大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
word2vec理解
学习nlp最先了解的概念应该就是词嵌入(word embedding)吧,Word2vec是一种有效的词嵌入的方法,采用了两种模型(CBOW与skip-gram模型)与两种优化方法(负采样与层次softmax方法)的组合。现在使用Word2vec获得词的向量表达,并将其应用于各种nlp任务中已经非常常见。
由于我们要用计算机来完成各种自然语言理解的任务,而对于计算机来说,人类世界的各种语言文字符号,它根本就不认识,它只能理解数字化的对象,所以需要将自然语言“翻译”成计算机能理解的形式。
One-hot Representation
比较简单的“翻译”方式是One-hot Representation,即词的独热表示。这种词表示方法是将每个词表示成一个向量,向量的长度等于语料中所有词的个数,向量中该单词位置的元素是1,其他位置的元素都是0。比如一个语料中有两个句子,“易烊千玺喜欢我”,“我喜欢李现”,那么这个语料中每个词的独热词表示如下:
“易烊千玺”表示为:[1 0 0 0]
“喜欢”表示为:[0 1 0 0]
“我”表示为:[0 0 1 0]
“李现”表示为:[0 0 0 1]
每个词都是茫茫0海中的一个1,(哈哈哈哈这句话是从别的博客中看到的,笑死)。
One-hot Representation这种将一个词转化成一个高维稀疏向量的表示方式比较简单,但缺点也很明显。一个缺陷就是容易造成维度灾难,如果语料中有五万个词,那么每个词向量就是五万维,然而平时用来训练的语料词语数都很多,数量成千上万很常见。另一个缺陷是这种方法无法表示词之间的相关性,每个词之间都是独立的,不包含语义信息无法反映出词语在语义层面的含义。
distributed representation
另外一种“翻译”方式是distributed representation,即词的分布式表达。通过训练,将每个词映射成一个维度固定的向量,这个向量的维度可以自己设定,所以它就不会那么长了。另外由于在训练的过程中考虑了词语的上下文,所以这种方式可以将词语表达成带有语义信息的低维稠密向量。这个“翻译”的过程就是‘词嵌入(word embedding)’。Word2vec就是一种有效的词嵌入的方法。
Word2vec这种词嵌入的方法在训练的过程中考虑了词语的上下文,就是在目标词(x)和目标词的上下文(y)之间建立一个语言模型f(x)=y,对这个语言模型进行训练,从而实现根据上下文的词得到目标词或根据目标词得到其上下文的词。可以说一个词由其上下文的词表示,而相似的词往往拥有相似的上下文语境,所以相似的词用这种方式得到的词向量也相似。
Word2vec用神经网络的方式来建立上下文和目标词之间的语言模型,当神经网络训练结束后,其隐藏层的权重就是我们要的每个词的词向量。所以word2vec是一个通过训练神经网络得到语言模型的任务,只不过这个任务是个幌子,我们实际要的是这个过程中产生的副产物即隐藏层权重,用这个副产物作为每个词的词向量,将获得的词向量送入下游nlp任务中进行应用才是最终目的。
刚刚说了word2vec包括两个模型和两个用来优化模型trick,下面先说两个模型。
CBOW
CBOW模型理解
CBOW模型根据某个中心词前后A个连续的词,来计算该中心词出现的概率,即用上下文预测目标词。模型结构简易示意图如下:
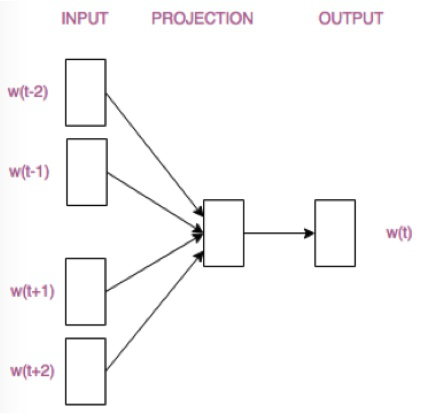

模型有三层,输入层,隐藏层(又叫投影层),输出层。上图模型的window=2,即在中心词前后各选两个连续的词作为其上下文。输入层的w(t-2),w(t-1),w(t+1),w(t+2)是中心词w(t)的上下文。
接下来根据下图,走一遍CBOW的流程,推导一下各层矩阵维度的变化。
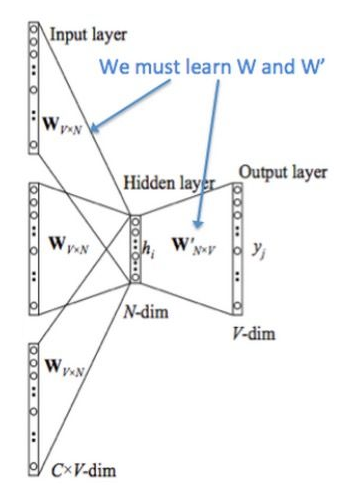
原始语料词库(corpus)中有V个单词。滑动窗口window选为A,那总共选取的上下文词个数C=2A.
1.在输入层,输入的是多个上下文单词的one-hot。
(维度:因为corpus中有V个单词,所以每个单词的one-hot的维度1*V,那么在输入层输入的就是C个1*V的向量,所以在输入层,数据维度为C*V)
2.设定最终获得的词向量的维度为N,初始化输入层与隐藏层之间的权重矩阵w,w维度为V*N。上下文单词的one-hot(C*V)与网络的输入权重矩阵w(V*N)相乘,得到C个1*N的向量。把它们求和再平均,得到隐藏层向量h,维度为1*N.
