大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
前言
在前两篇文章二叉树和二叉搜索树中已经涉及到了二叉树的三种遍历。递归写法,只要理解思想,几行代码。可是非递归写法却很不容易。这里特地总结下,透彻解析它们的非递归写法。其中,中序遍历的非递归写法最简单,后序遍历最难。我们的讨论基础是这样的:
//Binary Tree Node
typedef struct node
{
int data;
struct node* lchild; //左孩子
struct node* rchild; //右孩子
}BTNode;首先,有一点是明确的:非递归写法一定会用到栈,这个应该不用太多的解释。我们先看中序遍历:
中序遍历
分析
中序遍历的递归定义:先左子树,后根节点,再右子树。如何写非递归代码呢?一句话:让代码跟着思维走。我们的思维是什么?思维就是中序遍历的路径。假设,你面前有一棵二叉树,现要求你写出它的中序遍历序列。如果你对中序遍历理解透彻的话,你肯定先找到左子树的最下边的节点。那么下面的代码就是理所当然的:
中序代码段(i)
BTNode* p = root; //p指向树根
stack<BTNode*> s; //STL中的栈
//一直遍历到左子树最下边,边遍历边保存根节点到栈中
while (p)
{
s.push(p);
p = p->lchild;
}
保存一路走过的根节点的理由是:中序遍历的需要,遍历完左子树后,需要借助根节点进入右子树。代码走到这里,指针p为空,此时无非两种情况:

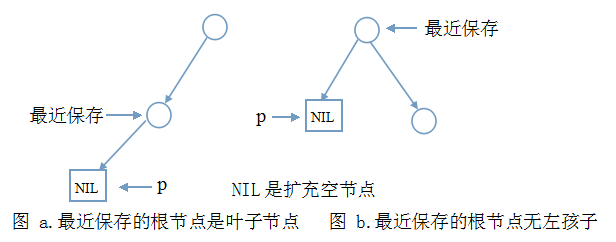
说明:
- 上图中只给出了必要的节点和边,其它的边和节点与讨论无关,不必画出。
- 你可能认为图a中最近保存节点算不得是根节点。如果你看过树、二叉树基础,使用扩充二叉树的概念,就可以解释。总之,不用纠结这个没有意义问题。
- 整个二叉树只有一个根节点的情况可以划到图a。
p = s.top();
s.pop();
cout << p->data;
我们的思维接着走,两图情形不同得区别对待:
p = s.top();
s.pop();
cout << p->data;
p = s.top();
s.pop();
cout << p->data;
p = s.top();
s.pop();
cout << p->data;
p = p->rchild;
p = s.top();
s.pop();
cout << p->data;
p = p->rchild;
中序代码段(ii)
p = s.top();
s.pop();
cout << p->data;
p = p->rchild;
BTNode* p = root;stack<BTNode*> s;while (!s.empty() || p){ //代码段(i)一直遍历到左子树最下边,边遍历边保存根节点到栈中 while (p) { s.push(p); p = p->lchild; } //代码段(ii)当p为空时,说明已经到达左子树最下边,这时需要出栈了 if (!s.empty()) { p = s.top(); s.pop(); cout << setw(4) << p->data; //进入右子树,开始新的一轮左子树遍历(这是递归的自我实现) p = p->rchild; }}
仔细想想,上述代码是不是根据我们的思维走向而写出来的呢?再加上边界条件的检测,中序遍历非递归形式的完整代码是这样的:
中序遍历代码一
//中序遍历void InOrderWithoutRecursion1(BTNode* root){ //空树 if (root == NULL) return; //树非空 BTNode* p = root; stack<BTNode*> s; while (!s.empty() || p) { //一直遍历到左子树最下边,边遍历边保存根节点到栈中 while (p) { s.push(p); p = p->lchild; } //当p为空时,说明已经到达左子树最下边,这时需要出栈了 if (!s.empty()) { p = s.top(); s.pop(); cout << setw(4) << p->data; //进入右子树,开始新的一轮左子树遍历(这是递归的自我实现) p = p->rchild; } }}
恭喜你,你已经完成了中序遍历非递归形式的代码了。回顾一下难吗?
