大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
目录
1、遗传算法流程
遗传算法的运算流程如下图所示:
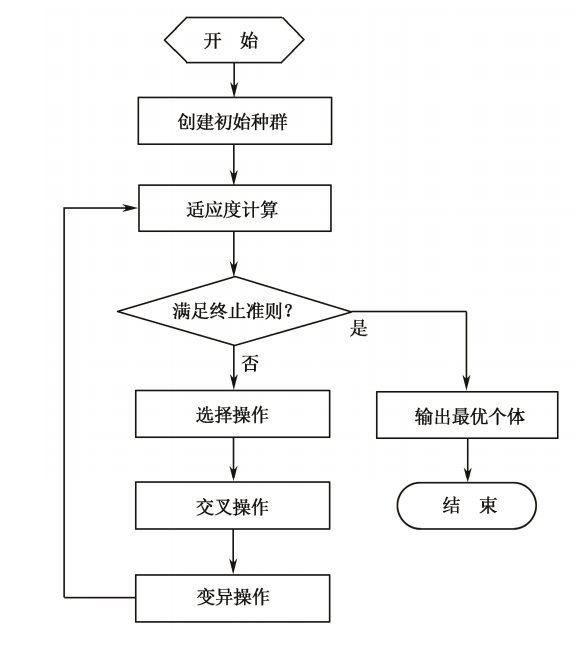

具体步骤如下:
(1)初始化。设置进化代数计数器 \(g=0\),设置最大进化代数 \(G\),随机生成 \(NP\) 个个体作为初始群体 \(P(0)\)。
(2)个体评价。计算群体 \(P(t)\)中各个个体的适应度。
(3)选择运算。将选择算子作用于群体,根据个体的适应度,按照一定的规则或方法,选择一些优良个体遗传到下一代群体。
(4)交叉运算。将交叉算子作用于群体,对选中的成对个体,以某一概率交换它们之间的部分染色体,产生新的个体。
(5)变异运算。将变异算子作用于群体,对选中的个体,以某一概率改变某 一个或某一些基因值为其他的等位基因。群体 \(P(t)\)经过选择、交叉和变异运算之 后得到下一代群体 \(P(t+1)\)。计算其适应度值,并根据适应度值进行排序,准备进 行下一次遗传操作。
(6)终止条件判断:若 \(g≤G\),则 \(g = g+1\),转到步骤(2);若 \(g > G\),则此 进化过程中所得到的具有最大适应度的个体作为最优解输出,终止计算。
2、关键参数说明
(1)群体规模 \(NP\)
群体规模将影响遗传优化的最终结果以及遗传算法的执行效率。当群体规模 \(NP\) 太小时,遗传优化性能一般不会太好。采用较大的群体规模可以减小遗传算法陷入局部最优解的机会,但较大的群体规模意味着计算复杂度较高。一般 \(NP\) 取 \(10~200\)。
(2)交叉概率 \(P_c\)
交叉概率 \(P_c\)控制着交叉操作被使用的频度。较大的交叉概率可以增强遗传算法开辟新的搜索区域的能力,但高性能的模式遭到破坏的可能性增大;若交叉概率太低,遗传算法搜索可能陷入迟钝状态。一般 \(P_c\)取 \(0.25~1.00\)。
(3)变异概率 \(P_m\)
变异在遗传算法中属于辅助性的搜索操作,它的主要目的是保持群体的多样性。一般低频度的变异可防止群体中重要基因的可能丢失,高频度的变异将使遗传算法趋于纯粹的随机搜索。通常 \(P_m\)取 \(0.001~0.1\)。
(4)进化代数 \(G\)
终止进化代数 \(G\) 是表示遗传算法运行结束条件的一个参数,它表示遗传算法运行到指定的进化代数之后就停止运行,并将当前群体中的最佳个体作为所求问题的最优解输出。一般视具体问题而定,\(G\) 的取值可在 \(100~1000\) 之间。
3、MATLAB仿真实例
3.1 遗传算法求解一元函数的极值
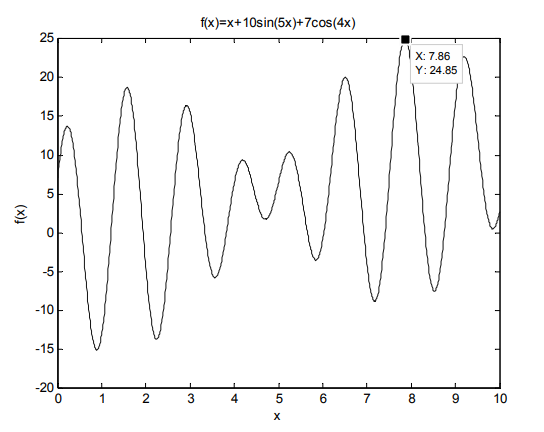
例 2.1 用标准遗传算法求函数\(f (x) = x+10\sin(5x)+7\cos(4x)\) 的最大值,其中 \(x\) 的取值范围为\([0,10]\)。这是一个有多个局部极值的函数,其函数值图形如下图所示。
解:仿真过程如下:
(1)初始化种群数目为 \(NP = 50\),染色体二进制编码长度为 \(L = 20\),最大进化代数为 \(G = 100\),交叉概率 \(P_c = 0.8\),变异概率 \(P_m = 0.1\)。
(2)产生初始种群,将二进制编码转换成十进制,计算个体适应度值,并进行归一化;采用基于轮盘赌的选择操作、基于概率的交叉和变异操作,产生新的种群,并把历代的最优个体保留在新种群中,进行下一步遗传操作。
