大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
目录
1.写在前面
BP神经网络算法作为作为机器学习最基础的算法,非常适合入门。透彻掌握其原理将对于今后的机器学习有很大的帮助。
2.BP神经网络推导
2.1前向传播
前向传播过程可以表示为:
O [ l ] = σ ( w [ l ] I [ l − 1 ] + b [ l ] ) O^{[l]}=\sigma\left(w^{[l]} I^{[l-1]}+b^{[l]}\right) O[l]=σ(w[l]I[l−1]+b[l])
2.2反向传播
2.2.1求解梯度矩阵
假设函数 f : R n × 1 → R f:R^{n \times 1} \rightarrow R f:Rn×1→R 将输入的列向量(shape: n × 1 n \times 1 n×1 )映射为一个实数。那么,函数 f f f 的梯度定义为:
∇ x f ( x ) = [ ∂ f ( x ) ∂ x 1 ∂ f ( x ) ∂ x 2 ⋮ ∂ f ( x ) ∂ x n ] \nabla_{x} f(x)=\left[\begin{array}{c}\frac{\partial f(x)}{\partial x_{1}} \\ \frac{\partial f(x)}{\partial x_{2}} \\ \vdots \\ \frac{\partial f(x)}{\partial x_{n}}\end{array}\right] ∇xf(x)=⎣⎢⎢⎢⎢⎡∂x1∂f(x)∂x2∂f(x)⋮∂xn∂f(x)⎦⎥⎥⎥⎥⎤
同理,假设函数 f : R m × n → R f: R^{m \times n} \rightarrow R f:Rm×n→R 将输入的矩阵(shape: m × n m \times n m×n )映射为一个实数。函数 f f f 的梯度定义为:
∇ A f ( A ) = [ ∂ f ( A ) ∂ A 11 ∂ f ( A ) ∂ A 12 … ∂ f ( A ) ∂ A 13 ∂ f ( A ) ∂ A 21 ∂ f ( A ) ∂ A 22 … ∂ f ( A ) ∂ A 2 n ⋮ ⋮ ⋱ ⋮ ∂ f ( A ) ∂ A m 1 ∂ f ( A ) ∂ A m 2 … ∂ f ( A ) ∂ A m n ] \nabla_{A} f(A)=\left[\begin{array}{cccc}\frac{\partial f(A)}{\partial A_{11}} & \frac{\partial f(A)}{\partial A_{12}} & \dots & \frac{\partial f(A)}{\partial A_{13}} \\ \frac{\partial f(A)}{\partial A_{21}} & \frac{\partial f(A)}{\partial A_{22}} & \dots & \frac{\partial