大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
Faster R-CNN算法是作者Ross Girshick对Fast R-CNN算法的一种改进。Fast R-CNN在速度和精度上都有了不错的结果,但仍有一些不足之处。Faster R-CNN算法同样使用VGG-16网络结构,检测速度在GPU上达到5fps(包括候选区域的生成),准确率也有进一步的提升。在ILSVRC和COCO 2015竞赛中获得多个项目的第一名。在Faster R-CNN中提出了区域生成网络(Region Proposal Network,RPN),将候选区域的提取和Fast R-CNN中的目标检测网络融合到一起,这样可以在同一个网络中实现目标检测。Faster R-CNN主要是解决Fast R-CNN存在的问题:
- 候选区域提取方法耗时较长;
- 没有真正实现end-to-end训练测试。
Faster R-CNN算法步骤:
- 将图像输入网络得到相应的特征图;
- 使用RPN结构生成候选框,将RPN生成的候选框投影到特征图上获得相应的特征矩阵;
- 将每个特征矩阵通过ROl pooling层缩放到7×7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果。
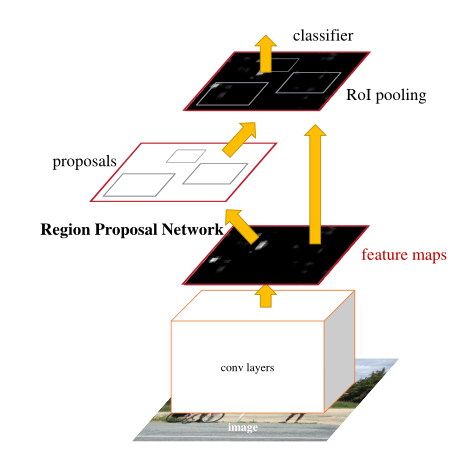

上图中各层的主要功能:
-
1) conv layers提取特征图:
作为一种CNN网络目标检测方法,Faster R-CNN首先使用一组基础的conv+relu+pooling层提取input image的feature maps,该feature maps会用于后续的RPN层和全连接层。 -
2) RPN(Region Proposal Networks):
RPN网络主要用于生成region proposals,首先生成一堆Anchor box,对其进行裁剪过滤后通过softmax判断anchors属于前景(foreground)或者后景(background),即是物体或者不是物体,所以这是一个二分类;同时,另一分支bounding box regression修正anchor box,形成较精确的proposal(注:这里的较精确是相对于后面全连接层的再一次box regression而言)。 -
3) RoI Pooling:
该层利用RPN生成的proposals和VGG16最后一层得到的feature map,得到固定大小的proposal feature map,进入到后面可利用全连接操作来进行目标识别和定位。 -
4) Classifier:
会将RoI Pooling层形成固定大小的feature map进行全连接操作,利用Softmax进行具体类别的分类,同时利用L1 Loss完成bounding box regression回归操作获得物体的精确位置。
Faster R-CNN算法可以看作是由R-CNN和Fast R-CNN演化而来。
Faster R-CNN存在的问题:
- 还是无法达到实时检测目标;
- 获取region proposal,再对每个proposal分类计算量还是比较大。
Faster R-CNN算法详解:

-
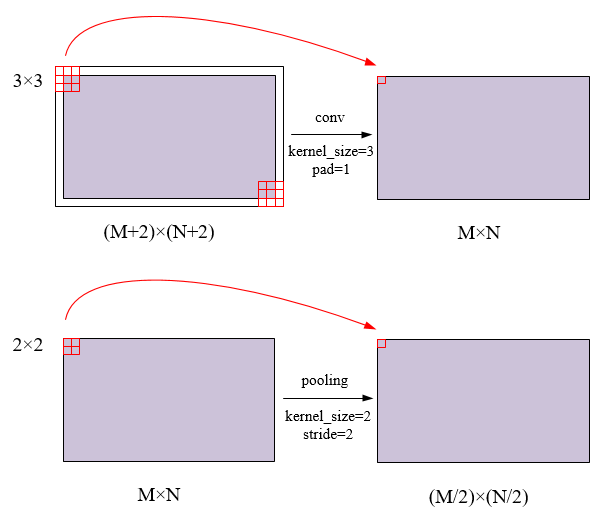
conv layers: 在input-data层时,作者把原图都reshape成M×N大小的图片,conv layers中包含了conv、relu、pooling三种层。就VGG16而言,就有13个conv层,13个relu层,4个pooling层。在conv layer中:
1. 所有的conv层都是kernel_size=3,pad=1;
2. 所有的pooling层都是kernel_size=2,stride=2。
conv layers中的pooling层kernel_size=2,stride=2,这样使得经过pooling层,M×N矩阵都会变为(M/2) × \times ×(N/2)大小。综上所述,在整个conv layers中,conv和relu层不改变输入输出的大小,只有pooling层使输出长宽都变为输入的1/2。那么,一个MxN大小的矩阵经过conv layers固定变为(M/16) × \times ×(N/16),这样conv layers生成的feature map中都可以和原图对应起来,最后得到51 × \times × 39 × \times × 256。
