大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
文章目录
常用指令
改库表索引
参考文档
https://www.cnblogs.com/dongling/p/5710643.html
删除索引
删除索引的方法是,使用 DROP INDEX 或 ALTER TABLE 语句。如果要使用 DROP INDEX 语句,则必须给出那个要被删除的索引的名字:
DROP INDEX index_name ON tbl_name;
如果要使用 DROP INDEX 语句来删除 PRIMARY KEY,则必须以带引号标识符的形式给指定名字 PRIMARY:
DROP INDEX 'PRIMARY' ON tbl_name;
创建索引
索引是加快访问表内容的基本手段,尤其是在涉及多个表的关联查询里。这是一个非常重要的话题。
使用 ALTER TABLE 语句可以创建MySQL所支持的任何一种索引:
ALTER TABLE tbl_name ADD INDEX index_name (index_columns);
ALTER TABLE tbl_name ADD UNIQUE index_name(index_columns);
ALTER TABLE tbl_name ADD PRIMARY KEY (index_columns);
ALTER TABLE tbl_name ADD FULLTEXT index_name(index_columns);
ALTER TABLE tbl_name ADD SPATIAL index_name(index_columns);
查看创建表结构命令
show create table 表名
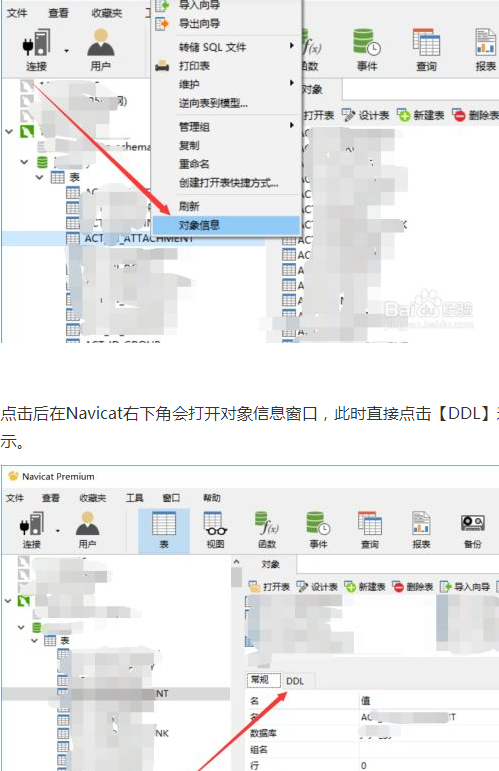

展示表列结构列表
show columns from 表名
show full columns from 表名; //携带注解信息
增 表中新字段
如果想在某列之后增加字段,则参考代码如下:
ALTER TABLE 表名 ADD 新增列名 VARCHAR(255) not null DEFAULT '默认填充内容' AFTER 之前已有列名
改 表的列默认值
alter table 表名 alter column 已有列字段 set default 默认值;
not null 改为 默认为null
alter table business_tree_change modify fail_reason varchar(2048) DEFAULT NULL COMMENT '审核失败原因';

改 表的列数据长度
ALTER TABLE 表名 MODIFY COLUMN 列名 VARCHAR(350);
经典指令
数据库
-- 直接创建字符
-- create database rxguo;
-- 删除当前指定数据库
-- drop database rxguo;
-- 创建带初始字符的库
-- create database rxguo_test DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
-- 指定数据库
-- use `rxguo_test`;
表
注意数值,字符串,时间
自增,默认,非空,注释
索引,外键
字符集,存储引擎
create table `source_conf8`(
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`type` enum('mysql','mongo','replicator') NOT NULL COMMENT '数据源类型',
`name` varchar(255) not null comment '数据源名称',
`price` decimal(8,2) not null comment '单价',
`status` tinyint(3) DEFAULT '0' comment '状态,0正常,1下架',
`config` text not null comment '数据源配置',
`create_time2` timestamp DEFAULT CURRENT_TIMESTAMP not null comment '创建时间',
`update_time2` timestamp DEFAULT CURRENT_TIMESTAMP on update CURRENT_TIMESTAMP not null comment '更新时间',
primary key(`id`) using btree,
unique index `source_conf_name_uindex`(`name`) using btree
)ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic comment '数据源';
-- 删除表
drop table source_conf3;
思考
datatime不考虑时区和自动更新有效期更长timestamp对比
`create_time` datetime not null comment '创建时间',
`update_time` datetime not null comment '更新时间',
Mysql中char,varchar与text类型的区别和选用
、
MySql的时间类型有 Java中与之对应的时间类型
date java.sql.Date
Datetime java.sql.Timestamp
