大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
1.树模型和线性模型的区别
-
树形模型是一个一个特征进行处理
-
线性模型是所有特征给予权重相加得到一个新的值
2.什么是决策树
- 所谓决策树,就是一个类似于流程图的树形结构,树内部的每一个节点代表的是对一个特征的测试,树的分支代表该特征的每一个测试结果,而树的每一个叶子节点代表一个类别。树的最高层是就是根节点。下图即为一个决策树的示意描述,内部节点用矩形表示,叶子节点用椭圆表示。

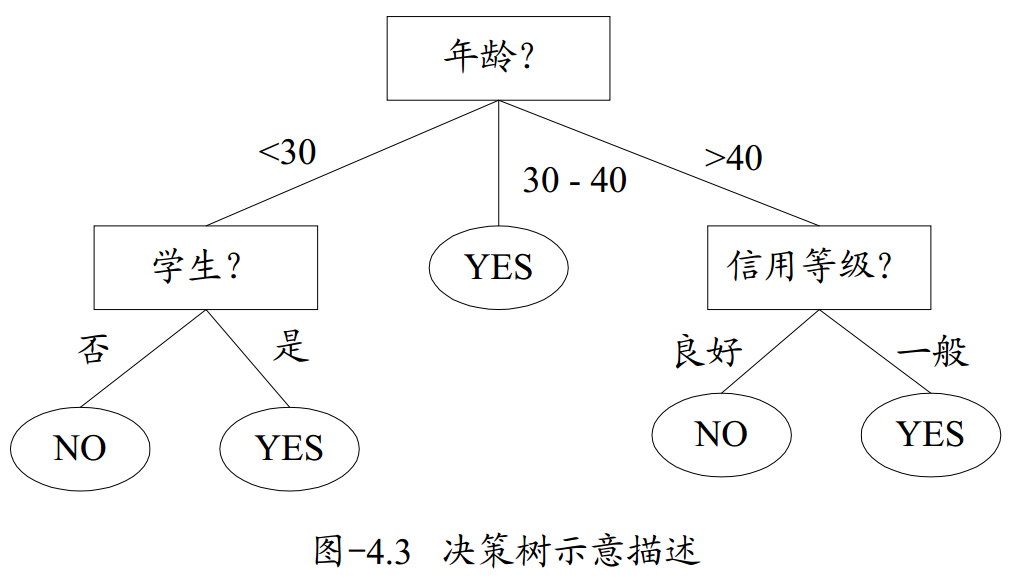
3.学习过程
-
**特征选择:**特征选择是指从训练数据中众多的特征中选择一个特征作为当前节点的分裂标准,如何选择特征有着很多不同量化评估标准标准,从而衍生出不同的决策树算法。
-
决策树生成: 根据选择的特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止生长。 树结构来说,递归结构是最容易理解的方式。
-
**剪枝:**决策树容易过拟合,一般来需要剪枝,缩小树结构规模、缓解过拟合。剪枝技术有预剪枝和后剪枝两种。
4.一些概念
- GINI系数:
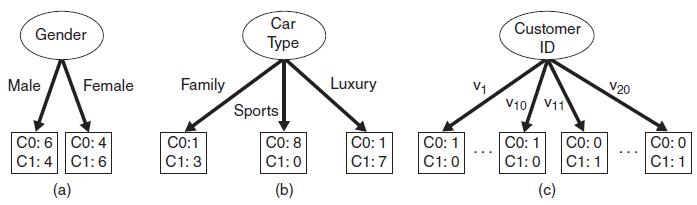
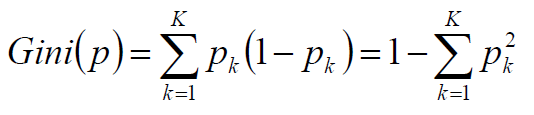
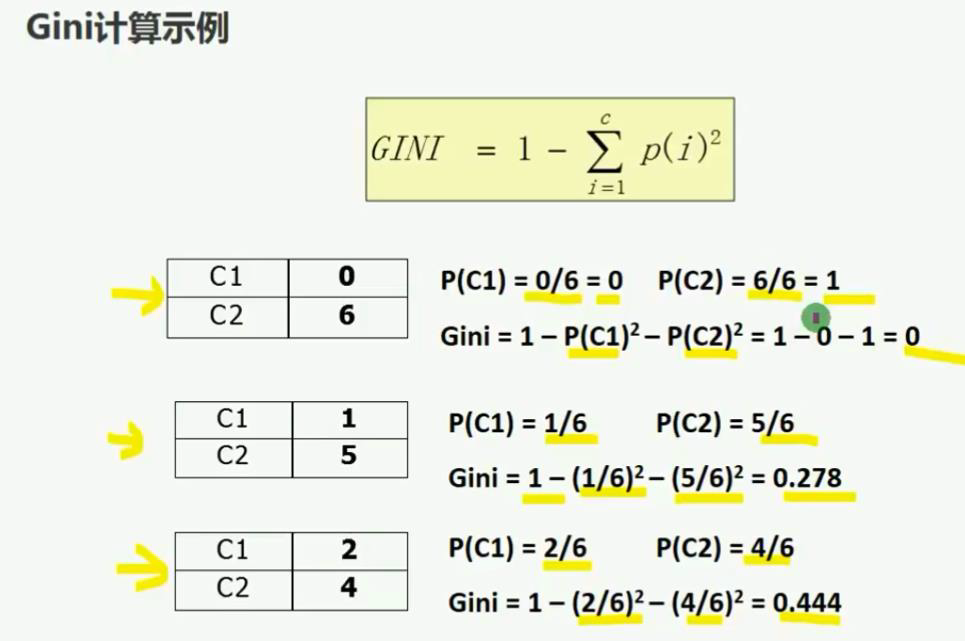
-
熵:
- 设X是一个取有限个值的离散随机变量,其概率分布为:
- 则随机变量X的熵定义为 :
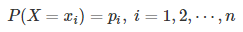
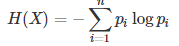

5.如何划分特征
- 通过一种衡量标准,来计算通过不同特征进行分支选择后的分类情况,找出来最好的那个当成根节点,以此类推
- 熵是表示随机变量不确定性的度量,即物体的混乱程度
特征挑选方法:信息增益法
- 特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,即公式为
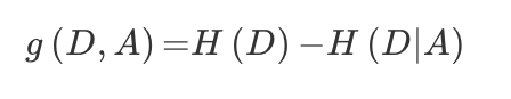
注:信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度,即信息增益越大,信息的不确定性越小,而信息熵是度量信息混乱程度的,即信息熵越大,信息的不确定性越大。
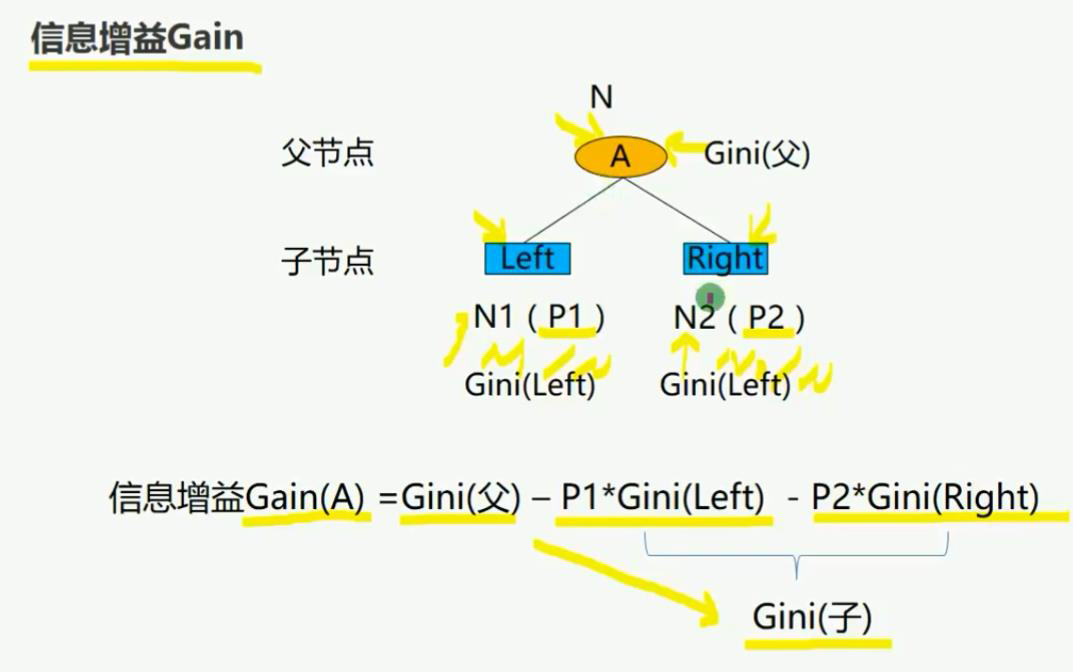
- 选择具有最高信息增益的特征作为测试特征,利用该特征对节点样本进行划分子集,会使得各子集中不同类别样本的混合程度最低,在各子集中对样本划分所需的信息(熵)最少,(信息增益既可以用熵也可以用GINI系数来计算)

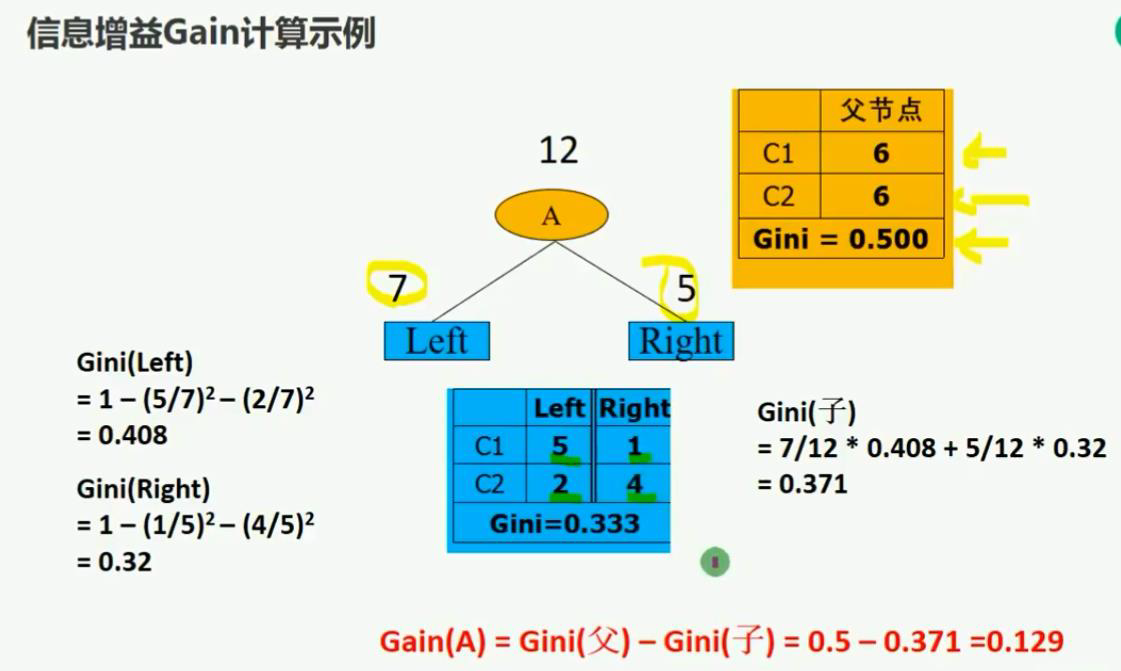
6.决策树的生成
- 从根节点出发,根节点包括所有的训练样本。
- 一个节点(包括根节点),若节点内所有样本均属于同一类别,那么将该节点就成为叶节点,并将该节点标记为样本个数最多的类别。
