大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
ShuffleNet是由2017年07月发布的轻量级网络,设计用于移动端设备,在MobileNet之后的网络架构。主要的创新点在于使用了分组卷积(group convolution)和通道打乱(channel shuffle)。
分组卷积和通道打乱
分组卷积
分组卷积最早由AlexNet中使用。由于当时的硬件资源有限,训练AlexNet时卷积操作不能全部放在同一个GPU处理,因此作者把特征图分给多个GPU分别进行处理,最后把特征图结果进行连接(concatenate)。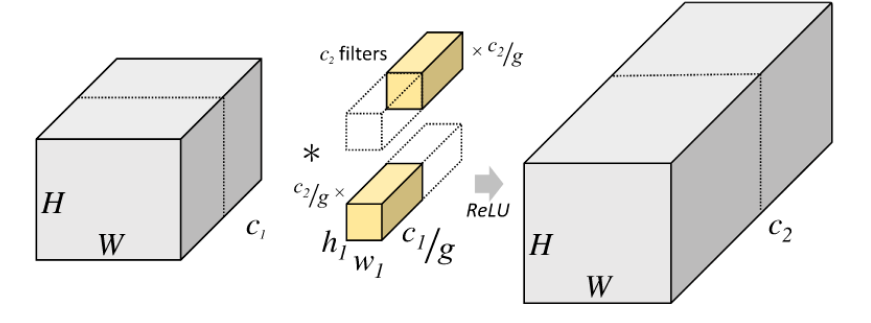
对于输入特征图 H ⋅ W ⋅ c 1 H\cdot W \cdot c_{1} H⋅W⋅c1,将其按照channel-level分为 g g g组,每组的通道数为 c 1 / g c_{1}/g c1/g,因此卷积核的深度也要变为 c 1 / g c_{1}/g c1/g,此时可认为有 g g g个卷积核去对应处理一个特征图生成 g g g个通道的特征图。若预期输出的特征图为通道数为 c 2 c_{2} c2,则总卷积核数也是 c 2 c_{2} c2。
通道打乱
通道打乱并不是随机打乱,而是有规律地打乱。
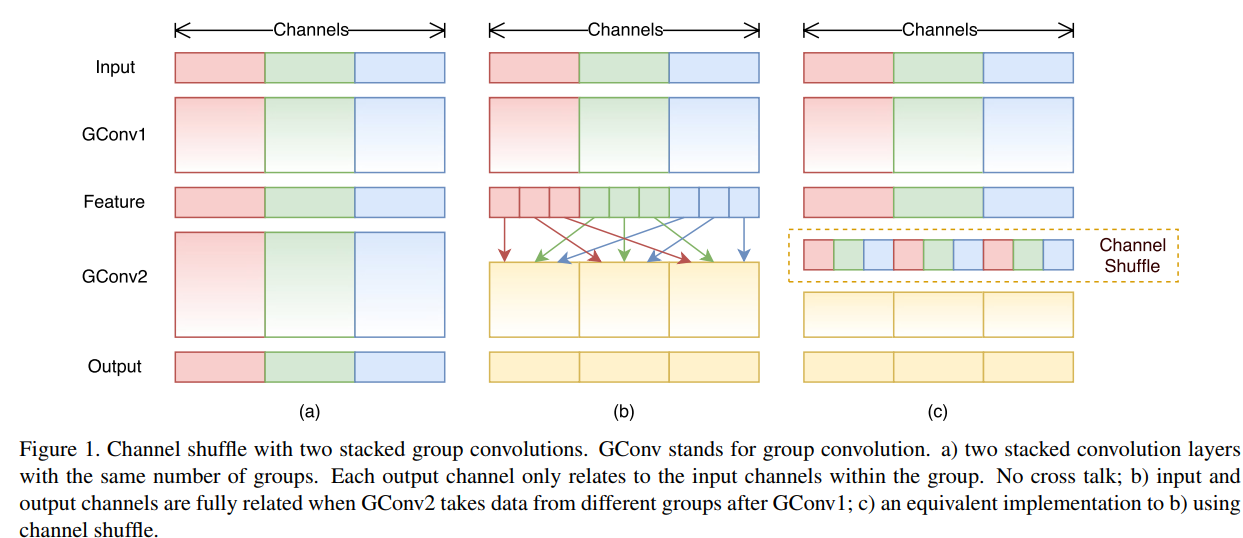 (a)表示的是使用分组卷积处理未加打乱的特征图。每一个输出通道都对应组内的输入通道。(b)对组卷积GConv1处理后的特征图channel进行如上方式的打乱,此时大部分输出通道会对应不同组 的输入通道;(c )是与(b)的等价实现,将通道调整到合适的位置。
(a)表示的是使用分组卷积处理未加打乱的特征图。每一个输出通道都对应组内的输入通道。(b)对组卷积GConv1处理后的特征图channel进行如上方式的打乱,此时大部分输出通道会对应不同组 的输入通道;(c )是与(b)的等价实现,将通道调整到合适的位置。
ShuffleNet单元
 (a)是ResNet提出的bottleneck层,只是将3×3的卷积替换为depthwise(DW)卷积。(b)是1×1卷积变为pointwise分组卷积(GConv),并且加入了通道打乱。按照DW卷积的原论文,在3×3的DW后面不添加非线性因素。最后的点卷积用来匹配相加操作。( c)加入了stride=2去减少特征图尺寸,旁路加入平均池化层来维持相同的尺寸,最终在channel水平上连接特征图。
(a)是ResNet提出的bottleneck层,只是将3×3的卷积替换为depthwise(DW)卷积。(b)是1×1卷积变为pointwise分组卷积(GConv),并且加入了通道打乱。按照DW卷积的原论文,在3×3的DW后面不添加非线性因素。最后的点卷积用来匹配相加操作。( c)加入了stride=2去减少特征图尺寸,旁路加入平均池化层来维持相同的尺寸,最终在channel水平上连接特征图。
ShuffleNet网络结构
表格中的complexity表示FLOPs。stage2阶段的pointwise卷积不使用组卷机。对于一个bottleneck单元,对于输入维度为 c × h × w c\times h\times w c×h×w的特征图,设bottleneck的channel数为 m m m,输出channel数为 4 m 4m 4m。对于每一个stage的第一个bottleneck,对应图( c),FLOPs的计算规则为: h × w × c × m g + h 2 × w 2 × ( 9 m + 4 m × m g ) h\times w\times c\times \frac{m}{g}+\frac{h}{2}\times \frac{w}{2}\times(9m+4m\times \frac{m}{g})\\ h×w×c×gm+2h×2w×(9m+4m×gm)
对于其他bottleneck,输入和输出特征图的尺寸和channel数保持不变,所以为: h × w × ( c m / g + 9 m + c m / g ) = h w ( 2 c m / g + 9 m ) h\times w\times (cm/g+9m+cm/g)=hw(2cm/g+9m) h×w×(cm/g+9m+cm/g)=hw(2cm/g+9m)
'''ShuffleNet in PyTorch. See the paper "ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices" for more details. '''
import torch
import torch.nn as nn
import torch.nn.functional as F
class ShuffleBlock(nn.Module):
def __init__(self, groups):
super(ShuffleBlock, self).__init__()
self.groups = groups
def forward(self, x):
'''Channel shuffle: [N,C,H,W] -> [N,g,C/g,H,W] -> [N,C/g,g,H,w] -> [N,C,H,W]'''
N,C,H,W = x.size()
g = self.groups
# 维度变换之后必须要使用.contiguous()使得张量在内存连续之后才能调用view函数
return x.view(N,g,int(C/g),H,W).permute(0,2,1,3,4).contiguous().view(N,C,H,W)
