大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
本文分别介绍了区块链与联邦学习的研究现状、架构和运行原理、主要技术及局限性,并针对区块链与联邦学习所存在的问题,通过分析区块链与联邦学习各自的特点,探讨了如何将区块链与联邦学习进行融合互补,介绍了两种融合模型及其应用场景。
文章目录
1. 区块链概述
1.1 区块链的研究现状
2008年10月,化名为“中本聪”的学者在密码学论坛上公开了《比特币:一种点对点的电子现金系统》一文[1],提出了利用PoW和时间戳机制构造交易区块的链式结构,剔除了可信第三方,实现了去中心化的匿名支付。比特币于2009年1月上线并发布创世块,标志着首个基于区块链技术应用的诞生。2010—2015年,比特币逐渐进入大众视野。2016—2018年,随着各国陆续对比特币进行公开表态以及世界主流经济的不确定性增强,比特币的受关注程度激增,需求量迅速扩大。事实上,比特币是区块链技术最成功的应用场景之一。2015年12月,英国政府发布了《分布式账本技术:超越区块链》[2],预测区块链将引起新一轮技术变革,建议加快区块链理论推广与应用开发进程。我国工信部于2016年10月发布了《中国区块链技术与应用发展白皮书(2016)》[3]。国务院在《“十三五”国家信息化规划》中将区块链列入战略性前沿科技之一。同年,世界经济论坛也对区块链在金融场景下的应用进行预测分析,认为区块链将在跨境支付、保险、贷款等多方面重塑金融市场基础设施。
目前区块链的发展可以分为如下3个阶段[4]。
1)区块链1.0—称为可编程货币阶段。 区块链技术是伴随着数字货币比特币而生,随后还产生了莱特币(Litecoin)、以太币(Ether)等数字货币。数字货币在支付过程中,不再需要中心权威机构参与,降低了支付成本,对传统的金融市场有强烈的影响。
2)区块链2.0—可编程金融系统。 在比特币成功应用以后,研究者将其应用扩展到其他的金融领域。智能合约(smart contract)的理念在1995年就已经被法律学者尼克·萨博提出来,但是由于技术问题一直被搁置。区块链很好地解决了智能合约中的技术难题,使得可编程的智能合约可被应用于金融领域。区块链的应用范围从单一的数字货币扩展到其他金融领域。
3)区块链3.0—可编程社会。 随着区块链技术的发展,区块链开始被应用于物联网、智慧农业、医疗、供应链、匿名投票等领域。由此,区块链技术已经开始对互联网产生了根本的影响。区块链可以分为3个类别,分别是以比特币为代表的公开的公有链、半公开状态的组织内部使用的联盟链以及完全封闭的私有链。
伴随着以太坊等开源区块链平台的诞生以及大量去中心化应用的落地,区块链技术在更多的行业中得到了应用。从记账的角度出发,区块链是一种分布式账本技术或账本系统; 从协议的角度出发,区块链是一种解决数据信任问题的互联网协议;从经济学的角度出发,区块链是一个提升合作效率的价值互联网。近年来,区块链逐渐从加密数字货币演变为一种提供可信区块链即服务的平台,各行各业均对区块链青睐有加,积极探索“区块链+”的行业应用创新模式。区块链包含社会学、经济学和计算机科学的一般理论和规律,就计算机技术而言,包含分布式存储、点对点网络、密码学、智能合约、拜占庭容错和共识算法等一系列复杂技术。由于跨学科融合支撑,使得区块链构建了一个在数字世界中自治理、可信赖、可溯源的系统。
当前区块链的广泛应用,主要是利用了其以下特点[5]:
1)身份管理。区块链通过哈希地址以及权限认证等,实现对参与节点的安全管理。
2)数据记录。借助非对称加密(如椭圆曲线)、哈希算法等技术,区块链上的数据具有透明、可追溯、防篡改等特性。
3)激励机制。区块链通过激励机制,如数字货币,确保参与方共同维持区块链的运转。