- 否则利用采用信息增益法来选择用于对样本进行划分的特征,该特征即为测试特征,特征的每一个值都对应着从该节点产生的一个分支及被划分的一个子集。在决策树中,所有的特征均为符号值,即离散值。如果某个特征的值为连续值,那么需要先将其离散化。
- 递归上述划分子集及产生叶节点的过程,这样每一个子集都会产生一个决策(子)树,直到所有节点变成叶节点。
- 递归操作的停止条件就是:
(1)一个节点中所有的样本均为同一类别,那么产生叶节点
(2)没有特征可以用来对该节点样本进行划分,这里用attribute_list=null为表示。此时也强制产生叶节点,该节点的类别为样本个数最多的类别
(3)没有样本能满足剩余特征的取值,即test_attribute= 对应的样本为空。此时也强制产生叶节点,该节点的类别为样本个数最多的类别
7.决策树剪枝
由于噪声等因素的影响,会使得样本某些特征的取值与样本自身的类别不相匹配的情况,基于这些数据生成的决策树的某些枝叶会产生一些错误;尤其是在决策树靠近枝叶的末端,由于样本变少,这种无关因素的干扰就会突显出来;由此产生的决策树可能存在过拟合的现象。树枝修剪就是通过统计学的方法删除不可靠的分支,使得整个决策树的分类速度和分类精度得到提高。
- 预剪枝:在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶节点。
- 后剪枝:先从训练集生成一棵完整的决策树,然后自底向上地对非叶节点进行考察,若将该节点对应的子树替换为叶节点能带来决策树泛化性能提升,则将该子树替换为叶结点。
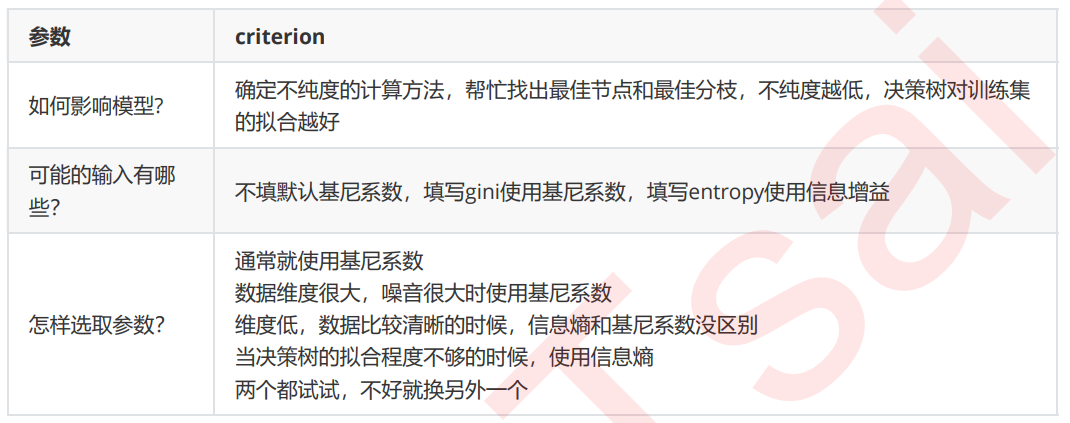
8.sklearn

class sklearn.tree.DecisionTreeClassifier (criterion=’gini’, splitter=’best’, max_depth=None,
min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None,
random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None,
class_weight=None, presort=False)
重要参数
-
criterion


from sklearn import tree from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split wine = load_wine() wine.data.shape #(178, 13) wine.feature_names ''' ['alcohol', 'malic_acid', 'ash', 'alcalinity_of_ash', 'magnesium', 'total_phenols', 'flavanoids', 'nonflavanoid_phenols', 'proanthocyanins', 'color_intensity', 'hue', 'od280/od315_of_diluted_wines', 'proline'] ''' wine.target_names #array(['class_0', 'class_1', 'class_2'], dtype='<U7') Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3) clf = tree.DecisionTreeClassifier(criterion="entropy") clf = clf.fit(Xtrain, Ytrain) score = clf.score(Xtest, Ytest) #返回预测的准确度accuracy #0.9074074074074074 #绘制决策树 feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜色强度','色调','od280/od315稀释葡萄酒','脯氨酸'] import graphviz dot_data = tree.export_graphviz(clf, out_file="tree.dot" ,feature_names = feature_name ,class_names=["琴酒","雪莉","贝尔摩德"] ,filled=True ,rounded=True ) #转换dot文件的编码 import re # 打开 dot_data.dot,修改 fontname="支持的中文字体" f = open("./tree.dot", "r+", encoding="utf-8") open('./tree_utf8.dot', 'w', encoding="utf-8").write(re.sub(r'fontname=helvetica', 'fontname="Microsoft YaHei"', f.read())) f.close() #在cmd中输入命令,转换成pdf格式![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XchC02QH-1631617823675)(C:\Users\张治\AppData\Roaming\Typora\typora-user-images\image-20210914124531670.png)]](https://img-blog.csdnimg.cn/302258b67e3148cb875d7ee7da882b6c.png)
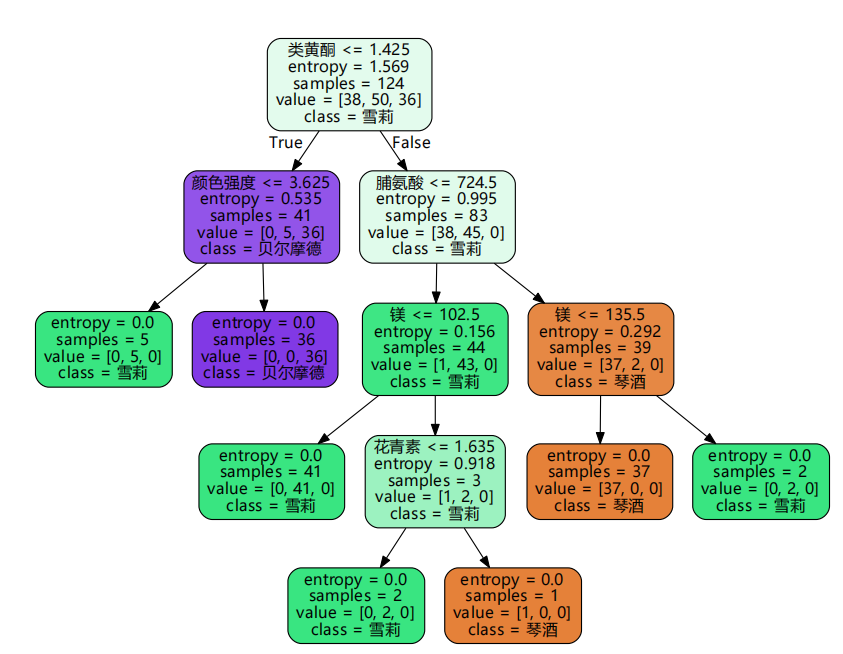
#特征重要性 clf.feature_importances_ ''' array([0. , 0. , 0. , 0. , 0.07971485, 0. , 0.46293811, 0. , 0.01415747, 0.11271291, 0. , 0. , 0.33047666]) ''' [*zip(feature_name,clf.feature_importances_)] ''' [('酒精', 0.0), ('苹果酸', 0.0), ('灰', 0.0), ('灰的碱性', 0.0), ('镁', 0.07971484654602709), ('总酚', 0.0), ('类黄酮', 0.4629381086984116), ('非黄烷类酚类', 0.0), ('花青素', 0.014157468716276041), ('颜色强度', 0.11271291326362196), ('色调', 0.0), ('od280/od315稀释葡萄酒', 0.0), ('脯氨酸', 0.33047666277566334)] ''' -
splitter

clf = tree.DecisionTreeClassifier(criterion="entropy"