Timestamp java.sql.Timestamp
Time java.sql.Time
Year java.sql.Date
增删改查
增
INSERT INTO `source_conf` VALUES (, ,)
INSERT INTO `source_conf` VALUES (7, 'mysql', 'mimimi', 'test_task24', '_2871', 'mimimi_mysql_test_task24_2871', '{\"database.user\":\"root\",\"database.port\":\"3306\",\"database.hostname\":\"172.31.96.165\",\"database.password\":\"aURXcHVmYmZVRWRjMjA5eng2ZUp4QnhGYmxRQTdtUWJHc2hmMCt3ZnlHaWl2MisvdTNCdWNMQ3hYd1RIMXl1alV6aHlpUnVVRnJhb0k4MjdkYjZnSjZLMzZSanNrcGcrNTJKaStuTjFLa1QydEZzc0RJYTA4QWk0UCtjOEEwTU9ibnFqUEdlV2xWT0gyVWc1cm42bVhlMXNYYUwwSVRLTjUycnp2Y3lmQU5zPQ==\",\"table.include.list\":\"inventory.addresses,inventory.customers\",\"decimal.handling.mode\":\"precise\",\"snapshot.mode\":\"initial\"}', 'PG_mimimi_mysql_test_task24_2871', 9411, 'test task24', '2020-11-02 13:51:41', '2020-11-09 11:01:39', 'mlguo');
INSERT INTO `source_conf` VALUES (18, 'mongo', 'mimimi', 'test_task30', '_4950', 'mimimi_mongo_test_task30_4950', '{\"mongodb.hosts\":\"gml1/172.31.96.157:27017\",\"collection.whitelist\":\"test.testd,test.testc\"}', 'PG_mimimi_mongo_test_task30_4950', 9444, 'test task30', '2020-11-03 15:56:25', '2020-11-03 15:56:25', 'mlguo');
// 明确只插入一条Value
方式1、 INSERT INTO t1(field1,field2) VALUE(v001,v002);
方式2、 INSERT INTO t1(field1,field2) VALUES(v101,v102),(v201,v202),(v301,v302),(v401,v402);
在插入批量数据时方式2优于方式1.
改
UPDATE `source_conf` SET
name = 'rxguo'
WHERE ID = 29;
查
select * from `source_conf`;
ORDER BY id DESC LIMIT 1;
先where 再order by 再limit
group by后过滤条件having
select release_name, count(*) as num from service group by release_name having num > 1;
删
delete from `source_conf` where type = 'mysql';
select * from `source_conf`;
like
SQL LIKE 子句中使用百分号 %字符来表示任意字符,类似于UNIX或正则表达式中的星号 *。
如果没有使用百分号 %, LIKE 子句与等号 = 的效果是一样的。
select * from `source_conf`
where name like 'test_%';
unin
场景:
查询两张表数据中姓名为‘张三’ 学生 共出现的次数?
一个学生出现了多少次
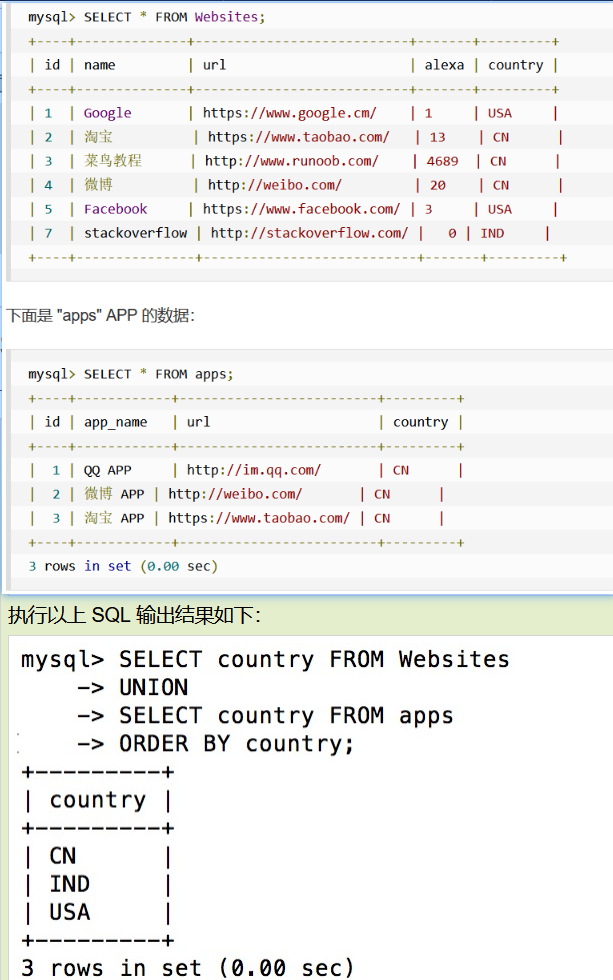
连接两个以上的 SELECT 语句的结果组合到一个结果集合中。多个 SELECT 语句会删除重复的数据。
SELECT 列名称 FROM 表名称 UNION SELECT 列名称 FROM 表名称 ORDER BY 列名称;
UNION [ALL | DISTINCT]
DISTINCT: 可选,删除结果集中重复的数据。默认情况下 UNION 操作符已经删除了重复数据,所以 DISTINCT 修饰符对结果没啥影响。
ALL: 可选,返回所有结果集,包含重复数据。
 all
all
where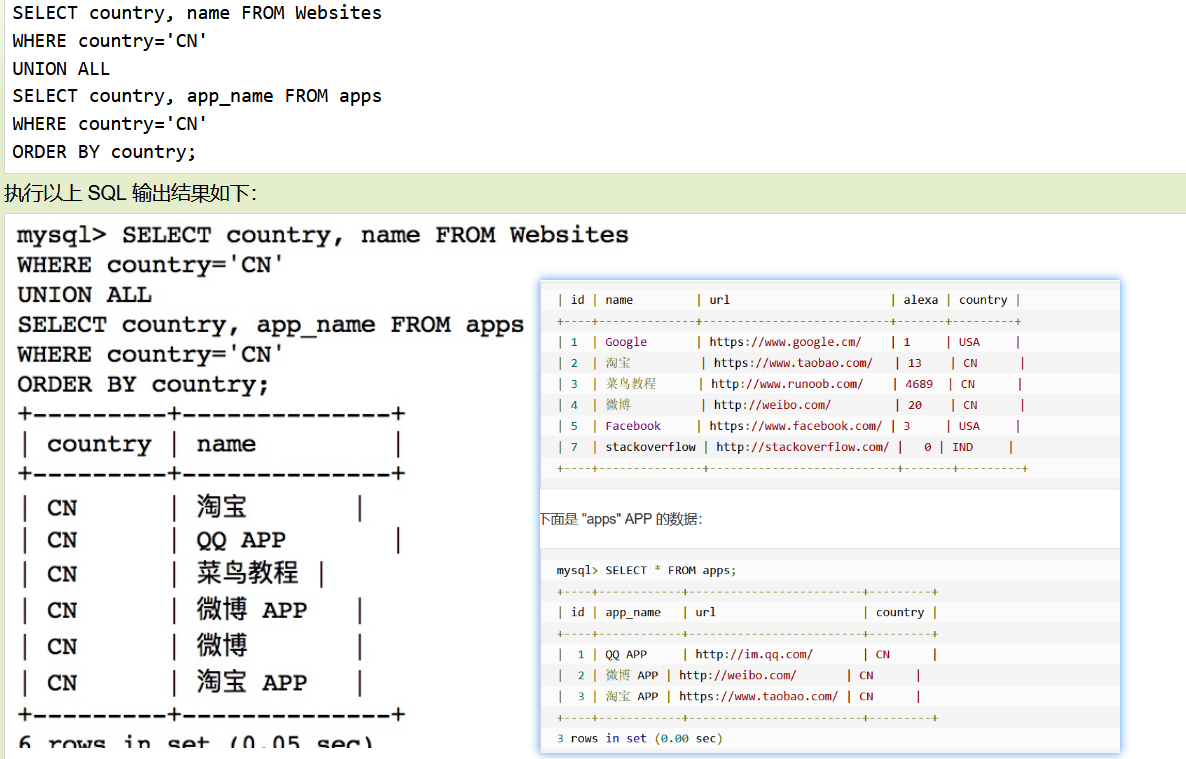
排序ORDER BY
SELECT 语句使用 ORDER BY 子句将查询数据排序后再返回数据:
ASC 或 DESC 关键字来设置查询结果是按升序或降序排列。 默认情况下,它是按升序排列。
mysql> use RUNOOB;
Database changed
mysql> SELECT * from runoob_tbl ORDER BY submission_date ASC;
+-----------+---------------+---------------+-----------------+