h = 1 C ( x 1 + x 2 + . . . + x c ) ⋅ w h = \frac{1}{C}({x_1} + {x_2} + … + {x_c}) \cdot w h=C1(x1+x2+...+xc)⋅w
3.初始化隐藏层与输出层之间的权重矩阵 w , {w^,} w,,维度为N*V。
4.隐藏层向量h(1*N)与 w ′ {w\prime} w′(N*V)相乘,得到1*V的向量u, u = h ⋅ w ′ u = h \cdot w\prime u=h⋅w′。为了方便概率表示,将向量u经过softmax,此时向量softmax(u)的每一维代表语料中的一个单词。向量softmax(u)概率最大的位置所代表的单词为模型预测出的中间词。
5.上一步输出的1*V向量与groud truth中的one hot比较。训练的目的是最大化实际中心词出现的概率,基于此定义损失函数,通过最小化损失函数,采用梯度下降算法更新W和W’。当网络收敛则训练完成,此时矩阵W就是我们想要的词向量。如果我们想要知道语料中某个词的向量表示,就用这个词的one-hot乘以权重矩阵w,得到1*N的向量,这个向量就是我们要找的这个词的向量表示。
因为词的one-hot表示中只有一个位置是1,其余都是0,那么与w相乘后,得到的是w中的某一列向量。由于每个词语的 one-hot里面 1 的位置是不同的,所以不同词的one-hot与w相乘,得到的词向量是w中的不同的列向量。所以可见,权重矩阵中的每一列向量都能对应的、唯一的表示corpus中的每一个词。所以要的词向量就是神经网络输入层与隐藏层之间的权重矩阵。
CBOW模型参数训练过程
这里推导的是更一般的情况,即输入的上下文词不止一个的情况。
前向传播:
输入: x (上下文的one-hot)
Input-hidden权重矩阵: w
隐藏层: 当输入的上下文词有多个时,CBOW在计算隐藏层输出时,并不是直接复制输入上下文的词的输入向量,而是取输入的C个上下文词的向量的均值。
h = 1 C w ⊤ ( x 1 + x 2 + . . . + x c ) = 1 C ( v W , I 1 + v W , I 2 + . . . + v W , I c ) ⊤ h = \frac{1}{C}{w^ \top }({x_1} + {x_2} + … + {x_c}) = \frac{1}{C}{({v_{W,I1}} + {v_{W,I2}} + … + {v_{W,Ic}})^ \top } h=C1w⊤(x1+x2+...+xc)=C1(vW,I1+vW,I2+...+vW,Ic)⊤
Hidden-output权重矩阵: w’
输出层每个节点的输入: u j = h ⋅ w ′ = v ′ w j ⊤ h {u_j} = h \cdot w\prime = v{\prime _w}{_j^ \top }{\text{h}} uj=h⋅w′=v′wj⊤h,其中 v ′ w j v{\prime _w}_j v′wj是矩阵w’的第j列向量
输出层每个节点的输出: 就是用softmax获得的词表中每个单词为中心词的概率,
p ( w j ∣ w I 1 , w I 2 , . . . w I C ) = y j = exp ( u j ) ∑ j ′ = 1 v exp ( u j ′ ) p({w_j}|{w_{I1,}}{w_{I2,}}…{w_{IC}}) = {y_j} = \frac{
{\exp ({u_j})}}{
{\sum\limits_{j\prime = 1}^{\text{v}} {\exp ({u_{j\prime }})} }} p(wj∣wI1,wI2,...wIC)=yj=j′=1∑vexp(uj′)exp(uj)
由模型输出的真实中心词的概率为: p ( w O ∣ w I 1 , w I 2 , . . . w I C ) p({w_O}|{w_{I1,}}{w_{I2,}}…{w_{IC}}) p(wO∣wI1,wI2,...wIC)
