大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
一、相关文献:
fast.ai上面关于自监督学习的资料:Self-supervised learning and computer vision.
GitHub上面每年使用自监督学习的论文列表:Awesome Self-Supervised Learning.
相关微信推送
二、自监督学习的介绍
1.自监督学习的由来
机器学习中基本的学习方法有:监督学习(supervised learning)、半监督学习(semi-supervised learning)和无监督学习(unsupervised learning)。他们最大的区别就是模型在训练时需要人工标注的标签信息,监督学习利用大量的标注数据来训练模型,使模型最终学习到输入和输出标签之间的相关性;半监督学习利用少量有标签的数据和大量无标签的数据来训练网络;而无监督学习不依赖任何标签值,通过对数据内在特征的挖掘,找到样本间的关系,比如聚类。
使用监督学习时我们需要足够的标记数据。为了获得这些信息,需要手工标记数据(图像/文本),这是一个既耗时又昂贵的过程。还有一些领域,比如医疗领域,获取足够的数据本身就是一个挑战。而在使用无监督学习的时候,例如自编码器,仅仅是做了维度的降低而已,并没有包含更多的语义特征,对下游任务并没有很大的帮助。
因此我们想要在不需要手工标记数据的情况下,训练过程还能对任务本身有很大的帮助,可以包含更多的语义特征,自监督学习因此被提出。
2.自监督学习的定义
自监督学习主要是利用辅助任务(pretext)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。
也就是说,自监督学习不需要任何的外部标记数据,这些标签是从输入数据自身中得到的。自监督学习的模式仍然是Pretrain-Fintune的模式,即先在pretext上进行预训练,然后将学习到的参数迁移到下游任务网络中,进行微调得到最终的网络。
3.自监督学习的pretext
在计算机视觉中使用自监督学习最需要回答的问题是:“你应该使用什么pretext?”其实你有很多选择。下面是其中的一些,以及描述它们的论文,在每个部分都有一篇论文的图片展示了这种方法。
3.1图像旋转
论文:Unsupervised Representation Learning by Predicting Image Rotations (ICLR18),如图,文章提出,通过训练ConvNets来识别输入图像的2D旋转来学习图像特征。在质量和数量上证明了这个看似简单的任务,实际上为语义特征学习提供了非常强大的监督信号。其生成的标签为人为旋转图片后得到的数据。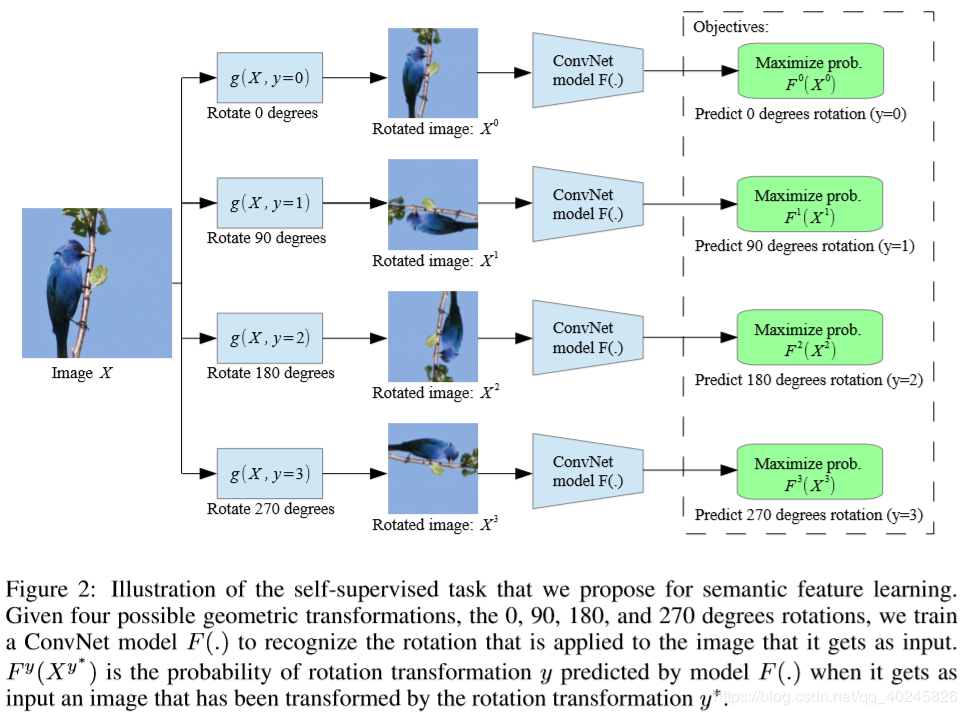

3.2图像着色
论文:Colorful Image Colorization|Real-Time User-Guided Image Colorization with Learned Deep Priors。使用图像灰度化来作为图像的输入数据,对应的彩色图像为标签数据训练网络。为了解决这个问题,模型必须了解图像中出现的不同物体和相关部分,这样它才能用相同的颜色绘制这些部分。因此对下游任务提供了帮助。
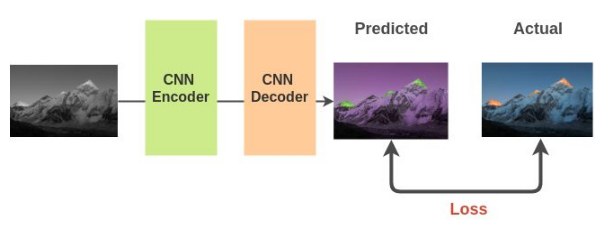
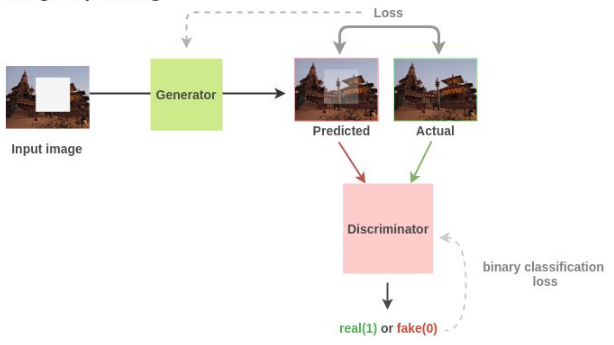
3.3图像修复
论文:Context encoders: Feature learning by inpainting。我们可以通过随机去掉图像中的某个部分来生成训练数据,原数据作为训练标签来进行预训练,对于下游任务,Pathak等人表明,在PASCAL VOC 2012语义分割的比赛上,生成器学到的语义特征相比随机初始化有10.2%的提升,对于分类和物体检测有<4%的提升。