| runoob_id | runoob_title | runoob_author | submission_date |
+-----------+---------------+---------------+-----------------+
| 3 | 学习 Java | RUNOOB.COM | 2015-05-01 |
| 4 | 学习 Python | RUNOOB.COM | 2016-03-06 |
| 1 | 学习 PHP | 菜鸟教程 | 2017-04-12 |
| 2 | 学习 MySQL | 菜鸟教程 | 2017-04-12 |
+-----------+---------------+---------------+-----------------+
4 rows in set (0.01 sec)
mysql> SELECT * from runoob_tbl ORDER BY submission_date DESC;
+-----------+---------------+---------------+-----------------+
| runoob_id | runoob_title | runoob_author | submission_date |
+-----------+---------------+---------------+-----------------+
| 1 | 学习 PHP | 菜鸟教程 | 2017-04-12 |
| 2 | 学习 MySQL | 菜鸟教程 | 2017-04-12 |
| 4 | 学习 Python | RUNOOB.COM | 2016-03-06 |
| 3 | 学习 Java | RUNOOB.COM | 2015-05-01 |
+-----------+---------------+---------------+-----------------+
4 rows in set (0.01 sec)
分组GROUP BY
分组的列上我们可以使用 COUNT, SUM, AVG,等函数。
count(*) 计数
mysql> SELECT * FROM employee_tbl;
+----+--------+---------------------+--------+
| id | name | date | singin |
+----+--------+---------------------+--------+
| 1 | 小明 | 2016-04-22 15:25:33 | 1 |
| 2 | 小王 | 2016-04-20 15:25:47 | 3 |
| 3 | 小丽 | 2016-04-19 15:26:02 | 2 |
| 4 | 小王 | 2016-04-07 15:26:14 | 4 |
| 5 | 小明 | 2016-04-11 15:26:40 | 4 |
| 6 | 小明 | 2016-04-04 15:26:54 | 2 |
+----+--------+---------------------+--------+
mysql> SELECT name, COUNT(*) FROM employee_tbl GROUP BY name;
+--------+----------+
| name | COUNT(*) |
+--------+----------+
| 小丽 | 1 |
| 小明 | 3 |
| 小王 | 2 |
+--------+----------+
3 rows in set (0.01 sec)
WITH ROLLUP 总计
WITH ROLLUP 可以实现在分组统计数据基础上再进行相同的统计(SUM,AVG,COUNT…)。
例如我们将以上的数据表按名字进行分组,再统计每个人登录的次数:
mysql> SELECT name, SUM(singin) as singin_count FROM employee_tbl GROUP BY name WITH ROLLUP;
+--------+--------------+
| name | singin_count |
+--------+--------------+
| 小丽 | 2 |
| 小明 | 7 |
| 小王 | 7 |
| NULL | 16 |
+--------+--------------+
4 rows in set (0.00 sec)
// 替换空值
其中记录 NULL 表示所有人的登录次数。
我们可以使用 coalesce 来设置一个可以取代 NUll 的名称,coalesce 语法:
select coalesce(a,b,c);
参数说明:如果a==null,则选择b;如果b==null,则选择c;如果a!=null,则选择a;如果a b c 都为null ,则返回为null(没意义)。
以下实例中如果名字为空我们使用总数代替:
mysql> SELECT coalesce(name, '总数'), SUM(singin) as singin_count FROM employee_tbl GROUP BY name WITH ROLLUP;
+--------------------------+--------------+
| coalesce(name, '总数') | singin_count |
+--------------------------+--------------+
| 小丽 | 2 |
| 小明 | 7 |
