大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
论文:ShuffleNet V2: Practical Guidelines for Ecient CNN Architecture Design
论文链接:https://pan.baidu.com/s/1so7aD3hLKO-0PB8h4HWliw
这篇是ECCV2018关于模型加速和压缩的文章,是之前ShuffleNet的升级版。这篇文章的观点和实验都比较新颖,看完还是有不少收获的,特来分享。
目前大部分的模型加速和压缩文章在对比加速效果时用的指标都是FLOPs(float-point operations),这个指标主要衡量的就是卷积层的乘法操作。但是这篇文章通过一系列的实验发现FLOPs并不能完全衡量模型速度,比如在Figure1(c)(d)中,相同MFLOPs的网络实际速度差别却很大,因此以FLOPs作为衡量模型速度的指标是有问题的。

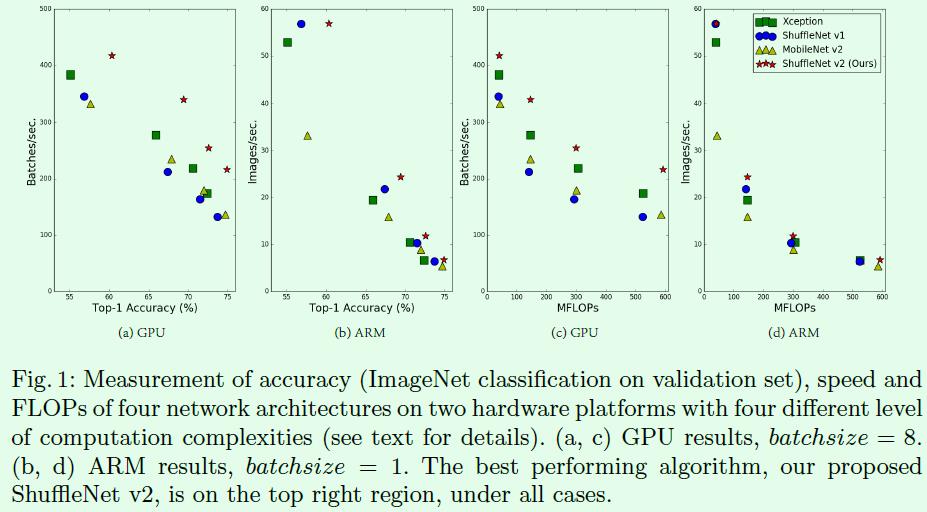
那么,为什么FLOPs相同的模型速度差别会那么大?这也是这篇文章的出发点和后续4个主要实验要证明的内容。首先直观的一点是内存访问消耗时间(memory access cost 缩写为 MAC)是需要计算的,这对模型速度影响比较大,但是却难以在FLOPs指标中体现出来。这个MAC指标将在出现在后续几个实验中,接下来分别介绍这4个实验。
第一个实验是关于卷积层的输入输出特征通道数对MAC指标的影响。结论是卷积层的输入和输出特征通道数相等时MAC最小,此时模型速度最快。
假设一个1*1卷积层的输入特征通道数是c1,输出特征尺寸是h和w,输出特征通道数是c2,那么这样一个1*1卷积层的FLOPs就是下面式子所示,更具体的写法是B=1*1*c1*c2*h*w,这里省略了1*1。
接下来看看存储空间,因为是1*1卷积,所以输入特征和输出特征的尺寸是相同的,这里用h和w表示,其中hwc1表示输入特征所需存储空间,hwc2表示输出特征所需存储空间,c1c2表示卷积核所需存储空间。
根据均值不等式可以得到公式1。接下来有意思了,把MAC和B代入式子1,就得到(c1-c2)^2>=0,因此等式成立的条件是c1=c2,也就是输入特征通道数和输出特征通道数相等时,在给定FLOPs前提下,MAC达到取值的下界。
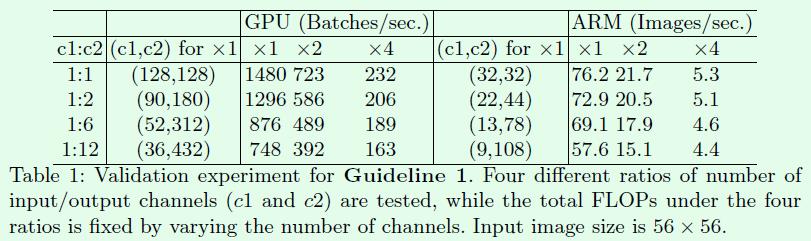
