大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
这是关于BiLSTM的第一篇文章,有关工程细节的介绍可以查看第二篇。
关于理解LSTM的一篇英文博客非常经典,可以去这里阅读,本文也参考了该博文。
循环神经网络(RNN)
BiLSTM是RNN的一种延伸,因此,要理解BiLSRM就必须首先弄明白什么是RNN。
普通神经网络的局限
假设我们对于普通的神经网络模型已经比较熟悉,那么不难理解,在神经网络的某一固定层中,该网络的各个输入之间是没有运算连接的。造成的一个直观的影响就是,该模型无法表示输入的“上下文”之间的关系。我们在读一篇文章时,有时需要返回头再看前文的内容,这样便于我们去理解文章真正想表达的含义。既然传统的神经网络无法解决这个问题,那么,一种新的、可以考虑上下文内容的模型——循环神经网络(Recurrent neural network)就诞生了。
RNN的运行机制
RNN的运行原理其实非常的简单,如下图:

上图中,粉色的部分为一个神经元,对输入进行运算。从图中可以看出,与普通神经网络不同的一点在于,神经元接受两个值:一个是当前时刻的输入 x t x_t xt,另一个是前一个神经元的输出 a t − 1 a_{t-1} at−1。其蕴含的意义也是不难理解的:通过将前一时刻的运算结果添加到当前的运算中,从而实现了“考虑上文信息”的功能。
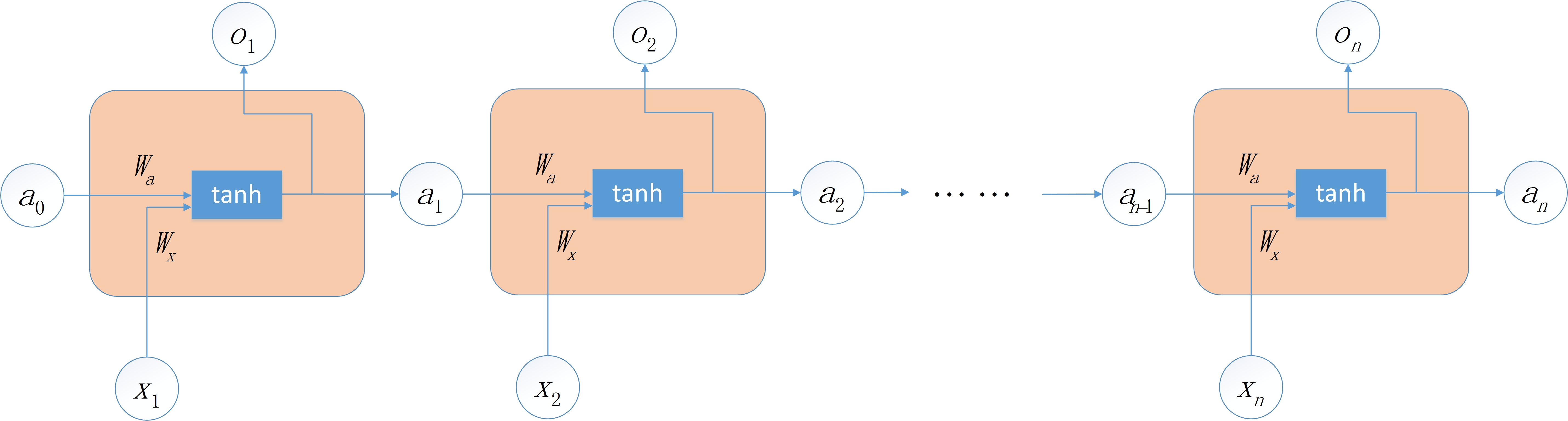
下面给出在线性计算过程中各个变量的维度情况。
假定我们的输入是一段文字,首先要做的是将文字转为词向量,因为神经网络只能进行数值运算。假定转换后的词向量维度为50,即每个词可以用一个长度为50的列向量进行表示。如果没有 a a a项,即在普通的神经网络中,要得到维度为10的输出,那么所作的线性运算部分为 W x ∗ x W_x*x Wx∗x(为简单起见,省去了偏置项 b b b),这里, W x W_x Wx是10×50的矩阵, x x x是50×1的向量。