4)共识机制。共识机制是区块链在分布式节点间保证数据安全可靠的关键。通过共识机制,各个参与方对数据进行认证,可以有效降低数据被篡改的风险,确保链上数据的一致性。
1.2 区块链的架构及其运行原理
区块链通用层次化技术结构(如图1.1[6]),自下而上分别为网络层、数据层、共识层、控制层和应用层。其中,网络层是区块链信息交互的基础,承载节点间的共识过程和数据传输,主要包括建立在基础网络之上的对等网络及其安全机制;数据层包括区块链基本数据结构及其原理;共识层保证节点数据的一致性,封装各类共识算法和驱动节点共识行为的奖惩机制;控制层包括沙盒环境、自动化脚本、智能合约和权限管理等,提供区块链可编程特性,实现对区块数据、业务数据、组织结构的控制;应用层包括区块链的相关应用场景和实践案例,通过调用控制合约提供的接口进行数据交互。 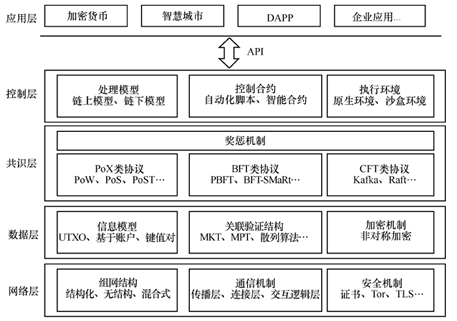

图1.1 区块链层次化技术结构
以比特币为例,区块链工作原理具体如下:
1)节点构造新的交易,并将新的交易向全网进行广播。
2)接收节点对收到的交易进行检验,判断交易是否合法,若合法,则将交易纳入一个新区块中。
3)全网所有矿工节点(网络中具有对交易打包和验证能力的节点)对上述区块执行共识算法,选取打包节点。
4)该节点通过共识算法将其打包的新区块进行全网广播。
5)其他节点通过校验打包节点的区块,经过数次确认后,将该区块追加到区块链中。
比特币系统的数据结构如图1.2所示,比特币中的交易被组织成为默克尔树结构。交易均被存储在默克尔树的叶子节点上,通过两两合并哈希直至得到根节点。根节点的哈希值作为一个区块头的元素,除此之外,区块头还包括时间戳、Nonce 和前一区块哈希值等。Nonce是矿工完成工作量证明算法时的输入,也是矿工获取奖励的凭证。区块头包含前一区块的哈希值,使得每一个区块逻辑上以链的方式串联起来。默克尔树结构可使得在仅有部分节点的情况下,快速验证交易的有效性,并大幅减少节点的存储空间。
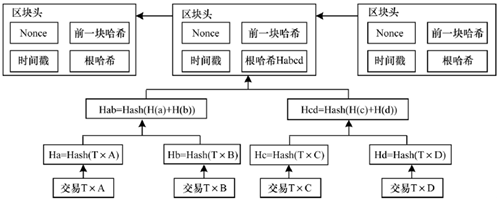
图1.2 比特币系统的数据结构
1.3 区块链的主要技术
1.3.1共识算法
区块链系统的节点可自由加入组织,具备自治性,为更好适应区块链系统,大多系统采用P2P网络进行数据传播。P2P网络中的每个节点均会承担网络路由、验证区块数据、传播区块数据、发现新节点等功能。为驱使区块链中的节点有效参与共识过程,区块链的共识算法包括设计合理的经济激励机制和公平选取特定的打包节点。
区块链网络中的共识算法包括工作证明(proof of work,PoW)、权益证明(proof of stake,POS)、委托权益证明(delegated proof of stake,DPOS)、实用拜占庭容错(practical byzantine fault tolerance,PBFT)算法以及在物联网领域兴起的一种基于有向无环图的缠结共识算法(tangle)。下面将详细介绍各共识机制的工作原理及其应用领域。
1)PoW
PoW算法最早在比特币中使用,其核心思想是通过节点的算力竞争来选取打包节点。比特币系统中的各节点基于各自的计算机算力相互竞争来共同解决一个求解复杂但是验证容易的SHA256数学难题,最快解决该难题的节点将获得下一区块的记账权和系统自动生成的比特币奖励。矿工通过不断尝试随机数使得计算得到的区块哈希值小于难度值,当找到合适的随机数后,广播该随机数和对应区块,随后其他节点验证该区块的合法性,因此,算力越高,得到记账权的几率越大。基于PoW的区块链(如比特币)的去中心化程度较高,节点可以自由进出系统,基于算力竞争的共识算法可以最多抵抗50%攻击。
