大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
1.首先我们需要先导入所需要的包,没有的话可以【 pip install ~】 来获取
import requests
from lxml import etree2.接下来我们要进行UA伪装,伪装的目的就是把电脑伪装成人 因为很多wangzahn都有反扒机制,不进行伪装的话根本就无法进行爬取信
#进行ua伪装
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}3.准备工作已经完成,告诉我们要访问的URL(告诉电脑去哪里执行以下的代码)
URL = 我们所常说的网址
#指定url
url = '网址'4.有了UA伪装以及URL,接下来我们就要去访问目标网站,把网站源代码给拿下来
#发起请求
resposne = requests.get(url=url,headers=headers)5.因为网站源码拿下来的时候出现了乱码,所以对乱码进行处理并把无乱码网站源码赋值给data
#获取源码后处理乱码
resposne.encoding='gbk'
data = resposne.text然后就是开始进行数据解析了
6.将抓取下来的网站源码数据加载etree对象中
tree = etree.HTML(data)7.然后将使用xpath()函数结合表达式进行标签定位,提取指定内容
我们这里是只要存储图片的<li></li>区域就可以了,有不懂的可以去查一下 很简单的
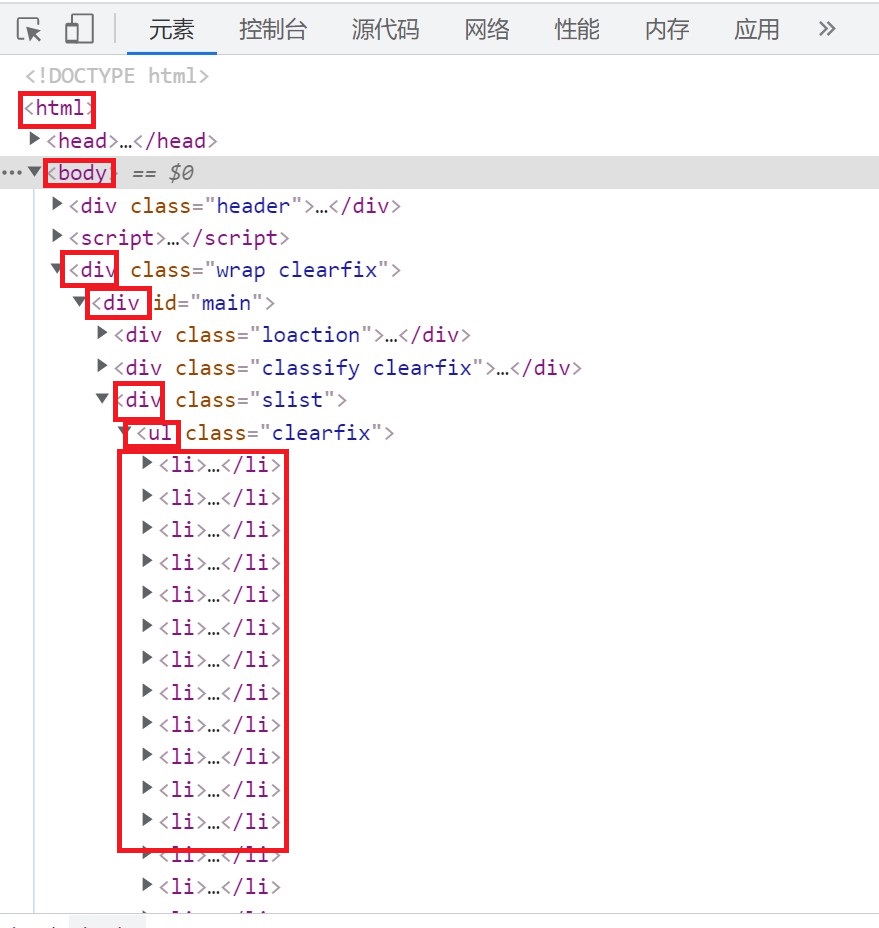

li_list = tree.xpath('/html/body/div[2]/div[1]/div[3]/ul/li')1.属性定位
定位div中属性名为href,属性值为‘www.baidu.com’的div标签: @属性名=属性值
/html/body/div[href=’www.baidu.com’] href为属性名 ‘www.baidu.com’为属性值2. 索引定位
在href值a的div标签下有很多的li标签,想要定位到第二个li标签,li标签后面用中括号加索引值(这里的索引值是从1开始的)
/html/body/div[href=’a’]li[2]3. 取文本内容
/text() 获取标签下直系的标签内容
//text() 获取标签中所有的文本内容
