大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
一:CBIR综述:转自于wiki:http://zh.wikipedia.org/wiki/CBIR
参考链接:http://blog.csdn.net/kezunhai/article/details/11614989
借用一个图:大致构架,与一般的模式识别构架相似.

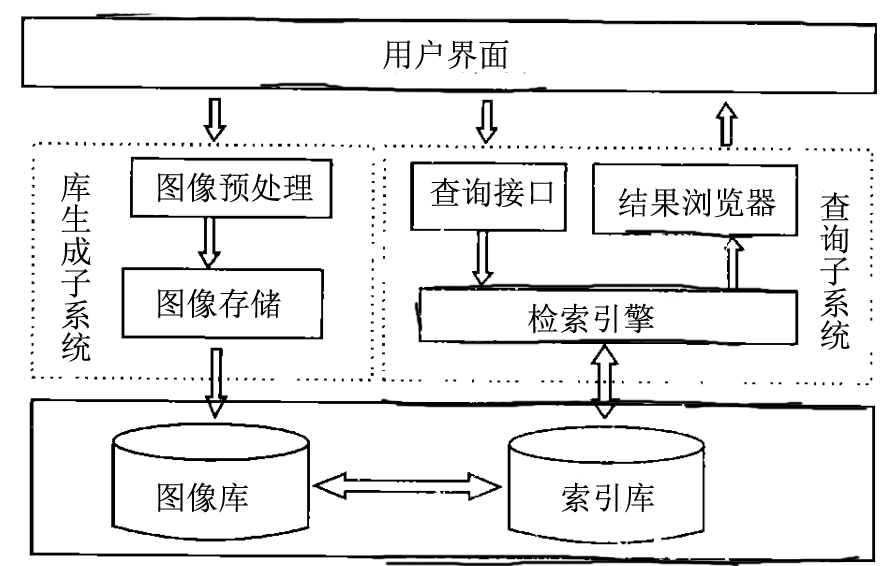
Definition:基于内容的图像检索(英语:Content-based image retrieval,CBIR;或content-based visual information retrieval),属于图像分析的一个研究领域。基于内容的图像检索目的是在给定查询图像的前提下,依据内容信息或指定查询标准,在图像数据库中搜索并查找出符合查询条件的相应图片。
互联网络上传统的搜索引擎,包括Google、Yahoo以及MSN都推出相应的图片搜索功能,但是这种搜索主要是基于图片的文件名建立索引来实现查询功能(也许利用了网页上的文字信息)。这种从查询文字,文件名,最会到图片查询的机制并不是基于内容的图像检索。基于内容的图像检索指的是查询条件本身就是一个图像,或者是对于图像内容的描述,它建立索引的方式是通过提取底层特征,然后通过计算比较这些特征和查询条件之间的距离,来决定两个图片的相似程度。
关键技术:查询方式、结果显示方式、图像特征、特征索引技术等;
技术细节
基于内容的图像检索通常包括以下几个部分:
特征提取
可提取的特征可以包括颜色、纹理、平面空间对应关系、外形,或者其他统计特征。图像特征的提取与表达是基于内容的图像检索技术的基础。从广义上讲,图像的特征包括基于文本的特征(如关键字、注释等)和视觉特征(如色彩、纹理、形状、对象表面等)两类。
视觉特征又可分为通用的视觉特征和领域相关的视觉特征。前者用于描述所有图像共有的特征,与图像的具体类型或内容无关,主要包括色彩、纹理和形状;后者则建立在对所描述图像内容的某些先验知识(或假设)的基础上,与具体的应用紧密有关,例如人的面部特征或指纹特征等。
[reference:其中,颜色,纹理,形状,图像边缘特征,是基于人的视觉原理,而语义特征是基于用户查询中对于图像内容的描述。
颜色特征主要包括颜色直方图、颜色矩等,颜色特征是一种全局特征,它描述了图像或图像某个区域所对应的景物的表面性质;
纹理特征是一种统计特征,它需要在包含多个像素点的区域中进行统计计算,纹理特征常具有旋转不变性,并且对噪声有较强的抵抗能力。主要包括粗糙性、方向性、对比性等。 纹理特征描述方法大致可分为四类:统计法、结构法、模型法、频谱法等;
形状特征是物体自身的一个重要特征,一般来说一个物体可以有不同的颜色,但它的形状不会有很大差别。
形状描述方法主要有两类:基于边缘和基于区域的形状方法,基于边缘的形状特征提取用面积、周长、偏心率、角点、链码、兴趣点、傅里叶描述子、矩描述子等特征来描述物体的形状,适用于图像边缘较为清晰、容易获取的图像;
基于区域的形状特征提取的主要思路是通过图像分割技术提取出图像中感兴趣的物体,依靠区域内像素的颜色分布信息提取图像特征,适合于区域能够较为准确地分割出来、区域内颜色分布较为均匀的图像。]
(总结:特征提取是一个信息量压缩的过程;如何提取具有强表达能力的特征有相当的专业素养要求。)
相似性(非相似性)的定义
从图像中提取的特征可以组成一个向量,两个图像之间可以通过定义一个距离或者相似性的测量度来计算相似程度。
reference:(相似度定义:参考相似度与距离的对比;范数距离(空间向量相似度);余弦距离(方向相似度);)
弥补语义鸿沟
在传统的基于文字的查询技术中,不存在这个问题,因为查询关键字基本能够反映查询意图。但是在基于内容的图像查询中,就存在一个底层特征和上层理解之间的差异(这也就是著名的semantic gap)。主要原因是底层特征不能完全反映或者匹配查询意图。弥补这个鸿沟的技术手段主要有:
- 相关反馈(relevance feedback):按照最初的查询条件,查询系统返回给用户查询结果,用户可以人为介入(或者自动)来选择几个最符合他查询意图的返回结果(正反馈),也可以选择最不符合他查询意图的几个返回结果(负反馈)。这些反馈信息被送入系统用来更新查询条件,重新进行查询。从而让随后的搜索更符合查询者的真实意图。
- 建立复杂的分类模型:一些比较复杂的非线性分类模型,比如支持向量机(Support Vector Machine)本身就可以起到一定程度的效果来弥补语义鸿沟。
查询模式
- 按例查询(QBE-Query By Example):用户提供一个查询图片,在数据库中搜索相似图片。
- 按绘查询(Query by sketch):用户在类似画笔的接口上面进行简单的绘画,依次为标准进行查询。[这样目标的拓扑特性是一个很显著的特征]
- 按描述查询:例如,指定条件可以是30%的黄色,70%的蓝色等。[直方图描述或者其他描述]
应用和研究:
近邻搜索: http://en.wikipedia.org/wiki/Nearest_neighbor_search
二:一个实例:使用OpenDIR搭建简单的图像检索系统
原文链接:http://blog.csdn.net/chenxin_130/article/details/6648280
系统比较潦草,希望大家能理解,不过我没有看,只是转载了;
图像检索看似是一门高深的学问,我们在享受谷歌,百度,Tineye等检索服务的同时,有没有想过自己也能搭建一个图像检索系统呢?OpenDIR是一个在google code上简单的开源文档图像检索应用。常见的图像检索基本是以自然图像的精确或相似检索为主,而OpenDIR则实现于以文本为主体的图像相似检索算法,比如生活中各类文书的电子扫描件等等。目前版本的OpenDIR使用了两种特征,projection histogram feature和density distribution feature,计算向量间的Cosine相似度进行相似匹配。
编译:
该项目的主页在http://code.google.com/p/opendir/,在download中下载新版本的源代码解压后,是一个VC 2008的工程。同时,项目也提供了可执行的压缩包。
在编译工程之前,首要要保证的是VC中已经配置了OpenCV。OpenCV作为开源计算机视觉库,应用已经比较广泛了,甚至在著名河蟹软件的“绿爸”中都能找到它的芳影。具体的安装和配置可以在http://www.opencv.org.cn/及其官网http://opencv.willowgarage.com/wiki/ 找到,这里小斤就不再赘述了。VS2010的话,可以直接下载opencv for VS2010,连Build步骤都省了。
对于OpenDIR,VC2008以上版本,直接打开项目或转换一下,build就可以用了。如果是VC2005等版本,可以直接建立一个空项目,把OpenDIR的一家老小都放进去Build,或者直接改vcproject文件中的Version参数。
使用:
OpenDIR执行时可以输入两个指令,-w和-r,-w 后跟输出的特征数据文件名, -r 后跟输入的特征数据文件名。
后台供检索的图片库,需在inputimage.txt这个文件中指定,使用-w指令后,会将所有后台图像的特征计算后,通过增量的方式存入特征数据文件中。
有了特征数据文件,只要调用-r指令就可以载入特征数据文件,而不需要重新计算后台图片的特征,直接开始检索了。
下载的源码包中已经包含了testimg文件夹和inputimage.txt,其中包含了几张文档图像,以及一张test.jpg的模糊图片用作测试。
在VC工程的属性-Debugging-Command Arguments,我们输入”-w feature.txt -r feature.txt”(引号内的内容),让OpenDIR计算特征数据文件后,再直接载入,进行检索。
执行过程中,可以看到feature.txt被生成了,打开窥一窥:
- imagepath=testimg\1.jpg
- index=0
- DDFLength=120
- PHFLength=50