class Bottleneck(nn.Module):
def __init__(self, in_planes, out_planes, stride, groups):
super(Bottleneck, self).__init__()
self.stride = stride
# bottleneck层中间层的channel数变为输出channel数的1/4
mid_planes = int(out_planes/4)
g = 1 if in_planes==24 else groups
# 作者提到不在stage2的第一个pointwise层使用组卷积,因为输入channel数量太少,只有24
self.conv1 = nn.Conv2d(in_planes, mid_planes,
kernel_size=1, groups=g, bias=False)
self.bn1 = nn.BatchNorm2d(mid_planes)
self.shuffle1 = ShuffleBlock(groups=g)
self.conv2 = nn.Conv2d(mid_planes, mid_planes,
kernel_size=3, stride=stride, padding=1,
groups=mid_planes, bias=False)
self.bn2 = nn.BatchNorm2d(mid_planes)
self.conv3 = nn.Conv2d(mid_planes, out_planes,
kernel_size=1, groups=groups, bias=False)
self.bn3 = nn.BatchNorm2d(out_planes)
self.shortcut = nn.Sequential()
if stride == 2:
self.shortcut = nn.Sequential(nn.AvgPool2d(3, stride=2, padding=1))
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.shuffle1(out)
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
res = self.shortcut(x)
out = F.relu(torch.cat([out,res], 1)) if self.stride==2 else F.relu(out+res)
return out
class ShuffleNet(nn.Module):
def __init__(self, cfg):
super(ShuffleNet, self).__init__()
out_planes = cfg['out_planes']
num_blocks = cfg['num_blocks']
groups = cfg['groups']
self.conv1 = nn.Conv2d(3, 24, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(24)
self.in_planes = 24
self.layer1 = self._make_layer(out_planes[0], num_blocks[0], groups)
self.layer2 = self._make_layer(out_planes[1], num_blocks[1], groups)
self.layer3 = self._make_layer(out_planes[2], num_blocks[2], groups)
self.linear = nn.Linear(out_planes[2], 10)
def _make_layer(self, out_planes, num_blocks, groups):
layers = []
for i in range(num_blocks):
if i == 0:
layers.append(Bottleneck(self.in_planes,
out_planes-self.in_planes,
stride=2, groups=groups))
else:
layers.append(Bottleneck(self.in_planes,
out_planes,
stride=1, groups=groups))
self.in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def ShuffleNetG2():
cfg = {
'out_planes': [200,400,800],
'num_blocks': [4,8,4],
'groups': 2
}
return ShuffleNet(cfg)
def ShuffleNetG3():
cfg = {
'out_planes': [240,480,960],
'num_blocks': [4,8,4],
'groups': 3
}
return ShuffleNet(cfg)
def test():
net = ShuffleNetG2()
x = torch.randn(1,3,32,32)
y = net(x)
print(y)
test()
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/195763.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...