我们训练的目的就是使这个概率最大。
max p ( w O ∣ w I 1 , w I 2 , . . . w I C ) = max log p ( w O ∣ w I 1 , w I 2 , . . . w I C ) = max log exp ( u j ∗ ) ∑ j ′ = 1 v exp ( u j ′ ) = max ( u j ∗ − log ∑ j ′ = 1 v exp ( u j ′ ) ) \begin{array}{l} \max p({w_O}|{w_{I1,}}{w_{I2,}}…{w_{IC}})\\ {\rm{ = }}\max \log p({w_O}|{w_{I1,}}{w_{I2,}}…{w_{IC}})\\ = \max \log \frac{
{\exp ({u_{
{j^*}}})}}{
{\sum\limits_{_{j\prime } = 1}^{\rm{v}} {\exp ({u_{j\prime }})} }} = \max ({u_{
{j^*}}} – \log \sum\limits_{_{j\prime } = 1}^{\rm{v}} {\exp ({u_{j\prime }})} ) \end{array} maxp(wO∣wI1,wI2,...wIC)=maxlogp(wO∣wI1,wI2,...wIC)=maxlogj′=1∑vexp(uj′)exp(uj∗)=max(uj∗−logj′=1∑vexp(uj′))其中 j ∗ {j^*} j∗表示真实词在词汇表中的下标。
定义损失函数:
E = − log p ( w O ∣ w I 1 , w I 2 , . . . w I C ) = log ∑ j ′ = 1 v exp ( u j ′ ) − u j ∗ = log ∑ j ′ = 1 v exp ( v ′ w j ⊤ ⋅ h ) − v ′ w o ⊤ ⋅ h E = – \log p({w_O}|{w_{I1,}}{w_{I2,}}…{w_{IC}}) = \log \sum\limits_{j\prime = 1}^{\text{v}} {\exp ({u_{j\prime }})} – u{}_{
{j^*}} = \log \sum\limits_{j\prime = 1}^{\text{v}} {\exp (v{\prime _{wj}}^ \top \cdot {\text{h}})} – v{\prime _{wo}}^ \top \cdot {\text{h}} E=−logp(wO∣wI1,wI2,...wIC)=logj′=1∑vexp(uj′)−uj∗=logj′=1∑vexp(v′wj⊤⋅h)−v′wo⊤⋅h
反向传播、随机梯度下降更新权重:
1.损失函数E 对w’取导数,获得隐层到输出层的权重的梯度
∂ E ∂ w ′ = ∂ E ∂ u j ⋅ ∂ u j ∂ w ′ = e j ⋅ h \frac{
{\partial E}}{
{\partial w\prime }} = \frac{
{\partial E}}{
{\partial {u_j}}} \cdot \frac{
{\partial {u_j}}}{
{\partial w\prime }} = {e_j} \cdot h ∂w′∂E=∂uj∂E⋅∂w′∂uj=ej⋅h,其中 e j {e_j} ej 是预测误差, e j = y j − t j {e_j} = {y_j} – {t_j} ej=yj−tj
根据随机梯度下降,得到隐含层和输出层之间的权重更新方程:
