大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
前言
做为一个性能测试工程师,每当我们发现计算机变慢的时候,我们通常的标准姿势就是执行 uptime 或 top 命令,来了解系统的负载情况。
比如像下面这样,我在命令行里输入了 uptime 命令,系统会返回一行信息。
appletekimbp:~ apple$ uptime
20:44 up 21 days, 6:41, 2 users, load averages: 2.85 2.33 2.91
但我想问的是,各位同学知道以上每列输出的含义吗?
20:44 # 当前时间
up 21 days, 6:41 # 系统运行时间
2 users # 正在登录用户数
# 系统的平均负载,分别是1分钟、5分钟、15分钟内系统的平均负载
load averages: 2.85 2.33 2.91
这行信息的后半部分,显示 “load average”,它的意思是”系统的平均载荷”,里面有三个数字,我们可以从中判断系统负载是大还是小。
什么是系统平均负载?
我猜一定会有同学会说,平均负载不就是单位时间的 CPU 使用率吗?上面 2.85,就代表 CPU 使用率是 285%。其实不是这样的。
CPU 负载值在 Linux 系统中表示正在运行,处于可运行状态的平均作业数(读取一组与流程执行线程对应的机器语言的程序指令),或者非常重要,休眠但不可中断(不可交错的休眠状态))。也就是说,要计算 CPU 负载的值,只考虑正在运行或等待分配 CPU 时间的进程。不考虑正常的休眠过程(休眠状态),僵尸或停止的过程。
简单来说,平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系。
进程状态代码
R 正在运行或可运行(在运行队列中)
D 不间断休眠(通常为IO)
S 可中断休眠(等待事件完成)
Z 失效/僵尸,终止但未被其父
T 停止,由作业控制停止信号或因为它被追踪
[…]
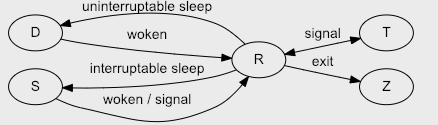
这里先解释下,可运行状态和不可中断状态。
可运行状态的进程,指的是正在使用CPU或者正在等待CPU的进程,也就是我们常用 ps 命令看到处于 R 状态(Running 或 Runnable)的进程。
不可中断状态的进程,指的是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如常见是等待硬件设备的 I/O 响应。也就是我们在Ps 命令看到的D状态(Uninterruptible Sleep,也称为 Disk Sleep)的进程。
比如,当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时间的进程就处于不可中断状态。如果此时的进程被打断,就容易出现磁盘数据与进程数据不一致的问题。
所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制。
因此,我们可以简单理解为,平均负载其实就是平均活跃进程数。平均活跃进程数,直观上的理解就是单位时间内的活跃进程数。
既然平均的是是活跃进程数,那么理想的是,每个CPU上都刚好运行着一个进程,这样每个CPU都得到了充分利用。
以下是单核处理器计算机中不同负载值的含义:
- 0.00:没有任何作业正在运行或等待 CPU 执行,即 CPU 完全空闲。因此,如果正在运行的程序(进程)需要执行任务,它会向 CPU 请求操作系统,并立即为该进程分配 CPU 时间,因为没有其他进程在竞争它。
- 0.50:没有任何作业在等待,但 CPU 正在处理以前的作业,并且它正在以 50% 的容量进行处理。在这种情况下,操作系统还可以立即将 CPU 时间分配给其他进程,而无需将其置于保持状态。
- 1.00:队列中没有作业,但 CPU 正在以 100% 的容量处理先前的作业,因此如果新进程请求 CPU 时间,则必须将其保留到另一个作业完成或当前 CPU 插槽时间(例如,CPU tick)到期,操作系统决定哪一个是下一个给定的进程优先级。
- 1.50:CPU 工作在其容量的 100%,15个工作中有5个请求CPU时间,即 33.33%,必须排队等待其他人耗尽他们分配的时间。因此,一旦超过1.0 的阈值,就可以说系统过载,因为它不能立即处理所请求的 100% 的工作。
那么很显然,”load average”的值越低,比如等于0.2或0.3,就说明服务器的工作量越小,系统负载比较低。
一个类比
上面还看太懂怎么办?没事,我们来看一个简单的类比例子。
先假设最简单的情况,你的计算机只有一个 CPU,所有的运算都必须由这个 CPU 来完成。
那么,我们不妨把这个 CPU 想象成一座大桥,桥上只有一根车道,所有车辆都必须从这根车道上通过。(很显然,这座桥只能单向通行。)
系统负载为 0,意味着大桥上一辆车也没有。


系统负载为 0.5,意味着大桥一半的路段有车。

系统负载为 1.0,意味着大桥的所有路段都有车,也就是说大桥已经”满”了。但是必须注意的是,直到此时大桥还是能顺畅通行的。

系统负载为 1.7,意味着车辆太多了,大桥已经被占满了(100%),后面等着上桥的车辆为桥面车辆的 70%。以此类推,系统负载 2.0,意味着等待上桥的车辆与桥面的车辆一样多;系统负载 3.0,意味着等待上桥的车辆是桥面车辆的 2 倍。总之,当系统负载大于 1,后面的车辆就必须等待了;系统负载越大,过桥就必须等得越久。