,random_state=30
,splitter="random"
)
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest)
score
#0.9814814814814815
剪枝参数

-
max_depth
限制树的最大深度,超过设定深度的树枝全部剪掉
这是用得最广泛的剪枝参数,在高维度低样本量时非常有效。决策树多生长一层,对样本量的需求会增加一倍,所 以限制树深度能够有效地限制过拟合。在集成算法中也非常实用。实际使用时,建议从=3开始尝试,看看拟合的效 果再决定是否增加设定深度
-
min_samples_leaf & min_samples_split
min_samples_leaf限定,一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样本,否则分 枝就不会发生,或者,分枝会朝着满足每个子节点都包含min_samples_leaf个样本的方向去发生
一般搭配max_depth使用,在回归树中有神奇的效果,可以让模型变得更加平滑。这个参数的数量设置得太小会引 起过拟合,设置得太大就会阻止模型学习数据。一般来说,建议从=5开始使用。如果叶节点中含有的样本量变化很 大,建议输入浮点数作为样本量的百分比来使用。同时,这个参数可以保证每个叶子的最小尺寸,可以在回归问题 中避免低方差,过拟合的叶子节点出现。对于类别不多的分类问题,=1通常就是最佳选择。
min_samples_split限定,一个节点必须要包含至少min_samples_split个训练样本,这个节点才允许被分枝,否则 分枝就不会发生。
clf = tree.DecisionTreeClassifier(criterion="entropy" ,random_state=30 ,splitter="random" ,max_depth=3 ,min_samples_leaf=10 ,min_samples_split=10 ) -
max_features & min_impurity_decrease
一般max_depth使用,用作树的”精修“
max_features限制分枝时考虑的特征个数,超过限制个数的特征都会被舍弃。和max_depth异曲同工, max_features是用来限制高维度数据的过拟合的剪枝参数,但其方法比较暴力,是直接限制可以使用的特征数量 ,而强行使决策树停下的参数,在不知道决策树中的各个特征的重要性的情况下,强行设定这个参数可能会导致模型 学习不足。如果希望通过降维的方式防止过拟合,建议使用PCA,ICA或者特征选择模块中的降维算法。
min_impurity_decrease限制信息增益的大小,信息增益小于设定数值的分枝不会发生。这是在0.19版本中更新的 功能,在0.19版本之前时使用min_impurity_split。
目标权重参数
-
class_weight & min_weight_fraction_leaf