(3)判断是否满足终止条件:若满足,则结束搜索过程,输出优化值;若不满足,则继续进行迭代优化。
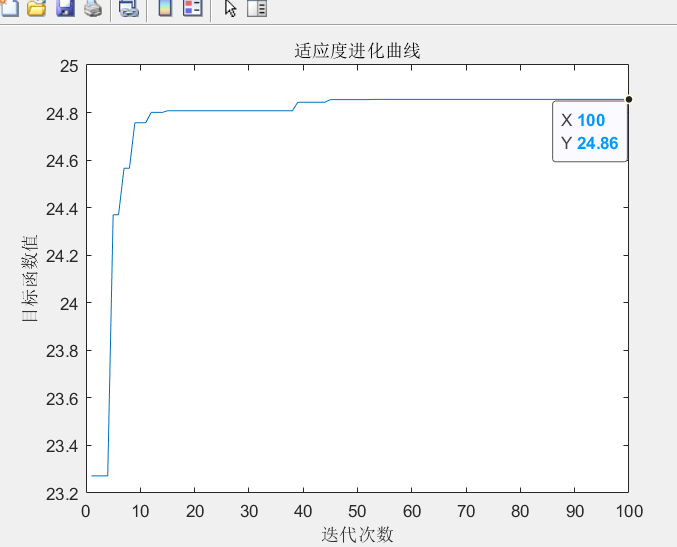
优化结束后,其适应度进化曲线如下图所示,优化结果为 \(x = 7.8567\),函数 \(f(x)\)的最大值为 \(24.86\)。
MATLAB 源程序如下:
%%%%%%%%%%%%%%%标准遗传算法求函数极值%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%初始化参数%%%%%%%%%%%%%%%%%%
clear all; %清除所有变量
close all; %清图
clc; %清屏
NP = 50; %种群数量
L = 20; %二进制位串长度
Pc = 0.8; %交叉率
Pm = 0.1; %变异率
G = 100; %最大遗传代数
Xs = 10; %上限
Xx = 0; %下限
f = rand(NP,L); %随机获得初始种群
%%%%%%%%%%%%%%%%%%遗传算法循环%%%%%%%%%%%%%%%%
for k = 1:G
%%%%%%%%%%将二进制解码为定义域范围内十进制%%%%%%%%%%
for i = 1:NP
U = f(i,:);
m = 0;
for j = 1:L
m = U(j)*2^(j-1)+m;
end
x(i) = Xx+m*(Xs-Xx)/(2^L-1);
Fit(i) = func1(x(i));
end
maxFit = max(Fit); %最大值
minFit = min(Fit); %最小值
rr = find(Fit==maxFit);
fBest = f(rr(1,1),:); %历代最优个体
xBest = x(rr(1,1));
Fit = (Fit-minFit)/(maxFit-minFit); %归一化适应度值
%%%%%%%%%%%%%%基于轮盘赌的复制操作%%%%%%%%%%%%%
sum_Fit = sum(Fit);
fitvalue = Fit./sum_Fit;
fitvalue = cumsum(fitvalue);
ms = sort(rand(NP,1));
fiti = 1;
newi = 1;
while newi <= NP
if (ms(newi)) < fitvalue(fiti)
nf(newi,:) = f(fiti,:);
newi = newi+1;
else
fiti = fiti+1;
end
end
%%%%%%%%%%%%%%%基于概率的交叉操作%%%%%%%%%%%%%
for i = 1:2:NP
p = rand;
if p < Pc
q = rand(1,L);
for j = 1:L
if q(j)==1;
temp = nf(i+1,j);
nf(i+1,j) = nf(i,j);
nf(i,j) = temp;
end
end
end
end
%%%%%%%%%%%%%基于概率的变异操作%%%%%%%%%%%%%%
i = 1;
while i <= round(NP*Pc)
h = randi([1,NP],1,1); %随机选取一个需要变异的染色体
for j = 1:round(L*Pc)
g = randi([1,L],1,1); %随机选取需要变异的基因数
nf(h,g) =~ nf(h,g);
end
i = i+1;
