Hive 0.8.0 and later)
| DECIMAL -- (Note: Available in Hive 0.11.0 and later)
| DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later)
| DATE -- (Note: Available in Hive 0.12.0 and later)
| VARCHAR -- (Note: Available in Hive 0.12.0 and later)
| CHAR -- (Note: Available in Hive 0.13.0 and later)
array_type
: ARRAY < data_type >
map_type
: MAP < primitive_type, data_type >
struct_type
: STRUCT < col_name : data_type [COMMENT col_comment], ...>
union_type
: UNIONTYPE < data_type, data_type, ... > -- (Note: Available in Hive 0.7.0 and later)
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later)
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
file_format:
: SEQUENCEFILE
| TEXTFILE -- (Default, depending on hive.default.fileformat configuration)
| RCFILE -- (Note: Available in Hive 0.6.0 and later)
| ORC -- (Note: Available in Hive 0.11.0 and later)
| PARQUET -- (Note: Available in Hive 0.13.0 and later)
| AVRO -- (Note: Available in Hive 0.14.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
constraint_specification:
: [, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE ]
[, CONSTRAINT constraint_name FOREIGN KEY (col_name, ...) REFERENCES table_name(col_name, ...) DISABLE NOVALIDATE
观察可发现一共有三种建表方式,接下来我们将一一讲解。
1.直接建表法:
create table table_name(col_name data_type);
这里我们针对里面的一些不同于关系型数据库的地方进行说明。
row format
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later)
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
Hive将HDFS上的文件映射成表结构,通过分隔符来区分列(比如’,’ ‘;’ or ‘^’ 等),row format就是用于指定序列化和反序列化的规则。
比如对于以下记录:
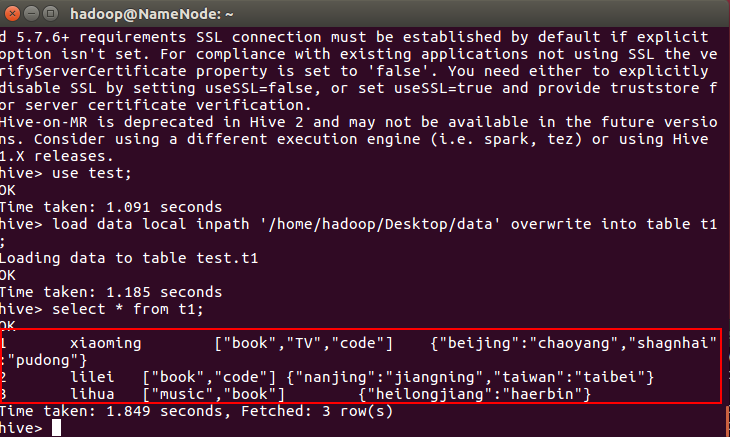
1,xiaoming,book-TV-code,beijing:chaoyang-shagnhai:pudong
2,lilei,book-code,nanjing:jiangning-taiwan:taibei