f(A)}{\partial A_{2 n}} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial f(A)}{\partial A_{m 1}} & \frac{\partial f(A)}{\partial A_{m 2}} & \dots & \frac{\partial f(A)}{\partial A_{m n}}\end{array}\right] ∇Af(A)=⎣⎢⎢⎢⎢⎡∂A11∂f(A)∂A21∂f(A)⋮∂Am1∂f(A)∂A12∂f(A)∂A22∂f(A)⋮∂Am2∂f(A)……⋱…∂A13∂f(A)∂A2n∂f(A)⋮∂Amn∂f(A)⎦⎥⎥⎥⎥⎤
可以简化为:
( ∇ A f ( A ) ) i j = ∂ f ( A ) ∂ A i j \left(\nabla_{A} f(A)\right)_{i j}=\frac{\partial f(A)}{\partial A_{i j}} (∇Af(A))ij=∂Aij∂f(A)
2.2.2梯度下降法
从几何意义,梯度矩阵代表了函数增加最快的方向,沿着梯度相反的方向可以更快找到最小值。
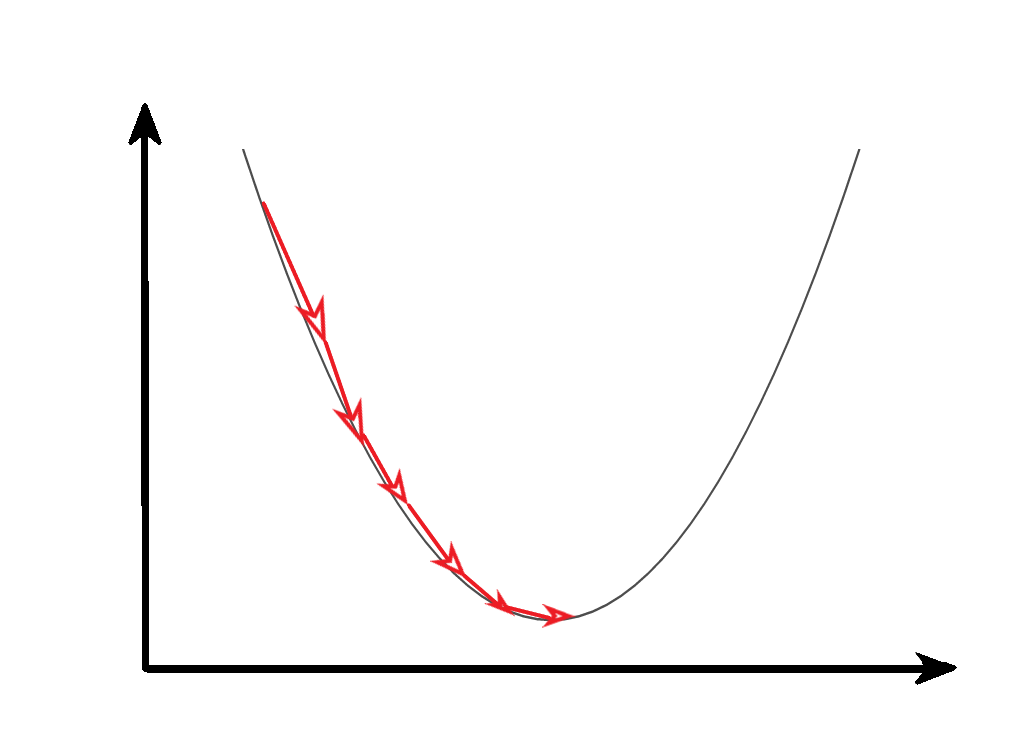

反向传播的过程就是利用梯度下降法原理,逐步找到成本函数的最小值,得到最终的模型参数。
2.2.3反向传播公式推导
输出层误差
δ j [ L ] = ∂ L ∂ a j [ L ] σ ′ ( z j [ L ] ) \delta_{j}^{[L]}=\frac{\partial L}{\partial a_{j}^{[L]}} \sigma^{\prime}\left(z_{j}^{[L]}\right) δj[L]=∂aj[L]∂Lσ′(zj[L])
L表示输出层层数。以下用 ∂ L \partial L ∂L 表示 ∂ L ( a [ L ] , y ) \partial L\left(a^{[L]}, y\right) ∂L(a[L],y)
推导
计算输出层的误差 δ j [ L ] = ∂ L ∂ z j [ L ] \delta_{j}^{[L]}=\frac{\partial L}{\partial z_{j}^{[L]}} δj[L]=∂zj[L]∂L ,根据链式法则
δ j [ L ] = ∑ k ∂ L ∂ a k [ L ] ∂ a k [ L ] ∂ z j [ L ] \delta_{j}^{[L]}=\sum_{k} \frac{\partial L}{\partial a_{k}^{[L]}} \frac{\partial a_{k}^{[L]}}{\partial z_{j}^{[L]}} δj[L]=∑k∂ak[L]∂L∂zj[L]∂ak[L]
输出层不一定只有一个神经元,可能有多个神经元。成本函数是每个输出神经元的损失函数之和,每个输出神经元的误差与其它神经元没有关系,所以只有 k = j k=j k=j 的时候值不是0。