添加了 a a a项之后,与之对应的有一个权重矩阵 W a W_a Wa,在具体的计算时,实际上是将 x t x_t xt和 a t − 1 a_{t-1} at−1做了简单的“堆叠”: [ a t − 1 ; x t ] [a_{t-1};x_t] [at−1;xt]是一个60×1的向量,那么 [ W a ; W x ] [W_a;W_x] [Wa;Wx]就是一个10×60的矩阵,这样在做线性运算之后,得到的输出( a t a_t at和 o t o_t ot)仍是10×1的向量。
BiRNN
由上一部分可以知道,RNN可以考虑上文的信息,那么如何将下文的信息也添加进去呢?这就是BiRNN要做的事情。
具体运算如下图:
与RNN计算流程类似,BiRNN在其基础上添加了反向的运算。可以理解为把输入的序列反转,重新按照RNN的方式计算一遍输出,最终的结果为正向RNN的结果与反向RNN的结果的简单堆叠。这样,模型就可以实现考虑上下文信息了,所以这种RNN叫做Bidirectional recurrent neural network。
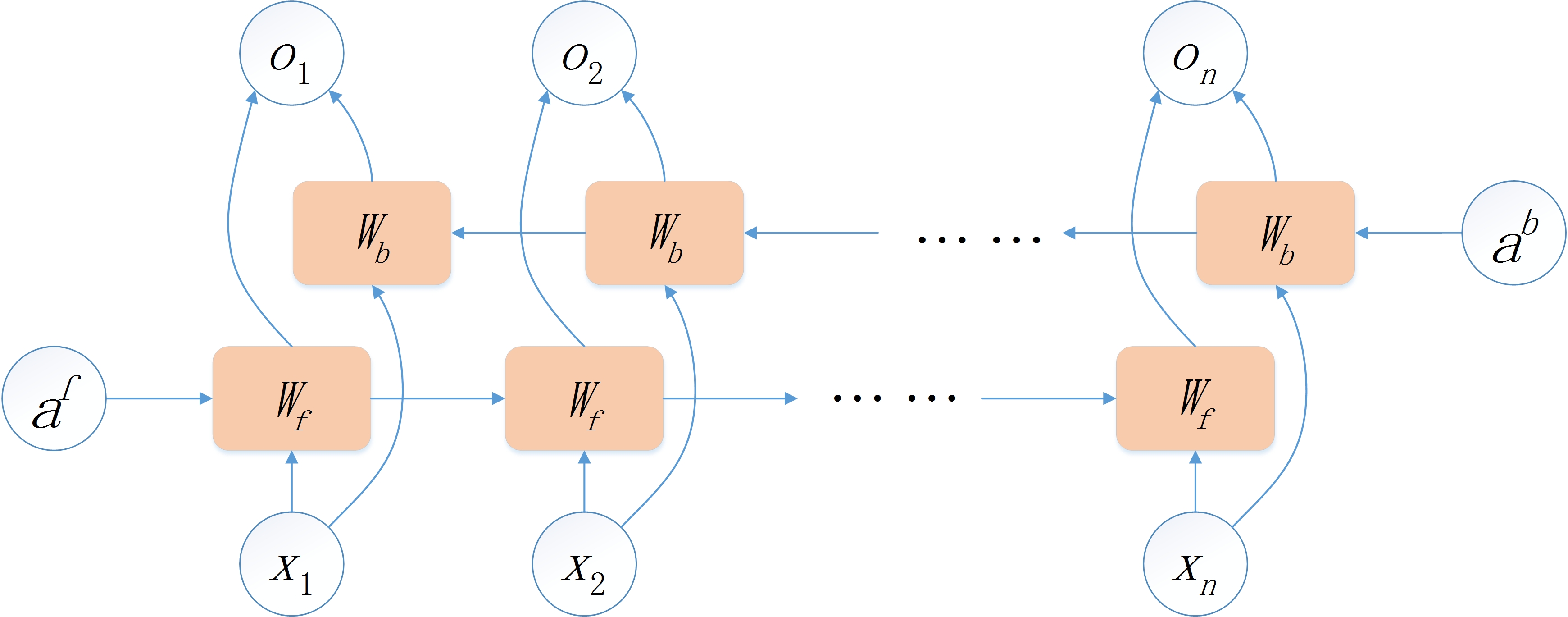
注意,这里只是对RNN类神经网络的前向传播过程进行了说明,该类神经网络也可以通过梯度下降法进行后向传播,从而实现训练模型的功能。
RNN存在的问题
由上文可知,理论上BiRNN可以考虑到上下文的信息,因为每一个传递给后面神经元的 a a a的值都包含了前面所有时刻的输入信息。但是直觉告诉我们,如果仅仅依靠这一条线来记录所有输入的信息,工作效果很可能并不理想,实际也的确如此:人们已经证实,RNN很难完美地处理具有长期依赖的信息。一个比较容易理解的英文例子是:当句子很长时,RNN无法记住主语的单复数形式从而在后面选择合适的谓词。
