大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
前面在《遗传算法通识》中介绍了基本原理,这里结合实例,看看遗传算法是怎样解决实际问题的。
有一个函数:
求其在区间[-10,10]之间的最大值。下面是该函数的图像:

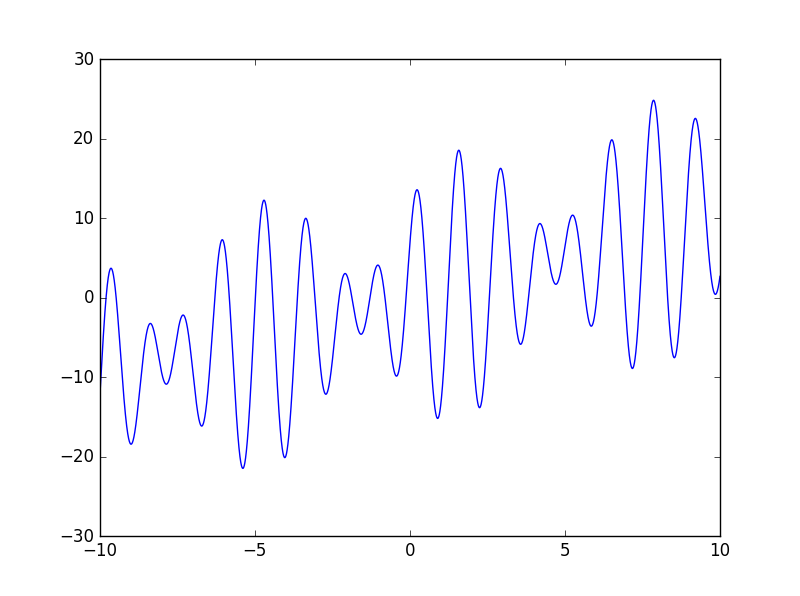
在本例中,我们可以把x作为个体的染色体,函数值f(x)作为其适应度值,适应度越大,个体越优秀,最大的适应度就是我们要求的最大值。
直接看代码吧(直接看注释就能看懂)。
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
# 适应度函数
def fitness(x):
return x + 10 * np.sin(5 * x) + 7 * np.cos(4 * x)
# 个体类
class indivdual:
def __init__(self):
self.x = 0 # 染色体编码
self.fitness = 0 # 适应度值
def __eq__(self, other):
self.x = other.x
self.fitness = other.fitness
# 初始化种群
def initPopulation(pop, N):
for i in range(N):
ind = indivdual()
ind.x = np.random.uniform(-10, 10)
ind.fitness = fitness(ind.x)
pop.append(ind)
# 选择过程
def selection(N):
# 种群中随机选择2个个体进行变异(这里没有用轮盘赌,直接用的随机选择)
return np.random.choice(N, 2)
# 结合/交叉过程
def crossover(parent1, parent2):
child1, child2 = indivdual(), indivdual()
child1.x = 0.9 * parent1.x + 0.1 * parent2.x
child2.x = 0.1 * parent1.x + 0.9 * parent2.x
child1.fitness = fitness(child1.x)
child2.fitness = fitness(child2.x)
return child1, child2
# 变异过程
def mutation(pop):
# 种群中随机选择一个进行变异
ind = np.random.choice(pop)
# 用随机赋值的方式进行变异
ind.x = np.random.uniform(-10, 10)
ind.fitness = fitness(ind.x)
# 最终执行
def implement():
# 种群中个体数量
N = 20
# 种群
POP = []
# 迭代次数
iter_N = 500
# 初始化种群
initPopulation(POP, N)
# 进化过程
for it in range(iter_N):
a, b = selection(N)
if np.random.random() < 0.75: # 以0.75的概率进行交叉结合
child1, child2 = crossover(POP[a], POP[b])
new = sorted([POP[a], POP[b], child1, child2], key=lambda ind: ind.fitness, reverse=True)
POP[a], POP[b] = new[0], new[1]
if np.random.random() < 0.1: # 以0.1的概率进行变异
mutation(POP)
POP.sort(key=lambda ind: ind.fitness, reverse=True)
return POP
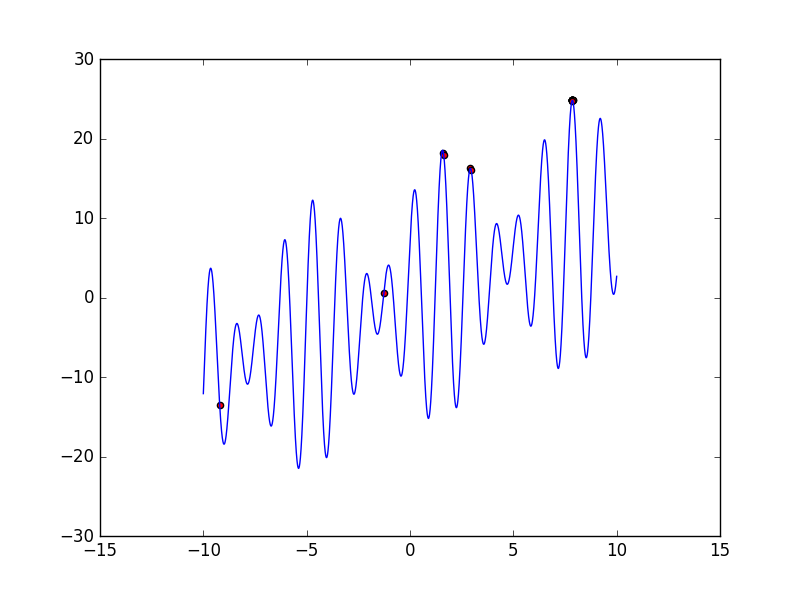
pop = implement()某一次执行中生成的种群结果:
x= 7.856668536350623 f(x)= 24.8553618344
x= 7.856617137410436 f(x)= 24.8553599496
x= 7.855882244973719 f(x)= 24.855228419
x= 7.858162713580771 f(x)= 24.8549986778
x= 7.854666292636083 f(x)= 24.8545814476
x= 7.8546151621339035 f(x)= 24.8545425164
x= 7.854257103484315 f(x)= 24.8542433686
x= 7.8540369711896485 f(x)= 24.8540364169
x= 7.859755006757047 f(x)= 24.8537223172
x= 7.853295380711855 f(x)= 24.85321014
x= 7.853150338317231 f(x)= 24.853025258
x= 7.865253897257472 f(x)= 24.8422607373
x= 7.865398960184752 f(x)= 24.8418103374
x= 7.83788118828644 f(x)= 24.7909840929
x= 1.6190862308608494 f(x)= 18.1988285173
x= 1.6338610617810327 f(x)= 17.9192791105
x= 2.9228585632615074 f(x)= 16.2933631636
x= 2.95557040313432 f(x)= 16.1223714647
x= -1.2700947285555912 f(x)= 0.575714213108
x= -9.208677771536376 f(x)= -13.4869432732
得到的最优解结果为:
x= 7.856668536350623 f(x)= 24.8553618344
从图像上看符合要求。其结果图像如下,红色点表示种群中个体的位置。
# 绘图代码
def func(x):
return x + 10 * np.sin(5 * x) + 7 * np.cos(4 * x)
x = np.linspace(-10, 10, 10000)
y = func(x)
scatter_x = np.array([ind.x for ind in pop])
scatter_y = np.array([ind.fitness for ind in pop])
plt.plot(x, y)
plt.scatter(scatter_x, scatter_y, c='r')
plt.show()
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/194361.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