| 小王 | 7 |
| 总数 | 16 |
+--------------------------+--------------+
4 rows in set (0.01 sec)
连接join
JOIN 在两个或多个表中查询数据。
你可以在 SELECT, UPDATE 和 DELETE 语句中使用 Mysql 的 JOIN 来联合多表查询。
INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。
LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。
RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
测试数据
mysql> use RUNOOB;
Database changed
mysql> SELECT * FROM tcount_tbl;
+---------------+--------------+
| runoob_author | runoob_count |
+---------------+--------------+
| 菜鸟教程 | 10 |
| RUNOOB.COM | 20 |
| Google | 22 |
+---------------+--------------+
3 rows in set (0.01 sec)
mysql> SELECT * from runoob_tbl;
+-----------+---------------+---------------+-----------------+
| runoob_id | runoob_title | runoob_author | submission_date |
+-----------+---------------+---------------+-----------------+
| 1 | 学习 PHP | 菜鸟教程 | 2017-04-12 |
| 2 | 学习 MySQL | 菜鸟教程 | 2017-04-12 |
| 3 | 学习 Java | RUNOOB.COM | 2015-05-01 |
| 4 | 学习 Python | RUNOOB.COM | 2016-03-06 |
| 5 | 学习 C | FK | 2017-04-05 |
+-----------+---------------+---------------+-----------------+
5 rows in set (0.01 sec)

INNER JOIN(也可以省略 INNER 使用 JOIN,效果一样)
来连接以上两张表来读取runoob_tbl表中所有runoob_author字段在tcount_tbl表对应的runoob_count字段值:
INNER JOIN
mysql> SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a INNER JOIN tcount_tbl b ON a.runoob_author = b.runoob_author;
+-------------+-----------------+----------------+
| a.runoob_id | a.runoob_author | b.runoob_count |
+-------------+-----------------+----------------+
| 1 | 菜鸟教程 | 10 |
| 2 | 菜鸟教程 | 10 |
| 3 | RUNOOB.COM | 20 |
| 4 | RUNOOB.COM | 20 |
+-------------+-----------------+----------------+
4 rows in set (0.00 sec)
等价于where(自我感觉where方便)
WHERE 子句
mysql> SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a, tcount_tbl b WHERE a.runoob_author = b.runoob_author;
+-------------+-----------------+----------------+
| a.runoob_id | a.runoob_author | b.runoob_count |
+-------------+-----------------+----------------+
| 1 | 菜鸟教程 | 10 |
| 2 | 菜鸟教程 | 10 |
| 3 | RUNOOB.COM | 20 |
| 4 | RUNOOB.COM | 20 |
+-------------+-----------------+----------------+
4 rows in set (0.01 sec)

LEFT JOIN 会读取左边数据表的全部数据,即便右边表无对应数据。
mysql> SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a LEFT JOIN tcount_tbl b ON a.runoob_author = b.runoob_author;
+-------------+-----------------+----------------+
| a.runoob_id | a.runoob_author | b.runoob_count |