既然仅仅依靠一条线连接后面的神经元不足以解决问题,那么就再加一条线好了,这就是LSTM。研究表明,与RNN相比,LSTM可以很好的表达输入中的长期依赖的信息。
长短记忆网络(LSTM)
LSTM中一个重要的概念就是“门”,它控制信息通过的量,实质上就是一个 σ \sigma σ函数。
门(gate)函数
对于接触深度学习的人而言,一定不会对 σ \sigma σ函数感到陌生,它的表达式为 σ ( t ) = 1 1 + e − t \sigma\left(t\right)=\frac{1}{1+e^{-t}} σ(t)=1+e−t1。该函数最重要的一个特征是,它可以把实数轴上的值映射到 ( 0 , 1 ) \left( 0,1\right) (0,1)上,而且,绝大部分的值都是非常接近0或者1的。
这样的特性就仿佛是一个门结构,根据函数的取值可以决定让多少信息通过这个门。
在LSTM中,一共有3种门结构,分别是遗忘门(forget gate)、输入门(input gate)与输出门(output gate)。下面结合一个神经元内部的结构图分析其运算情况。
LSTM的神经元及运行机制
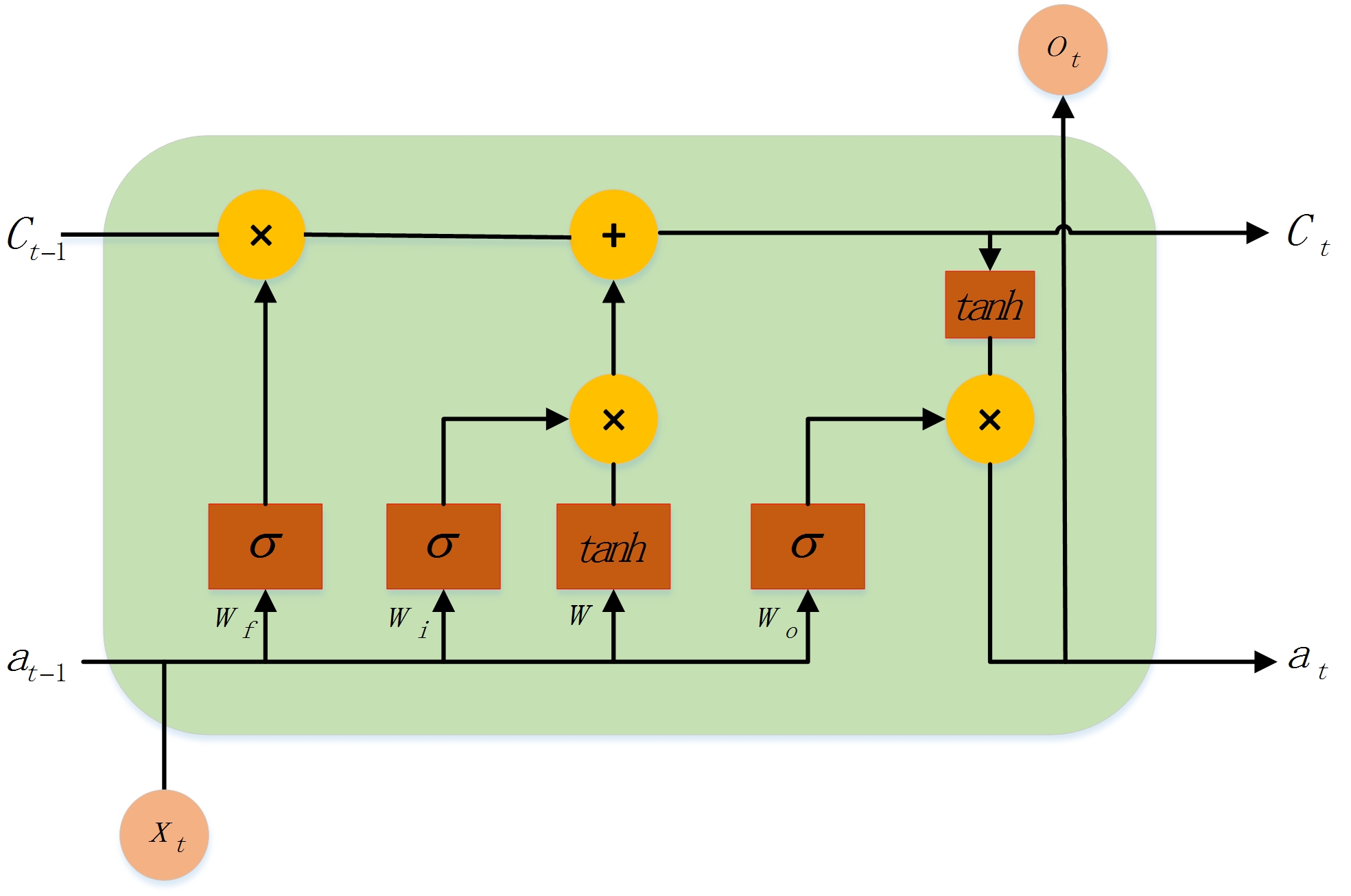
上图是一个LSTM“神经元”(即英文‘cell’)的内部情况。
首先,忽略其内部细节,单看输入与输出可以发现,每个神经元都有三个输入与三个输出。根据上文,不难想到, X t X_t Xt是该时刻新加入的信息, a t − 1 a_{t-1} at−1与 C t − 1 C_{t-1} Ct−1是上文信息的表示。
其次,在该神经元内部:
- 黄色的部分表示“逐元素运算”,一共有两种,分别是乘运算和加运算。也就是说,两个相同维度的向量经过黄色运算框之后对应元素进行相乘或相加。
- 棕色部分表示“激活运算”,也有两种,分别是 σ \sigma σ函数和 t a n h tanh tanh函数。
- 两条线按箭头方向融合,则是上文说的简单堆叠;一条线分成两条,则是复制为相同的两份。