string() 获取标签中所有的文本内容
8.然后就是对该区域进行遍历
#进行遍历
for li in li_list:
#获取图片名称以及图片后缀 .jpg
name = li.xpath('./a/b/text()')[0] + '.jpg'
#获取图片的存储位置,别忘了加上前面的域名(不知道叫啥,前缀)
href = 'https://pic.netbian.com/' + li.xpath('./a/img/@src')[0]
#这个是再次模仿人去获取图片信息,这次的url是单纯图片存储位置
img_response = requests.get(url=href,headers=headers)
#这个是对图片信息进行编译
img_data = img_response.content9.经过遍历循环每个图片信息都可以获取,接下来就是进行存储
#上面讲解
for li in li_list:
name = li.xpath('./a/b/text()')[0] + '.jpg'
href = 'https://pic.netbian.com/' + li.xpath('./a/img/@src')[0]
img_response = requests.get(url=href,headers=headers)
img_data = img_response.content
# print(img_data)
#持久化存储
#定义存储位置,我这里是当级目录名字是拼音tupian
#注意:tupian后的斜杠一定要添加,这样才可以放入里面
img_path = './tupian/' + name
#定义打开方式,存储位置 'wb'是因为图片信心为二进制,所以需要加b,b是二进制英语首字母
with open(img_path,'wb') as f:
f.write(img_data)
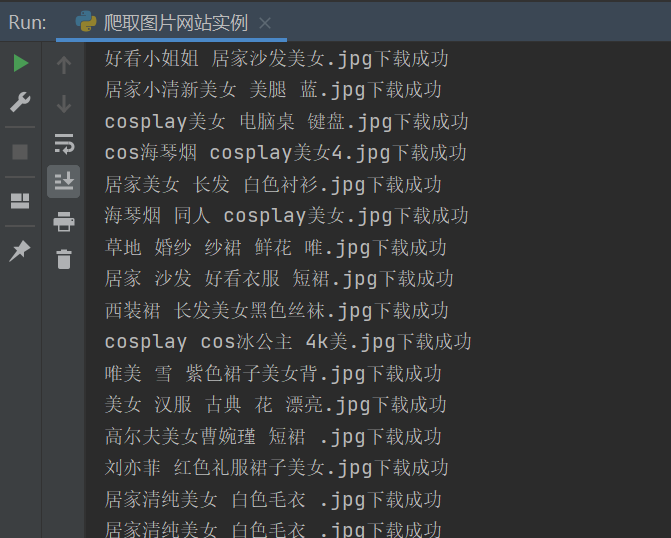
print(name + '下载成功')10.然后就是点击运行等待就可以了
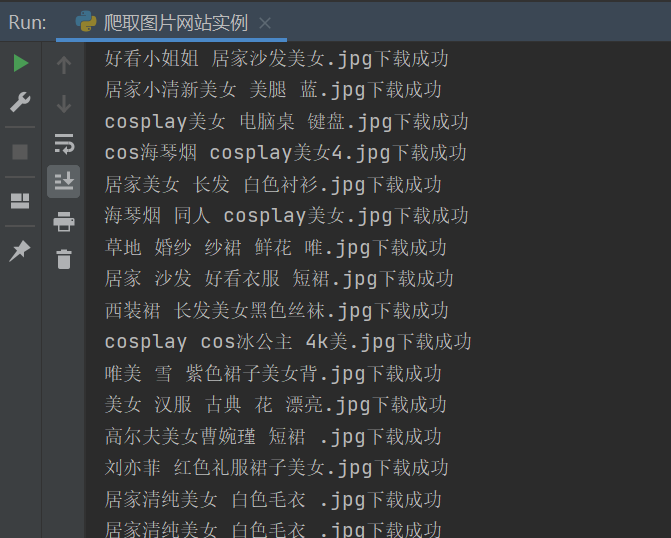
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/194879.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