+-------------+-----------------+----------------+
| 1 | 菜鸟教程 | 10 |
| 2 | 菜鸟教程 | 10 |
| 3 | RUNOOB.COM | 20 |
| 4 | RUNOOB.COM | 20 |
| 5 | FK | NULL |
+-------------+-----------------+----------------+
5 rows in set (0.01 sec)

会读取右边数据表的全部数据,即便左边边表无对应数据。
尝试以下实例,以 runoob_tbl 为左表,tcount_tbl 为右表,理解MySQL RIGHT JOIN的应用:
RIGHT JOIN
mysql> SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a RIGHT JOIN tcount_tbl b ON a.runoob_author = b.runoob_author;
+-------------+-----------------+----------------+
| a.runoob_id | a.runoob_author | b.runoob_count |
+-------------+-----------------+----------------+
| 1 | 菜鸟教程 | 10 |
| 2 | 菜鸟教程 | 10 |
| 3 | RUNOOB.COM | 20 |
| 4 | RUNOOB.COM | 20 |
| NULL | NULL | 22 |
+-------------+-----------------+----------------+
5 rows in set (0.01 sec)
NULL 值处理
IS NULL: 当列的值是 NULL,此运算符返回 true。
IS NOT NULL: 当列的值不为 NULL, 运算符返回 true。
<=>: 比较操作符(不同于 = 运算符),当比较的的两个值相等或者都为 NULL 时返回 true。
ifnull() 处理带null的数值表
select * , columnName1+ifnull(columnName2,0) from tableName;
columnName1,columnName2 为 int 型,当 columnName2 中,有值为 null 时,
columnName1+columnName2=null, ifnull(columnName2,0)
把 columnName2 中 null 值转为 0。
命令提示符中使用 NULL 值
mysql> SELECT * from runoob_test_tbl;
+---------------+--------------+
| runoob_author | runoob_count |
+---------------+--------------+
| RUNOOB | 20 |
| 信息 | NULL |
| Google | NULL |
| FK | 20 |
+---------------+--------------+
4 rows in set (0.01 sec)
关于 NULL 的条件比较运算是比较特殊的。你不能使用 = NULL 或 != NULL 在列中查找 NULL 值 。
在 MySQL 中,NULL 值与任何其它值的比较(即使是 NULL)永远返回 NULL,即 NULL = NULL 返回 NULL 。
以下实例中你可以看到 = 和 != 运算符是不起作用的:
mysql> SELECT * FROM runoob_test_tbl WHERE runoob_count = NULL;
Empty set (0.00 sec)
mysql> SELECT * FROM runoob_test_tbl WHERE runoob_count != NULL;
Empty set (0.01 sec)
查找数据表中 runoob_test_tbl 列是否为 NULL,必须使用 IS NULL 和 IS NOT NULL,如下实例:
mysql> SELECT * FROM runoob_test_tbl WHERE runoob_count IS NULL;
+---------------+--------------+
| runoob_author | runoob_count |
+---------------+--------------+
| 菜鸟教程 | NULL |
| Google | NULL |
+---------------+--------------+
2 rows in set (0.01 sec)
mysql> SELECT * from runoob_test_tbl WHERE runoob_count IS NOT NULL;
+---------------+--------------+
| runoob_author | runoob_count |
+---------------+--------------+
| RUNOOB | 20 |
| FK | 20 |
+---------------+--------------+
2 rows in set (0.01 sec)
正则表达式
MySQL中使用 REGEXP 操作符来进行正则表达式匹配。

事务
默认