3,lihua,music-book,heilongjiang:haerbin
逗号用于分割列,即FIELDS TERMINATED BY char,分割为如下列 ID、name、hobby(该字段是数组形式,通过 ‘-’ 进行分割,即COLLECTION ITEMS TERMINATED BY '-’)、address(该字段是键值对形式map,通过 ‘:’ 分割键值,即 MAP KEYS TERMINATED BY ':');
而LINES TERMINATED BY char用于区分不同条的数据,默认是换行符;
file format(HDFS文件存放的格式)
默认TEXTFILE,即文本格式,可以直接打开。
- 是
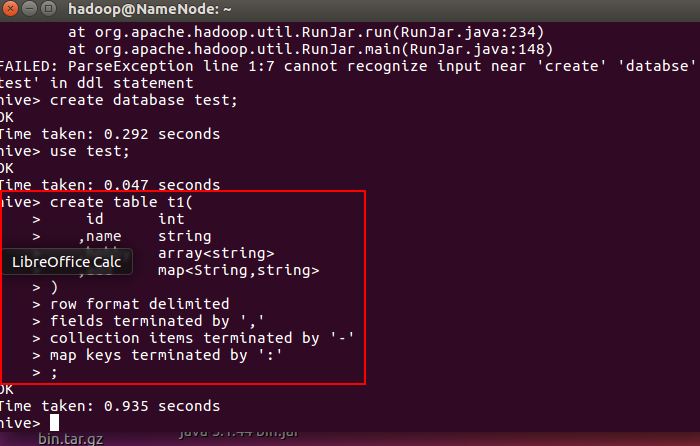
如下:根据上述文件内容,创建一个表t1
create table t1(
id int
,name string
,hobby array<string>
,add map<String,string>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
;

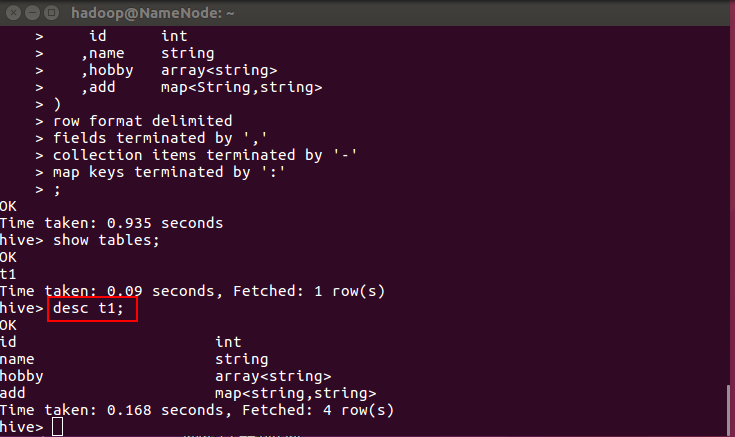
2. 查看表的描述:desc t1;
- 下面插入数据