- FusionFeature=3, 12, 20, 20, 17, 12, 8, 8, 8, 8, 7, 3, 0, 0, 1, 41, 83, 86, 85, 80, 62, 0, 0, 0, 0, 0, 0, 48, 98, 100, 82, 85, 75, 0, 0, 0, 0, 0, 0, 48, 99, 99, 93, 100, 58, 0, 0, 0, 0, 0, 0, 48, 100, 100, 95, 84, 59, 0, 0, 0, 0, 5, 15, 16, 18, 19, 18, 14, 8, 4, 4, 0, 0, 11, 22, 13, 13, 13, 14, 13, 7, 7, 7, 0, 0, 1, 24, 21, 11, 10, 7, 8, 7, 8, 2, 0, 0, 8, 20, 13, 11, 5, 5, 0, 0, 0, 0, 0, 0, 3, 4, 4, 4, 4, 4, 9, 11, 13, 11, 0, 70, 13, 88, 7, 38, 56, 53, 57, 53, 53, 57, 53, 53, 57, 53, 57, 53, 53, 57, 51, 53, 57, 53, 57, 53, 26, 34, 61, 43, 80, 85, 24, 16, 27, 100, 18, 24, 77, 52, 18, 15, 15, 53, 38, 17, 0, 0, 0, 79, 37
- imagepath=testimg\2.jpg
- index=1
- DDFLength=120
- PHFLength=50
- FusionFeature=7, 16, 15, 17, 16, 16, 10, 14, 15, 12, 13, 10, 8, 1, 29, 31, 32, 32, 32, 32, 32, 31, 0, 0, 0, 3, 100, 99, 100, 100, 100, 100, 100, 100, 3, 0, 0, 3, 100, 98, 96, 98, 90, 100, 100, 100, 3, 0, 0, 3, 100, 100, 99, 99, 97, 100, 100, 100, 3, 0, 4, 9, 51, 51, 51, 51, 52, 50, 51, 48, 1, 0, 14, 10, 10, 6, 2, 2, 3, 2, 2, 2, 0, 0, 7, 23, 20, 15, 12, 8, 0, 0, 0, 0, 0, 0, 19, 25, 16, 16, 16, 15, 13, 16, 15, 15, 17, 13, 9, 14, 13, 13, 14, 12, 12, 5, 5, 5, 5, 6, 56, 58, 15, 45, 66, 12, 8, 15, 69, 69, 69, 69, 69, 69, 69, 69, 69, 69, 69, 69, 69, 69, 69, 69, 69, 69, 69, 12, 33, 80, 12, 7, 13, 30, 20, 26, 39, 42, 36, 4, 16, 53, 99, 100, 16, 0, 0, 0, 91, 48
- imagepath=testimg\3.jpg
- index=2
- DDFLength=120
- PHFLength=50
- FusionFeature=73, 85, 63, 53, 28, 21, 21, 20, 20, 20, 20, 17, 18, 99, 98, 100, 64, 24, 21, 21, 22, 24, 23, 21, 40, 78, 50, 53, 53, 46, 51, 45, 44, 23, 27, 22, 43, 71, 52, 54, 27, 23, 24, 31, 20, 22, 24, 19, 17, 73, 61, 75, 69, 72, 57, 56, 45, 28, 26, 17, 18, 65, 64, 66, 45, 61, 46, 51, 41, 19, 24, 22, 43, 36, 24, 25, 24, 12, 9, 6, 0, 0, 0, 0, 63, 59, 13, 0, 0, 0, 0, 0, 0, 0, 0, 0, 59, 46, 48, 35, 13, 2, 0, 0, 0, 0, 0, 0, 57, 59, 60, 46, 33, 37, 63, 44, 53, 48, 52, 47, 59, 60, 7, 18, 57, 72, 21, 31, 32, 36, 8, 17, 14, 100, 79, 96, 34, 1, 34, 70, 40, 17, 41, 91, 61, 96, 26, 21, 49, 47, 3, 8, 37, 48, 12, 18, 21, 14, 20, 29, 46, 30, 32, 25, 39, 55, 18, 9, 95, 43
