大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
二叉树前序遍历
对于一种数据结构而言,我们最常见的就是遍历,那么关于二叉树我们该如何去遍历呢?
请看大屏幕 。。。。
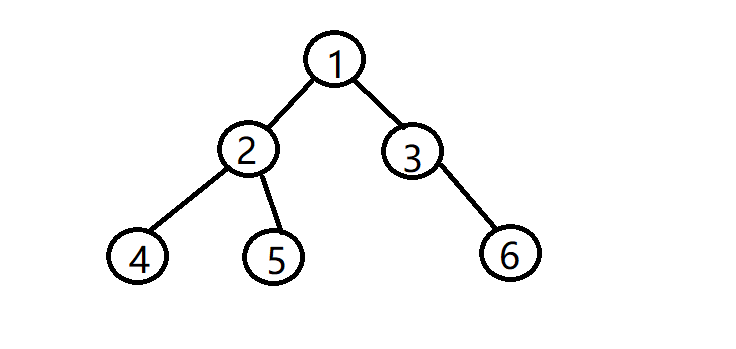

上图是一棵二叉树,前序遍历结果:1 2 4 5 3 6
咦,我想你可能会疑惑什么叫做前序遍历,其实很简单,就是按照 根 -》 左 -》 右 的方式去遍历二叉树。
-
首先让我们来看看如何递归的去前序遍历二叉树
注:在这里我特别强调一点,在我们二叉树中,如果采用递归的方式,大部分都采用的根左右的方式,即采用子问题的方式,即先处理跟节点,再处理左子树,再处理右子树的这样一种思想 -
前序递归遍历
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
vector<int>v;
vector<int> preorderTraversal(TreeNode* root) {
if(root!=NULL){
v.push_back(root->val); //将根节点放入容器中
preorderTraversal(root->left); //处理左子树
preorderTraversal(root->right); //处理右子树
}
return v;
}
};
你没看错,就这么简单,但是是如何递归的你得想清楚,这里我就不做详解了。那么接下来我们再看看非递归的方式
- 前序非递归遍历
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
vector<int>v;
stack<TreeNode*>s;
TreeNode* cur=root;
while(cur!=NULL || !s.empty()){
while(cur!=NULL){
v.push_back(cur->val);
s.push(cur);
cur=cur->left;
}
TreeNode* top=s.top();
s.pop();
cur=top->right;
}
return v;
}
};
这就是前序遍历的非递归方式,这种方式主要是采用栈来完成的。这个过程实在不好画图,所以只能靠大家自行理解了,类似一种搞传销的模式,不断的拉下线。。。。可能比喻不太恰当,不过我感觉还挺像的,哈哈!
All OVER
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/195236.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