注:一般很少用insert (不是insert overwrite)语句,因为就算就算插入一条数据,也会调用MapReduce,这里我们选择Load Data的方式。
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
创建一个文件粘贴上述记录,并上载即可,如下图:
然后上载
load data local inpath '/home/hadoop/Desktop/data' overwrite into table t1;
别忘记写文件名/data,笔者第一次忘记写,把整个Desktop上传了,一查全是null和乱码。。。。
查看表内容:
select * from t1;
external
未被external修饰的是内部表(managed table),被external修饰的为外部表(external table);
区别:
内部表数据由Hive自身管理,外部表数据由HDFS管理;
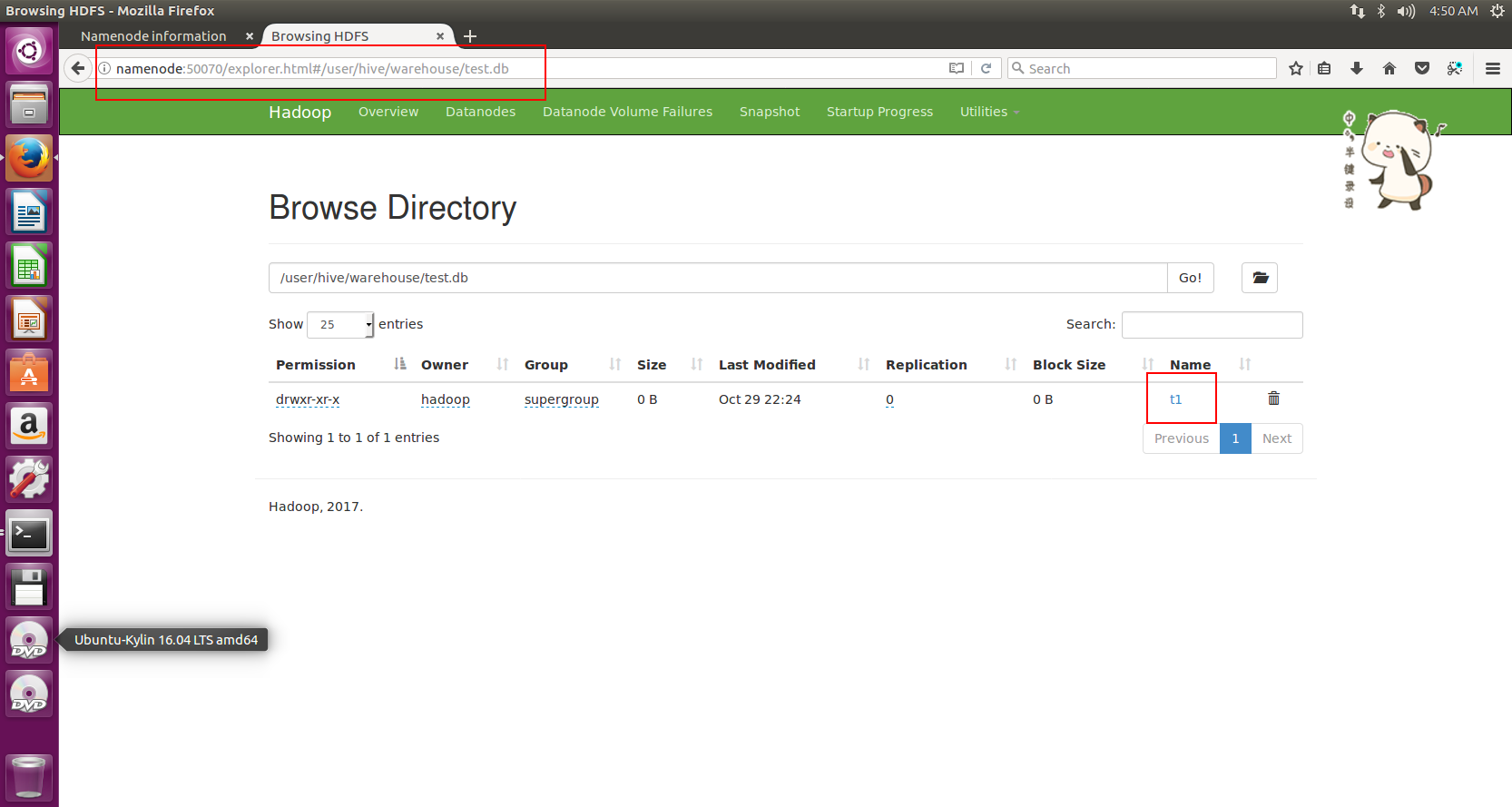
内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己制定;
删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)