w ′ ( n e w ) = w ′ ( o l d ) − η ⋅ e j ⋅ h , f o r j = 1 , 2 , . . . v w{\prime ^{(new)}} = w{\prime ^{(old)}} – \eta \cdot {e_j} \cdot h,for{\text{ }}j = 1,2,…v w′(new)=w′(old)−η⋅ej⋅h,for j=1,2,...v该方程向量方式的写法为: v w j ′ ( n e w ) = v w j ′ ( o l d ) − η ⋅ e j ⋅ h , f o r j = 1 , 2 , . . . v {v_{wj}}{\prime ^{(new)}} = {v_{wj}}{\prime ^{(old)}} – \eta \cdot {e_j} \cdot h,for{\text{ }}j = 1,2,…v vwj′(new)=vwj′(old)−η⋅ej⋅h,for j=1,2,...v其中 v ′ w j v{\prime _w}_j v′wj是矩阵w’的第j列向量,η为学习率。
2.损失函数E 对w取导数,获得输入层到隐层的权重的梯度
∂ E ∂ w = ∂ E ∂ h ⋅ ∂ h ∂ w \frac{
{\partial E}}{
{\partial w}} = \frac{
{\partial E}}{
{\partial h}} \cdot \frac{
{\partial h}}{
{\partial w}} ∂w∂E=∂h∂E⋅∂w∂h,其中 ∂ E ∂ h = ∑ j = 1 v ∂ E ∂ u j ∂ u j ∂ h = ∑ j = 1 v e j w ′ = E H \frac{
{\partial E}}{
{\partial h}} = \sum\limits_{j = 1}^v {\frac{
{\partial E}}{
{\partial {u_j}}}} \frac{
{\partial {u_j}}}{
{\partial h}} = \sum\limits_{j = 1}^v {
{e_j}} w\prime = EH ∂h∂E=j=1∑v∂uj∂E∂h∂uj=j=1∑vejw′=EH
根据随机梯度下降,得到输入层和隐层之间的权重更新方程: w ( n e w ) = w ( o l d ) − 1 c η ⋅ E H {w^{(new)}} = {w^{(old)}} – \frac{1}{c}\eta \cdot EH w(new)=w(old)−c1η⋅EH
该方程向量化的写法为: v ⊤ W , I c ( n e w ) = v ⊤ W , I c ( o l d ) − 1 c η ⋅ E H , f o r c = 1 , 2 , . . . C {v^ \top }{_{W,Ic}^{(new)}} = {v^ \top }{_{W,Ic}^{(old)}} – \frac{1}{c}\eta \cdot EH,for{\text{ }}c = 1,2,…C v⊤W,Ic(new)=v⊤W,Ic(old)−c1η⋅EH,for c=1,2,...C其中 v w , I ⊤ v_{
{
{_w}_{,I}}}^ \top vw,I⊤是矩阵w的第c列向量,η为学习率。
CBOW举例
下面用一个例子来说明CBOW的训练过程,其实主要是想明确一下实际操作时训练样本怎么生成怎么应用,所以具体计算只算了前向传播,计算梯度反向传播嫌麻烦都没算。
假如语料为一句话:Real dream is the other shore of reality.我们设定一个滑动窗口window=2,即中心词左右分别选两个词作为其上下文词。
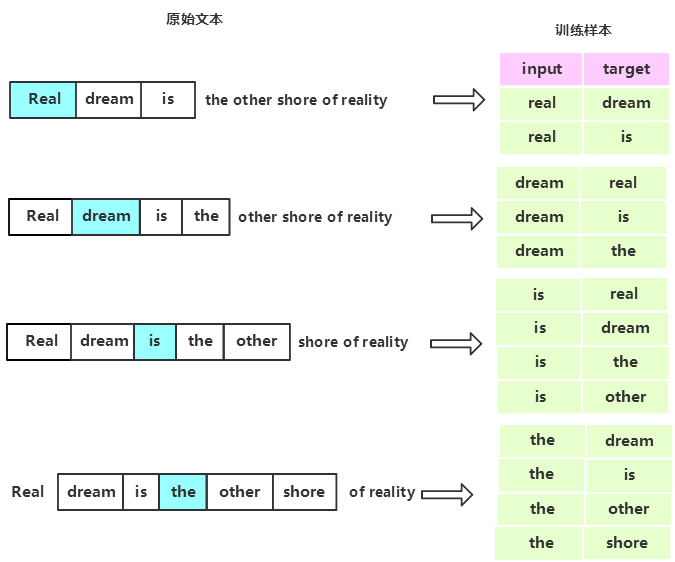
1.在训练前,首先要将原始文本生成训练样本数据。下图展示了根据原始语料生成训练数据的过程。
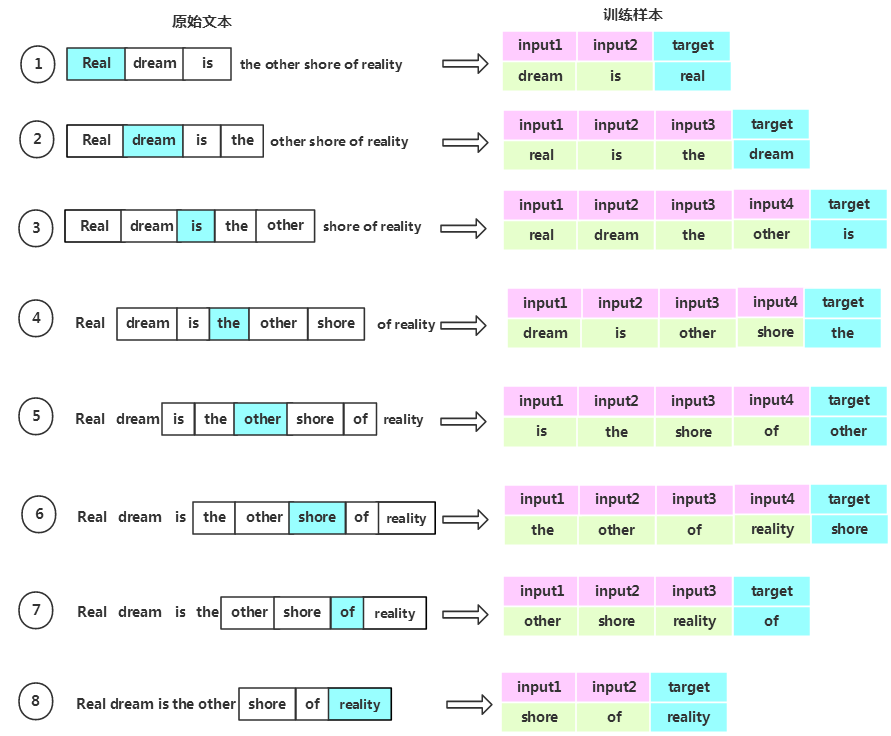
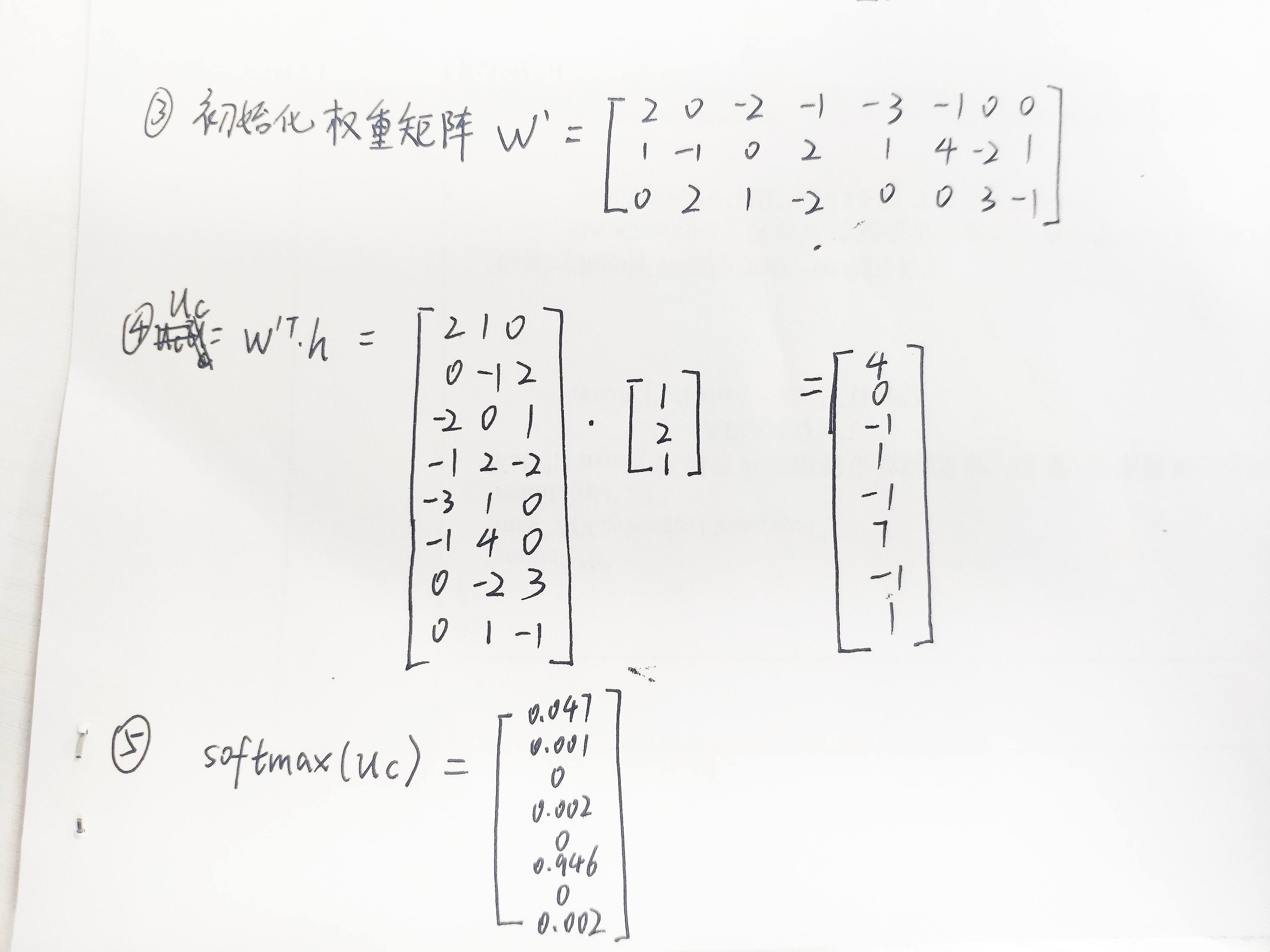
