大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
写在前面
LSTM模型的一个常见用途是对长时间序列数据进行学习预测,例如得到了某商品前一年的日销量数据,我们可以用LSTM模型来预测未来一段时间内该商品的销量。但对于不熟悉神经网络或者对没有了解过RNN模型的人来说,想要看懂LSTM模型的原理是非常困难的,但有些时候我们不得不快速上手搭建一个LSTM模型来完成预测任务。下面我将对一个真实的时间序列数据集进行LSTM模型的搭建,不加入很多复杂的功能,快速的完成数据预测功能。
问题大概如下:某煤矿有一个监测井,我们每20分钟获取一次该监测井的地下水位埋深,共获取了30000多条真实数据,数据集包括采样日期,采样时间,LEVEL,温度,电导率,地下水位埋深等信息。使用采样日期、采样时间和地下水位埋深这三个信息训练LSTM模型,预测未来的水位高度。
数据预处理
首先读入数据,简单查看一下数据的前几行,代码如下:
data=pd.read_csv("data.csv")
print(data.head())输出如下图所示:
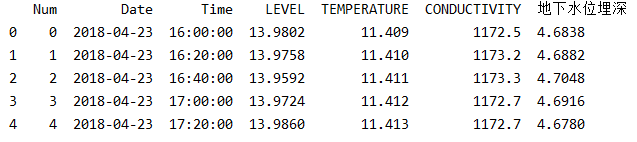

很显然,对于我们有用的信息只有Date、Time、地下水位埋深这三列。而且为了规范数据集,我们将Date列和Time列连接起来,并转换为python中的datetime格式。所以先将Date列和Time列用空格连接起来,然后将保留Date列和地下水位埋深列,其他列全部删除,代码如下:
data=pd.read_csv("data.csv")
data['Date']=data['Date']+' '
data['Date']=data['Date']+data['Time']
data.drop(['Time','LEVEL','TEMPERATURE','CONDUCTIVITY','Num'],axis=1,inplace=True)
data['Date']=pd.to_datetime(data['Date'])
print(data.head())打印处理后数据的前几列,如下图所示:
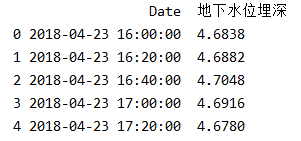
现在将Date列设为索引,即可绘制出地下水位埋深随时间变化的折线图,代码如下:
series = data.set_index(['Date'], drop=True)
plt.figure(figsize=(10, 6))
series['地下水位埋深'].plot()
plt.show()输出的折线图如下:
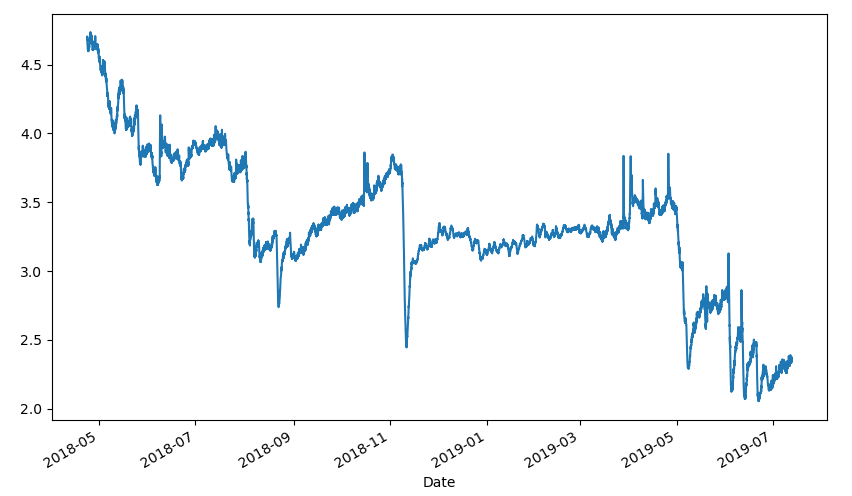
此时series中的数据可视为原始数据,下面要用它来构建训练神经网络的数据集。
构建数据集
1、首先将DataFrame格式的数据转换为二维数组的格式,例如将数据前三行进行转换后变成:[[4.6838],[4.6882],[4.7048]]。然后将其进行差分转换,就是除第一个数字外,其他数改为它本身与它前一个数的差值,例如前三行数据进行差分转换后为:[[4.6882-4.6838],[4.7048-4.6882]]。代码如下:
def difference(data_set,interval=1):
diff=list()
for i in range(interval,len(data_set)):
value=data_set[i]-data_set[i-interval]
diff.append(value)
return pd.Series(diff)
# 这里的series是之前数据预处理后得到的DateFrame型数据
raw_value=series.values
diff_value=difference(raw_value,1)进行差分转换后,数据变成了这样的形式:
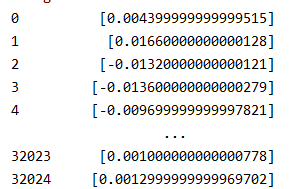
2、将时间序列形式的数据转换为监督学习集的形式,例如:[[10],[11],[12],[13],[14]]转换为[[0,10],[10,11],[11,12],[12,13],[13,14]],即把前一个数作为输入,后一个数作为对应输出。