- imagepath=testimg\4.jpg
- index=3
- DDFLength=120
- PHFLength=50
- FusionFeature=35, 44, 44, 44, 41, 41, 23, 25, 32, 31, 32, 28, 81, 99, 99, 82, 86, 91, 9, 0, 1, 3, 26, 31, 81, 99, 100, 94, 100, 80, 22, 31, 47, 16, 39, 0, 81, 100, 100, 97, 85, 72, 36, 59, 51, 12, 12, 14, 12, 11, 10, 4, 0, 0, 0, 0, 0, 0, 0, 0, 12, 16, 18, 15, 5, 0, 0, 0, 0, 0, 0, 0, 8, 23, 24, 26, 25, 18, 4, 0, 0, 0, 0, 0, 15, 20, 17, 11, 12, 10, 10, 0, 0, 0, 0, 0, 14, 5, 6, 6, 5, 6, 4, 5, 4, 0, 0, 0, 15, 15, 9, 5, 5, 5, 5, 5, 5, 5, 5, 6, 57, 59, 41, 100, 73, 64, 77, 75, 67, 80, 81, 86, 85, 82, 83, 88, 89, 85, 89, 93, 23, 15, 28, 2, 9, 14, 32, 39, 32, 39, 45, 49, 53, 48, 53, 30, 12, 18, 46, 30, 4, 4, 71, 34, 11, 10, 1, 0, 93, 20
- imagepath=testimg\5.jpg
- index=4
- DDFLength=120
- PHFLength=50
- FusionFeature=67, 66, 67, 55, 29, 20, 20, 20, 20, 20, 20, 17, 36, 25, 25, 21, 25, 22, 29, 26, 25, 26, 14, 0, 29, 90, 84, 71, 84, 78, 55, 53, 22, 19, 22, 19, 40, 40, 41, 41, 45, 37, 35, 41, 26, 0, 0, 0, 52, 86, 26, 20, 22, 23, 20, 20, 23, 24, 22, 19, 23, 86, 93, 57, 40, 30, 0, 0, 0, 0, 0, 0, 18, 67, 49, 38, 32, 30, 21, 23, 23, 23, 29, 22, 26, 85, 100, 56, 0, 0, 0, 0, 0, 0, 0, 0, 15, 55, 54, 52, 47, 33, 31, 28, 0, 0, 0, 0, 35, 46, 52, 42, 22, 20, 54, 46, 56, 50, 54, 49, 62, 63, 1, 5, 28, 5, 4, 6, 80, 97, 87, 58, 53, 18, 63, 30, 6, 6, 66, 34, 11, 13, 87, 53, 17, 41, 42, 23, 48, 49, 74, 70, 22, 21, 29, 31, 31, 32, 22, 50, 45, 70, 23, 21, 34, 21, 31, 1, 100, 45
- imagepath=testimg\6.jpg
- index=5
- DDFLength=120
- PHFLength=50