-
Region Propocal Networks(RPN): 经典的检测方法生成检测框都非常耗时,如OpenCV adaboost使用滑动窗口+图像金字塔生成检测框,或者如R-CNN使用SS(Selective Search)方法生成检测框。而Faster R-CNN则抛弃了传统的滑动窗口和SS方法,直接使用RPN生成检测框,这也是Faster R-CNN的巨大优势,能极大提升检测框的生成速度。
下图中展示了RPN网络的具体结构,可以看到,feature map经过一个3×3卷积核卷积后分成了两条线,上面一条通过softmax对anchors分类获得foreground和background(检测目标是foregrounnd),因为是2分类,所以它的维度是2k scores。下面那条线是用于计算anchors的bounding box regression的偏移量,以获得精确的proposal。它的维度是4k coordinates。而最后的proposal层则负责综合foreground anchors和bounding box regression偏移量获取proposal,同时剔除太小和超出边界的proposal,其实网络到这个Proposal Layer这里,就完成了目标定位的功能。

1×1卷积核和3×3卷积核: 如果卷积的输出输入都只是一个平面,那么1×1卷积核并没有什么意义,它是完全不考虑像素与周边其他像素关系。 但卷积的输出输入是长方体,所以1×1卷积实际上是对每个像素点,在不同的channels上进行线性组合(信息整合),且保留了图片的原有平面结构,调控depth,从而完成升维或降维的功能。
 候选区域(anchor): 特征可以看做一个尺度51 × \times × 39的256通道图像,对于该图像的每一个位置,考虑9个可能的候选窗口:三种面积{128 2 ^{2} 2,256 2 ^{2} 2,512 2 ^{2} 2} × × ×三种比例{1:1,1:2,2:1},这些候选窗口称为anchors。anchor的本质是SPP(spatial pyramid pooling)思想的逆向,而SPP本身就是将不同尺寸的输入resize成为相同尺寸的输出。所以SPP的逆向就是,将相同尺寸的输出,倒推得到不同尺寸的输入。下图示出51 × \times × 39个anchor中心,以及9种anchor示例。
候选区域(anchor): 特征可以看做一个尺度51 × \times × 39的256通道图像,对于该图像的每一个位置,考虑9个可能的候选窗口:三种面积{128 2 ^{2} 2,256 2 ^{2} 2,512 2 ^{2} 2} × × ×三种比例{1:1,1:2,2:1},这些候选窗口称为anchors。anchor的本质是SPP(spatial pyramid pooling)思想的逆向,而SPP本身就是将不同尺寸的输入resize成为相同尺寸的输出。所以SPP的逆向就是,将相同尺寸的输出,倒推得到不同尺寸的输入。下图示出51 × \times × 39个anchor中心,以及9种anchor示例。
 softmax判定foreground与background: 一个MxN大小的矩阵送入Faster R-CNN网络后,到RPN网络时变为(M/16)x(N/16),不妨设W=M/16,H=N/16。在进入reshape与softmax之前,先做了1×1卷积,如下图所示。经过卷积的输出图像的大小为W × × × H × × × 18,这刚好对应了feature maps每一个点都有9个anchors,同时每个anchors又可能是foreground和background,所以这些信息都保存在W × × × H × × × (9 × × × 2)大小的矩阵。至于在softmax前后都接一个reshape layer的原因,其实只是为了便于softmax分类。
softmax判定foreground与background: 一个MxN大小的矩阵送入Faster R-CNN网络后,到RPN网络时变为(M/16)x(N/16),不妨设W=M/16,H=N/16。在进入reshape与softmax之前,先做了1×1卷积,如下图所示。经过卷积的输出图像的大小为W × × × H × × × 18,这刚好对应了feature maps每一个点都有9个anchors,同时每个anchors又可能是foreground和background,所以这些信息都保存在W × × × H × × × (9 × × × 2)大小的矩阵。至于在softmax前后都接一个reshape layer的原因,其实只是为了便于softmax分类。