end
f = nf;
f(1,:) = fBest; %保留最优个体在新种群中
trace(k) = maxFit; %历代最优适应度
end
xBest; %最优个体
figure
plot(trace)
xlabel('迭代次数')
ylabel('目标函数值')
title('适应度进化曲线')
%%%%%%%%%%%%%%%%%%适应度函数%%%%%%%%%%%%%%%%%
function result = func1(x)
fit = x+10*sin(5*x)+7*cos(4*x);
result = fit;
end3.2 遗传算法求解旅行商问题(TSP)
例 2.3 旅行商问题(TSP 问题)。假设有一个旅行商人要拜访全国 31 个省会城市,他需要选择所要走的路径,路径的限制是每个城市只能拜访一次,而且最后要回到原来出发的城市。对路径选择的要求是:所选路径的路程为所有路径 之中的最小值。
全国 31 个省会城市的坐标为 [1304 2312; 3639 1315; 4177 2244; 3712 1399; 3488 1535; 3326 1556; 3238 1229; 4196 1004; 4312 790; 4386 570; 3007 1970; 2562 1756; 2788 1491; 2381 1676; 1332 695; 3715 1678; 3918 2179; 4061 2370; 3780 2212; 3676 2578; 4029 2838; 4263 2931; 3429 1908; 3507 2367; 3394 2643; 3439 3201; 2935 3240; 3140 3550; 2545 2357; 2778 2826; 2370 2975]。
解:仿真过程如下:
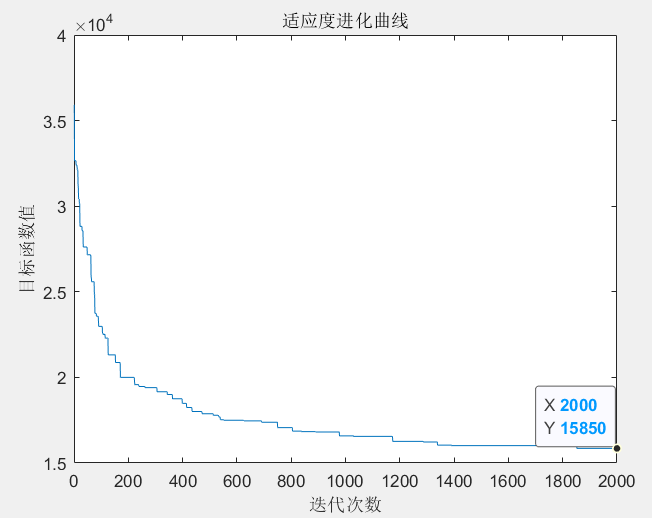
(1)初始化种群数目为 \(NP = 200\),染色体基因维数为 \(N = 31\),最大进化代数 为 \(G = 2000\)。
(2)产生初始种群,计算个体适应度值,即路径长度;采用基于概率的方式选择进行操作的个体;对选中的成对个体,随机交叉所选中的成对城市坐标,以确保交叉后路径每个城市只到访一次;对选中的单个个体,随机交换其一对城市坐标作为变异操作,产生新的种群,进行下一次遗传操作。
(3)判断是否满足终止条件:若满足,则结束搜索过程,输出优化值;若不满足,则继续进行迭代优化。
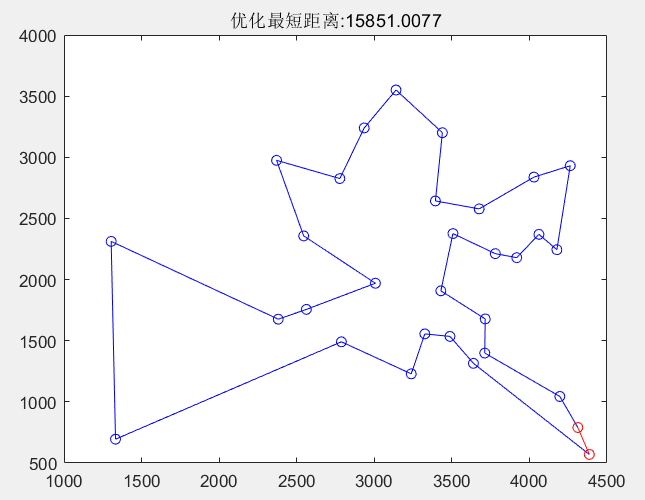
优化后的路径以及其适应度进化曲线如下图所示:
MATLAB 源程序如下:
%%%%%%%%%%%%%%%遗传算法解决 TSP 问题%%%%%%%%%%%%%%%
clear all; %清除所有变量
close all; %清图
clc; %清屏
C = [1304 2312;3639 1315;4177 2244;3712 1399;3488 1535;3326 1556;...
3238 1229;4196 1044;4312 790;4386 570;3007 1970;2562 1756;...
2788 1491;2381 1676;1332 695;3715 1678;3918 2179;4061 2370;...
3780 2212;3676 2578;4029 2838;4263 2931;3429 1908;3507 2376;...
