大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
简介
自监督学习是近几年(2020年)流行起来的一种机器学习方法,很多人认为自监督方法未来一段时间将取代现有的监督方法,成为深度学习中占据主导地位的方法。现在已经有不少采用自监督-对比学习的方法取得了领先的效果。目前(2020.10)来说这个领域貌似还比较新,没有找到很系统的讲解介绍资料。
首先介绍一下到底什么是 SSL,我们知道一般机器学习分为监督学习,非监督学习和强化学习。而 self-supervised learning 是无监督学习里面的一种。自监督学习的思想非常简单,就是输入的是一堆无监督的数据,但是通过数据本身的结构或者特性,人为构造标签(pretext)出来。有了标签之后,就可以类似监督学习一样进行训练。通过自己监督自己,比如把一段话里面的几个单词去掉,用他的上下文去预测缺失的单词,或者将图片的一些部分去掉,依赖其周围的信息去预测缺失的 patch。自监督还有一个主要是希望是能够学习到一种通用的特征表达用于多种下游任务,(预训练?)。
在表示学习方面,自我监督学习具有取代完全监督学习的巨大潜力。人类学习的本质告诉我们,大型注释数据集可能不是必需的,我们可以自发地从未标记的数据集中学习。更为现实的设置是使用少量带注释的数据进行自学习。这称为Few-shot Learning。
自监督学习的特点和优点
传统方法缺点
相对于自监督学习,当前的机器学习方法大多依赖于人类标注信息,这种对标注信息的过度依赖有如下危险:
1、数据的内部结构远比标注提供的信息要丰富,因此通常需要大量的训练样本,但得到的模型有时是较为脆弱的。(从另一个角度说深度学习需要大数据的原因之一是因为标签能给到的监督信息太少,所以需要大量样本来学习,如果有类似自监督的样的方法,能给出更多监督信息,那么是否就可以用更少的样本进行学习了。)
2、在高维分类问题上,我们不能直接依赖监督信息;同时,在增强学习等问题上,获取标签的成本非常高。
3、标签信息通常适用于解决特定的任务,而不是可以做为知识一样可以重新利用。
这么快又变成传统了!
自监督方法特点
因此,自监督学习成为一种非常有前途的方法,因为数据本身为学习算法提供了监督信息。
一个简单的例子