当 k ≠ j k\neq j k=j 时, ∂ L ∂ z j [ L ] = 0 \frac{\partial L}{\partial z_{j}^{[L]}}=0 ∂zj[L]∂L=0 ,简化误差 δ j [ L ] \delta_{j}^{[L]} δj[L] ,得到
δ j [ L ] = ∂ L ∂ a j [ L ] ∂ a j [ L ] ∂ z j [ L ] \delta_{j}^{[L]}=\frac{\partial L}{\partial a_{j}^{[L]}} \frac{\partial a_{j}^{[L]}}{\partial z_{j}^{[L]}} δj[L]=∂aj[L]∂L∂zj[L]∂aj[L]
σ \sigma σ 表示激活函数,由 a j [ L ] = σ ( z j [ L ] ) a_{j}^{[L]}=\sigma\left(z_{j}^{[L]}\right) aj[L]=σ(zj[L]),计算出 ∂ a j [ L ] ∂ z j [ L ] = σ ′ ( z j [ L ] ) \frac{\partial a_{j}^{[L]}}{\partial z_{j}^{[L]}}=\sigma^{\prime}\left(z_{j}^{[L]}\right) ∂zj[L]∂aj[L]=σ′(zj[L]) ,代入最后得到
δ j [ L ] = ∂ L ∂ a j [ L ] σ ′ ( z j [ L ] ) \delta_{j}^{[L]}=\frac{\partial L}{\partial a_{j}^{[L]}} \sigma^{\prime}\left(z_{j}^{[L]}\right) δj[L]=∂aj[L]∂Lσ′(zj[L])
隐藏层误差
δ j [ l ] = ∑ k w k j [ l + 1 ] δ k [ l + 1 ] σ ′ ( z j [ l ] ) \begin{array}{c} \delta_{j}^{[l]}=\sum_{k} w_{k j}^{[l+1]} \delta_{k}^{[l+1]} \sigma^{\prime}\left(z_{j}^{[l]}\right) \end{array} δj[l]=∑kwkj[l+1]δk[l+1]σ′(zj[l])
推导
z k [ l + 1 ] = ∑ j w k j [ l + 1 ] a j [ l ] + b k [ l + 1 ] = ∑ j w k j [ l + 1 ] σ ( z j [ l ] ) + b k [ l + 1 ] z_{k}^{[l+1]}=\sum_{j} w_{k j}^{[l+1]} a_{j}^{[l]}+b_{k}^{[l+1]}=\sum_{j} w_{k j}^{[l+1]} \sigma\left(z_{j}^{[l]}\right)+b_{k}^{[l+1]} zk[l+1]=∑jwkj[l+1]aj[l]+bk[l+1]=∑jwkj[l+1]σ(zj[l])+bk[l+1]