CPU 的系统负载,基本上等同于上面的类比。大桥的通行能力,就是CPU 的最大工作量;桥梁上的车辆,就是一个个等待 CPU 处理的进程(process)。
如果CPU 每分钟最多处理100个进程,那么系统负载0.2,意味着CPU在这 1 分钟里只处理 20 个进程;系统负载 1.0,意味着 CPU 在这 1 分钟里正好处理 100 个进程;系统负载 1.7,意味着除了 CPU 正在处理的100 个进程以外,还有 70 个进程正排队等着CPU处理。
为了计算机顺畅运行,系统负载最好不要超过 1.0,这样就没有进程需要等待了,所有进程都能第一时间得到处理。很显然,1.0 是一个关键值,超过这个值,系统就不在最佳状态了,你要动手干预了。
多处理器和多核系统
在具有多个处理器或核心(多个逻辑CPU)的系统中,CPU负载值的含义取决于系统中存在的处理器数量。因此,具有4个处理器的计算机在达到4.00的负载之前将不会以100%使用,因此在解释由top,htop或正常运行时间等命令提供的3个负载值时,你必须要做的第一件事 就是将它们分开。系统中存在的逻辑CPU数量,并从中得出结论。
举个例子,如果你的计算机装了 2 个 CPU,会发生什么情况呢?
2 个 CPU,意味着计算机的处理能力翻了一倍,能够同时处理的进程数量也翻了一倍。
还是用大桥来类比,两个 CPU 就意味着大桥有两根车道了,通车能力翻倍了

所以,2 个CPU表明系统负载可以达到 2.0,此时每个 CPU 都达到 100%的工作量。推广开来,n 个 CPU 的计算机,可接受的系统负载最大为n.0。
芯片厂商往往在一个 CPU 内部,包含多个CPU核心,这被称为多核CPU。
在系统负载方面,多核 CPU 与多 CPU 效果类似,所以考虑系统负载的时候,必须考虑这台计算机有几个 CPU、每个 CPU 有几个核心。然后,把系统负荷除以总的核心数,只要每个核心的负荷不超过 1.0,就表明计算机正常运行。
怎么知道电脑有多少个 CPU 核心呢?
延伸阅读:
性能基础之CPU、物理核、逻辑核概念与关系
CPU使用率
如果我们观察在给定时间间隔内通过CPU的不同进程,则利用率百分比将表示相对于CPU执行与每个进程相对应的指令的那个时间间隔的时间部分。但这种计算只运行的进程,而不是那些正在等待,无论它们是在队列(可运行状态)还是睡着但不可中断(例如在等待输入/输出操作的结束)被认为。
因此,这个指标可以让我们了解哪些进程最大程度地挤压CPU,但是如果系统状态过载或者未充分利用,则不能给出真实的系统状态图。
现实工作中,我们经常容易把平均负载和 CPU 使用率混淆,从上面我们知道平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅包括正在使用 CPU 的进程,还包括等待 CPU 和等待I/O 的进程。而 CPU使用率,从上面的解释我们知道是单位时间内繁忙程度,跟平均负载并不一定完全对应。比如:
- CPU 密集型进程,使用大量 CPU 会导致平均负载升高,这时候两者是一致的。
- I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高。
- 大量等待 CPU 的进程调度也会导致平均负载很高,此时的 CPU 使用率也会比较高。
注意输入/输出(I/O)操作
在本文反复强调了不间断休眠状态非常重要 (第一张图中的D),因为有时你可以在计算机中找到非常高的负载值,然而不同的运行过程使用率相对较低。如果你不考虑这种状态,你会发现情况莫名其妙,你将不知道如何处理它。当进程等待某个资源的释放并且其执行不能被中断时,例如当它等待不可中断的 I/O 操作时,进程处于此状态完成(并非所有都是不可中断的)。通常,这种情况是由于磁盘故障,网络文件系统(如 NFS 故障)或大量使用非常慢的设备(例如USB 1.0 pendrive)而发生的。
在这种情况下,我们将不得不使用替代工具,如 iostat 或 iotop,它们将指示哪些进程正在执行更多的 I/O 操作,以便我们可以杀死这些进程或为它们分配较少的优先级(nice 命令)能够为其他更关键的进程分配更多的CPU 时间。
一些技巧
系统过载并超过1.0的负载值有时不是问题,因为即使有一些延迟,CPU也会处理队列中的作业,负载将再次降低到1.0以下的值。但是如果系统的持续负载值大于1,则意味着它无法吸收执行中的所有负载,因此其响应时间将增加,系统将变得缓慢且无响应。高于1的高值,尤其是最后5分钟和15分钟的负载平均值是一个明显的症状,要么我们需要改进计算机的硬件,通过限制用户可以对系统的使用来节省更少的资源,或者除以多个相似节点之间的负载。
因此,我们提出以下建议:
>=0.70:没有任何反应,但有必要监控 CPU 负载。如果在一段时间内保持这种状态,就必须在事情变得更糟之前进行调查。>=1.00:存在问题,您必须找到并修复它,否则系统负载的主要高峰将导致您的应用程序变慢或无响应。>=3.00:你的系统变得 非常慢。甚至很难从命令行操作它来试图找出问题的原因,因此修复问题需要的时间比我们之前采取的行动要长。你冒的风险是系统会更饱和并且肯定会崩溃。>=5.00:你可能无法恢复系统。你可以等待奇迹自发降低负载,或者如果你知道发生了什么并且可以负担得起,你可以在控制台中启动kill -9 <process_name>之类的命令 ,并祈求它运行在某些时候,以减轻系统负荷并重新获得其控制权。否则,你肯定别无选择,只能重新启动计算机。
参考资料:
- [1]:http://www.ruanyifeng.com/blog/2011/07/linux_load_average_explained.html
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/194589.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
