大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
CVPR2022弱监督语义分割:https://blog.csdn.net/Sierkinhane/article/details/126228039
开源仓库:https://github.com/CVI-SZU/CLIMS
简单单人跟踪:https://github.com/Sierkinhane/human_tracker(基于目标检测与特征映射算法)
演示视频:https://www.bilibili.com/video/av44360925
斯坦福机器学习课程资料以及算法实现吴恩达-斯坦福CS229机器学习课程资料与算法的Python实现_Sierkinhane的博客-CSDN博客
代码仓库:GitHub – Sierkinhane/CS229-ML-Implementation: Implementation of algorithms introduced in CS229.
在六七月份参加了一个比赛,做的项目是提取图片中的文字信息,首先是接触了一些文本检测算法(如CTPN,East),后研究了文本识别算法(我认为较好的是CRNN)。代码实现是参考算法提出者的pytorch,python3版本的crnn实现。因为python版本的迭代,导致代码重使用比较难,其中涉及到ctc,python编码,中文数据集,如何将模型finetune到自己的应用场景上种种问题。实现的深度学习框架是pytorch,虽然TensorFlow也可以,但是比较多坑。其实是什么框架实现的都没关系,现在语法都是比较简单,看懂不难!
因为自己已经踩了很多坑,也填好了这些坑,就将自己填好的项目贡献给大家!
GitHub – Sierkinhane/CRNN_Chinese_Characters_Rec: (CRNN) Chinese Characters Recognition. 代码地址
这次分享的是文本识别算法CRNN,具体的内容我就不涉及了,这篇文章主要是做算法代码的实现(参考原作者),建议大家研读算法一定要看作者发的Paper! CRNN论文地址:http://arxiv.org/abs/1507.05717(作者是华中科技大学的老师)