def timeseries_to_supervised(data,lag=1):
df=pd.DataFrame(data)
columns=[df.shift(1)]
columns.append(df)
df=pd.concat(columns,axis=1)
df.fillna(0,inplace=True)
return df
supervised=timeseries_to_supervised(diff_value,1)
supervised_value=supervised.values解释一下函数体中的转换过程,首先将data转换为DataFrame格,shift(1)函数可以将数据整体下移一行,类似于原来是[10,11,12,13,14],执行shift(1)函数后成为:[NaN,10,11,12,13],溢出的数据直接丢弃。append()函数可以将两个DataFrame格式的数据连接起来,但两者又是分离的,类似于这样:[[NaN,10,11,12,13],[10,11,12,13,14]],只不过这里我用数组进行了类比。然后使用concat()函数将两个分离的DataFrame格式数据融合到一起,类似于这样:[[NaN,10],[10,11],[11,12],[12,13],[13,14]],但这里是数组形式的类比,不是DataFrame数据的真实情况。经过这一系列的处理后,数据变成了下面这个样子,可以跟上面的图进行对比来理解这里的操作过程:

3、将数据集分为训练集和测试集,这个问题下的数据有30000多条,就设置测试集为后6000条,代码如下:
testNum=6000
train,test=supervised_value[:-testNum],supervised_value[-testNum:]4、将训练集和测试集中的数据都缩放到[-1,1]之间,可以加快收敛。
def scale(train,test):
# 创建一个缩放器,将数据集中的数据缩放到[-1,1]的取值范围中
scaler=MinMaxScaler(feature_range=(-1,1))
# 使用数据来训练缩放器
scaler=scaler.fit(train)
# 使用缩放器来将训练集和测试集进行缩放
train_scaled=scaler.transform(train)
test_scaled=scaler.transform(test)
return scaler,train_scaled,test_scaled
scaler,train_scaled,test_scaled=scale(train,test)其中MinMaxScaler是一种缩放器,初始化后,使用训练集数据来训练好这个缩放器,然后对训练集和数据集都进行缩放。这个缩放器在之后预测的时候还要用来进行逆缩放,将预测值还原到真实的量纲上。此时训练集变成了下图这个样子,数据集已经构建完成,下面开始训练LSTM模型。

训练LSTM模型
1、首先将训练集中的输入和输出两列分为x和y,并将输入列转换为三维数组,此时X是一个[N*1*1]的数组,代码如下:
X,y=train[:,0:-1],train[:,-1]
X=X.reshape(X.shape[0],1,X.shape[1])此时的X是这样子的三维数组:

2、初始化LSTM模型并开始训练,设置神经元核心的个数,设置训练时输入数据的格式等等。对于预测时间序列类的问题,可直接使用下面的参数设置:
def fit_lstm(train,batch_size,nb_epoch,neurons):
# 将数据对中的x和y分开
X,y=train[:,0:-1],train[:,-1]
# 将2D数据拼接成3D数据,形状为[N*1*1]
X=X.reshape(X.shape[0],1,X.shape[1])
model=Sequential()
model.add(LSTM(neurons,batch_input_shape=(batch_size,X.shape[1],X.shape[2]),stateful=True))
model.add(Dense(1))
model.compile(loss='mean_squared_error',optimizer='adam')