然而,PoW也存在明显的缺陷,其矿工重复和循环的算力消耗造成巨大资源浪费,而且长达10min的交易确认时间使其不适合小额交易的商业应用。比特币每秒最多能够处理7笔交易,可用性较低。而且PoW方式容易造成矿工联合成集中式的矿池,背离了原来去中心化的初衷,也提升了矿工集体合谋进行51%攻击的可能性。PoW中区块是概率确定的,如果追加在区块上的区块数越多,那么该区块的确定性越高,比特币系统认为有6个区块确认才能认为该区块是确定的,也就是一笔交易的确认需要至少1h的时间。
2)PoS
PoS算法的提出是为了解决PoW巨大能源浪费的问题。PoS由系统中具有最高权益而非最高算力的节点获得记账权,其中权益体现为节点对系统虚拟资源的所有权,Peercoin 是币龄或币天数。Peercoin中的挖矿难度由币龄决定,拥有更多币龄的用户有更高的概率决定下一个区块并获得出块的奖励,在成功出块后相应的币龄会清空,这样可以保证区块链的有效性由具有经济权益的用户来保障,同时避免PoW的大量能源消耗。
PoS共识算法中的权益一般指用户在区块链上的虚拟资源,常用持有token数量或持有token时间来衡量。根据用户持有权益的大小决定该用户挖矿的难度,权益越高,挖矿的难度就越低。通过权益的大小来决定记账权可以有效避免资源浪费,进而缩短出块时间和交易的处理时间。PoS可以通过提高区块链系统的每秒事务处理量提高可用性。PoS共识算法的去中心化程度较高,节点可以方便加入或者退出区块链系统。基于PoS的系统仍然需要进行挖矿,且区块的确定性也是概率型的,需要其他多个节点对区块确认后完成最终确定。
3)BFT
在BFT算法中,当拜占庭节点不超过总节点数的1/3时,拜占庭将军问题才能解决。原始的BFT算法分为口头协议和书面协议。在口头协议中,节点之间需要将接收到的“命令”相互传输,最终根据得到的各个节点的信息确定最终结果。书面协议需要对传输的信息进行签名验证,该协议可以防止拜占庭节点随意更改接收到的信息,使最终结果更加可靠。实用拜占庭容错(PBFT)算法的提出解决了原始BFT算法信息传输复杂度较高的问题。PBFT主要包括3个阶段:预准备,准备,提交。该算法可以较快达到最终结果,但是PBFT不适用于大规模的公链场景,因为节点越多,通信时间越长,共识成本较高,所以PBFT适用于节点较少的联盟链或者私链,例如Hyperledger Fabric。PBFT主要解决原始BFT共识算法效率较低的问题,将通信复杂度从指数级降低到二次方级别,使其能够在实际系统中使用。
4)DPoS
DPoS共识的基本思路类似于“董事会决策”,即系统中每个节点可以将其持有的股份权益作为选票授予一个代表,希望参与记账并且获得票数最多的前N个代表节点将进入“董事会”,按照既定的时间表轮流对交易进行打包结算并且生产新区块。如果说PoW和PoS共识分别是“算力为王”和“权益为王”的记账方式的话,DPoS 则可以认为是“民主集中式”的记账方式,其不仅能够较好地解决PoW 浪费能源和矿池对去中心化构成威胁的问题,也能够弥补PoS中拥有记账权益的参与者不希望参与记账的缺点,其设计者认为DPoS是当时最快速、高效、去中心化和灵活的共识算法。DPoS 共识算法可与PBFT 一起使用,先通过DPoS的方式在区块链系统中选取一定数量的出块者,当出块者生成一个区块后,用PBFT 算法在所有出块者中进行区块共识,当PBFT共识过程结束才能将区块记录在账本中。
在DPoS共识算法下,用户通过抵押一定数量的权益成为记账候选人,其他用户利用投票结果来确定记账候选人的排名,得到票数最多的几个节点拥有某个时间片的记账权,例如EOS设置票数最多的21个节点为记账节点。投票排名会在一段时间后更新,重新选择出块者。DPoS共识因为共识节点数量较少,节点间的通信速度快,可以快速完成区块打包、广播以及验证,显著提升系统TPS,增强平台应用的可用性。DPoS算法中参与记账的节点大幅减少,因此其是通过牺牲去中心化为代价而实现TPS的提升。