在 MySQL 命令行的默认设置下,事务都是自动提交的,即执行 SQL 语句后就会马上执行 COMMIT 操作。因此要显式地开启一个事务务须使用命令 BEGIN 或 START TRANSACTION,或者执行命令 SET AUTOCOMMIT=0,用来禁止使用当前会话的自动提交。
事务是必须满足4个条件(ACID)::原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。
事务控制语句:
BEGIN 或 START TRANSACTION 显式地开启一个事务;
COMMIT 也可以使用 COMMIT WORK,不过二者是等价的。COMMIT 会提交事务,并使已对数据库进行的所有修改成为永久性的;
ROLLBACK 也可以使用 ROLLBACK WORK,不过二者是等价的。回滚会结束用户的事务,并撤销正在进行的所有未提交的修改;
SAVEPOINT identifier,SAVEPOINT 允许在事务中创建一个保存点,一个事务中可以有多个 SAVEPOINT;
RELEASE SAVEPOINT identifier 删除一个事务的保存点,当没有指定的保存点时,执行该语句会抛出一个异常;
ROLLBACK TO identifier 把事务回滚到标记点;
SET TRANSACTION 用来设置事务的隔离级别。InnoDB 存储引擎提供事务的隔离级别有READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ 和 SERIALIZABLE。
MYSQL 事务处理主要有两种方法:
1、用 BEGIN, ROLLBACK, COMMIT来实现
BEGIN 开始一个事务
ROLLBACK 事务回滚
COMMIT 事务确认
2、直接用 SET 来改变 MySQL 的自动提交模式:
SET AUTOCOMMIT=0 禁止自动提交
SET AUTOCOMMIT=1 开启自动提交
mysql> use RUNOOB;
Database changed
mysql> CREATE TABLE runoob_transaction_test( id int(5)) engine=innodb; # 创建数据表
Query OK, 0 rows affected (0.04 sec)
mysql> select * from runoob_transaction_test;
Empty set (0.01 sec)
mysql> begin; # 开始事务
Query OK, 0 rows affected (0.00 sec)
mysql> insert into runoob_transaction_test value(5);
Query OK, 1 rows affected (0.01 sec)
mysql> insert into runoob_transaction_test value(6);
Query OK, 1 rows affected (0.00 sec)
mysql> commit; # 提交事务
Query OK, 0 rows affected (0.01 sec)
mysql> select * from runoob_transaction_test;
+------+
| id |
+------+
| 5 |
| 6 |
+------+
2 rows in set (0.01 sec)
mysql> begin; # 开始事务
Query OK, 0 rows affected (0.00 sec)
mysql> insert into runoob_transaction_test values(7);
Query OK, 1 rows affected (0.00 sec)
mysql> rollback; # 回滚
Query OK, 0 rows affected (0.00 sec)
mysql> select * from runoob_transaction_test; # 因为回滚所以数据没有插入
+------+
| id |
+------+
| 5 |
| 6 |
+------+
2 rows in set (0.01 sec)
mysql>
修改表名 表字段 Alter
修改数据表名或者修改数据表字段
修改表名
alter table source_conf rename to source_config;
增加表字段
alter table source_config add nid int;
指定新增字段的位置
貌似没啥用
FIRST (设定位第一列), AFTER 字段名(设定位于某个字段之后)ALTER TABLE testalter_tbl DROP i;
ALTER TABLE testalter_tbl ADD i INT FIRST;
ALTER TABLE testalter_tbl DROP i;
ALTER TABLE testalter_tbl ADD i INT AFTER c;
删除表字段
alter table source_config drop nid;
修改字段类型及名称
如果需要修改字段类型及名称, 你可以在ALTER命令中使用 MODIFY 或 CHANGE 子句 。
例如,把字段 c 的类型从 CHAR(1) 改为 CHAR(10),可以执行以下命令:
mysql> ALTER TABLE testalter_tbl MODIFY c CHAR(10);
使用 CHANGE 子句, 语法有很大的不同。 在 CHANGE 关键字之后,紧跟着的是你要修改的字段名,然后指定新字段名及类型。尝试如下实例:
mysql> ALTER TABLE testalter_tbl CHANGE i j BIGINT;
ALTER TABLE 对 Null 值和默认值的影响
当你修改字段时,你可以指定是否包含值或者是否设置默认值。
以下实例,指定字段 j 为 NOT NULL 且默认值为100 。
mysql> ALTER TABLE testalter_tbl
-> MODIFY j BIGINT NOT NULL DEFAULT 100;
索引
单列索引 组合索引
(一般作为 WHERE 子句的条件)。
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
普通索引 唯一索引在前面添加
如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length。
// 创建
CREATE INDEX indexName ON table_name (column_name)
修改表结构(添加索引)
ALTER table tableName ADD INDEX indexName(columnName)
直接创建
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX name_index (username(16))
);
组合索引
alter table source_config add index `com_index`(type, name, project);
显示索引信息
show index from mytable;
临时表
临时表只在当前连接可见,当关闭连接时,Mysql会自动删除表并释放所有空间。
可以提前手动释放
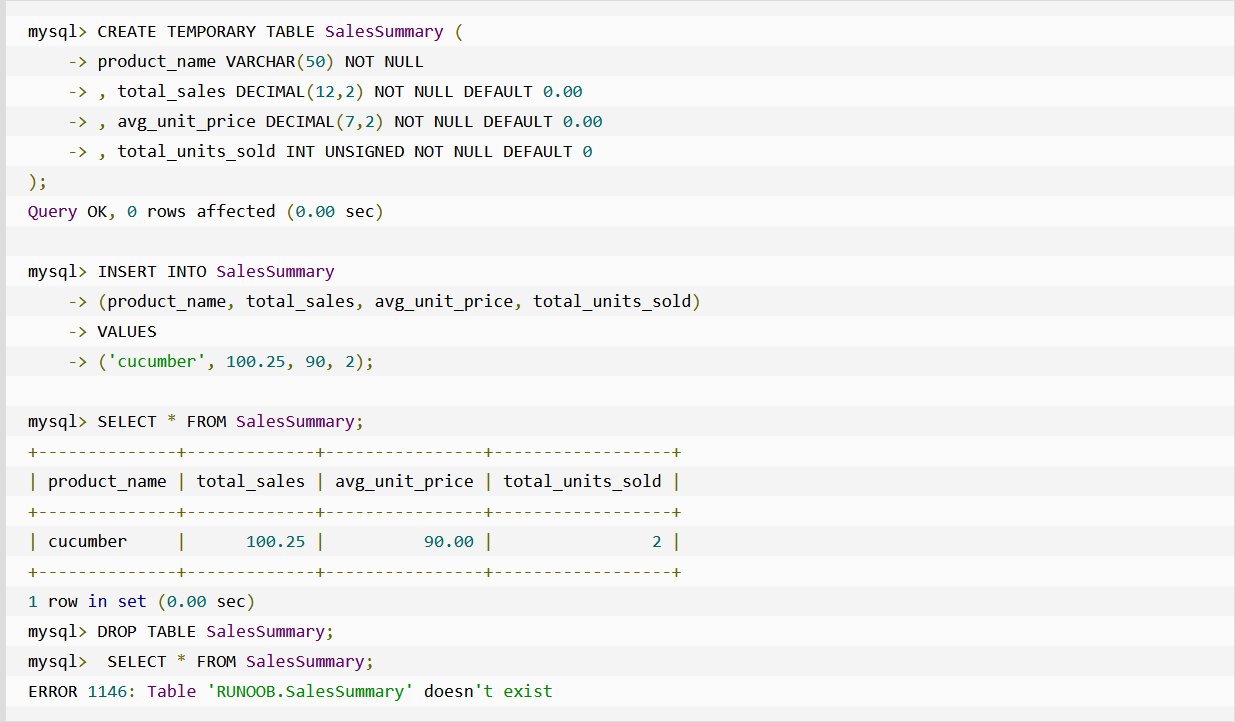 用查询直接创建临时表的方式:
用查询直接创建临时表的方式:
CREATE TEMPORARY TABLE 临时表名 AS
(
SELECT * FROM 旧的表名
LIMIT 0,10000
);
复制表
如果我们需要完全的复制MySQL的数据表,包括表的结构,索引,默认值等。 如果仅仅使用CREATE TABLE … SELECT 命令,是无法实现的。
如何完整的复制MySQL数据表,步骤如下:
使用 SHOW CREATE TABLE 命令获取创建数据表(CREATE TABLE) 语句,该语句包含了原数据表的结构,索引等。
复制以下命令显示的SQL语句,修改数据表名,并执行SQL语句,通过以上命令 将完全的复制数据表结构。
如果你想复制表的内容,你就可以使用 INSERT INTO … SELECT 语句来实现。
1获取创建语句
show create table source_config;
2创建结构+索引
CREATE TABLE `clone_config` (
3拷贝数据表的数据你可以使用 INSERT INTO... SELECT
insert into clone_config
select * from source_config;
元数据
查询结果信息: SELECT, UPDATE 或 DELETE语句影响的记录数。
数据库和数据表的信息: 包含了数据库及数据表的结构信息。
MySQL服务器信息: 包含了数据库服务器的当前状态,版本号等。
MYSQL序列
MySQL 序列是一组整数:1, 2, 3, …,由于一张数据表只能有一个字段自增主键, 如果你想实现其他字段也实现自动增加,就可以使用MySQL序列来实现。
获取AUTO_INCREMENT值
SELECT LAST_INSERT_ID()
show table status where name='clone_config'
重置序列
删除的同时又有新记录添加,有可能会出现数据混乱。
-- alter table clone_config drop id;
alter table clone_config
add id int UNSIGNED NOT NULL AUTO_INCREMENT FIRST,
add PRIMARY key(id);
加粗样式序列初始值
1创建时设置
)engine=innodb auto_increment=100 charset=utf8;
2alter添加设置
mysql> ALTER TABLE t AUTO_INCREMENT = 100;
处理重复数据
建立主键+索引防止
双主键 或 双唯一
CREATE TABLE person_tbl
(
first_name CHAR(20) NOT NULL,
last_name CHAR(20) NOT NULL,
sex CHAR(10),
PRIMARY KEY (last_name, first_name)
);
UNIQUE (last_name, first_name)
略过已插入过的数据
INSERT IGNORE INTO
mysql> INSERT IGNORE INTO person_tbl (last_name, first_name)
-> VALUES( 'Jay', 'Thomas');
Query OK, 1 row affected (0.00 sec)
mysql> INSERT IGNORE INTO person_tbl (last_name, first_name)
-> VALUES( 'Jay', 'Thomas');
Query OK, 0 rows affected (0.00 sec)
出现重复则替换删除当前重新添加 REPLACE INTO
统计重复数据