for i in range(nb_epoch):
# shuffle是不混淆数据顺序
his=model.fit(X,y,batch_size=batch_size,verbose=1,shuffle=False)
# 每训练完一次就重置一次网络状态,网络状态与网络权重不同
model.reset_states()
return model
# 构建一个LSTM模型并训练,样本数为1,训练次数为3,LSTM层神经元个数为4
lstm_model=fit_lstm(train_scaled,1,3,4)此时lstm_model就是一个训练好的LSTM模型,我们可以使用它来进行测试。
模型的泛化
首先列出一条数据的处理过程:
1、将一条数据的输入和输出列分开,并且将输入进行变换,传入到预测函数中进行单步预测,详见注释,代码如下:
def forecast_lstm(model,batch_size,X):
# 将形状为[1:]的,包含一个元素的一维数组X,转换形状为[1,1,1]的3D张量
X=X.reshape(1,1,len(X))
# 输出形状为1行一列的二维数组yhat
yhat=model.predict(X,batch_size=batch_size)
# 将yhat中的结果返回
return yhat[0,0]
# 取出测试集中的一条数据,并将其拆分为X和y
X,y=test[i,0:-1],test[i,-1]
# 将训练好的模型、测试数据传入预测函数中
yhat=forecast_lstm(lstm_model,1,X)2、得到预测值后对其进行逆缩放和逆差分,将其还原到原来的取值范围内,详见注释,代码如下:
# 对预测的数据进行逆差分转换
def invert_difference(history,yhat,interval=1):
return yhat+history[-interval]
# 将预测值进行逆缩放,使用之前训练好的缩放器,x为一维数组,y为实数
def invert_scale(scaler,X,y):
# 将X,y转换为一个list列表
new_row=[x for x in X]+[y]
# 将列表转换为数组
array=np.array(new_row)
# 将数组重构成一个形状为[1,2]的二维数组->[[10,12]]
array=array.reshape(1,len(array))
# 逆缩放输入的形状为[1,2],输出形状也是如此
invert=scaler.inverse_transform(array)
# 只需要返回y值即可
return invert[0,-1]
# 将预测值进行逆缩放
yhat=invert_scale(scaler,X,yhat)
# 对预测的y值进行逆差分
yhat=invert_difference(raw_value,yhat,len(test_scaled)+1-i)遍历全部测试集数据,对每行数据执行以上操作,并将最终的预测值保存下来,代码如下:
predictions=list()
for i in range(len(test_scaled)):
# 将测试集拆分为X和y
X,y=test[i,0:-1],test[i,-1]
# 将训练好的模型、测试数据传入预测函数中
yhat=forecast_lstm(lstm_model,1,X)
# 将预测值进行逆缩放
yhat=invert_scale(scaler,X,yhat)
# 对预测的y值进行逆差分
yhat=invert_difference(raw_value,yhat,len(test_scaled)+1-i)
# 存储正在预测的y值
predictions.append(yhat)预测结果的可视化
将测试集的y值和预测值绘制在同一张图表中,代码如下。这个问题的数据集非常大,LSTM的训练效果非常好,标准差大概为2,预测结果符合预期。
plt.plot(raw_value[-testNum:])
plt.plot(predictions)
plt.legend(['true','pred'])
plt.show()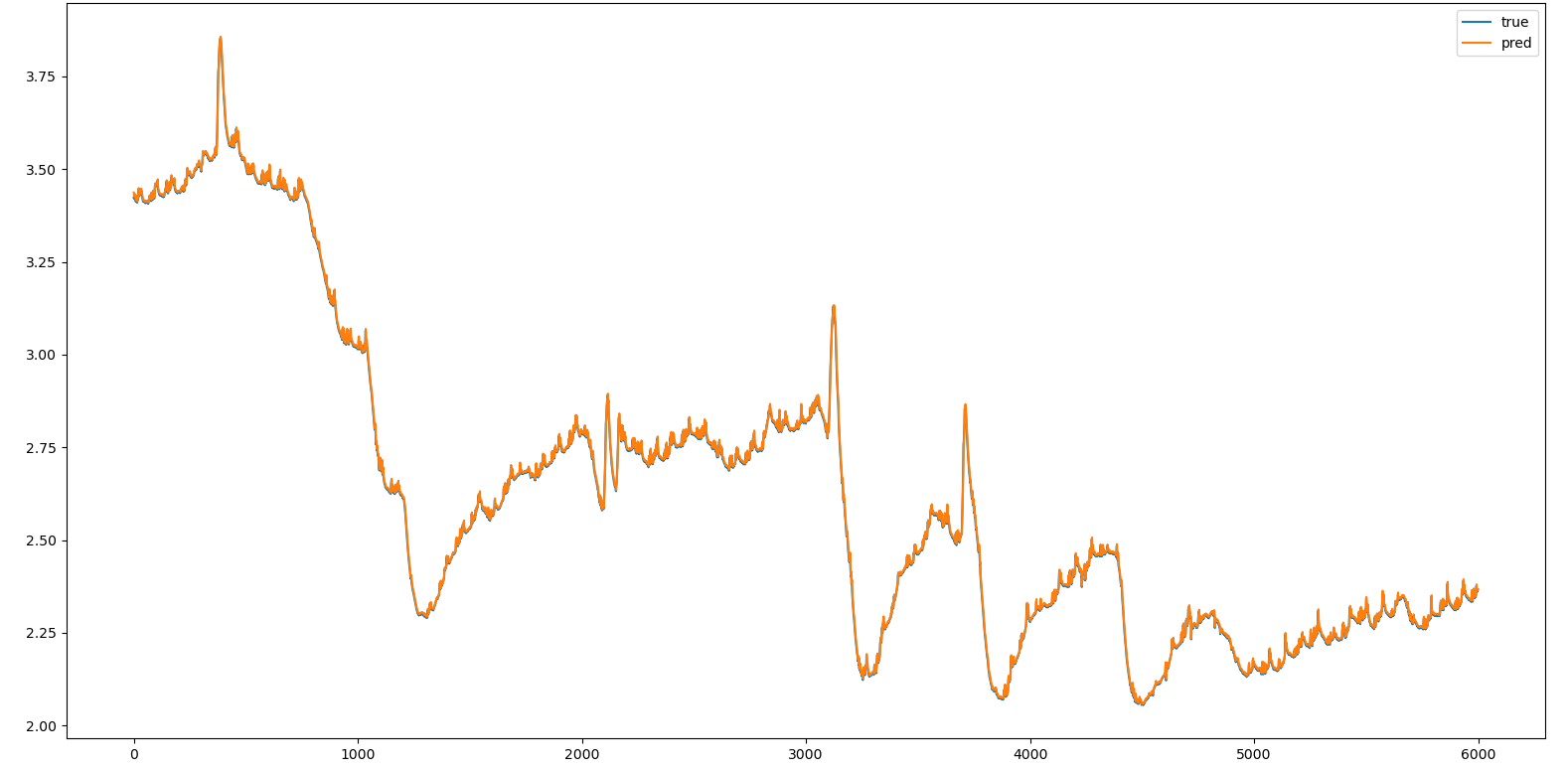
完整代码