5)共识算法对比
基于共识算法评价标准,表1.1对PoW、PoS、DPoS、PBFT的性能、去中心化程度、容错节点比例、确定性和资源消耗方面进行性能对比。
表1.1 常用共识算法性能对比结果
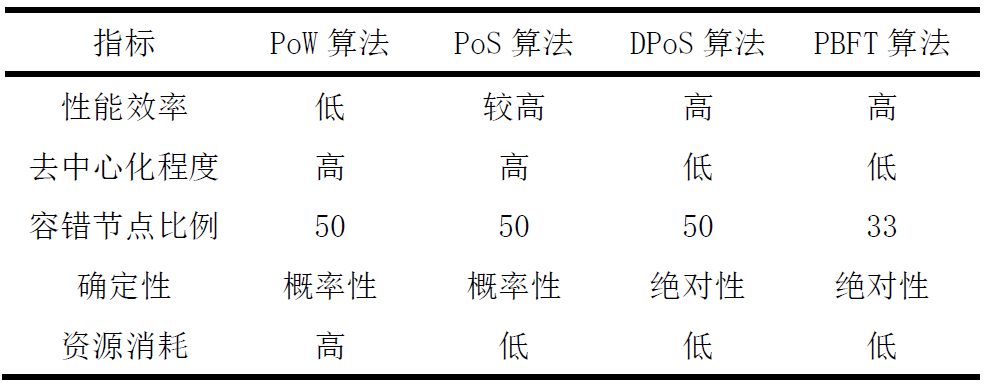
在“不可能三角”的评价体系中,任何的共识算法都无法达到3个特性的最好状态,需要在3个特性中进行权衡。PoW选择了去中心化和安全性,但可用性较低。PoS相对于PoW节约能源,但是不够灵活。PBFT算法保证了去中心化和安全性,但存在大规模节点时可用性较差。DPoS算法选择了高可用性和安全性,但是去中心化程度较低。
目前的区块链系统中还没有各方面性能都最优的共识算法,只能通过权衡系统需求达到特定的目标。在保证区块链系统安全性的同时,要不断提升可用性以适用于大规模应用,同时在满足一定的去中心化程度的情况下中的用户能积极参与到共识中,并使所有参与投票、共识、验证的节点能够从中获利,所以共识算法的经济激励也是不可或缺的一部分。只有充分使系统中的资源流通以及用户交互、参与,才能实现区块链系统的稳固运行。
1.3.2智能合约
智能合约是一套以数字形式定义的承诺,包括合约参与方可以在其上执行这些承诺的协议。这些承诺指的是合约参与方同意的权利与义务,并且在智能合约中定义了实施办法。由此可见,智能合约不一定需要使用区块链技术,只是因为区块链技术能够较好地支持智能合约。简言之,智能合约是传统合约的数字化版本,在区块链上是可执行程序。与传统程序一样,区块链智能合约拥有接口部分,接口可以接收和响应外部消息,并处理和储存外部消息。
在加密货币中,类似智能合约的功能为:1)验证交易中的签名是否正确;2)验证交易的输入和输出金额是否匹配;3)更新输入和输出账户的余额状态。以比特币为例,比特币只有不到200种操作命令,通过栈式脚本语言完成上述动作,实现转账功能。
智能合约不是直接运行在区块链节点已知的环境中,因为合约代码如果直接操作区块链,尤其是写区块链的数据,会导致合约不受管制,破坏区块链数据结构,威胁区块链节点的安全,所以智能合约必须在隔离的沙箱环境中运行。合约运行环境和宿主系统之间、合约与合约之间通过沙箱环境有效隔离,这既符合解耦合的设计,也提升了智能合约的安全性。目前,主流区块链平台对沙箱的支持主要包括虚拟机和容器,它们都能有效保证合约代码在沙箱中独立执行。
1.4 区块链的局限性
当前,区块链技术仍面临一些挑战。首先,是计算和认证的效率问题。为了达成各个分布式参与方之间的记录一致,区块链需要消耗大量额外的计算资源。传统的共识认证机制如工作量证明(PoW)等,虽然提升了区块链的安全性,但高昂的计算开销也成为了制约区块链出块速度的瓶颈。如何提高区块链交易认证的效率,是提升区块链计算效率的关键。其次,是如何实现区块链智能化。智能合约的提出,拓宽了区块链的应用范围,然而智能合约的“智能”仍然有待进一步加强。如何基于区块链,实现网络的边缘智能,需要进一步的研究。
2. 联邦学习概述
联邦学习是一种分布式的机器学习方法,即参与方对本地数据进行训练后将更新的参数上传至服务器,再由服务器进行聚合得到总体参数的学习方法。与传统机器学习技术相比,联邦学习不仅可以提高学习效率,还能解决数据孤岛问题,保护本地数据隐私。
2.1联邦学习的研究现状
在当前人工智能和深度学习浪潮中,存在两个突出而尖锐的难题——“数据孤岛”难题和隐私安全难题。在这个背景下,联邦学习应运而生。联邦学习在2016年由谷歌最先提出,用于建立移动终端与服务器之间的共享模型,从而在大规模数据背景下有效地利用这些数据资源,并且保证用户的隐私安全。但这些分散地数据大多是异构且不平衡的,为此,Jakub等提出了一个实用高效地优化算法来处理数据分布问题。之后,又有大量地研究来进一步优化联邦学习模型,如文献[7]提出了两种方法来减小通信消耗,从而实现更加髙效的训练过程;文献[8]解决了之前联邦学习机制中共享模型可能会偏向于某些参与方的问题,保证了参与方间的公平性;文献[9]提出单样本/少样本探索式的学习方法来解决压缩式联邦学习中的通信问题。