Epstein在2016年做了一个实验,受试者要求尽可能详细地画出美元图片。上图中左边为受试者按照自己的记忆画出来的一美元图片,右边为受试者携带着美元(不是一美元)然后照着画出来的一美元图片。实验表示,当有类似的美元图片做为参考时,人们画的要更好。
尽管无数次见过美元,但我们仍然不能记住它,并把它画出来。实际上,我们只是记住了美元的一些与其它对象有区分性的特征。因此,我们是不是可以构建一些不专注于像素细节的表示学习算法(representation learning algorithm),通过对高层特征编码来实现不同对象的区分,也即模型在特征空间上对不同的输入进行分辨,就像上面美元的例子。
自监督学习方法有如下的特点:
- 在 feature space 上构建距离度量;
- 通过特征不变性,可以得到多种预测结果,或者叫用于多种任务;
- 使用 Siamese Network;
- 不需要 pixel-level 重建。正因为这类方法不用在 pixel-level 上进行重建,所以优化变得更加容易。
当然这类方法也不是没有缺点,因为数据中并没有标签,所以主要的问题就是怎么取构造正样本和负样本。
用于多种任务,也就是说比如知道了美元的特征,不仅可以用于分辨美元增加,还可以用于识别美元面额,或者用文字描述一下美元的样子,或者风格迁移生成类似的图片等等任务,可以在同一个模型中就做多种任务。
通过自监督学习,我们可以做的事情可以远超过监督学习
与无监督学习的区别联系
无监督的方法不依赖于人类注释,并且通常集中在数据良好表示(例如平滑度,稀疏性和分解)的预设先验上。无监督方法的经典类型是聚类方法,例如高斯混合模型,它将数据集分解为多个高斯分布式子数据集。然而,非监督学习学习由于预设先验的一般性较差而不太值得信赖,在某些数据集(例如非高斯子数据集)上选择将数据拟合为高斯分布可能是完全错误的。
自我监督方法可以看作是一种具有监督形式的特殊形式的无监督学习方法,这里的监督是由自我监督任务而不是预设先验知识诱发的。与完全不受监督的设置相比,自监督学习使用数据集本身的信息来构造伪标签。
对比学习-具体实现方式
现在 self-supervised learning 主要分为两大类:1. Generative Methods;2. Contrastive Methods。下面我们分别简要介绍一下这这两种方法。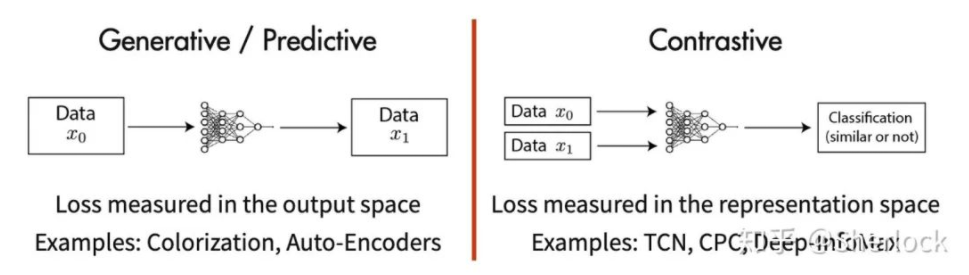
这篇文章总结比较好:https://zhuanlan.zhihu.com/p/141141365
对比方法(Contrastive methods)通过正面和负面的例子来学习表征。尽管不是全新的思路,对比方法通过无监督的对比预训练(Unsupervised contrastive pre-training)在计算机视觉任务中取得了巨大的成功。
比较知名的方法有:
在未标记的ImageNet数据上训练并使用线性分类器的无监督对比方法已经超过了监督的AlexNet(2019年Henaff提出的CPC方法)。
ImageNet上的对比式预训练成功地转移到了其它任务,并且胜过了监督的预训练任务(2019年何恺明提出的MoCo方法)。
和传统的 Generative model 不同,传统方法专注于像素空间的特征,会存在如下不足:
使用像素级loss可能导致此类方法过于关注基于像素的细节,而不是抽象的语义信息。
在于像素分析的方法难以有效的建立空间关联及对象的复杂结构。
对比模型是如何工作的?
对比学习核心就是要学习一个映射函数f(x),把样本 x 编码成其表示 f(x),对比学习的核心就是使得这个 f(x) 满足下面这个式子:

这里 x+ 指的是与x 相似的数据(正样本), x- 指的是与x不相似的数据(负样本)。score 函数是一个度量函数,评价两个特征间的相似性。
如果用向量内积来计算两个样本的相似度,则对比学习的损失函数可以表示成:

其中对应样本 [公式] 有1个样本和N-1个负样本。可以发现,这个形式类似于交叉熵损失函数,学习的目标就是让 [公式] 的特征和正样本的特征更相似,同时和N-1个负样本的特征更不相似。在对比学习的相关文献中把这一损失函数称作InfoNCE损失。也有一些其他的工作把这一损失函数称为multi-class n-pair loss或者ranking-based NCE。
![如何构建正例和负例?针对不同类型数据,例如图像、文本和音频,如何合理的定义哪些样本应该被视作是 [公式],哪些该被视作是 [公式],;如何增加负例样本的数量,也就是上面式子里的 [公式]?这个问题是目前很多 paper 关注的一个方向,因为虽然自监督的数据有很多,但是设计出合理的正例和负例 pair,并且尽可能提升 pair 能够 cover 的 semantic relation,才能让得到的表示在 downstream task 表现的更好。](https://img-blog.csdnimg.cn/20201009035332651.png)
知乎:
我将自我监督的表示学习方法分为4种类型:基于数据生成(恢复)的任务,基于数据变换的任务,基于多模态的任务,基于辅助信息的任务。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/193954.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