- FusionFeature=28, 39, 40, 38, 40, 39, 32, 17, 34, 32, 32, 26, 37, 30, 30, 25, 15, 13, 14, 11, 18, 16, 16, 12, 0, 50, 25, 13, 0, 0, 0, 0, 0, 0, 0, 0, 27, 45, 18, 12, 12, 12, 12, 12, 12, 12, 12, 10, 42, 57, 42, 43, 41, 46, 48, 28, 29, 23, 12, 10, 47, 39, 27, 19, 15, 16, 17, 13, 15, 13, 14, 13, 8, 31, 30, 41, 39, 49, 43, 30, 27, 23, 7, 0, 12, 44, 43, 28, 31, 47, 27, 29, 52, 27, 28, 22, 0, 0, 0, 3, 73, 57, 5, 100, 46, 0, 0, 0, 24, 33, 35, 55, 81, 14, 41, 71, 13, 12, 12, 17, 59, 60, 20, 59, 12, 7, 11, 37, 97, 33, 11, 10, 18, 21, 11, 13, 1, 15, 26, 99, 92, 80, 50, 9, 11, 88, 61, 8, 10, 16, 59, 57, 45, 89, 100, 97, 20, 6, 11, 11, 14, 25, 27, 28, 29, 20, 14, 0, 95, 37<span style=”font-family:Comic Sans MS;font-size:16px;”>
- </span>
其中的FusionFeature就是特征向量了,每个图像由一个120维的
density distribution feature和一个50维的
projection histogram feature组成。
接着,小斤就输入text.jpg来试一把:
项目主页中介绍了这个text.jpg,是手机拍摄一个文档后二值化的结果,有一坨大噪点,中间看起来是一个插图。
输入test.jpg后,查看检索的相似性结果:
 结果:
结果: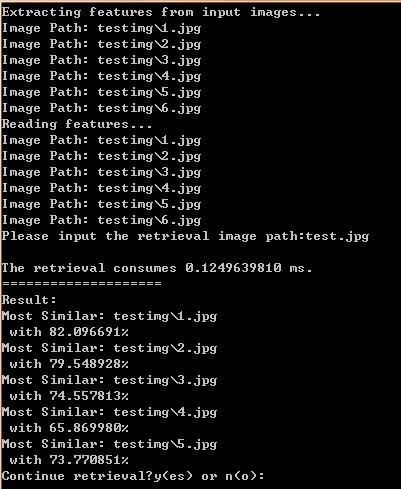
testimg的1.jpg的相似度最高,这是1.jpg的原图,从段落开始结束的位置分布来看,应该就是它了:
简单的性能测试:
小斤准备使用1000张后台图像进行测试,看看检索的效率如何。
去网上搜集1000张文档图像显然比较累人,这里使用了一个偷懒的办法,找个1000页左右的pdf,使用pdf2image等工具,生成1000张文档图像的jpg,
最后每张在850*1100左右,分辨率还行。
把这么多图像填到inputimage.txt配置文件中,同样有简单的办法,运行cmd,进入存放图像的目录后,使用dir /b命令,每一行会显示一个图像文件名,右键选中标记,圈住他们复制,粘贴到inputimage.txt中就可以了。当然,这样做也有个弊端,就是这些图像和OpenDIR的可执行文件必须是在同一目录下了。
后台图像库算是轻而易举地构建好了,和之前一样,先使用-w指令生成特征数据文件,1000张图的特征计算了1分多钟,但也只要辛苦一次就够了。
完成后,使用-r指令开始检索:
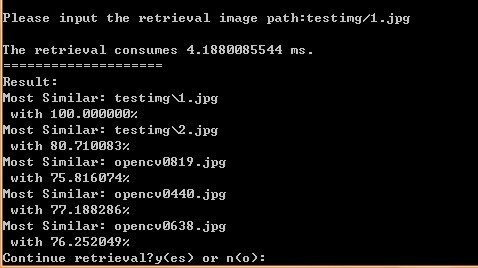
在1000张图片中找到了一模一样的它,相似度100%,花费4ms。
(测试环境Turion X2 RM-74 2.2G,2G内存)
测试多次后,对于精确检索,比如检索后台图库中存在的同一图像,每次都能以100%找到。
对于相似检索,如一些扫描质量比较差的图片或处理过的图像,(类似于之前的test.jpg),虽然检索速度令人满意,但检索结果也就中规中矩了,有时结果风马牛不相及。也许今后融入更好的特征可以提高准确度吧。
三:CPU/GPU优化:http://blog.csdn.net/b5w2p0/article/details/13004265
图像涉及到大规模的并行运算,可以利用GPU的流处理能力进行加速运算;
主要从图像识别开始,简述笔者对于计算机视觉领域的优化的任务的总结和思考:
(一) 图像识别一般符合如下框架:
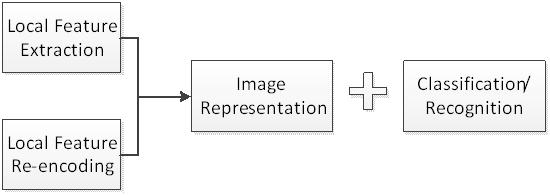
1.