对 z j [ l ] z_{j}^{[l]} zj[l] 求偏导
∂ z k [ l + 1 ] ∂ z j [ l ] = w k j [ l + 1 ] σ ′ ( z j [ l ] ) \frac{\partial z_{k}^{[l+1]}}{\partial z_{j}^{[l]}}=w_{k j}^{[l+1]} \sigma^{\prime}\left(z_{j}^{[l]}\right) ∂zj[l]∂zk[l+1]=wkj[l+1]σ′(zj[l])
根据链式法则
δ j [ l ] = ∂ L ∂ z j [ l ] = ∂ L ∂ z k [ l + 1 ] ∂ z k [ l + 1 ] ∂ z j [ l ] = ∑ k w k j [ l + 1 ] δ k [ l + 1 ] σ ′ ( z j [ l ] ) \delta_{j}^{[l]}=\frac{\partial L}{\partial z_{j}^{[l]}}=\frac{\partial L}{\partial z_{k}^{[l+1]}}\frac{\partial z_{k}^{[l+1]}}{\partial z_{j}^{[l]}}=\sum_{k} w_{k j}^{[l+1]} \delta_{k}^{[l+1]} \sigma^{\prime}\left(z_{j}^{[l]}\right) δj[l]=∂zj[l]∂L=∂zk[l+1]∂L∂zj[l]∂zk[l+1]=∑kwkj[l+1]δk[l+1]σ′(zj[l])
参数变化率
∂ L ∂ b j [ l ] = δ j [ l ] ∂ L ∂ w j k [ l ] = a k [ l − 1 ] δ j [ l ] \begin{array}{c} \frac{\partial L}{\partial b_{j}^{[l]}}=\delta_{j}^{[l]} \\ \frac{\partial L}{\partial w_{j k}^{[l]}}=a_{k}^{[l-1]} \delta_{j}^{[l]} \end{array} ∂bj[l]∂L=δj[l]∂wjk[l]∂L=ak[l−1]δj[l]
推导
z j [ l ] = ∑ k w j k [ l ] a k [ l − 1 ] + b k [ l ] z_{j}^{[l]}=\sum_{k} w_{j k}^{[l]} a_{k}^{[l-1]}+b_{k}^{[l]} zj[l]=∑kwjk[l]ak[l−1]+bk[l]
L 对 b j [ l ] b_{j}^{[l]} bj[l] 求偏导,根据链式法则得到