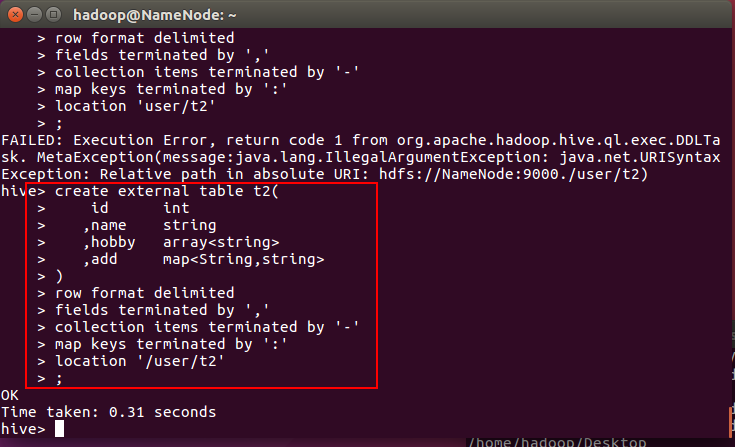
创建一个外部表t2
create external table t2(
id int
,name string
,hobby array<string>
,add map<String,string>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
location '/user/t2'
;
装载数据
load data local inpath '/home/hadoop/Desktop/data' overwrite into table t2;
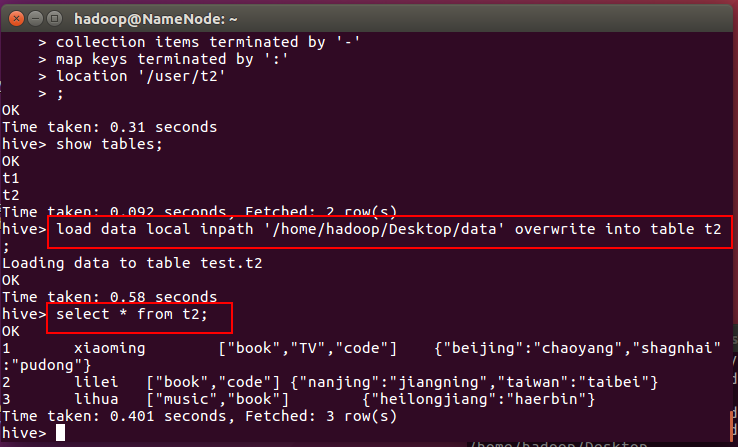
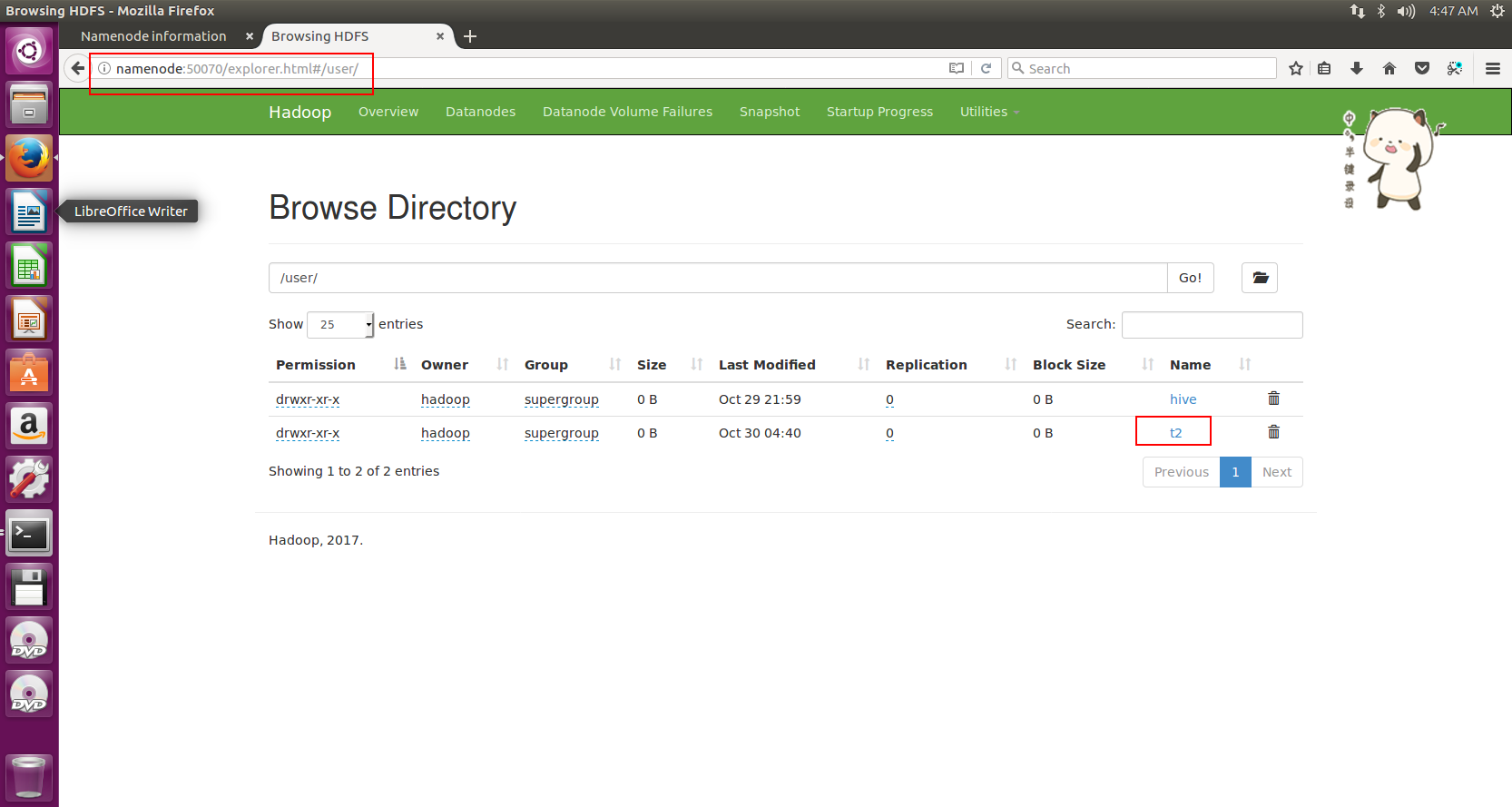
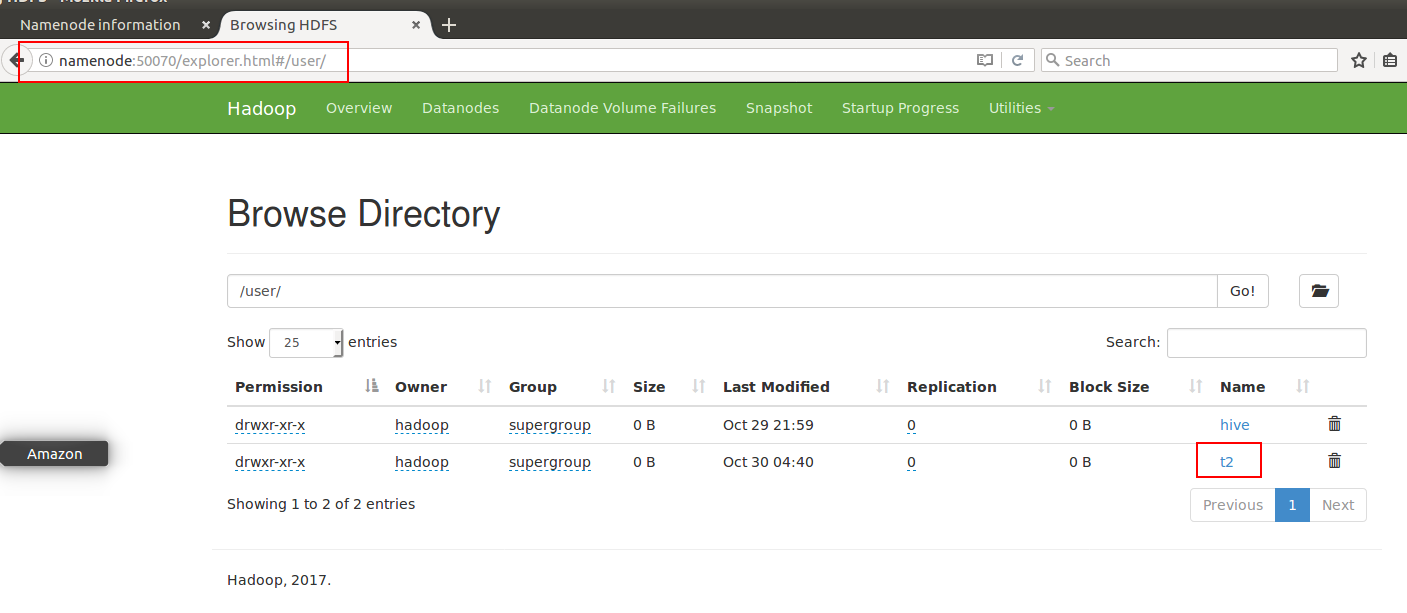
查看文件位置
如下图,我们在NameNode:50070/explorer.html#/user/目录下,可以看到t2文件
t1在哪呢?在我们之前配置的默认路径里
同样我们可以通过命令行获得两者的位置信息:
desc formatted table_name;