识别正确率与图像数据和所建立的图像类别模型有关,前者即与所提取的image representation的判别性有关,进一步,
与所提取的local description和encoding完的描述子的判别性有关
;后者与所采用的数学模型有关,至于具体采用什么模型,与前者encoding完的数据在高维空间中的相对位置关系有关(Data Drive)。
2. 图像理解是一个大规模的数据并行计算过程,用到了大量的矩阵运算。
可以优化的地方:
1)
local feature descriptor的获取
,这方面效果最好的是SIFT描述子,是十年来效果最好的,但是效率低,提取一副720*576的图像的特征,可能需要几秒钟,当然提取的时间与图像梯度的复杂度正相关。09年,CVPR best demo 在这方面做了很漂亮的工作,他们将提取一个点的时间减少到2.5毫秒。参看demo(http://mi.eng.cam.ac.uk/~sjt59/hips.html)同时,该实验室也制作了iPhone 应用oMoby,识别效果我认为比Google goggles 效果还要好。提升特征描述的时间,是图像理解的第一步,对于将图像信息转化为计
算机可识别信息至关重要。
2)
Local descriptorre-encoding
由于局部特征描述繁杂无序,难以通过训练得到有意义的模型。通过将其量化(建立码书模型)得到统一的,可分的多维空间中的点,以便于通过训练可以将这些模型区分开。
3) 对于
数学模型计算的优化
。基本上所有的判别式模型都可以归结为是
凸优化问题如支持向量机SVM
,面临大量的数值计算。模型计算过程一般是离线过程。
这里有一个很好的讲座:
http://www.youtube.com/watch?v=g1tLjptuTBo
(Kaiyu是NEC美国研究院的研究员,在09年的VOC中拿了classification组第一名。)
重申一下,这里所介绍的最经典的基于统计学习的识别框架,近些年有一些科学家试图跳出这个套路,提出了deep learning等算法,可以参看文末给出的demo。
3. 图像理解相关领域进行优化的价值:
1) 图像识别技术在03年以后有了突飞猛进的进展。Google 有相关产品,goggles,similar image search(两者均是基于图像内容的检索和识别),微软亚洲研究院中,图像识别是其非常重要的研究领域(如sun,jian所作的工作), 其他的有:百度淘宝都有以图识图的产品。
2) 这些图像产品都面临着计算效率的问题,即:图像特征提取慢,数学模型离线训练慢。这方面的优化具有非常有价值的意义。
3) 优化过程是否可以考虑:强化OpenCV和IPP(这两者我估计在实际产品中用到的很多),CPU+GPU的联合优化(由于是大规模的矩阵运算,有效地利用GPU是可行之路,即:OpenCL),针对特定算法有效利用IA架构CPU优势,分布式计算等。
4) 扩展:随着图像识别技术的发展,基于相关技术的视频序列识别近些年也得到了更多的应用和发展,比如行为识别等。由此而引发的,传统监控系统向智能监控系统的转变这两年也逐渐兴起,具体内容请看下面。
(二) 智能监控中的优化
所谓智能,是指让计算机具备一部分自主的分析功能。比如监控视频中的目标锁定(detection 可以是基于特征的检测,比如人脸检测,可以使基于行为的检测,比如犯罪分子有某种行为习惯),目标跟踪(tracking),目标识别(recognition首先将目标分割出来,然后利用前面所述的图像识别方法进行识别)。
对于智能监控来说,
实时性
极为重要。但是detection, tracking, segmentation都是非常耗时的过程(比如采用单纯粒子滤波进行单目标跟踪,对于DVD图像,未优化的程序处理速度不超过15fps,使用效果更好的改进算法,速度可能降至5fps),计算效率极大的阻碍了前沿技术在工程实际中的应用。
目前智能监控在国内和世界范围内都是非常火的领域。国内海康威视,银江科技等都是监控领域炙手可热的公司,尤其是前者,他在这个领域世界排名大约第六,产品遍及国内各大城市街道,高速公路,大型工业企业。但是目前的主流监控市场是不断的提升监控的分辨率,智能算法很少被引入到实际产品中,很大一部分原因是因为算法的复杂性。尽管一些海归和博士建立了一些拥有自己算法的智能监控系统公司,比如莲花山研究院所办的公司在这方面所作的尝试。
智能监控是一个非常有价值的领域,成长快,利润高。
英特尔的优势在于OpenCV中已经开发了大量前沿视觉算法,这些在Intel的CPU上都可以进行优化。
(三) :移动终端上的性能优化
在移动终端上,图像和语音可能成为和打字同等重要的信息输入方法。比较火的领域有:图像识别,语音识别(如科大讯飞),增强现实(无数的APP),图像拼接(如微软的重量产品Kinect和photosynth(在bing上结合地图有重要应用))等领域,这些都是与计算能力十分相关的内容,而其本质上也是大规模的矩阵运算,如果能有效地利用OpenCV, Ipp, Intel数学运算库和利用好CPU-GPU的联合运算,都会对性能和功耗有比较大的提升。
