大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
toDom方法用来将html标签字符串转化成DOM节点。1.7之后toDom方法被分配到了dom-construct模块。
require(["dojo/dom-construct"], function(domConstruct){ // Take a string and turn it into a DOM node var node = domConstruct.toDom("<div>I'm a Node</div>"); });
dom操作是每位想要有所建树的前端开发者必须要跨过的槛,类库虽好常用有依赖,对于类库里常用的函数,我们要做到知其然知其所以然。toDOM将html转换为dom节点,我能想到的是两种方法:
- 利用正则表达式,依次匹配出所有标签;首先需要一个正确的正则,其次需要保证正确的节点关系
- 利用dom的api来做,这个我们可以创建一个元素使用innerHTML来自动转换
- innerHTML取值时会把所有的子元素作为文本输出;
- 设值时,会先将字符串转化为dom节点,然后用dom节点替换元素中的子元素;此时如果字符串中有特殊标签开头,比如tbody、thead、tfoot、tr、td、th、caption、colgroup、col等;对于必须存在包装元素的标签,浏览器不会为这些标签补全包装元素,或者统一作为文本处理,或者忽略这些标签
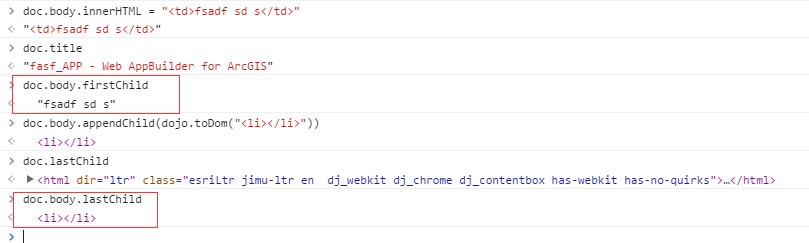
 那我们就有必要对html标签进行一些修正,主要是针对必须存在于包装元素的标签;这些标签作为innerHTML赋值会被浏览器忽略,但是如果作为dom节点直接挂载到dom树中,浏览器会为他们自动创建隐含的包装元素。所以在遇到这些标签开头的html片段时,我们需要手动补全缺失的包装元素。
那我们就有必要对html标签进行一些修正,主要是针对必须存在于包装元素的标签;这些标签作为innerHTML赋值会被浏览器忽略,但是如果作为dom节点直接挂载到dom树中,浏览器会为他们自动创建隐含的包装元素。所以在遇到这些标签开头的html片段时,我们需要手动补全缺失的包装元素。
下面我们来看一下dom-construct模块是怎么处理的。
找出所有待补全的元素:tbody、thead、tfoot、tr、td、th、caption、colgroup、col、legend、li;dojo中使用如下结构将某些缺失的标签管理起来:
var tagWrap = { option: ["select"], tbody: ["table"], thead: ["table"], tfoot: ["table"], tr: ["table", "tbody"], td: ["table", "tbody", "tr"], th: ["table", "thead", "tr"], legend: ["fieldset"], caption: ["table"], colgroup: ["table"], col: ["table", "colgroup"], li: ["ul"] },
经过下面这一步处理后,tagWrap中的每一项中多了两个属性, eg:tagWrap.tr.pre = “<table><tbody>”和tagWrap.tr.post = “</tbody></table>”;
for(var param in tagWrap){ if(tagWrap.hasOwnProperty(param)){ var tw = tagWrap[param]; tw.pre = param == "option" ? '<select multiple="multiple">' : "<" + tw.join("><") + ">"; tw.post = "</" + tw.reverse().join("></") + ">"; } }
1、innerHTML方式需要一个额外的元素,作为临时的容器,所以利用一下变量来管理这个额外的元素:
var reTag = /<\s*([\w\:]+)/,//用来判断字符串参数中是否含有html标签 masterNode = {},//作为仓库来管理临时容器 masterNum = 0,//z这两个变量用来标识临时容器 masterName = "__" + dojo._scopeName + "ToDomId";
2、toDom方法中,首先创建一个临时容器,是一个div元素:
doc = doc || win.doc; var masterId = doc[masterName]; if(!masterId){ doc[masterName] = masterId = ++masterNum + ""; masterNode[masterId] = doc.createElement("div"); }
3、然后判断frag中是否含有html标签,如果含有html标签而且需要我们补全包装元素,则利用上面生成的pre和post补全标签后传递给master这个容器的innerHTML,这一步完成后找到我们传入的html标签对应的dom树,赋值给master;如果不需要包装,直接赋值给master.innerHTML
var match = frag.match(reTag), tag = match ? match[1].toLowerCase() : "", master = masterNode[masterId], wrap, i, fc, df; if(match && tagWrap[tag]){ wrap = tagWrap[tag]; master.innerHTML = wrap.pre + frag + wrap.post; for(i = wrap.length; i; --i){ master = master.firstChild; } }else{ master.innerHTML = frag; }