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from keras.layers import LSTM
from keras.layers import Dense
from keras.models import Sequential
from sklearn.metrics import mean_squared_error
import numpy as np
import math
# 数据的差分转换
def difference(data_set,interval=1):
diff=list()
for i in range(interval,len(data_set)):
value=data_set[i]-data_set[i-interval]
diff.append(value)
return pd.Series(diff)
# 对预测的数据进行逆差分转换
def invert_difference(history,yhat,interval=1):
return yhat+history[-interval]
# 将数据转换为监督学习集,移位后产生的NaN值补0
def timeseries_to_supervised(data,lag=1):
df=pd.DataFrame(data)
columns=[df.shift(i) for i in range(1,lag+1)]
columns.append(df)
df=pd.concat(columns,axis=1)
df.fillna(0,inplace=True)
return df
# 将数据缩放到[-1,1]之间
def scale(train,test):
# 创建一个缩放器,将数据集中的数据缩放到[-1,1]的取值范围中
scaler=MinMaxScaler(feature_range=(-1,1))
# 使用数据来训练缩放器
scaler=scaler.fit(train)
# 使用缩放器来将训练集和测试集进行缩放
train_scaled=scaler.transform(train)
test_scaled=scaler.transform(test)
return scaler,train_scaled,test_scaled
# 将预测值进行逆缩放,使用之前训练好的缩放器,x为一维数组,y为实数
def invert_scale(scaler,X,y):
# 将X,y转换为一个list列表
new_row=[x for x in X]+[y]
# 将列表转换为数组
array=np.array(new_row)
# 将数组重构成一个形状为[1,2]的二维数组->[[10,12]]
array=array.reshape(1,len(array))
# 逆缩放输入的形状为[1,2],输出形状也是如此
invert=scaler.inverse_transform(array)
# 只需要返回y值即可
return invert[0,-1]
# 构建一个LSTM模型
def fit_lstm(train,batch_size,nb_epoch,neurons):
# 将数据对中的x和y分开
X,y=train[:,0:-1],train[:,-1]
# 将2D数据拼接成3D数据,形状为[N*1*1]
X=X.reshape(X.shape[0],1,X.shape[1])
model=Sequential()
model.add(LSTM(neurons,batch_input_shape=(batch_size,X.shape[1],X.shape[2]),stateful=True))
model.add(Dense(1))
model.compile(loss='mean_squared_error',optimizer='adam')
for i in range(nb_epoch):
# shuffle是不混淆数据顺序
his=model.fit(X,y,batch_size=batch_size,verbose=1,shuffle=False)
# 每训练完一次就重置一次网络状态,网络状态与网络权重不同
model.reset_states()