联邦学习一经推出,就受到广泛的关注。各大科技金融龙头也开始进行开源项目的搭建,如WeBank开发地FATE、Google推出的Tensor Flow Federated(TFF)、Uber开源的Horovod等。联邦学习已经被广泛应用于无线通信与边缘计算、智慧金融、智慧医疗、环境保护等领域,未来有望改变时代的商业模式,深入影响到智能城市的建设。
2.2联邦学习的定义及分类
联邦学习面向的场景是分散式多用户{?1,…,??},每个用户客户端拥有当前用户的数据集,{?1,…,??}表示这些用户的数据集。传统的深度学习将这些数据收集在一起,得到汇总数据集?=?1∪…∪??,训练得到模型?SUM。联邦学习方法则是参与的用户共同训练一个模型?FED,同时用户数据??保留在本地,不对外传输。如果存在一个非负实数?,使得?FED的模型精度?FED与?SUM的模型精度?SUM如下不等式成立:|?FED − ?SUM| < ?则称该联邦学习算法达到?-精度损失[10]。
联邦学习具有以下优势与特点:
1)用户隐私保护。联邦学习数据只存储在本地,各参与方数据不共享,保证了用户数据的隐私,满足了《通用数据保护条例》的要求。
2)适应大规模数据的模型训练。大规模的训练数据可以提高训练模型的质量。采用联邦学习可以保证训练出的模型效果无损,同时可以减小对训练过程中的设备要求,提高模型训练速度。
3)增强了数据来源的灵活性。在联邦学习的技术支持下,一些原本因为特定因素无法参与训练的数据源,可以将数据存放在本地的同时参与总体模型的训练,更好地提升模型的泛化效果。
根据数据分布的不同情况,联邦学习大致分为3类:横向联邦学习、纵向联邦学习与联邦迁移学习。
1)横向联邦学习指的是在不同数据集之间数据特征重叠较多而用户重叠较少的情况下,按照用户维度对数据集进行切分,并取出双方数据特征相同而用户不完全相同的那部分数据进行训练。
2)纵向联邦学习指的是在不同数据集之间用户重叠较多而数据特征重叠较少的情况下,按照数据特征维度对数据集进行切分,并取出双方针对相同用户而数据特征不完全相同的那部分数据进行训练。
3)联邦迁移学习指的是在多个数据集的用户与数据特征重叠都较少的情况下,不对数据进行切分,而是利用迁移学习来克服数据或标签不足的情况。
表2.1 三类联邦学习的对比

2.3联邦学习的局限性
新技术的出现往往是一把“双刃剑”,联邦学习也不例外。联邦学习面临着一些挑战。首先是通信负载。联邦学习需要将迭代的传输训练参数上传至服务器,参与用户数目以及训练迭代次数的增加,会带来大量的链路传输开销。其次是参与用户的互信问题。由于联邦学习的参与方来自不同的组织或机构,彼此之间缺少信任。如何在缺乏互信的场景下建立安全可靠的协作机制,是实际应用中亟待解决的问题。第三是联邦学习需要一个中心服务器来聚合局部模型,如果这个中心服务器发生故障,将直接严重影响全局模型的训练。此外,联邦学习也面临一些安全风险。一方面,参与方所提供的参数缺乏相应的质量验证机制。恶意的参与用户可能会提供虚假的模型参数来破坏学习过程。如果这些虚假参数未经验证便聚合到整体模型中,会直接影响整体模型的质量,甚至会导致整个联邦学习过程失效。另一方面,参数在传输以及存储过程中的隐私性需要进一步保护加强。近期的一些研究表明,恶意的用户可以依据联邦学习梯度参数在每一轮中的差异,通过调整其输入数据逼近真实梯度,从而推测出用户的敏感数据。除了上述问题,联邦学习中参与用户的异构性、模型参数的聚合算法、用户通信链路的可靠性等,都值得进一步深入研究。