∂ L ∂ b j [ l ] = ∂ L ∂ z j [ l ] ∂ z j [ l ] b j [ l ] = ∂ L ∂ z j [ l ] ∗ 1 = δ j [ l ] \frac{\partial L}{\partial b_{j}^{[l]}}=\frac{\partial L}{\partial z_{j}^{[l]}} \frac{\partial z_{j}^{[l]}}{b_{j}^{[l]}}= \frac{\partial L}{\partial z_{j}^{[l]}} * 1 = \delta_{j}^{[l]} ∂bj[l]∂L=∂zj[l]∂Lbj[l]∂zj[l]=∂zj[l]∂L∗1=δj[l]
L 对 w j k [ l ] w_{j k}^{[l]} wjk[l] 求偏导,根据链式法则得到
∂ L ∂ w j k [ l ] = ∂ L ∂ z j [ l ] ∂ z j [ l ] w j k [ l ] = a k [ l − 1 ] δ j [ l ] \frac{\partial L}{\partial w_{j k}^{[l]}}=\frac{\partial L}{\partial z_{j}^{[l]}} \frac{\partial z_{j}^{[l]}}{w_{j k}^{[l]}}=a_{k}^{[l-1]} \delta_{j}^{[l]} ∂wjk[l]∂L=∂zj[l]∂Lwjk[l]∂zj[l]=ak[l−1]δj[l]
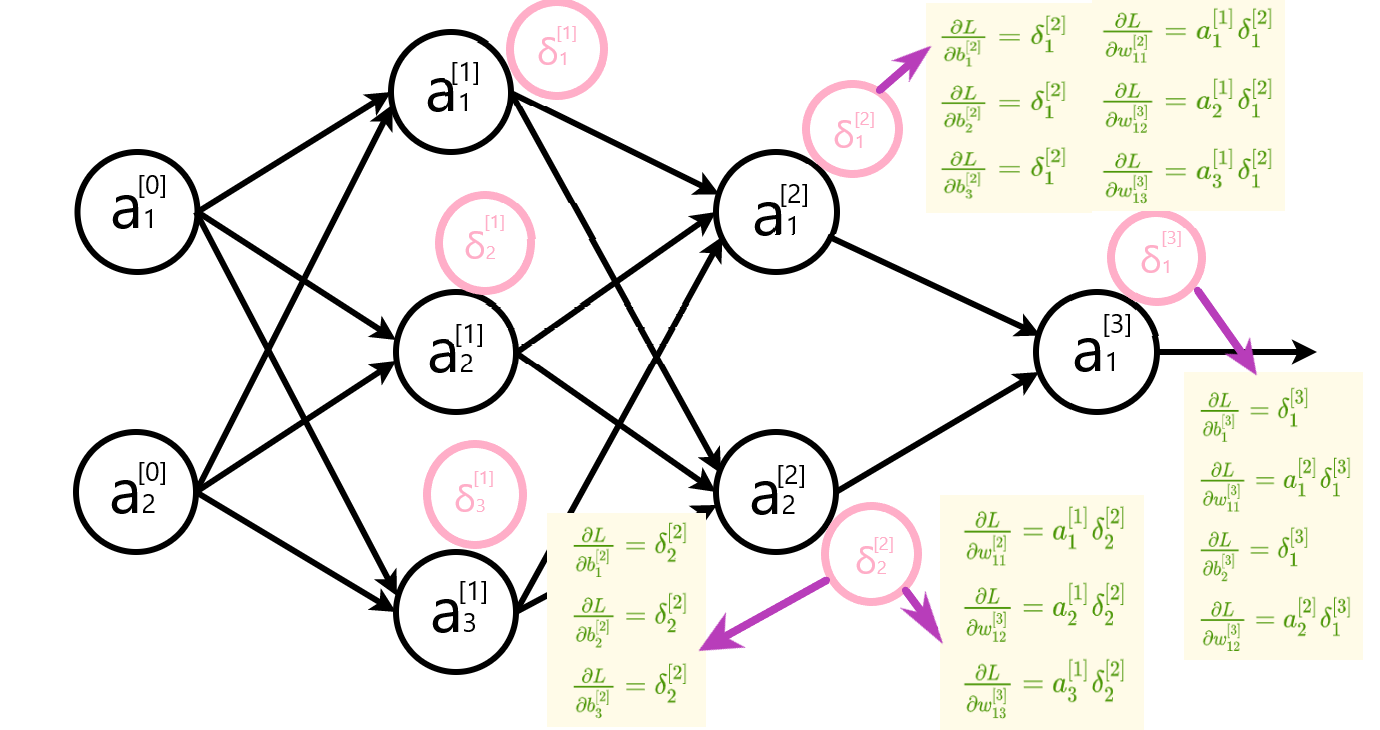
参数更新
根据梯度下降法原理,朝着梯度的反方向更新参数
b j [ l ] ← b j [ l ] − α ∂ L ∂ b j [ l ] w j k [ l ] ← w j k [ l ] − α ∂ L ∂ w j k [ l ] \begin{array}{c} b_{j}^{[l]} \leftarrow b_{j}^{[l]}-\alpha \frac{\partial L}{\partial b_{j}^{[l]}} \\ w_{j k}^{[l]} \leftarrow w_{j k}^{[l]}-\alpha \frac{\partial L}{\partial w_{j k}^{[l]}} \end{array} bj[l]←bj[l]−α∂bj[l]∂Lwjk[l]←wjk[l]−α∂wjk[l]∂L
3.代码实现
3.1过程解释
本次代码实现决定考虑四层神经网络,即含有两个隐层。其中,有三个输入单元,一个输出单元,第一层隐层含有四个节点,第二层隐层含有二个节点。
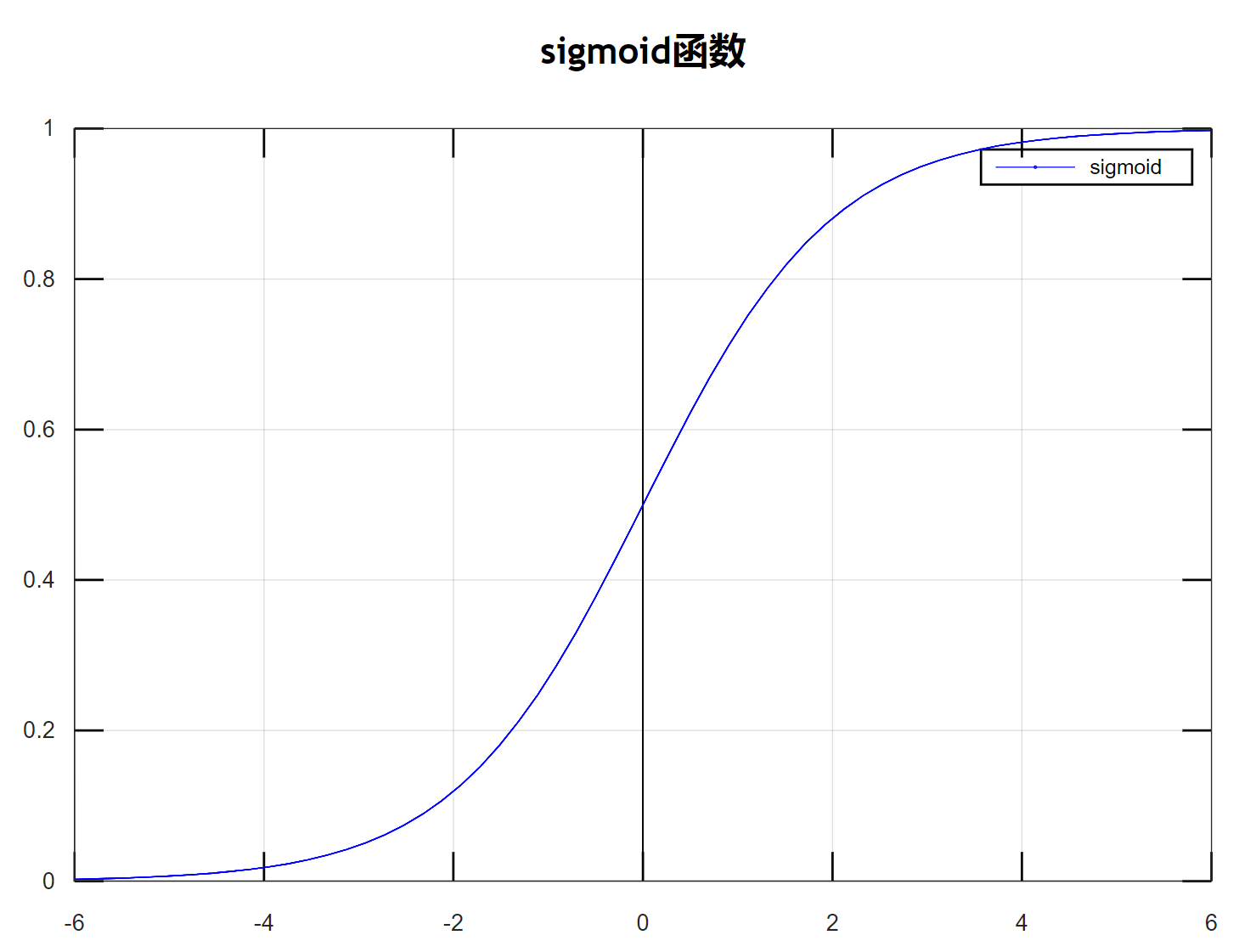
并且,激励函数采用sigmoid函数。
3.1.1导入库
import numpy as np
3.1.2定义sigmoid函数
def sigmoid(x, deriv = False):
if(deriv == True):
return x*(1-x)
else:
return 1/(1+np.exp(-x))
当deriv为默认值False时,进行sigmoid函数的运算;
当deriv为True时,对函数求导运算。(其中,求导运算时输入的x值应为函数值而非自变量)
3.1.3导入数据集
#input dataset