mysql> SELECT COUNT(*) as repetitions, last_name, first_name
-> FROM person_tbl
-> GROUP BY last_name, first_name
-> HAVING repetitions > 1;
过滤重复数据
DISTINCT 和 group by
mysql> SELECT DISTINCT last_name, first_name
-> FROM person_tbl;
mysql> SELECT last_name, first_name
-> FROM person_tbl
-> GROUP BY (last_name, first_name);
删除重复数据
重建表,重命名
mysql> CREATE TABLE tmp SELECT last_name, first_name, sex FROM person_tbl GROUP BY (last_name, first_name, sex);
mysql> DROP TABLE person_tbl;
mysql> ALTER TABLE tmp RENAME TO person_tbl;
添加主键限制法
mysql> ALTER IGNORE TABLE person_tbl
-> ADD PRIMARY KEY (last_name, first_name);
SQL 注入
网页获取用户输入的数据并将其插入一个MySQL数据库
1.永远不要信任用户的输入。对用户的输入进行校验,可以通过正则表达式,或限制长度;对单引号和 双"-"进行转换等。
2.永远不要使用动态拼装sql,可以使用参数化的sql或者直接使用存储过程进行数据查询存取。
3.永远不要使用管理员权限的数据库连接,为每个应用使用单独的权限有限的数据库连接。
4.不要把机密信息直接存放,加密或者hash掉密码和敏感的信息。
5.应用的异常信息应该给出尽可能少的提示,最好使用自定义的错误信息对原始错误信息进行包装
6.sql注入的检测方法一般采取辅助软件或网站平台来检测,软件一般采用sql注入检测工具jsky,网站平台就有亿思网站安全平台检测工具。MDCSOFT SCAN等。采用MDCSOFT-IPS可以有效的防御SQL注入,XSS攻击等。
Like语句中的注入% 注意字符转义
待完善

实践
-- create database test_rxguo default character set utf8 collate utf8_general_ci;
-- use test_rxguo;
create table source_config(
`id` int(11) not null AUTO_INCREMENT COMMENT '主键ID',
`type` enum('mysql','mongodb','replicator') not null comment '数据源类型',
`project` varchar(255) not null comment '项目',
`name` varchar(255) not null comment '数据源名称',
`suffix` varchar(50) not null comment '数据源后缀',
`connector_name` varchar(255) not null comment 'connector名称',
`config` text not null comment '数据源配置',
`pgroup_name` varchar(255) not null comment '生产组名称',
`pgroup_id` int(11) not null comment '生产组ID',
`note` varchar(255) comment '注释',
`create_time` datetime not null comment '创建时间',
`update_time` datetime not null comment '更新时间',
PRIMARY KEY(`id`) using btree,
UNIQUE INDEX `source_conf_name_uindex`(`name`) using btree
)ENGINE = INNODB CHARACTER SET = utf8 COLLATE = utf8_general_ci comment '数据源配置';
导入导出
直接用可视化工具得了
函数
日期 高级
https://www.runoob.com/mysql/mysql-functions.html
coalesce返回第一个非null值
语法
coalesce(expression_1, expression_2, …,expression_n)依次参考各参数表达式,遇到非null值即停止并返回该值。如果所有的表达式都是空值,最终将返回一个空值。使用coalesce在于大部分包含空值的表达式最终将返回空值。
用法
select coalesce(exp1,exp2,…) as a from table_name
select coalesce(real_name, “xiaoai”) from table_name
当real_name 为null值的时候,将返回xiaoai,否则将返回real_name的具体值。
运算符
不建议使用,最好只存储,运算放到逻辑处理
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/197048.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