因此就有了Table1这个实验,这些实验的网络是由10个block组成,每个block包含2个1*1卷积层,第一个卷积层的输入输出通道分别是c1和c2,第二个卷积层相反。4行结果分别表示不同的c1:c2比例,但是每种比例的FLOPs都是相同的,可以看出在c1和c2比例越接近时,速度越快,尤其是在c1:c2比例为1:1时速度最快。这和前面介绍的c1和c2相等时MAC达到最小值相对应。
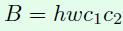
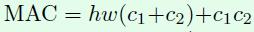

第二个实验是关于卷积的group操作对MAC的影响。结论是过多的group操作会增大MAC,从而使模型速度变慢。
像MobileNet、ShuffleNet、Xception其实都借鉴了卷积的group操作来加速模型,这是因为group操作可以大大减少FLOPs,因此即便适当加宽网络也不会使得FLOPs超过原来不带group的卷积操作,这样就能带来比较明显的效果提升(ResNeXt就是这样的例子)。但是,FLOPs不怎么增加并不代表速度变快,训练过ResNet和ResNeXt的同学应该都有一个直观的感受那就是相同层数情况下,ResNeXt的速度要慢许多,差不多只有相同层数的ResNet速度的一半,但是相同层数的ResNeXt的参数量、FLOPs和ResNet是基本差不多的。这就引出了group操作所带来的速度上的影响。
和前面同理,带group操作的1*1卷积的FLOPs如下所示,多了一个除数g,g表示group数量。这是因为每个卷积核都只和c1/g个通道的输入特征做卷积,所以多个一个除数g。
同理,MAC如下所示,和前面不同的是这里卷积核的存储量多了除数g,和B同理。
这样就能得到MAC和B之间的关系了,如公式2所示,可以看出在B不变时,g越大,MAC也越大,这个结论将用在后续实验中。
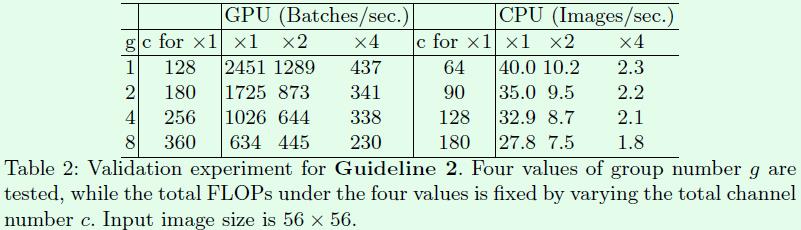
Table2是关于卷积的group操作对速度的影响,其中c表示c1+c2的和,通过控制这个参数可以使得每个实验的FLOPs相同,可以看出随着g的不断增大,c也不断增大,这和前面说的在基本不影响FLOPs的前提下,引入group操作后可以适当增加网络宽度吻合。从速度上看,group数量的增加对速度的影响还是很大的,原因就是group数量的增加带来MAC的增加(公式2),而MAC的增加带来速度的降低。
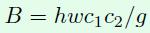
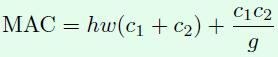
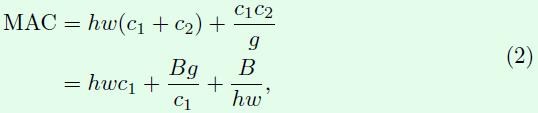