视觉识别一般分为图像层次和视频序列的识别;前者在一些大的搜索引擎公司都有所涉及,后者主要集中于国外高校实验室和一些本领域的领军人物的创业型公司(比如莲花山研究院所作的将视觉理论所做的产业化工作,Zhu,chunsong是UCLA的professor,在弯曲评论上有个简单的对他的介绍或者可以到他的Lab网页查看)。国内本土的监控公司,很多也采取了和国内各大高校合作的方式。而实际上,某些基于视频的识别在实验室已经做到相当好的效果,面临的主要问题是:光照,角度形变,尺度,实时性等问题(其实人脸识别尽管已经发展到了相当成熟,仍然面临这个问题,比如无法区分照片中的人脸,光照变化大的时候正确率有较大的下降,甚至已经有人专门研究过什么情况下人脸识别会失效:http://ahprojects.com/art/cv-dazzle)
四:参考资料:http://blog.csdn.net/kezunhai/article/details/11614989
(个人感觉不是太新)要想了解更多关于图像检索的理论知识,请参考:
1)周明全、耿国华、韦娜. 基于内容图像检索技术. 清华大学出版社.
2)孙君顶 、赵珊 . 图像低层特征提取与检索技术. 电子工业出版社.
这两本内容重叠的部分比较多,个人觉得周明全编的那本书更言简意赅,但是孙君顶的内容更全,大家可以任选一本即可。
下面介绍几个国外的图像检索的项目或系统:
1)1、QBIC:http://wwwqbic.almaden.ibm.com/
这是IBM的一个系统,采用了三类特征,分别是颜色直方图(描述颜色分布特征)、形状一阶矩(描述形状)以及纹理信息(包括对比度、粗细度、方向性),并且该系统采用数据库技术来处理高维数据。
2)、Blobword:http://elib.cs.berkeley.edu/photos/blobworld/
这是加利福尼亚大学伯克利分校开发的一个系统,该系统利用图像分割技术提取特征,通过EM簇的方法对图像的颜色、纹理和位置进行聚类,实现分割。用户查询时,通过手工选择一个区域,系统返回与选择区域相似的图片返回。
3)、AIMBA (Search IMages By Appearance):http://simba.informatik.uni-freiburg.de/
该系统通过提取图像的颜色和纹理不变特征(对旋转和平移),用户通过自设定权重实现相似性检索。
4)、VIPER (Visual Information Processing for Enhanced Retrieval):http://viper.unige.ch/
该系统采用一种二值特征的高维空间(80000)以及允许快速访问的逆向文件(inverted file)。在HSV颜色空间,计算颜色直方图以及一系列Gabor系数(a set of Gabor coefficients),根据特征出现的次数决定特征的权重。可喜的是,VIPER是一个开源库,可以通过GPL免费获取。现在该库已经扩展为一个用于医学图像检索的系统。源码获取地址:http://www.gnu.org/software/gift/gift.html
5)、CIRES:http://amazon.ece.utexas.edu/~qasim/research.htm
该系统采用颜色直方图(15 bins)作为颜色特征,Gabor特征表示纹理特征,并提取了十字线(line crossing)与交叉线( line junctions)。
6)、FIRE(Flexible Image Retrieval Engine):http://thomas.deselaers.de/fire/
FIRE是由 Thomas Deselaers及其同事开发的一个开源的图像检索引擎,C++代码编写,细节内容可以参考Thomas Deselaers的博士论文,也可以的可以去上述网站查看更多信息。
7)、IRMA (Image Retrieval in Medical Applications) :http://wang.ist.psu.edu/
8)、IRMA (Image Retrieval in Medical Applications):http://www.irma-project.org/
9)、Image Retrieval:http://pages.cs.wisc.edu/~beechung/dlm_image_processing/image_processing/retrieve.html
10)、Content-Based Image Retrieval:http://homes.cs.washington.edu/~shapiro/cbir.html
11)、Content Based Image Retrieval System with Relevance Feedback:http://www.ifp.illinois.edu/~xzhou2/demo/cbir.html