那么它的运行机制是什么样的呢?
假设没有三个门函数,不难发现, a t − 1 a_{t-1} at−1与 X t X_t Xt堆叠之后乘以权重 W W W然后经过 t a n h tanh tanh激活函数后输出,这与RNN的运算是一模一样的。
现在, a t − 1 a_{t-1} at−1与 X t X_t Xt堆叠之后的值被复制成了四份:
第一份乘以遗忘门的权重 W f W_f Wf然后用 σ \sigma σ激活,得到的值可以称之为“遗忘权重”。
第二份乘以输入门的权重 W i W_i Wi然后用 σ \sigma σ激活,得到的值可以称之为“输入权重”。
第三份则是进行了RNN中的运算。
第四份乘以输出门的权重 W o W_o Wo然后用 σ \sigma σ激活,得到的值可以称之为“输出权重”。
应该时刻注意的是,上述“某某权重”其实是一个与 a t − 1 a_{t-1} at−1与 X t X_t Xt堆叠后的向量同维度的向量,向量中所有的值都在 ( 0 , 1 ) (0,1) (0,1)之间,而且大部分都是非常接近0或者1的。
接下来看神经元内最上方的 C t − 1 C_{t-1} Ct−1。与 a t − 1 a_{t-1} at−1类似, C t − 1 C_{t-1} Ct−1也携带着上文的信息。进入神经元后, C t − 1 C_{t-1} Ct−1首先会与遗忘权重逐元素相乘,可以想见,由于遗忘权重中值的特点,因此与该权重相乘之后 C t − 1 C_{t-1} Ct−1中绝大部分的值会变的非常接近0或者非常接近该位置上原来的值。这非常像一扇门,它会决定让哪些 C t − 1 C_{t-1} Ct−1的元素通过以及通过的比例有多大。反映到实际中,就是对 C t − 1 C_{t-1} Ct−1中携带的信息进行选择性的遗忘(乘以非常接近0的数)和通过(乘以非常接近1的数),亦即乘以一个权重。