X = np.array([[0,0,1],
[0,1,1],
[1,0,1],
[1,1,1]])
#output dataset
y = np.array([[0,1,1,0]]).T
3.1.4初始化权重和偏倚
权重weight01表示从第0层(即输入层)到第1层(第一隐层)的权重矩阵;
偏倚bias1表示第1层(第一隐层)的偏倚矩阵。
#初始化权重
weight01 = 2*np.random.random((3,4)) - 1
weight12 = 2*np.random.random((4,2)) - 1
weight23 = 2*np.random.random((2,1)) - 1
#初始化偏倚
b1 = 2*np.random.random((1,4)) - 1
b2 = 2*np.random.random((1,2)) - 1
b3 = 2*np.random.random((1,1)) - 1
bias1=np.array([b1[0],b1[0],b1[0],b1[0]])
bias2=np.array([b2[0],b2[0],b2[0],b2[0]])
bias3=np.array([b3[0],b3[0],b3[0],b3[0]])
3.1.5开始训练
I0表示第0层输入,O0表示第0层输出。
for j in range(60000):
I0 = X
O0=I0
I1=np.dot(O0,weight01)+bias1
O1=sigmoid(I1)
I2=np.dot(O1,weight12)+bias2
O2=sigmoid(I2)
I3=np.dot(O2,weight23)+bias3
O3=sigmoid(I3)
f3_error = y-O3
f3_delta = f3_error*sigmoid(O3,deriv = True)
f2_error = f3_delta.dot(weight23.T)
f2_delta = f2_error*sigmoid(O2,deriv = True)
f1_error = f2_delta.dot(weight12.T)
f1_delta = f1_error*sigmoid(O1,deriv = True)
weight23 += O2.T.dot(f3_delta) #调整权重
weight12 += O1.T.dot(f2_delta)
weight01 += O0.T.dot(f1_delta)
bias3 += f3_delta #调整偏倚
bias2 += f2_delta
bias1 += f1_delta
3.2完整代码
import numpy as np
#定义sigmoid函数
def sigmoid(x, deriv = False):
if(deriv == True):
return x*(1-x)
else:
return 1/(1+np.exp(-x))
#input dataset
X = np.array([[0,0,1],
[0,1,1],