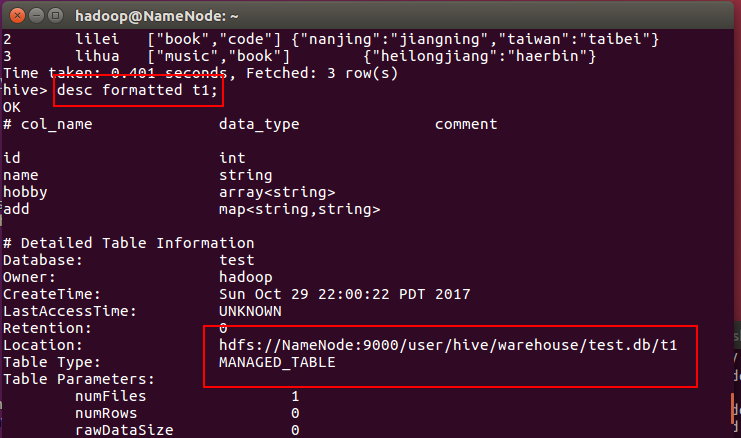
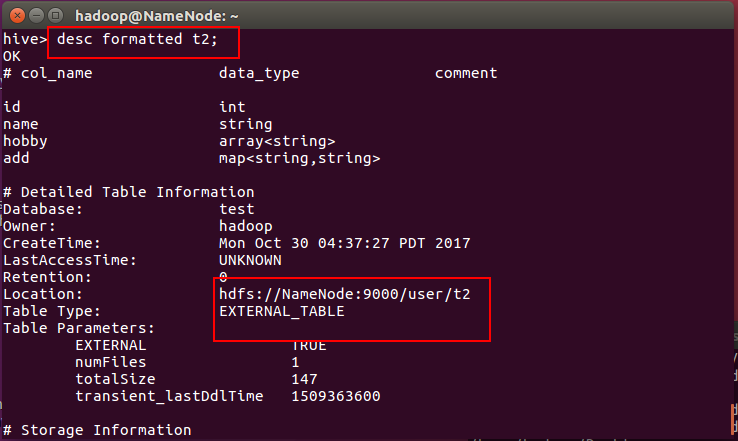
注:图中managed table就是内部表,而external table就是外部表。
分别删除内部表和外部表
下面分别删除内部表和外部表,查看区别
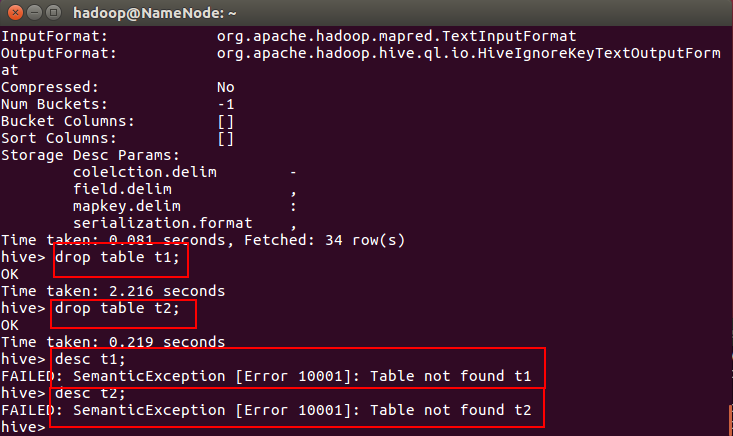
观察HDFS上的文件
发现t1已经不存在了
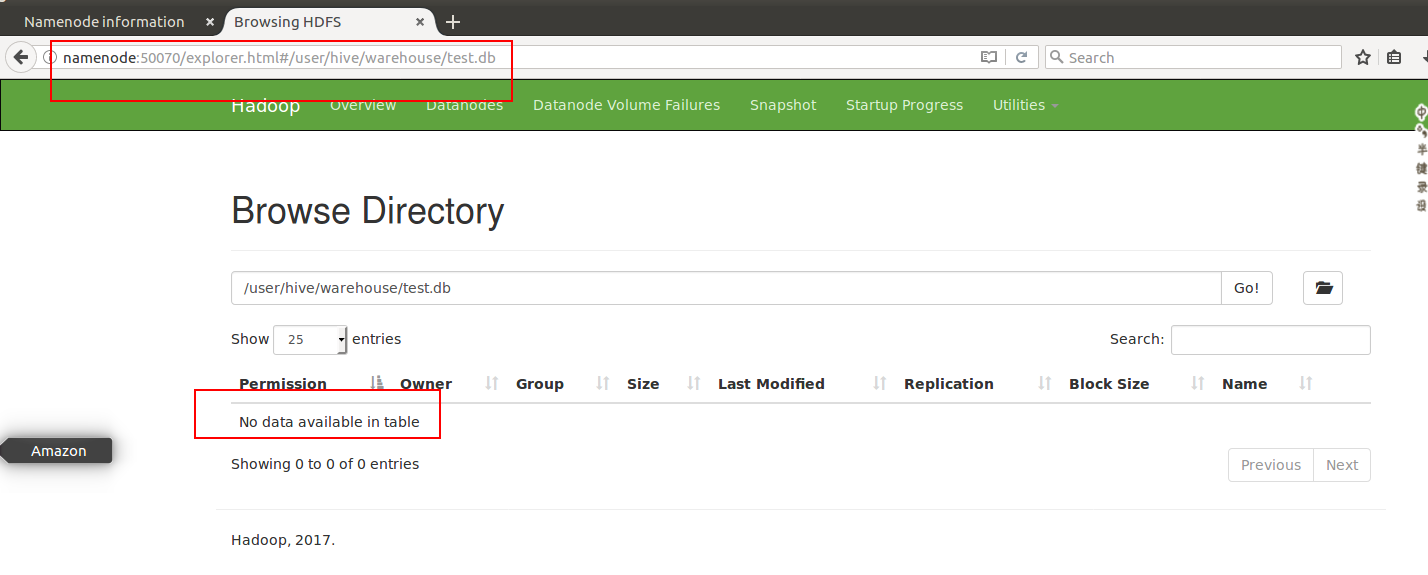
但是t2仍然存在
因而外部表仅仅删除元数据
重新创建外部表t2
create external table t2(
id int
,name string
,hobby array<string>
,add map<String,string>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
location '/user/t2'
;
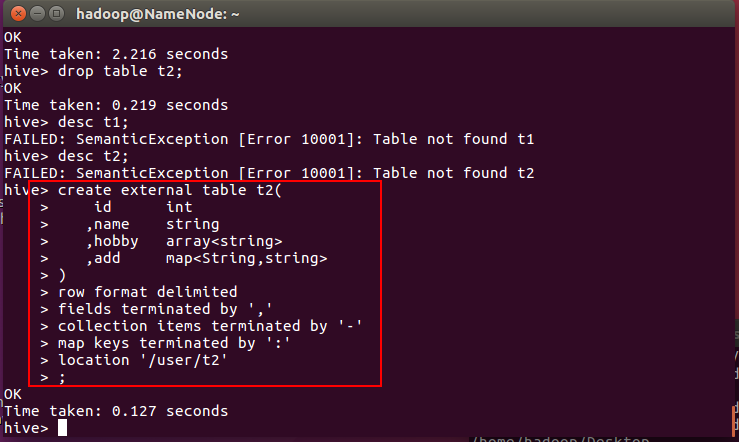
不往里面插入数据,我们select * 看看结果
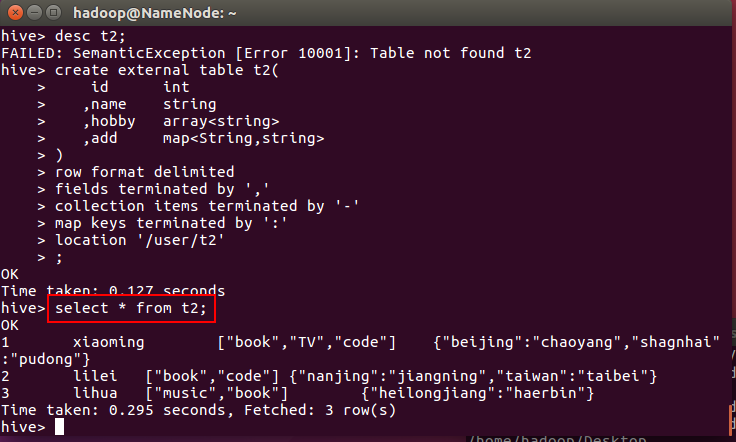
可见数据仍然在!!!