理解了遗忘门的作用之后,其他两个门也就比较好理解了。输入门则是对输入信息进行限制,而输入信息就是RNN中的前向运算的结果。经过输入门处理后的信息就可以添加到经过遗忘门处理的上文信息中去,这就是神经元内唯一一个逐元素相加的工作。
按照一般的理解,上文的信息根据当前的输入遗忘了旧的信息,并添加了新的信息,那么整体的更新操作就已经完成,即 C t C_{t} Ct已经生成。但是 C t C_{t} Ct实际扮演的角色是携带上文的信息,因此,如果当前神经元要输出内容,那么还要有一个输出门进行限制。 C t C_t Ct再乘以一个 t a n h tanh tanh激活函数之后,与输出权重逐元素相乘,就得到了当前神经元的输出和 a t a_t at。
可以这样认为: C t C_t Ct携带的信息经过由当前时刻的输入构成的输出门限制之后,含有更多的当前时刻的信息,因此得到的 a t a_t at与 C t C_t Ct相比可以说是具有短期记忆的,而 C t C_t Ct则是具有长期记忆的。因此,将它们统称为长短记忆网络。
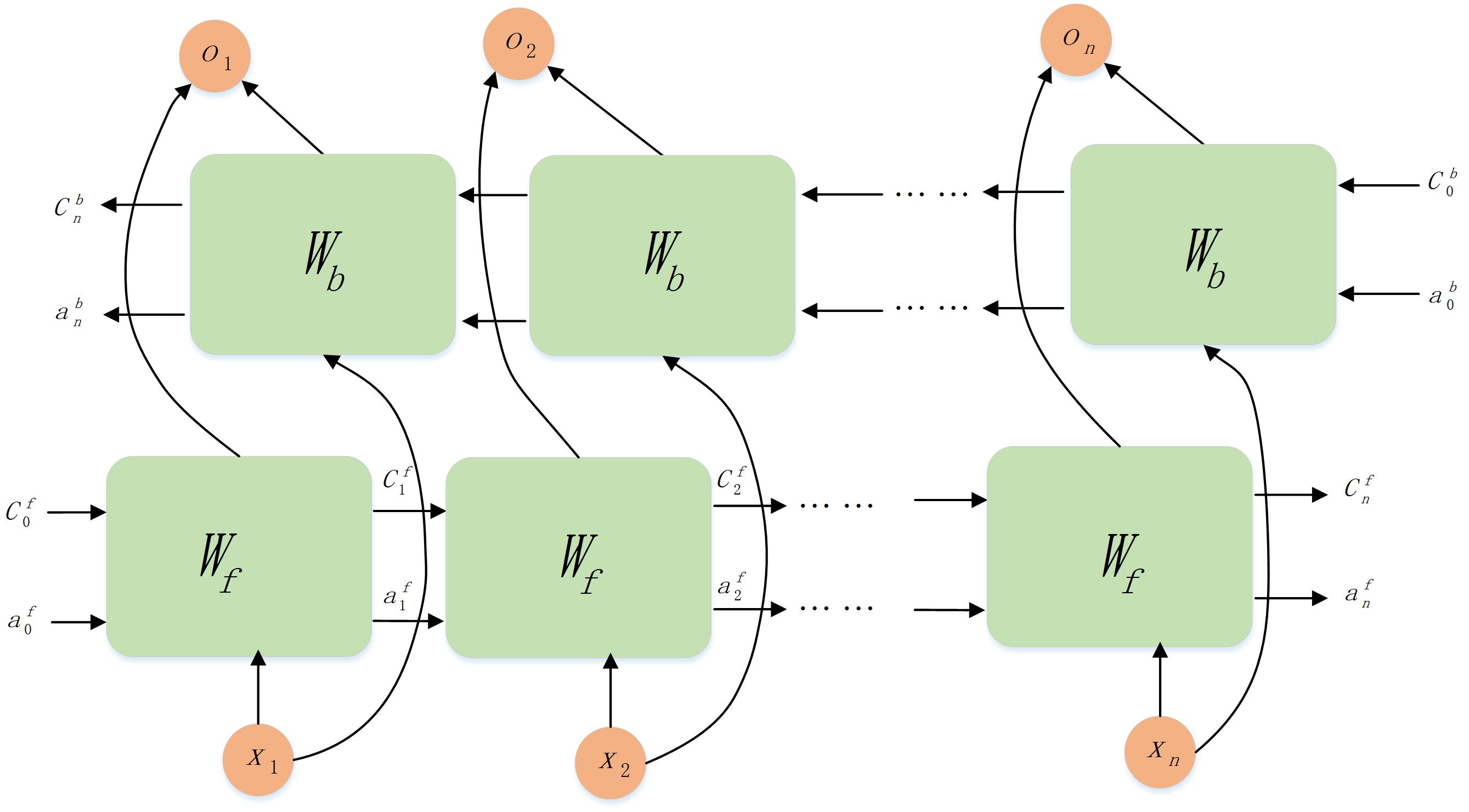
BiLSTM
类似的,LSTM也可以携带下文的信息,采用的方法与BiRNN并无差别,这里给出运算图,不再细表:
总结
尽管RNN理论上可以衡量上下文的信息,但当上下文过长时效果太差。LSTM的提出可以很好的解决这一问题,从而使循环神经网络可以在实际中有非常好的应用成果。
最后值得注意的是,对于BiRNN来说,前向的计算的所有神经元内的权重参数均是一样的,反向的计算(不是后向传播!!)所有的神经元内的权重参数也都是一样的。同理,LSTM也有这个特点,换句话说,它们是权值共享的。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/195359.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