图中蓝色阴影所覆盖的单词为中心词,生成的训练所用的数据。每一个训练样本由多个输入特征和一个输出组成。其中input是feature,output是label。可见,这句文本最后整理成了8个训练样本,下面以第6个样本为例,说明词向量的生成过程。

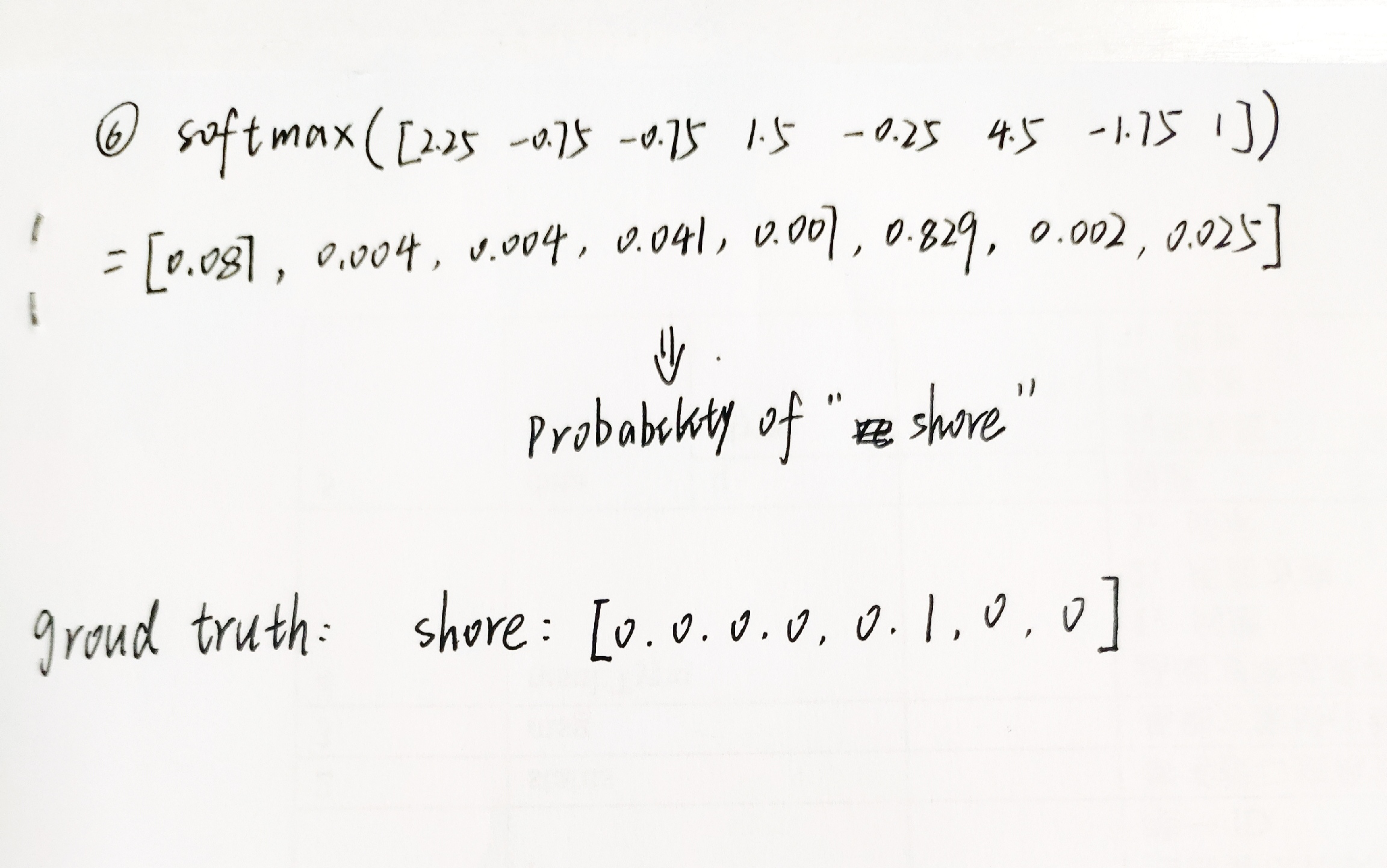
最后网络输出的向量 probability of “shore”,表示了词库中每个词是中心词“shore”的概率大小。训练的目的是使真正的中心词“shore”出现的概率最大,基于此构建损失函数,使用梯度下降法更新网络参数w和w’,直至收敛。那么词向量就是网络收敛后的w。
Skip-Gram
Skip-Gram模型理解
Skip-Gram与CBOW相反,它是用中心词预测其上下文的词。
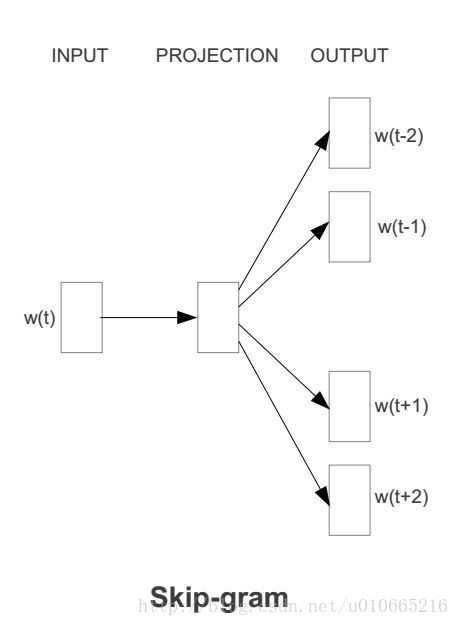
模型有三层,输入层,隐藏层(又叫投影层),输出层。Skip-Gram的参数skip_window表示滑动窗口大小。Skip-Gram还有一个参数num_skips,这个参数表示,对于一个中心词,在window范围随机取 num_skips个词,产生一系列的训练样本。在上图中模型的skip_window=2,即在中心词前后各选两个连续的词进入窗口,所以整个窗口大小span=4。num_skips=4。输入层w(t)表示中心词,输出层w(t-2),w(t-1),w(t+1),w(t+2)是中心词w(t)的上下文词。
接下来走一遍Skip-Gram的流程,其实和CBOW差不多。
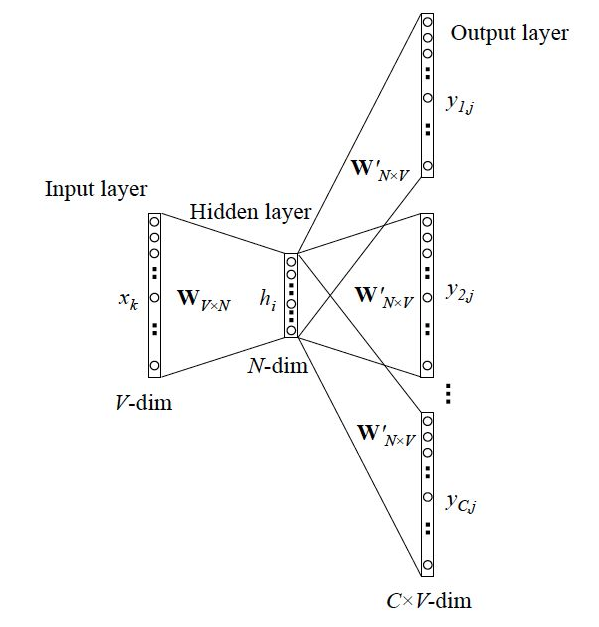
原始语料词库(corpus)中有V个单词,滑动窗口skip_window=C/2,num_skips=C
1.在输入层,输入的是选定的一个中心词的one-hot,维度V*1。
2.设定最终获得的词向量的维度为N,初始化输入层与隐藏层之间的权重矩阵w,维度为V*N。中心词的one-hot(V*1)与输入权重矩阵w(V*N)相乘,得到1个N*1的向量,将其作为隐藏层向量。 h = w ⊤ ⋅ x = v w I ⊤ h = {w^ \top } \cdot x = v_{wI}^ \top h=w⊤⋅x=vwI⊤
3.初始化隐藏层与输出层之间的权重矩阵 w ′ w{\prime} w′,维度为N*V。
4.隐藏层向量h(N*1)与 w ′ w{\prime} w′(N*V)相乘C次,得到 u c , j = w ′ ⊤ ⋅ h = v ′ w j ⊤ ⋅ h {u_{c,j}} = w{\prime ^ \top } \cdot h = v{\prime _{wj}}^ \top \cdot h uc,j=w′⊤⋅h=v′wj⊤⋅h,为了方便概率表示,将向量 u c , j {u_{c,j}} uc,j经过softmax,得到C个V*1的向量,每个V*1向量的每一维代表语料中的一个单词。第C个V*1向量中概率最大的位置所代表的单词,就是由中心词预测出的第c个上下文位置的词。Skip-Gram在输出层不是输出一个多项分布,而是输出C个多项分布。
5.上一步输出的C个V*1向量与C个groud truth中的one hot比较。训练的目的是最大化实际上下文词出现的概率,基于此定义损失函数,通过最小化损失函数,采用梯度下降算法更新W和W’。当网络收敛则训练完成,此时矩阵W就是我们想要的词向量。如果我们想要知道语料中某个词的向量表示,就用这个词的one-hot乘以权重矩阵w,得到N*1的向量,这个向量就是我们要找的这个词的向量表示。
Skip-Gram模型参数训练过程
前向传播:
输入: x (中心词的one-hot)
隐藏层: h = w ⊤ ⋅ x = v w I ⊤ h = {w^ \top } \cdot x = v_{wI}^ \top h=w⊤⋅x=vwI⊤
Hidden-output权重矩阵: w ′ w{\prime} w′