[1,0,1],
[1,1,1]])
#output dataset
y = np.array([[0,1,1,0]]).T
#初始化权重
weight01 = 2*np.random.random((3,4)) - 1
weight12 = 2*np.random.random((4,2)) - 1
weight23 = 2*np.random.random((2,1)) - 1
#初始化偏倚
b1 = 2*np.random.random((1,4)) - 1
b2 = 2*np.random.random((1,2)) - 1
b3 = 2*np.random.random((1,1)) - 1
bias1=np.array([b1[0],b1[0],b1[0],b1[0]])
bias2=np.array([b2[0],b2[0],b2[0],b2[0]])
bias3=np.array([b3[0],b3[0],b3[0],b3[0]])
#开始训练
for j in range(60000):
I0 = X
O0=I0
I1=np.dot(O0,weight01)+bias1
O1=sigmoid(I1)
I2=np.dot(O1,weight12)+bias2
O2=sigmoid(I2)
I3=np.dot(O2,weight23)+bias3
O3=sigmoid(I3)
f3_error = y-O3
if(j%10000) == 0:
print ("Error:"+str(np.mean(f3_error)))
f3_delta = f3_error*sigmoid(O3,deriv = True)
f2_error = f3_delta.dot(weight23.T)
f2_delta = f2_error*sigmoid(O2,deriv = True)
f1_error = f2_delta.dot(weight12.T)
f1_delta = f1_error*sigmoid(O1,deriv = True)
weight23 += O2.T.dot(f3_delta) #调整权重
weight12 += O1.T.dot(f2_delta)
weight01 += O0.T.dot(f1_delta)
bias3 += f3_delta #调整偏倚
bias2 += f2_delta
bias1 += f1_delta
print ("outout after Training:")
print (O3)
3.3预测结果
迭代次数为1000时,预测结果为:

迭代次数为5000时,预测结果为:

迭代次数为10000时,预测结果为:

迭代次数为60000时,预测结果为:

可见,已经十分逼近预期结果。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/194908.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