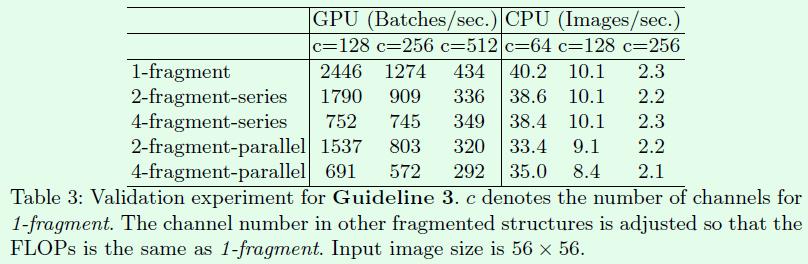
第三个实验是关于模型设计的分支数量对模型速度的影响。结论是模型中的分支数量越少,模型速度越快。
网络结构设计上,文章用了一个词:fragment,翻译过来就是分裂的意思,可以简单理解为网络的支路数量。为了研究fragment对模型速度的影响,作者做了Table3这个实验,其中2-fragment-series表示一个block中有2个卷积层串行,也就是简单的叠加;4-fragment-parallel表示一个block中有4个卷积层并行,类似Inception的整体设计。可以看出在相同FLOPs的情况下,单卷积层(1-fragment)的速度最快。因此模型支路越多(fragment程度越高)对于并行计算越不利,这样带来的影响就是模型速度变慢,比如Inception、NASNET-A这样的网络。
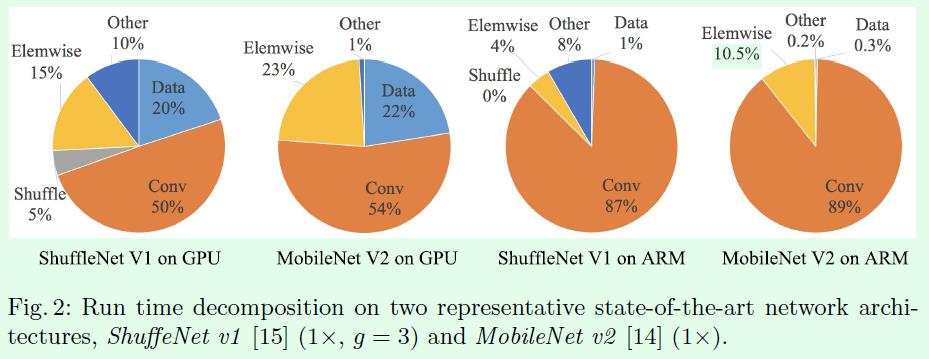
第四个实验是关于element-wise操作对模型速度的影响。结论是element-wise操作所带来的时间消耗远比在FLOPs上的体现的数值要多,因此要尽可能减少element-wise操作。
element-wise类型操作虽然FLOPs非常低,但是带来的时间消耗还是非常明显的。比如在Figure2中,作者对ShuffleNet v1和MobileNet v2的几种层操作的时间消耗做了分析,常用的FLOPs指标其实主要表示的是卷积层的操作,而element-wise操作虽然基本上不增加FLOPs,但是所带来的时间消耗占比却不可忽视。
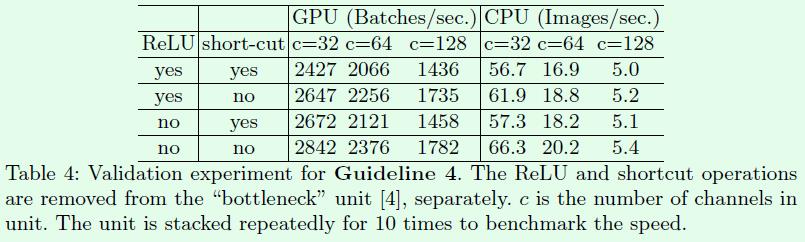
因此作者做了Table4的实验,Table4的实验是基于ResNet的bottleneck进行的,short-cut其实表示的就是element-wise操作。这里作者也将depthwise convolution归为element-wise操作,因为depthwise convolution也具有低FLOPs、高MAC的特点。T
介绍完4个实验,接下来就是针对这4个发现来设计网络结构,也就是ShuffleNet v2。
Figure3是关于ShuffleNet v1和ShuffleNet v2的结构对比,其中(a)和(b)是ShuffleNet v1的两种不同block结构,两者的差别在于后者对特征图尺寸做了缩小,这和ResNet中某个stage的两种block功能类似,同理(c)和(d)是ShuffleNet v2的两种不同block结构。