return model
# 开始单步预测
def forecast_lstm(model,batch_size,X):
# 将形状为[1:]的,包含一个元素的一维数组X,转换形状为[1,1,1]的3D张量
X=X.reshape(1,1,len(X))
# 输出形状为1行一列的二维数组yhat
yhat=model.predict(X,batch_size=batch_size)
# 将yhat中的结果返回
return yhat[0,0]
# 读取数据,将日期和时间列合并,其他列删除,合并后的列转换为时间格式,设为索引
data=pd.read_csv('data.csv')
data['Date']=data['Date']+' '
data['Date']=data['Date']+data['Time']
data.drop(['Num','LEVEL','TEMPERATURE','CONDUCTIVITY','Time'],axis=1,inplace=True)
data['Date']=pd.to_datetime(data['Date'])
series=data.set_index(['Date'],drop=True)
# 将原数据转换为二维数组形式,例如:
# [[4.6838],[4.6882],[4.7048]]
raw_value=series.values
# 将数据进行差分转换,例如[[4.6838],[4.6882],[4.7048]]转换为[[4.6882-4.6838],[4.7048-4.6882]]
diff_value=difference(raw_value,1)
#
# 将序列形式的数据转换为监督学习集形式,例如[[10],[11],[12],[13]]
# 在此将其转换为监督学习集形式:[[0,10],[10,11],[11,12],[12,13]],
# 即前一个数作为输入,后一个数作为对应的输出
supervised=timeseries_to_supervised(diff_value,1)
supervised_value=supervised.values
# 将数据集分割为训练集和测试集,设置后1000个数据为测试集
testNum=6000
train,test=supervised_value[:-testNum],supervised_value[-testNum:]
# 将训练集和测试集都缩放到[-1,1]之间
scaler,train_scaled,test_scaled=scale(train,test)
# 构建一个LSTM模型并训练,样本数为1,训练次数为5,LSTM层神经元个数为4
lstm_model=fit_lstm(train_scaled,1,1,4)
# 遍历测试集,对数据进行单步预测
predictions=list()
for i in range(len(test_scaled)):
# 将测试集拆分为X和y
X,y=test[i,0:-1],test[i,-1]
# 将训练好的模型、测试数据传入预测函数中
yhat=forecast_lstm(lstm_model,1,X)
# 将预测值进行逆缩放
yhat=invert_scale(scaler,X,yhat)
# 对预测的y值进行逆差分
yhat=invert_difference(raw_value,yhat,len(test_scaled)+1-i)
# 存储正在预测的y值
predictions.append(yhat)
# 计算方差
rmse=mean_squared_error(raw_value[:testNum],predictions)
print("Test RMSE:",rmse)
plt.plot(raw_value[-testNum:])
plt.plot(predictions)
plt.legend(['true','pred'])
plt.show()
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/195175.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