上面只是举例介绍了一下自我监督的pretext有哪些,还有很多工作,大家可以去GitHub论文列表中查找相应的论文。
4.自监督学习的主要方法
自监督学习的方法主要可以分为 3 类:1. 基于上下文(Context based) 2. 基于时序(Temporal Based)3. 基于对比(Contrastive Based)
4.1基于上下文(Context Based)
基于数据本身的上下文信息,我们其实可以构造很多任务,比如在 NLP 领域中最重要的算法 Word2vec 。Word2vec 主要是利用语句的顺序,例如 CBOW 通过前后的词来预测中间的词,而 Skip-Gram 通过中间的词来预测前后的词。
而在图像中,图像拼图(将图像分割,预测每一部分的相对位置或者预测出这是哪一种打乱方式)、图像修复(上述例子中提到)、图像着色(上述例子中提到)、图像旋转(上述例子中提到)等任务都是典型的作为pretext的例子。
比较特殊的最近的任务还有两种:一种是自监督学习和具体任务紧密结合的方法(Task Related Self-Supervised Learning)(Boosting Few-Shot Visual Learning with Self-Supervision_ICCV2019),另一种是自监督和半监督学习进行结合(SL: Self-Supervised Semi-Supervised Learning_ICCV2019)。
4.2基于时序(Temporal Based)
之前介绍的方法大多是基于样本自身的信息,比如旋转、色彩、裁剪等。而样本间其实也是具有很多约束关系的,这里我们来介绍利用时序约束来进行自监督学习的方法。最能体现时序的数据类型就是视频了(video)。
第一种思想是基于帧的相似性Time-Contrastive Networks: Self-Supervised Learning from Video,对于视频中的每一帧,其实存在着特征相似的概念,简单来说我们可以认为视频中的相邻帧特征是相似的,而相隔较远的视频帧是不相似的,通过构建这种相似(position)和不相似(negative)的样本来进行自监督约束。
另外,对于同一个物体的拍摄是可能存在多个视角(multi-view),对于多个视角中的同一帧,可以认为特征是相似的,对于不同帧可以认为是不相似的。
还有一种想法是来自 ICCV 2015 Unsupervised Learning of Visual Representations Using Videos.的基于无监督追踪方法,首先在大量的无标签视频中进行无监督追踪,获取大量的物体追踪框。那么对于一个物体追踪框在不同帧的特征应该是相似的(positive),而对于不同物体的追踪框中的特征应该是不相似的(negative)。
除了基于特征相似性外,视频的先后顺序也是一种自监督信息。比如ECCV 2016, Misra, I. Shuffle and Learn:unsupervised learning using temporal order verification等人提出基于顺序约束的方法,可以从视频中采样出正确的视频序列和不正确的视频序列,构造成正负样本对然后进行训练。简而言之,就是设计一个模型,来判断当前的视频序列是否是正确的顺序。
4.3基于对比(Contrastive Based)
相关资料:https://ankeshanand.com/blog/2020/01/26/contrative-self-supervised-learning.html
对比约束,它通过学习对两个事物的相似或不相似进行编码来构建表征,这类方法的性能目前来说是非常强的,主要思想是通过构建正样本(positive)和负样本(negative),然后度量正负样本的距离来实现自监督学习,即样本和正样本之间的距离远远大于样本和负样本之间的距离,可以使用点积的方式构造距离函数,然后构造一个 softmax 分类器,以正确分类正样本和负样本。这应该鼓励相似性度量函数(点积)将较大的值分配给正例,将较小的值分配给负例:

通常这个损失也被称为 InfoNCE,后面的所有工作也基本是围绕这个损失进行的。
三、选择一个pretext
选择的任务必须是这样的,如果解决了这个任务,就需要了解数据,这也是解决下游任务所需要的,也就是说下游任务和pretext要有一定的相关性。例如,科研学者经常使用一种叫做自动编码器的pretext。这是一个模型,它可以将一个输入图像转换成一个大大简化的形式(使用瓶颈层),然后将其转换回尽可能接近原始图像的内容。它有效地利用压缩作为借口任务。然而,解决这个问题不仅需要重新生成原始图像的内容,还需要重新生成原始图像中的任何噪声。因此,如果您的下游任务是您想要生成更高质量的图像,那么这将是一个糟糕的借口任务的选择。你也应该确保这个借口任务是一个人可以做的事情。例如,您可以将生成未来视频帧的问题作为借口任务。但是如果你试图生成的框架在未来太远了,那么它可能是一个完全不同的场景的一部分,以至于没有任何模型能够自动生成它。
四、对下游任务进行微调
一旦利用一个pretext预训练了模型,就可以进行微调了。在这一点上,应该把这当作一个迁移学习的问题,因此应该小心不要伤害预先训练的weight。参考ULMFiT论文中讨论的内容,例如逐步解冻、有区别的学习率和单周期训练。
总的来说,我建议不要花太多时间来创建完美的pretext,而应该尽可能地快速、简单地构建所能构建的任何东西。然后你就可以知道它是否适合你的下游任务。通常情况下并不需要一个特别复杂的pretext来完成下游任务。因此很容易在设计pretext上浪费时间。
五、Consistency loss
在自监督训练的基础上,可以增加一个非常有用的技巧,这在NLP中被称为“一致性损失(Consistency loss)”,在计算机视觉中被称为“噪声对比估计(noise contrastive estimation)”。基本思想是这样的:pretext是一些混乱原数据的事情,比如模糊部分,旋转,移动补丁,或者(在NLP中)改变单词位置或者把一个句子翻译成外语然后再翻译回来。在每种情况下,都希望原始项和“混乱”项在pretext中给出相同的预测,并在中间表示中创建相同的特性。并且也希望同样的东西,当以两种不同的方式“混乱”时(例如,一个图像旋转了两个不同的量),也应该有相同的一致表示。
因此,我们在loss函数中添加了一些内容,以惩罚为相同数据的不同版本获取不同的答案。这是一幅图片,来自谷歌的文章,提出了 Advancing Semi-supervised Learning with Unsupervised Data Augmentation。
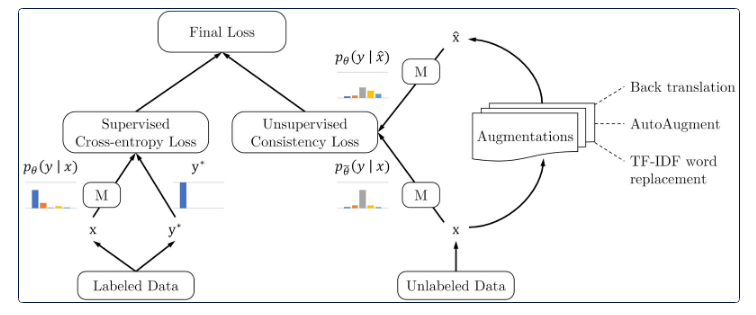
说这是“有效的”将是一个巨大的轻描淡写…例如,在上述文章中讨论的方法完全打破了我们之前的状态,他们使用的标签数据比我们少1000倍!
Facebook人工智能最近发表了两篇论文,在计算机视觉环境中使用了这一想法:Self-Supervised Learning of Pretext-Invariant Representations and Momentum Contrast for Unsupervised Visual Representation Learning。就像NLP中的谷歌论文一样,这些方法超越了以前最先进的方法,并且需要更少的数据。
六、扩展阅读
Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey
Revisiting Self-Supervised Visual Representation Learning
Self-Supervised Representation Learning
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/194022.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
