大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
一:HashMap底层实现原理解析
我们常见的有数据结构有三种结构:1、数组结构 2、链表结构 3、哈希表结构 下面我们来看看各自的数据结构的特点:
1、数组结构: 存储区间连续、内存占用严重、空间复杂度大
- 优点:随机读取和修改效率高,原因是数组是连续的(随机访问性强,查找速度快)
- 缺点:插入和删除数据效率低,因插入数据,这个位置后面的数据在内存中都要往后移动,且大小固定不易动态扩展。
2、链表结构:存储区间离散、占用内存宽松、空间复杂度小
- 优点:插入删除速度快,内存利用率高,没有固定大小,扩展灵活
- 缺点:不能随机查找,每次都是从第一个开始遍历(查询效率低)
3、哈希表结构:结合数组结构和链表结构的优点,从而实现了查询和修改效率高,插入和删除效率也高的一种数据结构
常见的HashMap就是这样的一种数据结构
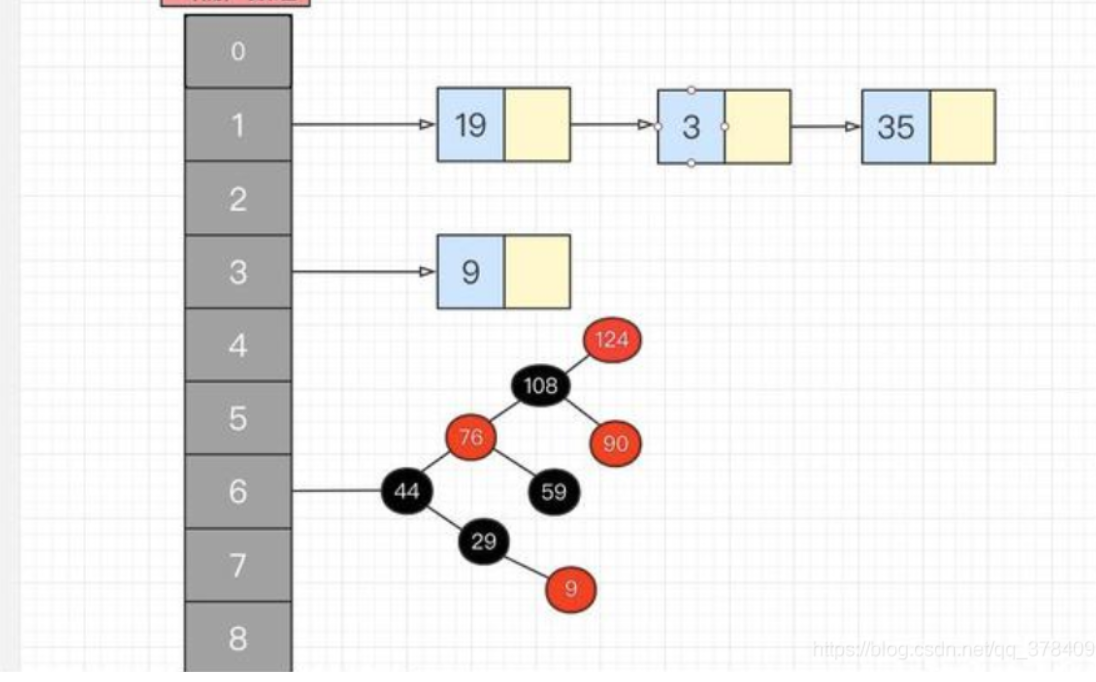

HashMap中的put()和get()的实现原理:
- 1、map.put(k,v)实现原理
(1)首先将k,v封装到Node对象当中(节点)。
(2)然后它的底层会调用K的hashCode()方法得出hash值。
(3)通过哈希表函数/哈希算法,将hash值转换成数组的下标,下标位置上如果没有任何元素,就把Node添加到这个位置上。如果说下标对应的位置上有链表。此时,就会拿着k和链表上每个节点的k进行equal。如果所有的equals方法返回都是false,那么这个新的节点将被添加到链表的末尾。如其中有一个equals返回了true,那么这个节点的value将会被覆盖。 - 2、map.get(k)实现原理
(1)先调用k的hashCode()方法得出哈希值,并通过哈希算法转换成数组的下标。
(2)通过上一步哈希算法转换成数组的下标之后,在通过数组下标快速定位到某个位置上。如果这个位置上什么都没有,则返回null。如果这个位置上有单向链表,那么它就会拿着K和单向链表上的每一个节点的K进行equals,如果所有equals方法都返回false,则get方法返回null。如果其中一个节点的K和参数K进行equals返回true,那么此时该节点的value就是我们要找的value了,get方法最终返回这个要找的value。
为何随机增删、查询效率都很高的原因是?
原因: 增删是在链表上完成的,而查询只需扫描部分,则效率高。
HashMap集合的key,会先后调用两个方法,hashCode and equals方法,这这两个方法都需要重写。
为什么放在hashMap集合key部分的元素需要重写equals方法?