输出层C*V个输出节点,每个节点的净输入: u c , j = w ′ ⊤ ⋅ h = v ′ w j ⊤ ⋅ h {u_{c,j}} = w{\prime ^ \top } \cdot h = v{\prime _{wj}}^ \top \cdot h uc,j=w′⊤⋅h=v′wj⊤⋅h,其中 u c j {u_{cj}} ucj可以理解为输出层第C个上下文位置,第j个单词的净输入, v ′ wj v{\prime _{
{\text{wj}}}} v′wj是 w ′ w{\prime} w′的第j列向量。由于每个输出的节点共享相同的 w ′ w{\prime} w′,所以 u c j = u j {u_{cj}} = {u_j} ucj=uj。
输出层每个节点的输出: 经过softmax,输出层第c个上下文位置上,第j个单词的输出为:
p ( w c , j = w o , c ∣ w I ) = y c , j = exp ( u c , j ) ∑ j ′ = 1 v exp ( u j ′ ) p({w_{c,j}} = {w_{o,c}}|{w_I}) = {y_{c,j}} = \frac{
{\exp ({u_{c,j}})}}{
{\sum\limits_{j\prime = 1}^{\text{v}} {\exp ({u_{j\prime }})} }} p(wc,j=wo,c∣wI)=yc,j=j′=1∑vexp(uj′)exp(uc,j)其中 w c , j {w_{c,j}} wc,j表示输出层第c个上下文位置上的第j个单词; w o , c {w_{o,c}} wo,c表示实际的第c个上下文位置上的单词; w I {w_I} wI表示输入的中心词; y c , j {y_{c,j}} yc,j表示输出层第c个上下文位置上的第j个单词的输出; p ( w c , j = w o , c ∣ w I ) p({w_{c,j}} = {w_{o,c}}|{w_I}) p(wc,j=wo,c∣wI)表示当以一个给定的输入词语作为中心词时,模型输出的第c个上下文位置上的词就是实际的第c个上下文位置词的概率。
我们的训练目标是使,给定一个中心词,模型输出的C个上下文为实际的C个上下文词的概率最大。简单举个栗子,I like apple. like为中心词,I和apple为上下文词。训练目标就是当给定中心词like时,模型在第一个上下文位置和第二个上下文位置输出的词语概率分布中,‘I’和‘apple’的概率最大。即最大化条件概率 p ( w o , 1 , w o , 2 , . . . , w o , c ∣ w I ) = p ( w o , 1 ∣ w I ) ⋅ p ( w o , 2 ∣ w I ) … ⋅ p ( w o , c ∣ w I ) p({w_{o,1}},{w_{o,2}},…,{w_{o,c}}|{w_I}) = p({w_{o,1}}|{w_I}) \cdot p({w_{o,2}}|{w_I}) \ldots \cdot p({w_{o,c}}|{w_I}) p(wo,1,wo,2,...,wo,c∣wI)=p(wo,1∣wI)⋅p(wo,2∣wI)…⋅p(wo,c∣wI)
定义损失函数: E = − log p ( w o , 1 , w o , 2 , . . . , w o , c ∣ w I ) = − log p ( w o , 1 ∣ w I ) ⋅ p ( w o , 2 ∣ w I ) … ⋅ p ( w o , c ∣ w I ) = − log ∏ c = 1 C exp ( u c , j c ∗ ) ∑ j ′ = 1 v exp ( u j ′ ) = − ∑ c = 1 C u j c ∗ + c ⋅ log ∑ j ′ = 1 v exp ( u j ′ ) \begin{array}{l} E = – \log p({w_{o,1}},{w_{o,2}},…,{w_{o,c}}|{w_I})\\ = – \log p({w_{o,1}}|{w_I}) \cdot p({w_{o,2}}|{w_I}) \ldots \cdot p({w_{o,c}}|{w_I})\\ = – \log \prod\limits_{c = 1}^C {\frac{
