大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
首先,决策树(Decision Tree)是一种基本的分类与回归方法,在这里主要讨论用于分类的决策树。决策树的学习通常包含三个步骤:特征选择,决策树的生成,决策树的剪枝。
- 优点:计算复杂度不高,输出结果易于理解,对中间值的缺失值不敏感,可以处理不相关特征数据。
- 缺点:可能会产生过度匹配的问题。
- 使用数据类型:数值型和标称型。
那么具体的来通过一个例子说明一下决策树。
下面这个例子是通过贷款申请的数据表来判断是否可以贷款。
| 序号 | 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别 |
|---|---|---|---|---|---|
| 1 | 青年 | 否 | 否 | 一般 | 否 |
| 2 | 青年 | 否 | 否 | 好 | 否 |
| 3 | 青年 | 是 | 否 | 好 | 是 |
| 4 | 青年 |
是 |
是 | 一般 | 是 |
| 5 | 青年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 一般 | 否 |
| 7 | 中年 | 否 | 否 | 好 | 否 |
| 8 | 中年 | 是 | 是 | 好 | 是 |
| 9 | 中年 | 否 | 是 | 好 | 是 |
| 10 | 中年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 非常好 | 是 |
| 12 | 老年 | 否 | 是 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 好 | 是 |
| 14 | 老年 | 是 | 否 | 非常好 | 是 |
| 15 | 老年 | 否 | 否 | 一般 | 否 |
在这里第一步根据特征去选择划分的点,那么这个点怎么选择,就是如何选择特征去进行分类。
那么就引出来了,熵的定义,熵是表示随机变量不确定性的度量。熵越大随机变量的不确定性就越大。公式如下:

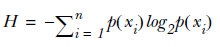
信息增益:特征A对于数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D/A)之差,即
g(D,A)=H(D)-H(D/A)
根据以上介绍,根据信息增益作为最优的选择特征,首先计算经验熵H(D)
H(D)=-9/15*log2(9/15)-6/15*log2(6/15)=0.971
数据集里面共有四个特征A,B,C,D
首先计算在特征A的情况下的信息增益
g(D,A)=H(D)-[5/15*(-2/5log2(2/5)-3/5log2(3/5))+5/15*(-3/5log2(3/5)-2/5log2(3/5))+5/15(-4/5log2(4/5)-1/5log2(1/5))]
=0.971-0.888
=0.083
根据以上分别计算每个特征的信息增益
g(D,B)=0.324
g(D,C)=0.420
g(D,D)=0.363
最后比较各特征的信息增益,由于特征C(有自己的房子)的信息增益最大,所以选择特征C作为最优特征。
以信息增益作为划分数据集的特征,存在偏向于选择取值较多的特征问题,使用信息增益比可以针对这一问题进行校正,这是特征选择的另一准则。C4.5就是根据这一准则进行特征的选择的。
ID3算法就是根据信息增益来进性树的构建。
ID3算法程序(pyhton)实现iris数据集的分类:
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import load_iris from sklearn.tree import DecisionTreeClassifier # Parameters n_classes = 3 plot_colors = "ryb" plot_step = 0.02 # Load data iris = load_iris() for pairidx, pair in enumerate([[0, 1], [0, 2], [0, 3], [1, 2], [1, 3], [2, 3]]): # We only take the two corresponding features X = iris.data[:, pair] y = iris.target # Train clf = DecisionTreeClassifier().fit(X, y) # Plot the decision boundary plt.subplot(2, 3, pairidx + 1) x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 xx, yy = np.meshgrid(np.arange(x_min, x_max, plot_step), np.arange(y_min, y_max, plot_step)) plt.tight_layout(h_pad=0.5, w_pad=0.5, pad=2.5) Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape) cs = plt.contourf(xx, yy, Z, cmap=plt.cm.RdYlBu) plt.xlabel(iris.feature_names[pair[0]]) plt.ylabel(iris.feature_names[pair[1]]) # Plot the training points for i, color in zip(range(n_classes), plot_colors): idx = np.where(y == i) plt.scatter(X[idx, 0], X[idx, 1], c=color, label=iris.target_names[i], cmap=plt.cm.RdYlBu, edgecolor='black', s=15) plt.suptitle("Decision surface of a decision tree using paired features") plt.legend(loc='lower right', borderpad=0, handletextpad=0) plt.axis("tight") plt.show()
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/196105.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