官网说明
A table created without the EXTERNAL clause is called a managed table because Hive manages its data.
Managed and External Tables
By default Hive creates managed tables, where files, metadata and statistics are managed by internal Hive processes. A managed table is stored under the hive.metastore.warehouse.dir path property, by default in a folder path similar to /apps/hive/warehouse/databasename.db/tablename/. The default location can be overridden by the location property during table creation. If a managed table or partition is dropped, the data and metadata associated with that table or partition are deleted. If the PURGE option is not specified, the data is moved to a trash folder for a defined duration.
Use managed tables when Hive should manage the lifecycle of the table, or when generating temporary tables.
An external table describes the metadata / schema on external files. External table files can be accessed and managed by processes outside of Hive. External tables can access data stored in sources such as Azure Storage Volumes (ASV) or remote HDFS locations. If the structure or partitioning of an external table is changed, an MSCK REPAIR TABLE table_name statement can be used to refresh metadata information.
Use external tables when files are already present or in remote locations, and the files should remain even if the table is dropped.
Managed or external tables can be identified using the DESCRIBE FORMATTED table_name command, which will display either MANAGED_TABLE or EXTERNAL_TABLE depending on table type.
Statistics can be managed on internal and external tables and partitions for query optimization.
2.查询建表法
通过AS 查询语句完成建表:将子查询的结果存在新表里,有数据
一般用于中间表
CREATE TABLE new_key_value_store
ROW FORMAT SERDE "org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe"
STORED AS RCFile
AS
SELECT (key % 1024) new_key, concat(key, value) key_value_pair
FROM key_value_store
SORT BY new_key, key_value_pair;
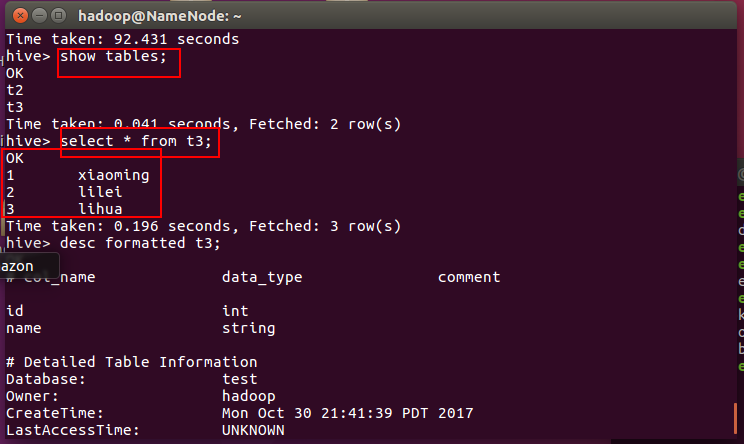
根据例子我们建一张表:t3
create table t3 as
select
id
,name
from t2
;
会执行MapReduce过程。
查看表结构及内容,发现是有数据的,并且由于没有指定外部表和location,该表在默认位置,即是内部表。
3.like建表法
会创建结构完全相同的表,但是没有数据。
常用语中间表
CREATE TABLE empty_key_value_store
LIKE key_value_store;
例子
create table t4 like t2;
可以发现,不会执行MapReduce,且表结构和t2完全一样,但是没有数据。

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/197635.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