 bounding box regression原理: 下图所示的绿色框为飞机的Ground Truth(GT),红色为提取的foreground anchors,那么即便红色的框被分类器识别为飞机,但是由于红色的框定位不准,这张图相当于没有正确的检测出飞机。所以我们希望采用一种方法对红色的框进行微调,使得foreground anchors和GT更加接近。
bounding box regression原理: 下图所示的绿色框为飞机的Ground Truth(GT),红色为提取的foreground anchors,那么即便红色的框被分类器识别为飞机,但是由于红色的框定位不准,这张图相当于没有正确的检测出飞机。所以我们希望采用一种方法对红色的框进行微调,使得foreground anchors和GT更加接近。
 对于窗口一般使用四维向量(x, y, w, h)表示,分别表示窗口的中心点坐标和宽高。对于下图,红色的框A代表原始的Foreground Anchors,绿色的框G代表目标的GT,我们的目标是寻找一种关系,使得输入原始的anchor A经过映射得到一个跟真实窗口G更接近的回归窗口G’,即:给定A=(A x _x x, A y _y y, A w _w w, A h _h h),寻找一种映射f,使得f(A x _x x, A y _y y, A w _w w, A h _h h)=(G’ x _x x, G’ y _y y, G’ w _w w, G’ h _h h),其中(G’ x _x x, G’ y _y y, G’ w _w w, G’ h _h h)≈(G x _x x, G y _y y, G w _w w, G h _h h)。
对于窗口一般使用四维向量(x, y, w, h)表示,分别表示窗口的中心点坐标和宽高。对于下图,红色的框A代表原始的Foreground Anchors,绿色的框G代表目标的GT,我们的目标是寻找一种关系,使得输入原始的anchor A经过映射得到一个跟真实窗口G更接近的回归窗口G’,即:给定A=(A x _x x, A y _y y, A w _w w, A h _h h),寻找一种映射f,使得f(A x _x x, A y _y y, A w _w w, A h _h h)=(G’ x _x x, G’ y _y y, G’ w _w w, G’ h _h h),其中(G’ x _x x, G’ y _y y, G’ w _w w, G’ h _h h)≈(G x _x x, G y _y y, G w _w w, G h _h h)。
 那么经过何种变换才能从上图中的A变为G’呢? 比较简单的思路就是:
那么经过何种变换才能从上图中的A变为G’呢? 比较简单的思路就是:
1. 先做平移
 2. 再做缩放
2. 再做缩放
 观察上面4个公式发现,需要学习的是d x _x x(A),d y _y y(A),d w _w w(A),d h _h h(A)这四个变换。当输入的anchor与GT相差较小时,可以认为这种变换是一种线性变换, 那么就可以用线性回归来建模对窗口进行微调(注意,只有当anchors和GT比较接近时,才能使用线性回归模型,否则就是复杂的非线性问题了)。对应于Faster R-CNN原文,平移量(t x _x x, t y _y y)与尺度因子(t w _w w, t h _h h)如下:
观察上面4个公式发现,需要学习的是d x _x x(A),d y _y y(A),d w _w w(A),d h _h h(A)这四个变换。当输入的anchor与GT相差较小时,可以认为这种变换是一种线性变换, 那么就可以用线性回归来建模对窗口进行微调(注意,只有当anchors和GT比较接近时,才能使用线性回归模型,否则就是复杂的非线性问题了)。对应于Faster R-CNN原文,平移量(t x _x x, t y _y y)与尺度因子(t w _w w, t h _h h)如下:
 接下来的问题就是如何通过线性回归获得d x _x x(A),d y _y y(A),d w _w w(A),d h _h h(A)了。线性回归就是给定输入的特征向量X,学习一组参数W,使得经过线性回归后的值跟真实值Y(即GT)非常接近,即Y=WX。对于该问题,输入X是一张经过num_output=1的1 × \times × 1卷积获得的feature map,定义为 Φ Φ Φ;同时还有训练传入A与GT之间的变换量,即(t x _x x, t y _y y, t w _w w, t h _h h),输出是d x _x x(A),d y _y y(A),d w _w w(A),d h _h h(A)四个变换。那么目标函数可以表示为:
接下来的问题就是如何通过线性回归获得d x _x x(A),d y _y y(A),d w _w w(A),d h _h h(A)了。线性回归就是给定输入的特征向量X,学习一组参数W,使得经过线性回归后的值跟真实值Y(即GT)非常接近,即Y=WX。对于该问题,输入X是一张经过num_output=1的1 × \times × 1卷积获得的feature map,定义为 Φ Φ Φ;同时还有训练传入A与GT之间的变换量,即(t x _x x, t y _y y, t w _w w, t h _h h),输出是d x _x x(A),d y _y y(A),d w _w w(A),d h _h h(A)四个变换。那么目标函数可以表示为:
 其中 Φ ( A ) Φ(A) Φ(A)是对应anchor的feature map组成的特征向量,w是需要学习的参数,d(A)是得到的预测值(*表示 x, y, w, h,也就是每一个变换对应一个上述目标函数)。为了让预测值d ∗ _* ∗(A)与真实值t ∗ _* ∗差距最小,得到损失函数:
其中 Φ ( A ) Φ(A) Φ(A)是对应anchor的feature map组成的特征向量,w是需要学习的参数,d(A)是得到的预测值(*表示 x, y, w, h,也就是每一个变换对应一个上述目标函数)。为了让预测值d ∗ _* ∗(A)与真实值t ∗ _* ∗差距最小,得到损失函数:
 函数优化目标为:
函数优化目标为:
 对proposals进行bounding box regressiond: 看了RPN网络的第一条线路后,再来看第二条线路,如下图所示。经过卷积输出图像为W × × × H × × × 36,这里相当于feature maps每个点都有9个anchors,每个anchors又有4个用于回归的[dx(A),dy(A),dw(A),dh(A)]变换量。
对proposals进行bounding box regressiond: 看了RPN网络的第一条线路后,再来看第二条线路,如下图所示。经过卷积输出图像为W × × × H × × × 36,这里相当于feature maps每个点都有9个anchors,每个anchors又有4个用于回归的[dx(A),dy(A),dw(A),dh(A)]变换量。
 proposal layer: proposal layer负责综合所有的[dx(A),dy(A),dw(A),dh(A)]变换量和foreground anchors,计算出精准的proposal,送入后续的RoI Pooling layer。
proposal layer: proposal layer负责综合所有的[dx(A),dy(A),dw(A),dh(A)]变换量和foreground anchors,计算出精准的proposal,送入后续的RoI Pooling layer。
proposal layer有3个输入:fg/bg anchors分类器结果rpn_prob_reshape,对应的bbox reg的[dx(A),dy(A),dw(A),dh(A)]变换量rpn_bbox_ped,以及im_info,另外还有参数feat_stride=16,这和上图对应。
im_info:对于一幅任意大小的P × × × Q图像,传入Faster R-CNN前首先reshape到M × × × N大小,im_info=[M, N, scale_factor]则保存了此次缩放的所有信息。然后经过conv layers,经过4次pooling变为W × × × H=(M/16) × × × (N/16)大小,其中feature_stride=16则保存了该信息,用于计算anchor偏移量。