3394 2643;3439 3201;2935 3240;3140 3550;2545 2357;2778 2826;...
2370 2975]; %31 个省会城市坐标
N = size(C,1); %TSP 问题的规模,即城市数目
D = zeros(N); %任意两个城市距离间隔矩阵
%%%%%%%%%%%%求任意两个城市距离间隔矩阵%%%%%%%%%%%%%%
for i = 1:N
for j = 1:N
D(i,j) = ((C(i,1)-C(j,1))^2+(C(i,2)-C(j,2))^2)^0.5;
end
end
NP = 200; %种群规模
G = 2000; %最大遗传代数
f = zeros(NP,N); %用于存储种群
F = []; %种群更新中间存储
for i = 1:NP
f(i,:) = randperm(N); %随机生成初始种群
end
R = f(1,:); %存储最优种群
len = zeros(NP,1); %存储路径长度
fitness = zeros(NP,1); %存储归一化适应值
gen = 0;
%%%%%%%%%%%%%%%%%遗传算法循环%%%%%%%%%%%%%%%%
while gen < G
%%%%%%%%%%%%%%%计算路径长度%%%%%%%%%%%%%%%%
for i = 1:NP
len(i,1) = D(f(i,N),f(i,1));
for j = 1:(N-1)
len(i,1) = len(i,1)+D(f(i,j),f(i,j+1));
end
end
maxlen = max(len); %最长路径
minlen = min(len); %最短路径
%%%%%%%%%%%%%%%更新最短路径%%%%%%%%%%%%%%%
rr = find(len==minlen);
R = f(rr(1,1),:);
%%%%%%%%%%%%%%计算归一化适应值%%%%%%%%%%%%%%
for i = 1:length(len)
fitness(i,1) = (1-((len(i,1)-minlen)/(maxlen-minlen+0.001)));
end
%%%%%%%%%%%%%%%%%选择操作%%%%%%%%%%%%%%%%
nn = 0;
for i = 1:NP
if fitness(i,1) >= rand
nn = nn+1;
F(nn,:) = f(i,:);
end
end
[aa,bb] = size(F);
while aa < NP
nnper = randperm(nn);
A = F(nnper(1),:);
B = F(nnper(2),:);
%%%%%%%%%%%%%%%交叉操作%%%%%%%%%%%%%%%
W = ceil(N/10); %交叉点个数
p = unidrnd(N-W+1); %随机选择交叉范围,从 p 到 p+W
for i = 1:W
x = find(A==B(1,p+i-1));
y = find(B==A(1,p+i-1));
temp = A(1,p+i-1);
A(1,p+i-1) = B(1,p+i-1);
B(1,p+i-1) = temp;
temp = A(1,x);
A(1,x) = B(1,y);
B(1,y) = temp;
end
%%%%%%%%%%%%%%%%%变异操作%%%%%%%%%%%%%
p1 = floor(1+N*rand());
p2 = floor(1+N*rand());