先放一些效果图,利用360万的中文数据训练集,最后可以finetune到97.7%的验证准确率,训练好的模型在train_models文件夹


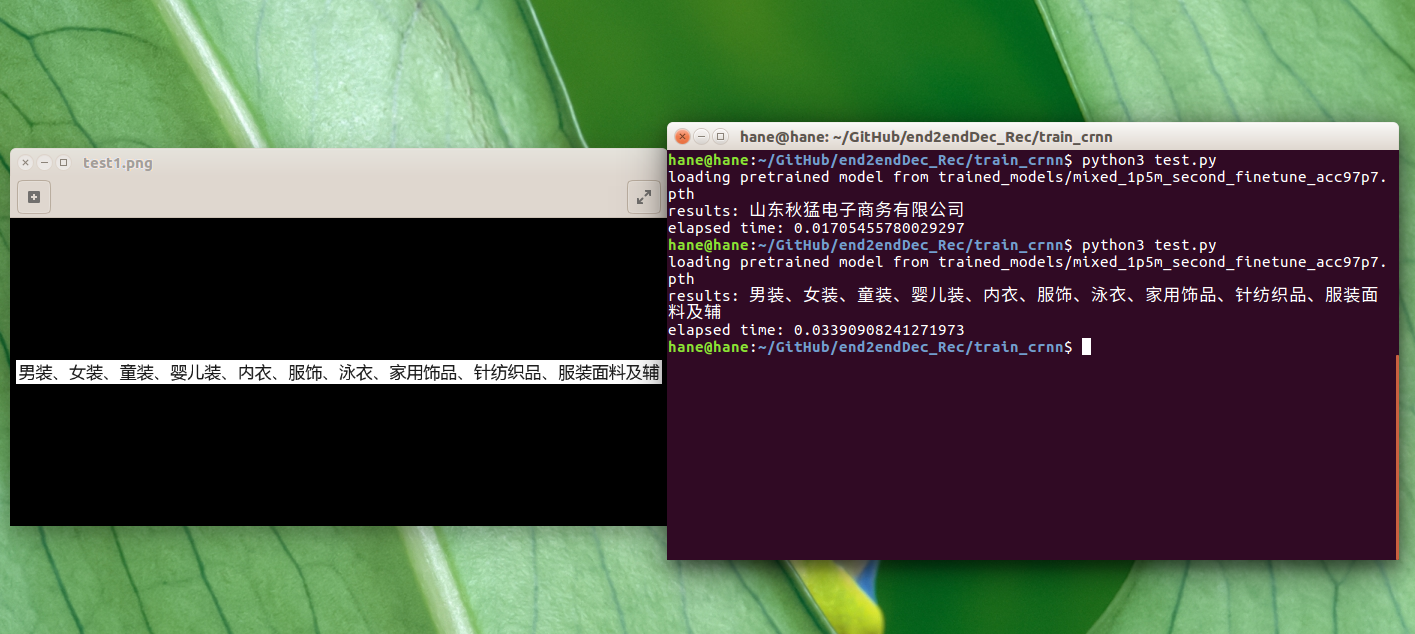

第一、二张图片是最近修改的一个demo,第三、四张图是CTPN算法和CRNN的结合,可以将图片上的任何文字信息提取。因为CTPN要求的环境比较复杂,所以这次只放出CRNN的代码,因为CRNN实现环境比较简单。
现在开始介绍代码:
代码的实现必须是Linux环境(因为涉及到warp-ctc的安装,最好是Ubuntu16.04,能跳的坑我基本都填了)
1. Warp-ctc安装
首先得安装warp-ctc GitHub – SeanNaren/warp-ctc: Pytorch Bindings for warp-ctc,这是pytorch版本的ctc实现(计算序列loss,具体看论文),安装方法按照作者的步骤即可,如果遇到问题可以私聊我。我是在Ubuntu16.04安装的,并没有太大问题,但是在17.04就遇到很多问题,所以最好用Ubuntu16.04作为代码实现环境。
现在只需将pytorch更新至1.1.0,使用其自带的ctcloss即可。
2. 测试
安装好ctc后,直接运行终端输入 python3 test.py 试下效果,测试图片在test_images文件夹下。
3. 训练
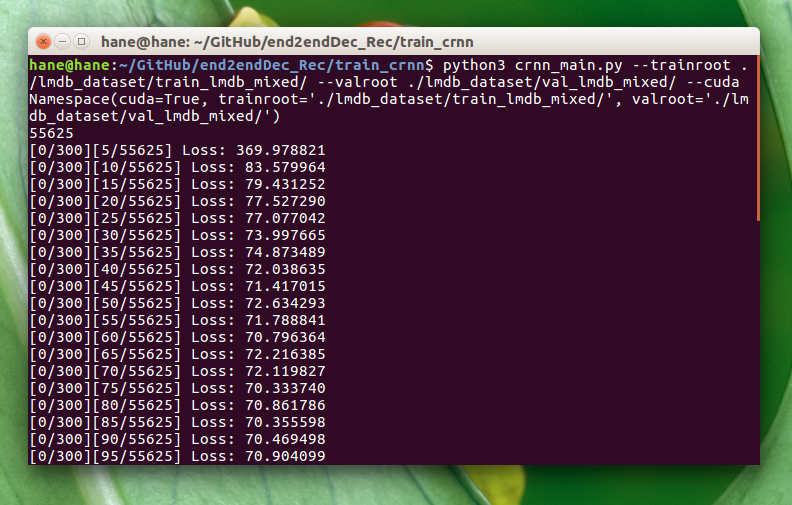
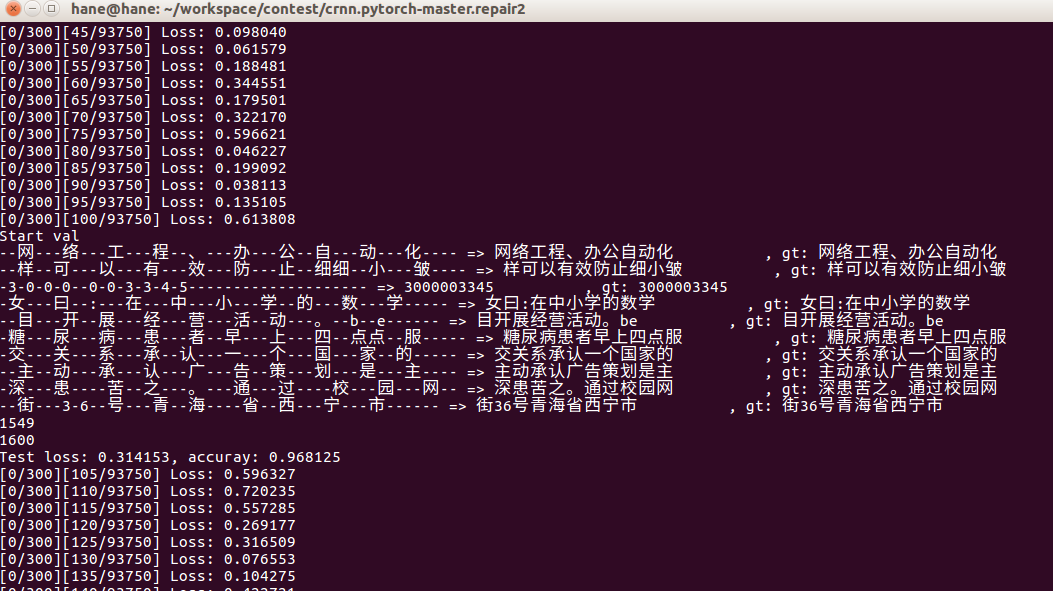
正确的训练效果如图。
训练之前首先制作数据集,因为360万的中文数据集制作成lmdb格式的数据有十几G,就没直接放到Github中。
先下载360万中文数据集:Synthetic Chinese String Dataset .rar_免费高速下载|百度网盘-分享无限制
对于数据集我想说明一下,在文字识别领域有比较多的识别场景,例如场景文本识别,比较正规的图片信息识别,这些不同的应用场景需要对应不同的数据集训练,这次我自己应用到的场景比较正规的字体识别,所以这个训练集不一定能够用到所有场景,但也确实提供了一个不错数据集资源!还有就是训练集最好是具有语义信息,如果只是将文字随机的组合生成图片作为训练集,模型收敛会更慢并且准确率受限!
