大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
本篇文章将对自监督学习的要点进行总结,包括以下几个方面:
- 监督学习与自监督学习
- 自监督学习需求背后的动机
- NLP 和CV中的自监督学习
- 联合嵌入架构
- 对比学习
- 关于数据增强的有趣观察
- 非对比学习
- 总结和参考
监督学习与自监督学习
监督学习:机器学习中最常见的方法是监督学习。在监督学习中,我们得到一组标记数据(X,Y),即(特征,标签),我们的任务是学习它们之间的关系。但是这种方法并不总是易于处理,因为-
- 训练通常需要大量数据,而标记数百万行数据既耗时又昂贵,这就对许多不同任务的训练模型造成了瓶颈。
- 以这种方式训练的模型通常非常擅长手头的任务,但不能很好地推广到相关但是非相同领域内的任务。因为网络只专注于学习 X 的良好表示以生成之间的直接映射X 和 Y ,而不是学习 X 的良好通用表示,所以无法转移到类似的其他任务。
这种学习通常会导致对概念的非常肤浅的理解,即它学习了 X 和 Y 之间的关系(它优化了网络以学习这种映射),但它不理解 X 的实际含义或它背后的含义。
自监督学习 (Self-supervised learning / SSL):自监督学习也适用于(特征、标签)数据集,即以监督的方式,但它不需要人工注释的数据集。它的基本思想是屏蔽/隐藏输入的某些部分,并使用可观察的部分来预测隐藏的部分。正如我们将在下面看到的,这是一个非常强大的想法。但是我们不称其为无监督学习是因为它仍然需要标签,但不需要人工对其进行标注。
SSL的优势是如果我们手头有大量未标记的数据,SSL的方式可以让我们利用这些数据。这样模型可以学习更强大的数据底层结构的表示,并且这些表示比监督学习中学到的更普遍,然后我们可以针对下游任务进行微调。
需求和动机
在过去的 10 年里,深度学习取得了长足的进步。几年前被认为计算机似乎不可能完成的任务(例如机器翻译、图像识别、分割、语音识别等)中,已经达到/超过了人类水平的表现。在经历了十年的成功故事之后,深度学习现在正处于一个关键点,人们已经慢慢但肯定地开始认识到当前深度学习方法的基本局限性。
人类和当前人工智能的主要区别之一是人类可以比机器更快地学习事物,例如仅通过查看 1-2 张照片来识别动物,只需 15-20 小时即可学会驾驶汽车。人类如何做到这一点?常识!虽然我们还不知道常识是如何产生的,但却可以通过思考人类如何实际了解世界来做出一些有根据的猜测:
- 人类主要通过观察学习,很少通过监督学习。从婴儿出生的那一刻起(或者之前),它就不断地听到/看到/感觉到周围的世界。因此,发生的大部分学习只是通过观察。
- 人类可以利用随着时间的推移获得的知识(感知、运动技能、基础物理来帮助导航世界等),而当前的 SOTA 机器却不能。
自监督学习通过学习从未屏蔽部分预测数据的屏蔽部分来模仿的人类这部分的能力。
NLP 与CV中的 SSL