因为equals方法默认比较的是两个对象的内存地址
二:HashMap红黑树原理分析
相比 jdk1.7 的 HashMap 而言,jdk1.8最重要的就是引入了红黑树的设计,当hash表的单一链表长度超过 8 个的时候,链表结构就会转为红黑树结构。
为什么要这样设计呢?好处就是避免在最极端的情况下链表变得很长很长,在查询的时候,效率会非常慢。
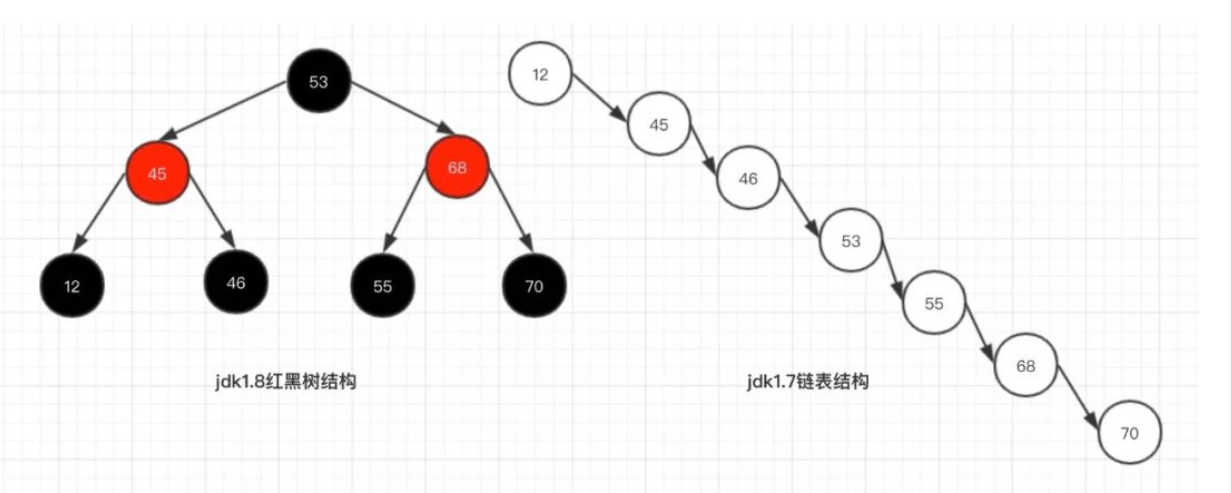
- 红黑树查询:其访问性能近似于折半查找,时间复杂度 O(logn);
- 链表查询:这种情况下,需要遍历全部元素才行,时间复杂度 O(n);
简单的说,红黑树是一种近似平衡的二叉查找树,其主要的优点就是“平衡“,即左右子树高度几乎一致,以此来防止树退化为链表,通过这种方式来保障查找的时间复杂度为 log(n)。
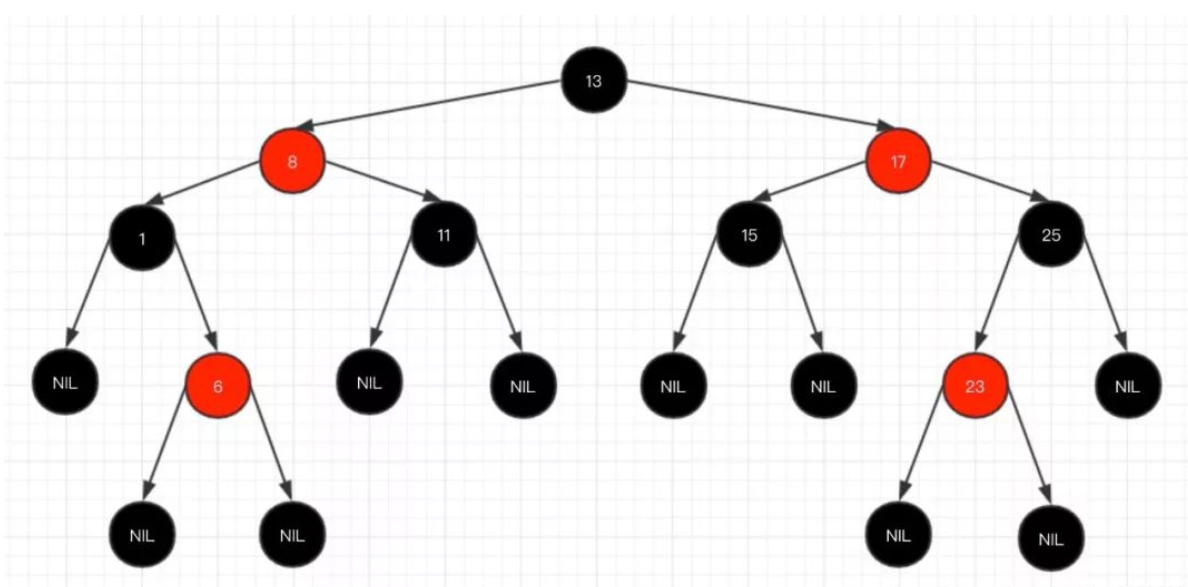
关于红黑树的内容,网上给出的内容非常多,主要有以下几个特性:
-
1、每个节点要么是红色,要么是黑色,但根节点永远是黑色的;
-
2、每个红色节点的两个子节点一定都是黑色;
-
3、红色节点不能连续(也即是,红色节点的孩子和父亲都不能是红色);
-
4、从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点;
-
5、所有的叶节点都是是黑色的(注意这里说叶子节点其实是上图中的 NIL 节点);
在树的结构发生改变时(插入或者删除操作),往往会破坏上述条件 3 或条件 4,需要通过调整使得查找树重新满足红黑树的条件。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/195154.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