从(a)和(c)的对比可以看出首先(c)在开始处增加了一个channel split操作,这个操作将输入特征的通道分成c-c’和c’,c’在文章中采用c/2,这主要是和前面第1点发现对应。然后(c)中取消了1*1卷积层中的group操作,这和前面第2点发现对应,同时前面的channel split其实已经算是变相的group操作了。其次,channel shuffle的操作移到了concat后面,和前面第3点发现对应,同时也是因为第一个1*1卷积层没有group操作,所以在其后面跟channel shuffle也没有太大必要。最后是将element-wise add操作替换成concat,这个和前面第4点发现对应。多个(c)结构连接在一起的话,channel split、concat和channel shuffle是可以合并在一起的。(b)和(d)的对比也是同理,只不过因为(d)的开始处没有channel split操作,所以最后concat后特征图通道数翻倍,可以结合后面Table5的具体网络结构来看。
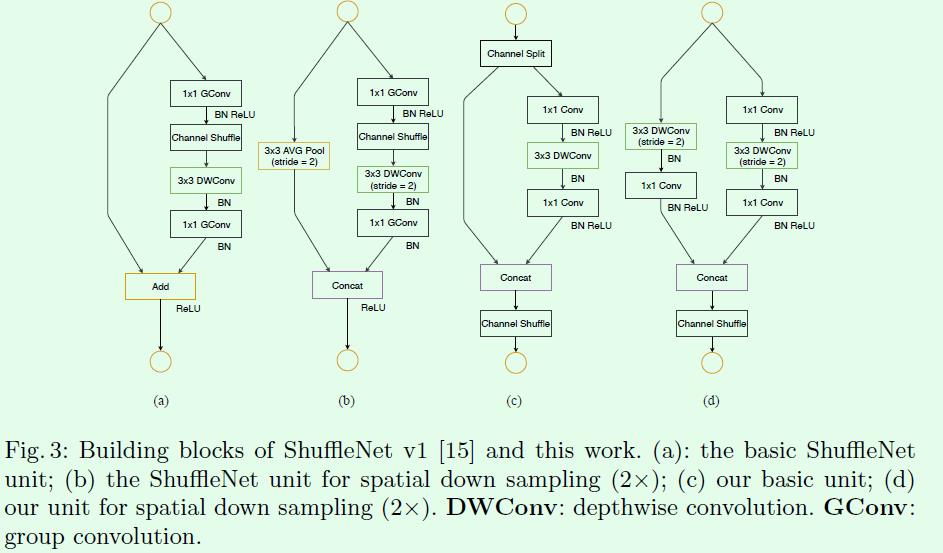
Figure5是ShuffleNet v2的具体网络结构示意图,不同stage的输出通道倍数关系和前面描述的吻合,每个stage都是由Figure3(c)(d)所示的block组成,block的具体数量对于Figure5中的Repeat列。
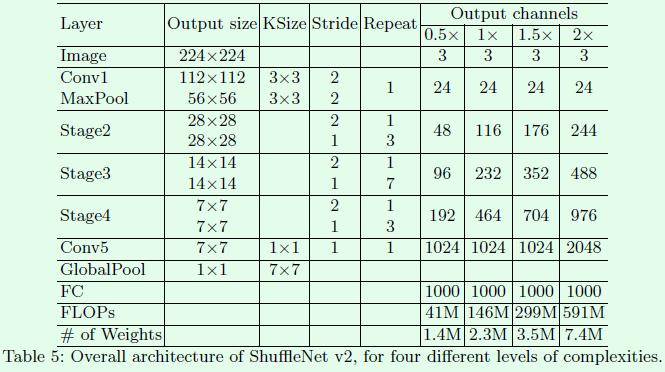
实验结果:
Table8是关于一些模型在速度、精度、FLOPs上的详细对比。实验中不少结果都和前面几点发现吻合,比如MobileNet v1速度较快,很大一部分原因是因为简单的网络结构,没有太多复杂的支路结构;IGCV2和IGCV3因为group操作较多,所以整体速度较慢;Table8最后的几个通过自动搜索构建的网络结构,和前面的第3点发现对应,因为支路较多,所以速度较慢。
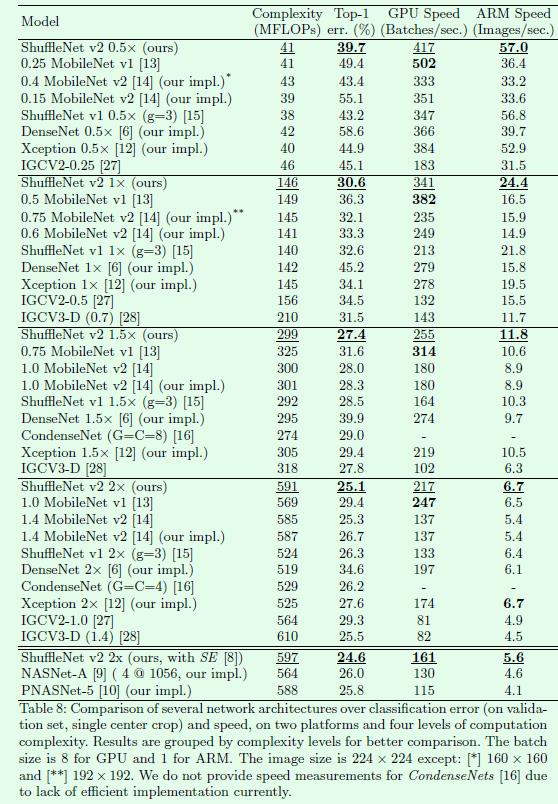
Table7是在COCO数据集上的速度和精度对比。ShuffleNet v2*是指在每个block的第一个pointwise卷积层前增加一个3*3的depthwise卷积层,可以参看前面Figure3(d),目的是增加感受野,这样有助于提升检测效果(受Xception启发)。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/195582.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
