大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
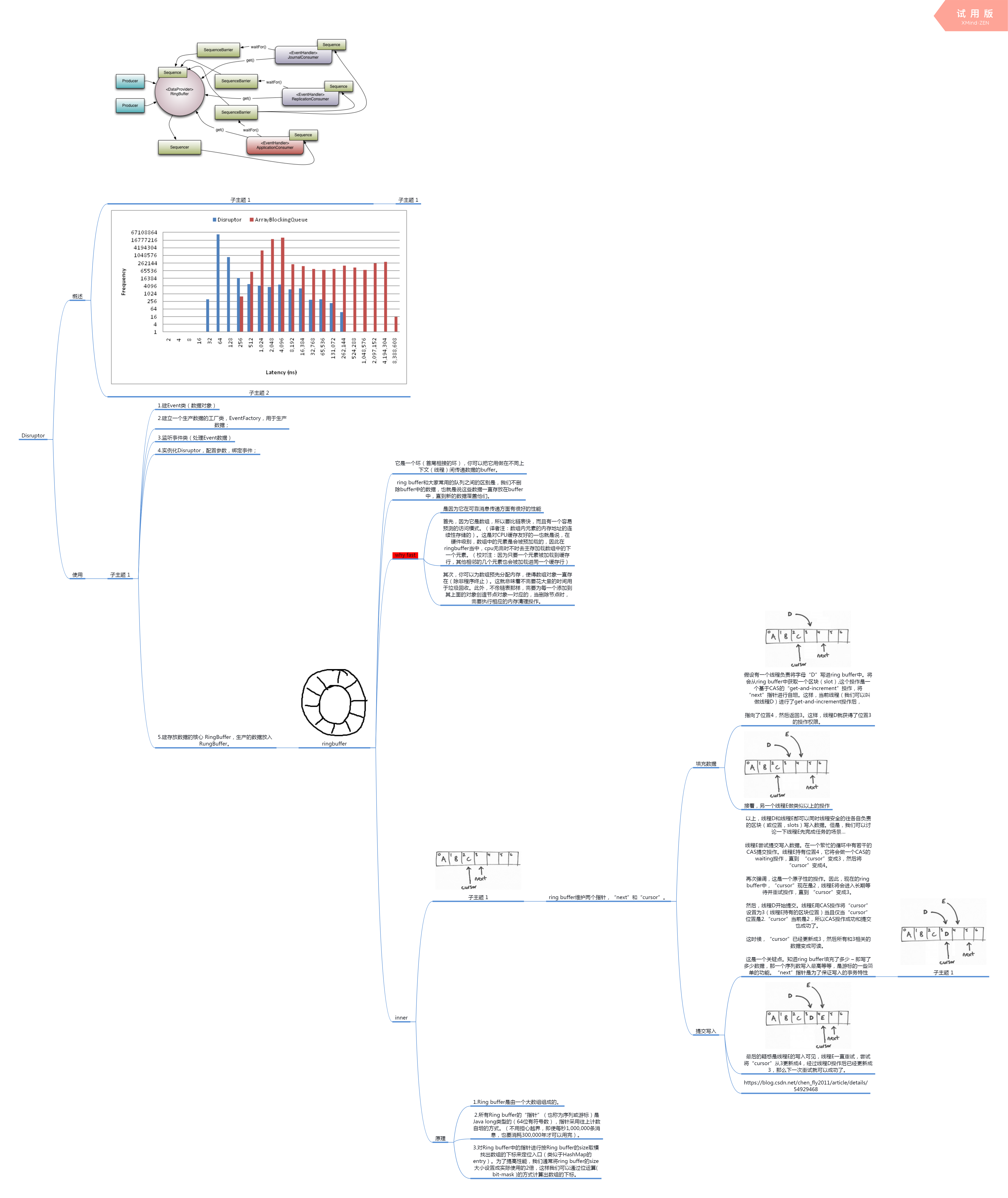

Disruptor
概述
子主题 1
- 从功能上来看,Disruptor 是实现了“队列”的功能,而且是一个有界队列。那么它的应用场景自然就是“生产者-消费者”模型的应用场合了。
可以拿 JDK 的 BlockingQueue 做一个简单对比,以便更好地认识 Disruptor 是什么。
我们知道 BlockingQueue 是一个 FIFO 队列,生产者(Producer)往队列里发布(publish)一项事件(或称之为“消息”也可以)时,消费者(Consumer)能获得通知;如果没有事件时,消费者被堵塞,直到生产者发布了新的事件。
这些都是 Disruptor 能做到的,与之不同的是,Disruptor 能做更多:
同一个“事件”可以有多个消费者,消费者之间既可以并行处理,也可以相互依赖形成处理的先后次序(形成一个依赖图);
预分配用于存储事件内容的内存空间;
针对极高的性能目标而实现的极度优化和无锁的设计;
以上的描述虽然简单地指出了 Disruptor 是什么,但对于它“能做什么”还不是那么直截了当。一般性地来说,当你需要在两个独立的处理过程(两个线程)之间交换数据时,就可以使用 Disruptor 。当然使用队列(如上面提到的 BlockingQueue)也可以,只不过 Disruptor 做得更好。
拿队列来作比较的做法弱化了对 Disruptor 有多强大的认识,如果想要对此有更多的了解,可以仔细看看 Disruptor 在其东家 LMAX 交易平台(也是实现者) 是如何作为核心架构来使用的,这方面就不做详述了,问度娘或谷哥都能找到。
原文:https://blog.csdn.net/nuaazhaofeng/article/details/72918467
子主题 2
使用
子主题 1
- 1.建Event类(数据对象)
- 2.建立一个生产数据的工厂类,EventFactory,用于生产数据;
- 3.监听事件类(处理Event数据)
- 4.实例化Disruptor,配置参数,绑定事件;
- 5.建存放数据的核心 RingBuffer,生产的数据放入 RungBuffer。
- ringbuffer
- 它是一个环(首尾相接的环),你可以把它用做在不同上下文(线程)间传递数据的buffer。
- ring buffer和大家常用的队列之间的区别是,我们不删除buffer中的数据,也就是说这些数据一直存放在buffer中,直到新的数据覆盖他们。
- why fast
- 是因为它在可靠消息传递方面有很好的性能
- 首先,因为它是数组,所以要比链表快,而且有一个容易预测的访问模式。(译者注:数组内元素的内存地址的连续性存储的)。这是对CPU缓存友好的—也就是说,在硬件级别,数组中的元素是会被预加载的,因此在ringbuffer当中,cpu无需时不时去主存加载数组中的下一个元素。(校对注:因为只要一个元素被加载到缓存行,其他相邻的几个元素也会被加载进同一个缓存行)
- 其次,你可以为数组预先分配内存,使得数组对象一直存在(除非程序终止)。这就意味着不需要花大量的时间用于垃圾回收。此外,不像链表那样,需要为每一个添加到其上面的对象创造节点对象—对应的,当删除节点时,需要执行相应的内存清理操作。
- inner
- 子主题 1
- ring buffer维护两个指针,“next”和“cursor”。
- 填充数据
- 假设有一个线程负责将字母“D”写进ring buffer中。将会从ring buffer中获取一个区块(slot),这个操作是一个基于CAS的“get-and-increment”操作,将“next”指针进行自增。这样,当前线程(我们可以叫做线程D)进行了get-and-increment操作后,
- 填充数据
- ring buffer维护两个指针,“next”和“cursor”。
- 子主题 1
- ringbuffer
指向了位置4,然后返回3。这样,线程D就获得了位置3的操作权限。
* 接着,另一个线程E做类似以上的操作
* 提交写入
* 以上,线程D和线程E都可以同时线程安全的往各自负责的区块(或位置,slots)写入数据。但是,我们可以讨论一下线程E先完成任务的场景…
线程E尝试提交写入数据。在一个繁忙的循环中有若干的CAS提交操作。线程E持有位置4,它将会做一个CAS的waiting操作,直到 “cursor”变成3,然后将“cursor”变成4。