完成样本标签平衡的参数。样本不平衡是指在一组数据集中,标签的一类天生占有很大的比例。比如说,在银行要 判断“一个办了信用卡的人是否会违约”,就是是vs否(1%:99%)的比例。这种分类状况下,即便模型什么也不 做,全把结果预测成“否”,正确率也能有99%。因此我们要使用class_weight参数对样本标签进行一定的均衡,给 少量的标签更多的权重,让模型更偏向少数类,向捕获少数类的方向建模。该参数默认None,此模式表示自动给 与数据集中的所有标签相同的权重。 有了权重之后,样本量就不再是单纯地记录数目,而是受输入的权重影响了,因此这时候剪枝,就需要搭配min_ weight_fraction_leaf这个基于权重的剪枝参数来使用。
另请注意,基于权重的剪枝参数(例如min_weight_ fraction_leaf)将比不知道样本权重的标准(比如min_samples_leaf)更少偏向主导类。如果样本是加权的,则使 用基于权重的预修剪标准来更容易优化树结构,这确保叶节点至少包含样本权重的总和的一小部分
9.回归树
class sklearn.tree.DecisionTreeRegressor (criterion=’mse’, splitter=’best’, max_depth=None,
min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None,
random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, presort=False)
重要参数,属性和接口



from sklearn.datasets import load_boston
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeRegressor
boston = load_boston()
regressor = DecisionTreeRegressor(random_state=0)
cross_val_score(regressor, boston.data, boston.target, cv=10,
scoring = "neg_mean_squared_error")
10.泰坦尼克号预测
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
data = pd.read_csv(r"C:\work\learnbetter\micro-class\week 1 DT\data\data.csv",index_col = 0)
data.info()
''' <class 'pandas.core.frame.DataFrame'> Int64Index: 891 entries, 1 to 891 Data columns (total 11 columns): Survived 891 non-null int64 Pclass 891 non-null int64 Name 891 non-null object Sex 891 non-null object Age 714 non-null float64 SibSp 891 non-null int64 Parch 891 non-null int64 Ticket 891 non-null object Fare 891 non-null float64 Cabin 204 non-null object Embarked 889 non-null object dtypes: float64(2), int64(4), object(5) memory usage: 83.5+ KB '''