3. 区块链与联邦学习的互补与融合
3.1模型概述
两项技术的目标都是在去中心化网络中增强节点之间的互信。联邦学习旨在实现“数据可用不可见”的隐私保护技术,并通过融合使用各方数据提升用户服务的质量,进而创造出新的价值。区块链旨在确保交易记录不可篡改,利用共识算法、分布式技术解决在去中心化网络中的双重支付问题,最终实现数字世界的价值表示和价值转移。针对上述区块链与联邦学习所存在的问题,分析区块链与联邦学习各自的特点,下文探讨如何将区块链与联邦学习进行融合互补。
区块链赋能联邦学习。区块链为联邦学习的各个参与方(用户)提供了一种可信的机制。通过区块链尤其是联盟链的授权机制、身份管理等,可以将互不可信的用户作为参与方整合到一起,建立一个安全可信的合作机制。此外,联邦学习的模型参数可以存储在区块链中,保证了模型参数的安全性与可靠性。
联邦学习赋能区块链。区块链节点有限的存储能力与区块链较大存储需求之间的矛盾,一直是限制区块链发展的瓶颈所在。通过联邦学习对原始数据的处理,仅存储计算结果,可以降低存储资源的开销。此外,基于联邦学习对区块链交易的认证计算、传输通信等进行优化,可以提升区块链的运行效率。
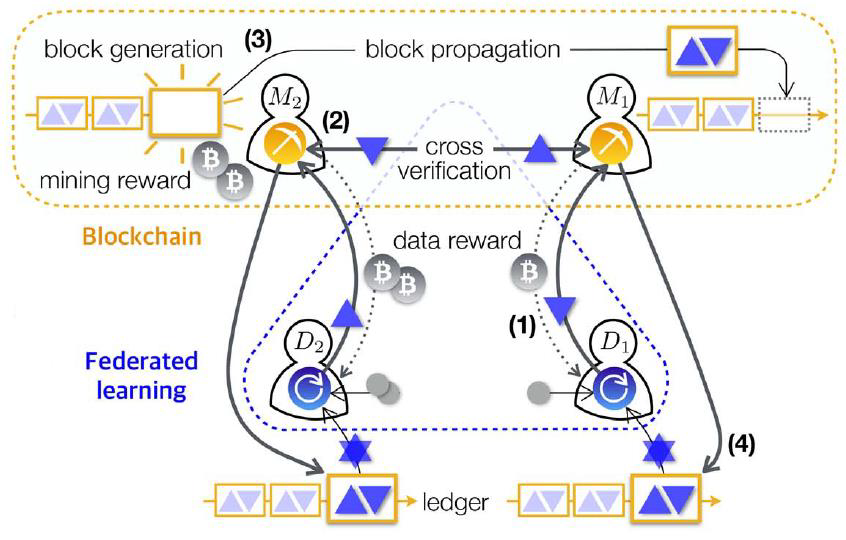
图3.1 基于区块链的联邦学习模型架构
基于以上分析,提出区块链与联邦学习相融合的架构BlockFL[11](如图3.1)。BlockFL的逻辑结构由设备和矿工组成。矿工在物理上是随机选择的设备或单独的节点。每个设备在BlockFL网路中计算并上传本地模型更新到相关联的矿工,设备从矿工那里获得数据奖励。矿工交换和验证所有的本地模型更新,然后运行工作量证明机制POW。当矿工完成POW,将生产一个新的区块,并且从区块链上获得挖矿奖励。区块里记录了验证的本地模型的更新,然后将存储本地聚合模型更新的区块添加到区块链中,再由每个设备下载,设备从新的块中计算全局模型更新。本地设备上的全局模型更新可以确保在矿工或者设备故障时不会影响其他设备的全局模型更新。这样普通设备用户和矿工用户都能得到最新的全局更新模型,同时形成对用户的激励作用。
另有文章将边缘计算和区块链结合,提出了一套适用与联邦学习的系统模型[12](如图3.2)。
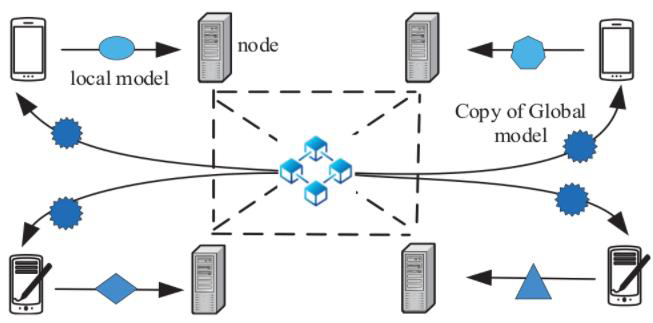
图3.2 融合边缘计算和区块链的联邦学习架构
该架构主要分为用户层和边缘服务层。用户主要由物联网设备、移动终端等构成;服务端主要由配备有移动边缘计算服务器、具备一定存储与计算能力的基站构成。
该架构依据功能可以划分为联邦学习和区块链两个模块。其中,联邦学习本地训练运行在用户侧,依据用户侧的数据学习本地模型参数。区块链则运行在边缘服务侧,接收并存储联邦学习的模型参数,并通过共识协议对参数进行认证。
其整体流程如下:
1)用户本地训练。参与的用户在本地依据所持有的数据,通过基于梯度下降的算法,寻找模型参数,使损失函数最小化。
2)服务端参数收集。用户训练的模型参数,通过无线网络传输至边缘服务层,基站收集来自各个用户的参数,并以交易的形式存储在各区块链节点。
3)产生交易区块。各参与节点收集来自用户层的交易(模型参数),并通过加密签名,打包进区块。节点间通过运行共识机制,决定出块权所属。获得出块权的节点,将区块广播至全网,认证通过后加入区块链。
4)模型聚合。位于边缘服务层的聚合节点依据区块链上的记录,聚合模型参数,并更新整体的模型。进一步,将该模型下发至各参与用户,从而开始新一轮的训练学习。
以上基于区块链与联邦学习的架构,将区块链安全、可信,以及联邦学习分布式智能、保护数据隐私等特点进行了互补,提升了系统整体的安全性,构建了更为智能的区块链机制。然而,区块链共识机制的效率,是限制系统整体性能、影响进一步应用的瓶颈。