再次强调,这是一个原子性的操作。因此,现在的ring buffer中,“cursor”现在是2,线程E将会进入长期等待并重试操作,直到 “cursor”变成3。
然后,线程D开始提交。线程E用CAS操作将“cursor”设置为3(线程E持有的区块位置)当且仅当“cursor”位置是2.“cursor”当前是2,所以CAS操作成功和提交也成功了。
这时候,“cursor”已经更新成3,然后所有和3相关的数据变成可读。
这是一个关键点。知道ring buffer填充了多少 – 即写了多少数据,那一个序列数写入最高等等,是游标的一些简单的功能。“next”指针是为了保证写入的事务特性
* 子主题 1
* 最后的疑惑是线程E的写入可见,线程E一直重试,尝试将“cursor”从3更新成4,经过线程D操作后已经更新成3,那么下一次重试就可以成功了。
* https://blog.csdn.net/chen_fly2011/article/details/54929468
* 原理
* 1.Ring buffer是由一个大数组组成的。
* 2.所有Ring buffer的“指针”(也称为序列或游标)是Java long类型的(64位有符号数),指针采用往上计数自增的方式。(不用担心越界,即使每秒1,000,000条消息,也要消耗300,000年才可以用完)。
* 3.对Ring buffer中的指针进行按Ring buffer的size取模找出数组的下标来定位入口(类似于HashMap的entry)。为了提高性能,我们通常将ring buffer的size大小设置成实际使用的2倍,这样我们可以通过位运算(bit-mask )的方式计算出数组的下标。
XMind: ZEN – Trial Version
代码实现:
LongEventMain
主入口:
import java.nio.ByteBuffer;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import org.apache.log4j.LogManager;
import org.apache.logging.log4j.core.Logger;
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.YieldingWaitStrategy;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.dsl.ProducerType;
public class LongEventMain {
public static void main(String[] args) throws Exception {
//创建缓冲池
ExecutorService executor = Executors.newCachedThreadPool();
//创建工厂
LongEventFactory factory = new LongEventFactory();
//创建bufferSize ,也就是RingBuffer大小,必须是2的N次方
int ringBufferSize = 1024 * 1024; //
/**
//BlockingWaitStrategy 是最低效的策略,但其对CPU的消耗最小并且在各种不同部署环境中能提供更加一致的性能表现
WaitStrategy BLOCKING_WAIT = new BlockingWaitStrategy();
//SleepingWaitStrategy 的性能表现跟BlockingWaitStrategy差不多,对CPU的消耗也类似,但其对生产者线程的影响最小,适合用于异步日志类似的场景
WaitStrategy SLEEPING_WAIT = new SleepingWaitStrategy();
//YieldingWaitStrategy 的性能是最好的,适合用于低延迟的系统。在要求极高性能且事件处理线数小于CPU逻辑核心数的场景中,推荐使用此策略;例如,CPU开启超线程的特性
WaitStrategy YIELDING_WAIT = new YieldingWaitStrategy();
*/
//创建disruptor
Disruptor<LongEvent> disruptor =
new Disruptor<LongEvent>(factory, ringBufferSize, executor, ProducerType.SINGLE, new YieldingWaitStrategy());
// 连接消费事件方法
disruptor.handleEventsWith(new LongEventHandler());
// 启动
disruptor.start();