{\exp ({u_{c,j_c^*}})}}{
{\sum\limits_{j\prime = 1}^{\rm{v}} {\exp ({u_{j\prime }})} }}} \\ = – \sum\limits_{c = 1}^C {
{u_{j_c^*}}} + c \cdot \log \sum\limits_{j\prime = 1}^{\rm{v}} {\exp ({u_{j\prime }})} \end{array} E=−logp(wo,1,wo,2,...,wo,c∣wI)=−logp(wo,1∣wI)⋅p(wo,2∣wI)…⋅p(wo,c∣wI)=−logc=1∏Cj′=1∑vexp(uj′)exp(uc,jc∗)=−c=1∑Cujc∗+c⋅logj′=1∑vexp(uj′)
其中 j c ∗ j_c^* jc∗是实际第C个上下文位置的词在词汇表中的索引。
反向传播、随机梯度下降更新权重:
1.损失函数E 对 w ′ w{\prime} w′取导数,获得隐层到输出层的权重的梯度
∂ E ∂ w ′ = ∑ c = 1 C ∂ E ∂ u c , j ⋅ ∂ u c , j ∂ w ′ = ∑ c = 1 C e c , j ⋅ h \frac{
{\partial E}}{
{\partial w{\prime }}} = \sum\limits_{c = 1}^C {\frac{
{\partial E}}{
{\partial {u_{c,j}}}} \cdot \frac{
{\partial {u_{c,j}}}}{
{\partial w{\prime }}}} = \sum\limits_{c = 1}^C {
{e_{c,j}} \cdot {h}} ∂w′∂E=c=1∑C∂uc,j∂E⋅∂w′∂uc,j=c=1∑Cec,j⋅h
根据随机梯度下降,得到隐含层和输出层之间的权重更新方程:
w ′ ( n e w ) = w ′ ( o l d ) − η ⋅ ∑ c = 1 C e c , j ⋅ h , f o r j = 1 , 2… v w{\prime }^{(new)} = w{\prime }^{(old)} – \eta \cdot \sum\limits_{c = 1}^C {
{e_{c,j}} \cdot {h}} ,for{\text{ }}j = 1,2…v w′(new)=w′(old)−η⋅c=1∑Cec,j⋅h,for j=1,2...v该方程向量形式的写法为: v w j ′ ( n e w ) = v w j ′ ( o l d ) − η ⋅ e c , j ⋅ h , f o r j = 1 , 2 , . . . v {v_{wj}}{\prime ^{(new)}} = {v_{wj}}{\prime ^{(old)}} – \eta \cdot {e_{c,j}} \cdot h,for{\text{ }}j = 1,2,…v vwj′(new)=vwj′(old)−η⋅ec,j⋅h,for j=1,2,...v其中 v w j ′ {v_{wj}}\prime vwj′是矩阵 w ′ w{\prime} w′的第j列向量,η为学习率。
2.损失函数E 对w取导数,获得输入层到隐层的权重的梯度
∂ E ∂ w = ∑ c = 1 C ∂ E ∂ u c , j ⋅ ∂ u c , j ∂ h ⋅ ∂ h ∂ w = ∑ j = 1 v ∑ c = 1 C e c , j ⋅ w ′ \frac{
{\partial E}}{