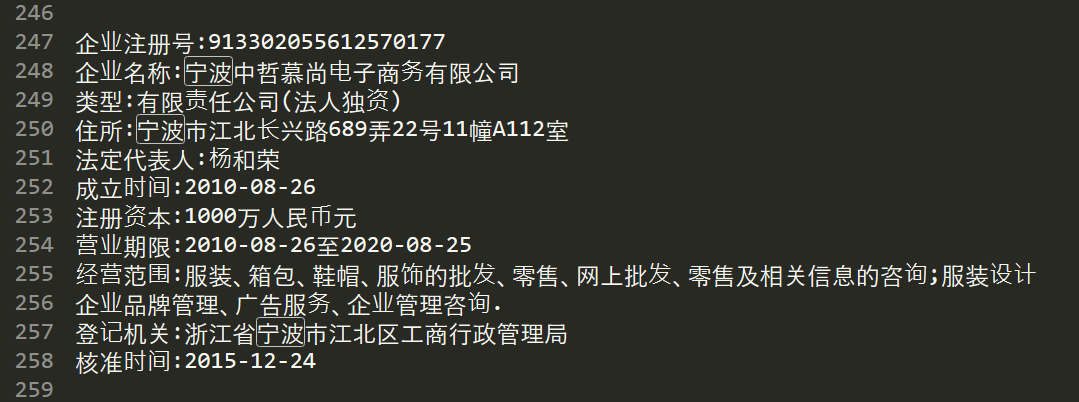
下图是部分训练集
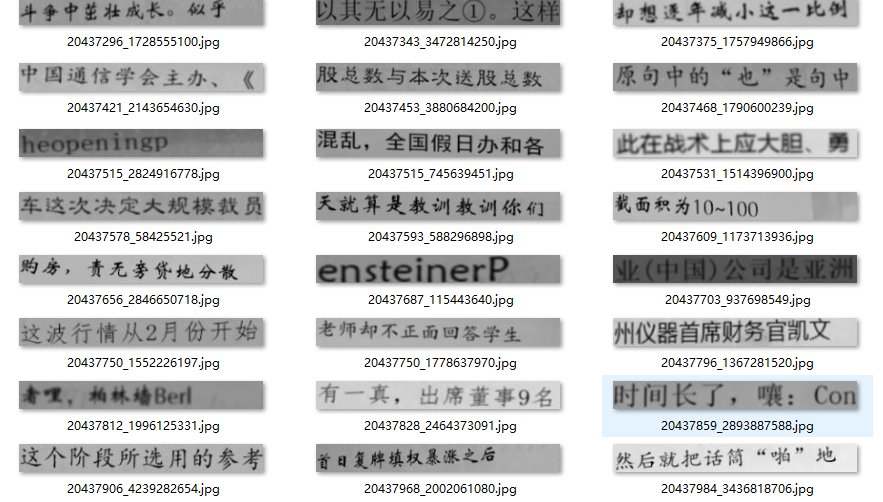
(这个数据是在Github中找到的,暂时没找到他的地址,很感谢作者的奉献!)
数据集是随机选取定长的字数,经过模糊、倾斜、颜色变化等操作之后生成的,比较具有一般性,能很好地提升模型的Robust。
下载好数据集之后如果解压出错,不完整,可以用好压进行修复。
修改crnn_main_v2.py中的图片路径和标签路径,运行python crnn_main_v2.py即可
接下来是制作lmdb格式的数据。
图片与之对应的标签我链接:https://pan.baidu.com/s/1jfAKQVjD-SMJSffOwGhh8A 密码:u7bo,只需要将下载好的数据集放到lmdb文件中,根据情况修改to_lmdb.py中的文件名 运行该py程序就可以制作lmdb格式的数据!(需要用Python2来运行to_lmdb.py)
制作好数据集之后将它放到lmdb_dataset文件夹中调出终端:
python3 crnn_main.py –train_root 训练数据集路径 –val_root 验证集路径 –cuda (如果有cuda加速可选)
大概流程就是这样了,最主要的还是自己看待自己琢磨!
(不定长识别是将训练集图片的放缩feed到神经网络中的尺寸应用到测试中,test.py已经标注!)
(如果有帮助到你,可以在Github给我个star!)
(下一篇:斯坦福机器学习课程资料以及算法实现吴恩达-斯坦福CS229机器学习课程资料与算法的Python实现_Sierkinhane的博客-CSDN博客)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/194746.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