//Disruptor 的事件发布过程是一个两阶段提交的过程:
//发布事件
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
org.apache.log4j.Logger logger1 = LogManager.getLogger(LongEventMain.class);
LongEventProducer producer = new LongEventProducer(ringBuffer);
//LongEventProducerWithTranslator producer = new LongEventProducerWithTranslator(ringBuffer);
ByteBuffer byteBuffer = ByteBuffer.allocate(8);
for(long l = 0; l<1000; l++){
byteBuffer.putLong(0, l);
producer.onData(byteBuffer);
//Thread.sleep(1000);
}
disruptor.shutdown();//关闭 disruptor,方法会堵塞,直至所有的事件都得到处理;
executor.shutdown();//关闭 disruptor 使用的线程池;如果需要的话,必须手动关闭, disruptor 在 shutdown 时不会自动关闭;
}
}
-准备工厂类
import com.lmax.disruptor.EventFactory;
//需要让disruptor为我们创建事件,我们同时还声明了一个EventFactory来实例化Event对象。
public class LongEventFactory implements EventFactory {
public Object newInstance() {
return new LongEvent();
}
}
public class LongEvent {
private long value;
public long getValue() {
return value;
}
public void setValue(long value) {
this.value = value;
}
}
生产者:
public class LongEventProducer {
private final RingBuffer<LongEvent> ringBuffer;
public LongEventProducer(RingBuffer<LongEvent> ringBuffer){
this.ringBuffer = ringBuffer;
}
/**
* onData用来发布事件,每调用一次就发布一次事件
* 它的参数会用过事件传递给消费者
*/
public void onData(ByteBuffer bb){
//1.可以把ringBuffer看做一个事件队列,那么next就是得到下面一个事件槽
long sequence = ringBuffer.next();
try {
//2.用上面的索引取出一个空的事件用于填充(获取该序号对应的事件对象)
LongEvent event = ringBuffer.get(sequence);
//3.获取要通过事件传递的业务数据
event.setValue(bb.getLong(0));
} finally {
//4.发布事件
//注意,最后的 ringBuffer.publish 方法必须包含在 finally 中以确保必须得到调用;如果某个请求的 sequence 未被提交,将会堵塞后续的发布操作或者其它的 producer。
ringBuffer.publish(sequence);
}
}
}
消费者
//我们还需要一个事件消费者,也就是一个事件处理器。这个事件处理器简单地把事件中存储的数据打印到终端:
public class LongEventHandler implements EventHandler<LongEvent> {
public void onEvent(LongEvent longEvent, long l, boolean b) throws Exception {
System.out.println(longEvent.getValue()+" haha");
}
}
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/195162.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