3.2应用场景
区块链与联邦学习的融合技术方案,可以在无线网络中建立一种安全可靠的分布式计算机制,在资源共享、智能交通以及网络数据分析等场景中有着广泛的应用前景。
1)资源共享
在下一代无线网络中,终端设备数量的迅猛增长以及大量低时延应用的出现,使得网络的频谱、数据等资源变得日趋紧张。资源共享是解决资源紧缺问题的有效手段。如何建立有效的资源感知、管理机制,确定资源优化分配的方案,是实现资源高效共享的关键。
利用空闲的资源信息进行分析预测可以高效地进行资源的动态共享。而中心化的资源信息数据库具有较高的维护及通信成本,同时面临单点故障等安全风险。通过利用区块链进行资源信息动态认知,不仅可以降低成本,其分布式特性还可以支持更多的用户接入。但在实际应用中,还需要统筹考虑业务特性、资源信息以及节点能力等,实现资源的动态分配。而区块链本身难以达成上述功能。
考虑无线环境中设备计算和存储资源的限制,基于本文所提出的技术方案,我们将联邦学习与区块链相融合,实现资源的智能共享。首先从区块链获取并分析可共享的资源信息;进而依据可用资源、业务负荷、用户特性以及服务质量(QoS)要求等,设计系统的资源共享效用函数;最后以效用函数最大化为目标,通过联邦学习计算适用于分布式边缘场景的资源优化分配策略。在所提出的区块链赋能联邦学习的资源共享场景中,有闲置频谱、数据等资源的用户成为资源提供者,有相应资源使用需求的用户则作为消费者。多个资源提供者通过区块链节点网络,为资源请求者提供相应的共享资源。资源共享的事件同时作为交易被记录在区块链中,资源使用者可以通过区块链支付资源的使用费用。
2)智能交通
将区块链与联邦学习的融合方案应用于智能交通领域,可以提升用户的驾驶体验、车辆运行安全以及交通效率。其中,车辆作为用户层,持有数据并运行本地联邦学习训练。路边单元(Road Side Unit, RSU) 则作为边缘服务层,维护区块链并执行模型参数的聚合。具体而言,联邦学习所训练的模型,可用于车联网中交通流量预测、车辆间多媒体资源共享策略制定以及车辆的驾驶路径智能规划等。而区块链可以在多个参与方之间建立一个可信机制,并且确保所传递数据的可靠性。
3)网络数据分析
网络数据分析(Network Data Analytics Function, NWDAF) 是5G技术中一项重要的内容,它允许网络中的设备利用人工智能技术监测和分析网络的运行情况。为了实现这一功能,NWDAF可以获取网络中的各部分数据内容。然而,网络中的很多数据会涉及较为敏感的信息,完全开放的数据内容将会带来较高的安全风险。采用本文所提出的基于区块链的联邦学习架构,每个核心网的实体可以在其内部运行联邦学习算法,仅将所学习的本地模型发送给NWDAF功能实体,从而在保护数据安全的同时,提升网络的性能表现。
3.3总结与挑战
本节探讨了将区块链与联邦学习互补融合的可能性,并介绍了一种基于区块链的联邦学习架构及技术方案。在此方案中,通过区块链对联邦学习的参数进行存储以及认证,显著提高了联邦学习的安全性与可靠性。而联邦学习的引入,也为“智能区块链”提供了更多的可能。
区块链与联邦学习的融合,提供了一套安全、可靠、智能的机制。然而,二者的融合也会带来一些额外的问题。首先,如何提升区块链的效率,以更好地驱动联邦学习,是提升系统整体效率所面临的问题。其次,如何降低联邦学习迭代过程所引入的额外通信开销,仍然需要进一步研究。
参考文献
- [1]Nakanoto S. Bitcoin: a peer-to-peer electronic cash system[EB/OL][J]. https://bit- coin.org/bitcoi n.pdf.