{\partial w}} = \sum\limits_{c = 1}^C {\frac{
{\partial E}}{
{\partial {u_{c,j}}}} \cdot \frac{
{\partial {u_{c,j}}}}{
{\partial h}} \cdot \frac{
{\partial h}}{
{\partial w}}} = \sum\limits_{j = 1}^v {} \sum\limits_{c = 1}^C {
{e_{c,j}} \cdot w\prime } ∂w∂E=c=1∑C∂uc,j∂E⋅∂h∂uc,j⋅∂w∂h=j=1∑vc=1∑Cec,j⋅w′
根据随机梯度下降,得到输入层和隐层之间的权重更新方程: w ( n e w ) = w ( o l d ) − η ⋅ ∑ j = 1 v ∑ c = 1 C e c , j ⋅ w ′ {w^{(new)}} = {w^{(old)}} – \eta \cdot \sum\limits_{j = 1}^v {} \sum\limits_{c = 1}^C {
{e_{c,j}} \cdot w\prime } w(new)=w(old)−η⋅j=1∑vc=1∑Cec,j⋅w′该方程向量化的写法为: v ⊤ W , I ( n e w ) = v ⊤ W , I ( o l d ) − 1 c η ⋅ E H , f o r c = 1 , 2 , . . . C {v^ \top }{_{W,I}^{(new)}} = {v^ \top }{_{W,I}^{(old)}} – \frac{1}{c}\eta \cdot EH,for{\text{ }}c = 1,2,…C v⊤W,I(new)=v⊤W,I(old)−c1η⋅EH,for c=1,2,...C
Skip-Gram举例
还是用刚才那个例子说明Skip-Gram的过程,也是着重说训练样本的生成和应用以及前向传播。
假如语料为一句话:Real dream is the other shore of reality. 设定skip_window=2,num_skips=4。
1.在训练前,首先要将原始文本生成训练样本数据。下图展示了根据原始语料生成训练样本的过程。这图贼难画。
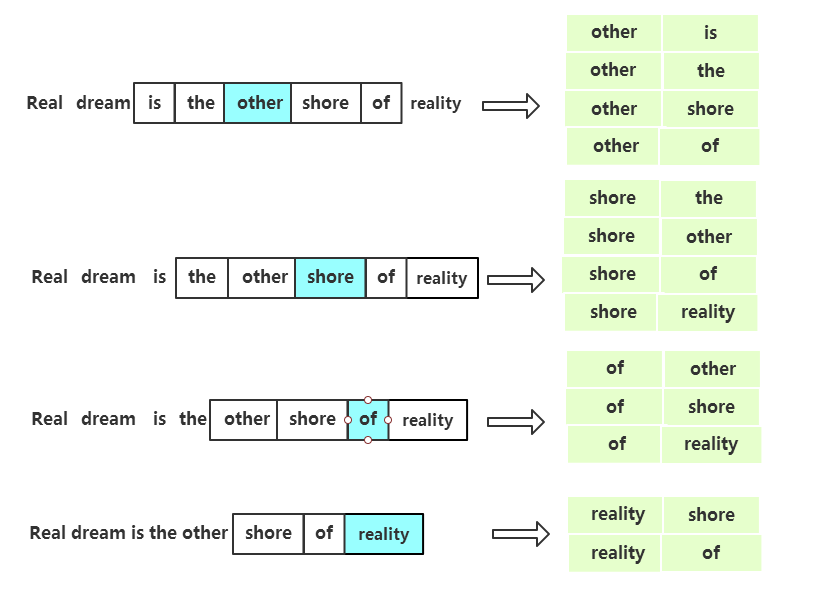
在训练模型之前,要先像上图一样,根据原始语料整理出成对的Training Samples用来训练。上图中原始语料文本中被蓝色阴影所覆盖的单词为中心词,生成的训练所用的单词对,往往将中心词放在第一个位置,其上下文词放在第二个位置。每一个训练样本都是一个输入和一个输出组成的数据对(X,Y)。其中,X是feature,Y是label。下面以一个样本为例,说明一下前向传播的计算过程。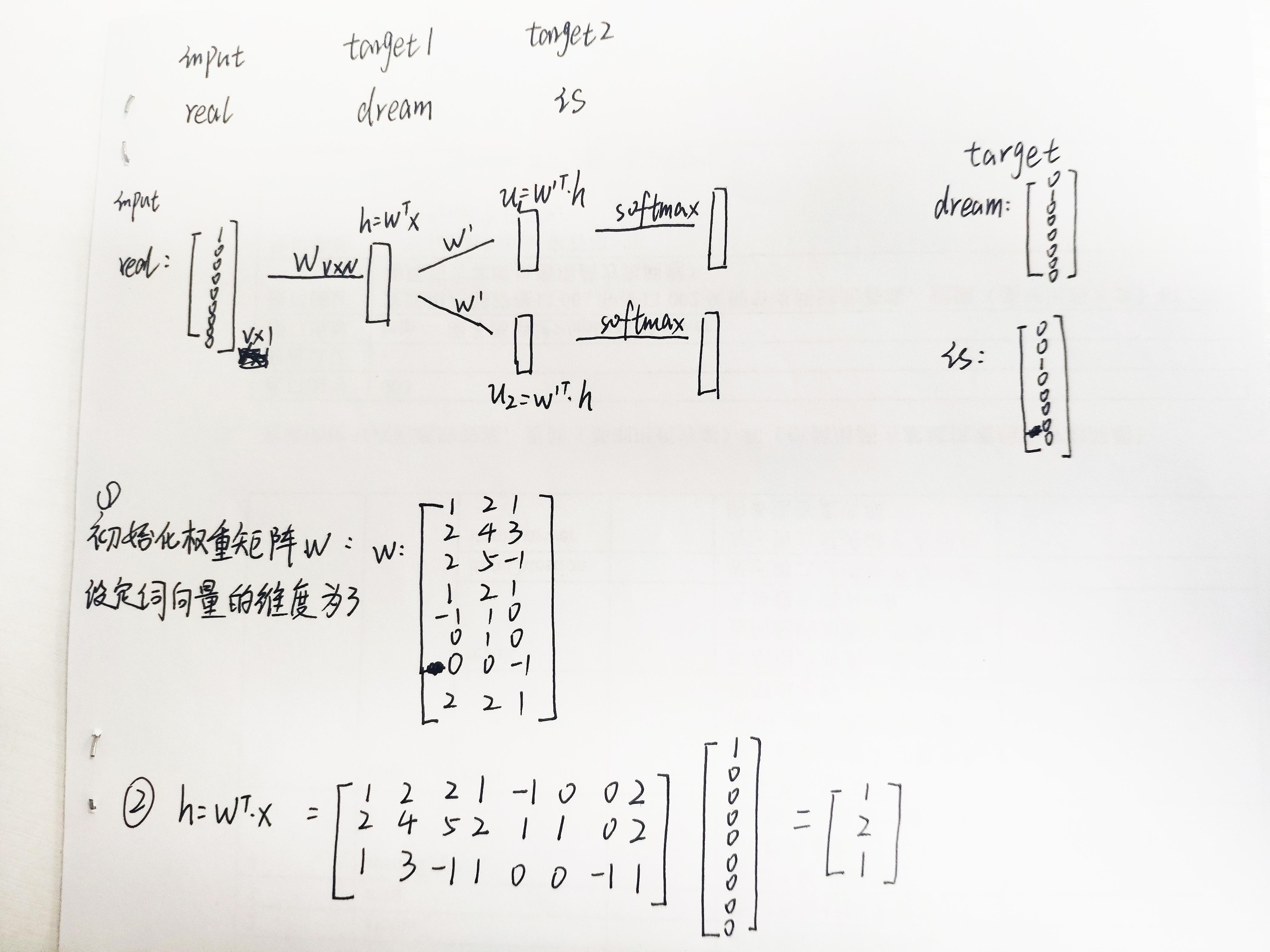
Word2vec还有两个优化方式,层次softmax和负采样。篇幅有点长了,这两个下篇再写吧。
以上。
参考:
- Mikolov T, Chen K, Corrado G, et al. Efficient Estimation of Word Representations in Vector Space[J]. Computer Science, 2013.
- 1411.2738.pdf https://arxiv.org/pdf/1411.2738.pdf,关于训练过程的数学推导主要受益于Xin Rong大佬的这篇讲解,感谢。
- https://jalammar.github.io/illustrated-word2vec/
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/196346.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