除了以上列出的内容外,还有很多商用的网站:
1)、http://tineye.com/
Tineye是典型的以图找图搜索引擎,输入本地硬盘上的图片或者输入图片网址,即可自动帮你搜索相似图片,搜索准确度相对来说还比较令人满意。TinEye是加拿大Idée公司研发的相似图片搜索引擎,TinEye主要用途有:1、发现图片的来源与相关信息;2、研究追踪图片信息在互联网的传播;3、找到高分辨率版本的图片;4、找到有你照片的网页;5、看看这张图片有哪些不同版本。
2)、http://shitu.baidu.com
百度正式上线了其最新的搜索功能——“识图”(shitu.baidu.com)。该功能是百度基于相似图片识别技术,让用户通过上传本地图片或者输入图片的URL地址之后,百度再根据图像特征进行分析,进而从互联网中搜索出与此相似的图片资源及信息内容。但需要注意的是,用户上传本地图片时,图片的文件要小于5M,格式可为JPG、JPEG、GIF、PNG、BMP等图片文件。
3)、http://www.gazopa.com/
GazoPa搜索图片时,不依据关键词进行检索,而是通过图片自身的某些特征(例如色彩,形状等信 息)来进行搜索。GazoPa搜索方式有四种:
第一种是传统的通过关键词搜索图片,但在传统图片搜索领域GazoPa与google等搜索引擎无法竞争。
第二种是创新的通过图片搜索图片,但在此领域GazoPa无法与TinEye相竞争。TinEye很容易就能搜索出与原图最接近的一些结果,而GazoPa很多时候的搜索结果则完全无法与原图匹配。
第三种是通过手绘图片搜索图片,这种方式其实没太大用处。GazoPa虽然有这样那样的不足之处,但也算是一个很有独创性的搜索引擎。GazoPa目前还处在内测阶段,想要加入测试的可以在官网上留下你的邮箱地址,收到邀请后你就可以测试使用了。
第四种是通过视频缩略图搜索视频,GazoPa仅凭一张视频缩略图就可找到相关视频。只要有截图,就可以找到截图的视频!
4)、http://similar-images.googlelabs.com/
Google实验室的图片搜索:输入一个关键词后,例如“lake”,返回的页面里面点击某个图片的下面的Similar images,运用Google 类似图片搜索功能引擎,即刻为你把类似的图片全部搜索出来,展示给用户以便查看。其准确率、相似率相对比较高。
5)、http://www.picitup.com/
Picitup是一个刚开始公测的专业图片搜索引擎,功能非常强大,并支持中文关键字的搜索,是国内图片爱好者的不错选择。Picitup主要支持关键字的搜索,但在它的特色搜索项目——名人匹配搜索(Celebritymatchup)中,你可以通过上传本地照片来进行搜索,不过结果一般让人失望。Picitup可以通过在搜索结果页选择过滤方式来筛选图片,比如可以按颜色、头像(人脸)、风景、产品四种类别来过滤搜索结果。
Picitup最大特点是提供相似图片搜索,即通过关键字找到初始图片,点击初始图片下面的similar pictures按钮,即可搜索与该张图片类似的图片。其实质和Google实验室类似图片搜索是一样的。
6)、http://www.tiltomo.com/
Tiltomo是由 Flickr 开发的一个搜索工具,主要用来维护Flickr 自己的图片数据库,其搜索算法主要是基于相似的主题风格或相似的色调和材质。
7)、http://cn.bing.com/
Live.com允许你进行一次关键字搜索后再执行相似性的搜索。你可以为Live索引中的任意一张图片寻找相似的图片,但搜索结果看起来并不是很精确。
8)、http://www.xcavator.net
Xcavator 和Live.com很相似,你需要先输入一个关键字,然后在搜索结果中挑选一张图片,在根据这张图片的特点来进行搜索。
9)、http://www.incogna.com
Incogna的搜索速度非常快,主要是基于色彩和形状上的相似性。
10)、http://www.terragalleria.com
Terragalleria主要基于视觉上的相似性,而不考虑图片的内容。
11)、http://labs.ideeinc.com/upload/
Byo image search是根据你上传的图片来搜索相似的图片,算法主要是基于色彩,也包括主题风。
12)、搜狗图片搜索:http://image.sogou.com/
作者:kezunhai 出处:http://blog.csdn.net/kezunhai 欢迎转载或分享,但请务必声明文章出处。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/195338.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