while p1==p2
p1 = floor(1+N*rand());
p2 = floor(1+N*rand());
end
tmp = A(p1);
A(p1) = A(p2);
A(p2) = tmp;
tmp = B(p1);
B(p1) = B(p2);
B(p2) = tmp;
F = [F;A;B];
[aa,bb] = size(F);
end
if aa > NP
F = F(1:NP,:); %保持种群规模为 NP
end
f = F; %更新种群
f(1,:) = R; %保留每代最优个体
clear F;
gen = gen+1;
Rlength(gen) = minlen;
end
figure
for i = 1:N-1
plot([C(R(i),1),C(R(i+1),1)],[C(R(i),2),C(R(i+1),2)],'bo-');
hold on;
end
plot([C(R(N),1),C(R(1),1)],[C(R(N),2),C(R(1),2)],'ro-');
title(['优化最短距离:',num2str(minlen)]);
figure
plot(Rlength)
xlabel('迭代次数')
ylabel('目标函数值')
title('适应度进化曲线')4、遗传算法的特点
遗传算法是模拟生物在自然环境中的遗传和进化的过程而形成的一种并行、高效、全局搜索的方法,它主要有以下特点:
(1)遗传算法以决策变量的编码作为运算对象。这种对决策变量的编码处理方式,使得在优化计算过程中可以借鉴生物学中染色体和基因等概念,模仿自然界中生物的遗传和进化等的机理,方便地应用遗传操作算子。特别是对一些只有代码概念而无数值概念或很难有数值概念的优化问题,编码处理方式更显示出了其独特的优越性。
(2)遗传算法直接以目标函数值作为搜索信息。它仅使用由目标函数值变换来的适应度函数值,就可确定进一步的搜索方向和搜索范围,而不需要目标函数的导数值等其他一些辅助信息。实际应用中很多函数无法或很难求导,甚至根本不存在导数,对于这类目标函数的优化和组合优化问题,遗传算法就显示了其高度的优越性,因为它避开了函数求导这个障碍。
(3)遗传算法同时使用多个搜索点的搜索信息。遗传算法对最优解的搜索过程,是从一个由很多个体所组成的初始群体开始的,而不是从单一的个体开始的。对这个群体所进行的选择、交叉、变异等运算,产生出新一代的群体,其中包括了很多群体信息。这些信息可以避免搜索一些不必搜索的点,相当于搜索了更多的点,这是遗传算法所特有的一种隐含并行性。
(4)遗传算法是一种基于概率的搜索技术。遗传算法属于自适应概率搜索技术,其选择、交叉、变异等运算都是以一种概率的方式来进行的,从而增加了其搜索过程的灵活性。虽然这种概率特性也会使群体中产生一些适应度不高的个体,但随着进化过程的进行,新的群体中总会更多地产生出优良的个体。与其他一些算法相比,遗传算法的鲁棒性使得参数对其搜索效果的影响尽可能小。
(5)遗传算法具有自组织、自适应和自学习等特性。当遗传算法利用进化过程获得信息自行组织搜索时,适应度大的个体具有较高的生存概率,并获得更适应环境的基因结构。同时,遗传算法具有可扩展性,易于同别的算法相结合,生成综合双方优势的混合算法。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/194604.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