 RPN网络结构总结: 生成anchors -> softmax分类器提取fg anchors -> bbox reg回归fg anchors -> proposal layer生成proposals。
RPN网络结构总结: 生成anchors -> softmax分类器提取fg anchors -> bbox reg回归fg anchors -> proposal layer生成proposals。 -
ROI Pooling: RoI Pooling层负责收集proposal,并计算出proposal feature maps,送入后续网络。Rol pooling层有2个输入:原始的featrue map和RPN输出的proposal boxes(大小各不相同)。
对于传统的CNN(如alexnxt,VGG),当网络训练好后输入的图像尺寸必须是固定的,同时网络输出也是固定大小的vector 或matrix。如果输入的图像大小不定,这个问题就变得比较麻烦了。有2种解决办法:1. 从图像中crop一部分传到网络;2. 将图像warp成需要大小后传入网络。两种办法的示意图如下图所示,可以看到无论采取哪种办法都不好,要么crop破坏了图像的完整结构,要么warp破坏了图像原始形状信息。
 而RPN网络生成的proposals的方法:对foreground anchors进行bound box regression,那么这样获得的proposal也是大小形状各不相同,即也存在上述问题。所以Faster R-CNN提出了ROI Pooling来解决这个问题。
而RPN网络生成的proposals的方法:对foreground anchors进行bound box regression,那么这样获得的proposal也是大小形状各不相同,即也存在上述问题。所以Faster R-CNN提出了ROI Pooling来解决这个问题。
ROI Pooling layerl forward过程:proposal=[x1,y1,x2,y2]是对应M × × × N尺度的,所以首先使用spatial_scale参数将其映射回(M/16) × × × (N/16)大小的feature map尺度,之后将每个proposal水平方向和竖直方向都分成7份,对每一份都进行max pooling处理,这样处理后,即使大小不同的proposal,输出的结果都是7 × × × 7大小的,实现了fixed-length output(固定长度输出),如下图所示。

-
Classification: classification部分利用已经获得的proposal featuer map,通过full connect层与softmax计算每个proposal具体属于哪个类别(如车,人等),输出cls_prob概率向量;同时再次利用Bounding box regression获得每个proposal的位置偏移量bbox_pred,用于回归更加精确的目标检测框。classification部分网络结构如下:
 从ROI Pooling获取到7 × × × 7=49大小的proposal feature maps后,送入后续的网络,可以看到做了如下2件事:
从ROI Pooling获取到7 × × × 7=49大小的proposal feature maps后,送入后续的网络,可以看到做了如下2件事:
1. 通过全连接层和softmax对proposal进行分类,这实际上已经是识别的范畴了;
2. 再次对proposals进行bounding box regression,获取更高精度的rect box。
接下来我们来看看全连接层,简单的示意图如下所示。
 其计算公式如下:
其计算公式如下:
 其中W和bias B都是预先训练好的,即大小是固定,当然输入X和输出Y也是固定大小。所以,这也就印证了之前RIO Pooling的必要性。
其中W和bias B都是预先训练好的,即大小是固定,当然输入X和输出Y也是固定大小。所以,这也就印证了之前RIO Pooling的必要性。
参考文章:https://blog.csdn.net/Lin_xiaoyi/article/details/78214874。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/196026.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