- [2]Walport M.Distributed ledger technology:beyond blockchain[Online][J],available:https://www.gov.uk/government/news/distributed-ledger-technology-beyond-block-chain,October 5, 2018
- [3]Ministry of Industry and Information Technology.Chinese blockchain technology and application developme- nt white paper2016 [Online][J],available:http://www.fullrich.com/Uploads/article/le/2016/1020/580866e3740 69.pdf, October 5, 2018.
- [4]曹傧,林亮,李云等.区块链研究综述[J].重庆邮电大学学报(自然科学版).2020,32-1(1-14).
- [5]张彦等.区块链与联邦学习:融合与互补[J].中国计算机学会通讯.2020,16-2(17-22).
- [6]曾诗钦等.区块链技术研究综述:原理、进展与应用[J].通信学报.2020,41-1(134-151).
- [7]Konecny J, Mcmahan H B,Yu F X, et al. Feaderated learning: Strategies for improving communication efficiency[J]. arXiv preprint, arXiv: 1610.05492,2016.
[8]Mohri M, Sivek G, Suresh A T. Agnostic federated learning[J]. arXiv preprint, arXiv: 190200146, 2019. - [9]Yurockin M, Agarwal M, Ghosh S, et al. Bayesian nonparametric federated learning of neural network[J]. ArXiv preprint, arVix:1905.12022, 2019.
[10]Yang Q, Liu Y, Chen T, et al. Federated machine learning: concept and applications[J]. ACM Transac- tions on Intelligent Systems and Technology, 2019, 10(2): 1-19. - [11]Hyesung K, Jihong P, Mehdi B,Seong-Lyun K. Blockchained On-Device Federated Learning[J]. IEEE COMMUNICATIONS LETTERS, 2020,24-6(1279-1283).
- [12]Umer M, Choong S H. FLchain: Federated Learning via MEC-enabled Blockchain Network[J]. IEICE–The 20th Asia-Pacific Network Operations and Management Symposium (APNOMS) 2019.
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/196781.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