#删除缺失值过多的列,和观察判断来说和预测的y没有关系的列
data.drop(["Cabin","Name","Ticket"],inplace=True,axis=1)
#处理缺失值,对缺失值较多的列进行填补,有一些特征只确实一两个值,可以采取直接删除记录的方法
data["Age"] = data["Age"].fillna(data["Age"].mean())
data = data.dropna()
#将分类变量转换为数值型变量
#将二分类变量转换为数值型变量
#astype能够将一个pandas对象转换为某种类型,和apply(int(x))不同,astype可以将文本类转换为数字,用这个方式可以很便捷地将二分类特征转换为0~1
data["Sex"] = (data["Sex"]== "male").astype("int")
#将三分类变量转换为数值型变量
labels = data["Embarked"].unique().tolist()
data["Embarked"] = data["Embarked"].apply(lambda x: labels.index(x))
X = data.iloc[:,data.columns != "Survived"]
y = data.iloc[:,data.columns == "Survived"]
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y,test_size=0.3)
#修正测试集和训练集的索引
for i in [Xtrain, Xtest, Ytrain, Ytest]:
i.index = range(i.shape[0])
score = cross_val_score(clf,X,y,cv=10).mean()
score
#0.7739274770173645
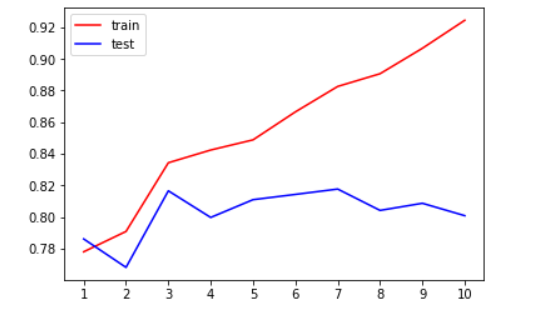
tr = []
te = []
for i in range(10):
clf = DecisionTreeClassifier(random_state=25
,max_depth=i+1
,criterion="entropy"
)
clf = clf.fit(Xtrain, Ytrain)
score_tr = clf.score(Xtrain,Ytrain)
score_te = cross_val_score(clf,X,y,cv=10).mean()
tr.append(score_tr)
te.append(score_te)
print(max(te))
plt.plot(range(1,11),tr,color="red",label="train")
plt.plot(range(1,11),te,color="blue",label="test")
plt.xticks(range(1,11))
plt.legend()
plt.show()
#0.8177860061287026
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/197350.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