中序遍历代码二
//中序遍历void InOrderWithoutRecursion2(BTNode* root){ //空树 if (root == NULL) return; //树非空 BTNode* p = root; stack<BTNode*> s; while (!s.empty() || p) { if (p) { s.push(p); p = p->lchild; } else { p = s.top(); s.pop(); cout << setw(4) << p->data; p = p->rchild; } }}
前序遍历
分析
前序代码段(i)
//边遍历边打印,并存入栈中,以后需要借助这些根节点(不要怀疑这种说法哦)进入右子树
while (p)
{
cout << setw(4) << p->data;
s.push(p);
p = p->lchild;
}
接下来就是:出栈,根据栈顶节点进入右子树。
前序代码段(ii)
//当p为空时,说明根和左子树都遍历完了,该进入右子树了if (!s.empty()){ p = s.top(); s.pop(); p = p->rchild;}
同样地,代码段(i)(ii)构成了一次完整的循环体。至此,不难写出完整的前序遍历的非递归写法。
前序遍历代码一
void PreOrderWithoutRecursion1(BTNode* root){ if (root == NULL) return; BTNode* p = root; stack<BTNode*> s; while (!s.empty() || p) { //边遍历边打印,并存入栈中,以后需要借助这些根节点(不要怀疑这种说法哦)进入右子树 while (p) { cout << setw(4) << p->data; s.push(p); p = p->lchild; } //当p为空时,说明根和左子树都遍历完了,该进入右子树了 if (!s.empty()) { p = s.top(); s.pop(); p = p->rchild; } } cout << endl;}
下面给出,本质是一样的另一段代码:
前序遍历代码二
//前序遍历void PreOrderWithoutRecursion2(BTNode* root){ if (root == NULL) return; BTNode* p = root; stack<BTNode*> s; while (!s.empty() || p) { if (p) { cout << setw(4) << p->data; s.push(p); p = p->lchild; } else { p = s.top(); s.pop(); p = p->rchild; } } cout << endl;}在二叉树中使用的是这样的写法,略有差别,本质上也是一样的:
前序遍历代码三
void PreOrderWithoutRecursion3(BTNode* root)
{
if (root == NULL)
return;
stack<BTNode*> s;
BTNode* p = root;
s.push(root);
while (!s.empty()) //循环结束条件与前两种不一样
{
//这句表明p在循环中总是非空的
cout << setw(4) << p->data;
/*
栈的特点:先进后出
先被访问的根节点的右子树后被访问
*/
if (p->rchild)
s.push(p->rchild);
if (p->lchild)
p = p->lchild;
else
{//左子树访问完了,访问右子树
p = s.top();
s.pop();
}
}
cout << endl;
}后序遍历
分析
后序遍历代码一
//后序遍历
void PostOrderWithoutRecursion(BTNode* root)
{
if (root == NULL)
return;
stack<BTNode*> s;
//pCur:当前访问节点,pLastVisit:上次访问节点
BTNode* pCur, *pLastVisit;
//pCur = root;
pCur = root;
pLastVisit = NULL;
//先把pCur移动到左子树最下边
while (pCur)
{
s.push(pCur);
pCur = pCur->lchild;
}
while (!s.empty())
{
//走到这里,pCur都是空,并已经遍历到左子树底端(看成扩充二叉树,则空,亦是某棵树的左孩子)
pCur = s.top();
s.pop();
//一个根节点被访问的前提是:无右子树或右子树已被访问过
if (pCur->rchild == NULL || pCur->rchild == pLastVisit)
{
cout << setw(4) << pCur->data;
//修改最近被访问的节点
pLastVisit = pCur;
}
/*这里的else语句可换成带条件的else if:
else if (pCur->lchild == pLastVisit)//若左子树刚被访问过,则需先进入右子树(根节点需再次入栈)
因为:上面的条件没通过就一定是下面的条件满足。仔细想想!
*/
else
{
//根节点再次入栈
s.push(pCur);
//进入右子树,且可肯定右子树一定不为空
pCur = pCur->rchild;
while (pCur)
{
s.push(pCur);
pCur = pCur->lchild;
}
}
}
cout << endl;
}后序遍历代码二
//定义枚举类型:Tag
enum Tag{left,right};
//自定义新的类型,把二叉树节点和标记封装在一起
typedef struct
{
BTNode* node;
Tag tag;
}TagNode;
//后序遍历
void PostOrderWithoutRecursion2(BTNode* root)
{
if (root == NULL)
return;
stack<TagNode> s;
TagNode tagnode;
BTNode* p = root;
while (!s.empty() || p)
{
while (p)
{
tagnode.node = p;
//该节点的左子树被访问过
tagnode.tag = Tag::left;
s.push(tagnode);
p = p->lchild;
}
tagnode = s.top();
s.pop();
//左子树被访问过,则还需进入右子树
if (tagnode.tag == Tag::left)
{
//置换标记
tagnode.tag = Tag::right;
//再次入栈
s.push(tagnode);
p = tagnode.node;
//进入右子树
p = p->rchild;
}
else//右子树已被访问过,则可访问当前节点
{
cout << setw(4) << (tagnode.node)->data;
//置空,再次出栈(这一步是理解的难点)
p = NULL;
}
}
cout << endl;
}<span style="font-family: 'Courier New'; "> </span>总结
- 所有的节点都可看做是父节点(叶子节点可看做是两个孩子为空的父节点)。
- 把同一算法的代码对比着看。在差异中往往可看到算法的本质。
- 根据自己的理解,尝试修改代码。写出自己理解下的代码。写成了,那就是真的掌握了。
专栏目录:
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/195115.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