这里仅是简单的认为如果正则匹配则进行包装处理,按照我的理解,正则的写法应该为:/^<\s*([\w\:]+)/,原因看下面例子:
第一个表达式子所以报错,就是因为“adffd”这部分在dom中被作为文本节点,文本节点并没有子节点。更改了正则之后,如果不是html标签做开头则统一作为文本节点添加到dom中去。
4、将html标签转化成dom后,如果仅有一个元素则返回这个元素,否则将转化后的元素,放入到文档片段中。
if(master.childNodes.length == 1){ return master.removeChild(master.firstChild); // DOMNode } df = doc.createDocumentFragment(); while((fc = master.firstChild)){ // intentional assignment df.appendChild(fc); } return df; // DocumentFragment
参考标准的描述,DocumentFragment是一个轻量级的文档对象,能够提取部分文档的树或创建一个新的文档片段。可以通过appendChild()或insertBefore()将文档片段中内容添加到文档中。在将文档片段作为参数传递给这两个方法时,实际上只会将文档片段的所有子节点添加到相应的位置上;文档片段本身永远不会称为文档树的一部分
利用innerHTML标签创建dom元素,并自动补齐缺失的标签,这就是dom-construct模块针对toDOM方法的实现思路。


1 exports.toDom = function toDom(frag, doc){ 2 // summary: 3 // instantiates an HTML fragment returning the corresponding DOM. 4 // frag: String 5 // the HTML fragment 6 // doc: DocumentNode? 7 // optional document to use when creating DOM nodes, defaults to 8 // dojo/_base/window.doc if not specified. 9 // returns: 10 // Document fragment, unless it's a single node in which case it returns the node itself 11 // example: 12 // Create a table row: 13 // | require(["dojo/dom-construct"], function(domConstruct){ 14 // | var tr = domConstruct.toDom("<tr><td>First!</td></tr>"); 15 // | }); 16 17 doc = doc || win.doc; 18 var masterId = doc[masterName]; 19 if(!masterId){ 20 doc[masterName] = masterId = ++masterNum + ""; 21 masterNode[masterId] = doc.createElement("div"); 22 } 23 24 if(has("ie") <= 8){ 25 if(!doc.__dojo_html5_tested && doc.body){ 26 html5domfix(doc); 27 } 28 } 29 30 // make sure the frag is a string. 31 frag += ""; 32 33 // find the starting tag, and get node wrapper 34 var match = frag.match(reTag), 35 tag = match ? match[1].toLowerCase() : "", 36 master = masterNode[masterId], 37 wrap, i, fc, df; 38 if(match && tagWrap[tag]){ 39 wrap = tagWrap[tag]; 40 master.innerHTML = wrap.pre + frag + wrap.post; 41 for(i = wrap.length; i; --i){ 42 master = master.firstChild; 43 } 44 }else{ 45 master.innerHTML = frag; 46 } 47 48 // one node shortcut => return the node itself 49 if(master.childNodes.length == 1){ 50 return master.removeChild(master.firstChild); // DOMNode 51 } 52 53 // return multiple nodes as a document fragment 54 df = doc.createDocumentFragment(); 55 while((fc = master.firstChild)){ // intentional assignment 56 df.appendChild(fc); 57 } 58 return df; // DocumentFragment 59 };
完整代码
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/194637.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