NLP 中的一般做法是屏蔽一些文本并使用附近的文本对其进行预测。这种做法已经有一段时间了,现在 SOTA 模型都是以这种方式进行训练,例如 BERT、ROBERTA XLM-R、GPT-2,3 等。在 NLP 中应用这种技术相对容易,因为屏蔽词的预测只能取离散值,即词汇表中的一个词。所以我们所要做的就是在词汇表中生成一个超过 10-20k 个单词的概率分布。
但是在计算机视觉方面,可能性是无限的。我们在这里处理高维连续对象,例如,一个 10X10 的屏蔽图像块可能在单个通道上获取 255¹⁰⁰ 值,对于动起来的视频复杂性甚至更高(同样的逻辑也适用于语音识别)。与 NLP 不同,我们无法对每一种可能性做出预测,然后选择更高概率的预测。这似乎是计算机视觉中一个棘手的问题。
孪生网络/联合嵌入架构
这里把图像识别作为我们运行的任务。SSL 会屏蔽一些随机图像块,然后尝试预测这些被屏蔽的块。由于我们无法对图像块中的每一种可能性进行预测,所以我们只能使用相似度匹配。
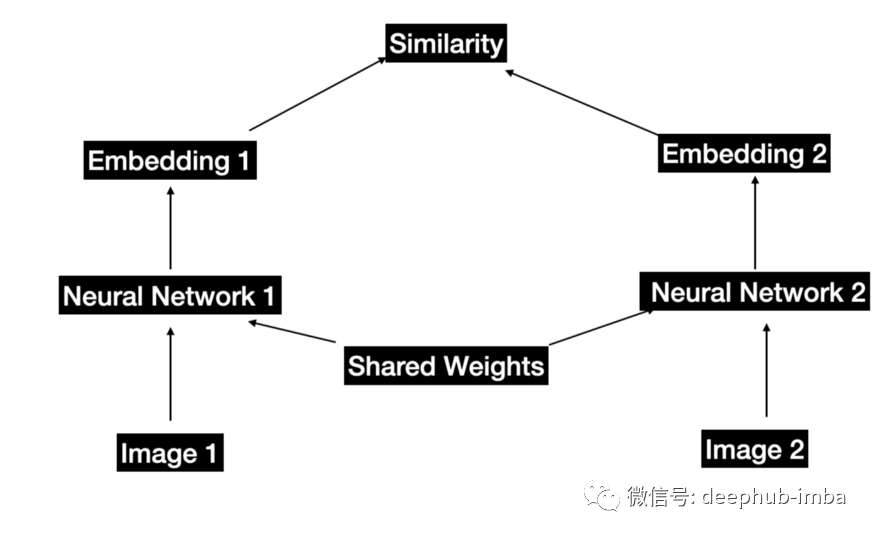

联合嵌入架构。这两个神经网络可以完全相同,也可以部分共享,也可以完全不同。
这个想法是训练一种孪生网络来计算两张图像之间的相似度,同时保证以下结果 –
- 相似/兼容的图像应该返回更高的相似度分数。
- 不同/不兼容的图像应返回较低的相似度分数。
第 1 点很容易实现 -可以用不同方式增强图像,例如裁剪、颜色增强、旋转、移动等。然后让 孪生网络学习原始图像和增强图像的相似表示。在将模型输出与固定目标进行比较的意义上,我们不再进行预测建模,因为现在比较的是模型的两个编码器的输出,这使得学习表示非常灵活。
但是第 2 点很麻烦。因为当图像不同时,我们如何确保网络学习不同的嵌入?如果没有进一步的激励,无论输入如何,网络都可以为所有图像学习相同的表示。这称为模式崩溃。那么如何解决这个问题?
对比学习 Contrastive Learning
基本思想是提供一组负样本和正样本。损失函数的目标是找到表示以最小化正样本之间的距离,同时最大化负样本之间的距离。图像被编码后的距离可以通过点积计算,这正是我们想要的!那么这是否意味着计算机视觉中的 SSL 现在已经解决了?其实还没有完全解决。
为什么这么说呢?因为图像是非常高维的对象,在高维度下遍历所有的负样本对象是几乎不可能的,即使可以也会非常低效,所以就衍生出了下面的方法。
在描述这方法之前,让我们首先来讨论对比损失这将会帮助我们理解下面提到的算法。我们可以将对比学习看作字典查找任务。想象一个图像/块被编码(查询),然后与一组随机(负 – 原始图像以外的任何其他图像)样本+几个正(原始图像的增强视图)样本进行匹配。这个样本组可以被视为一个字典(每个样本称为一个键)。假设只有一个正例,这意味着查询将很好地匹配其中一个键。这样对比学习就可以被认为是减少查询与其兼容键之间的距离,同时增加与其他键的距离。
目前对比学习中两个关键算法如下:
- Momentum Contrast – 这个想法是要学习良好的表示,需要一个包含大量负样本的大型字典,同时保持字典键的编码器尽可能保持一致。这种方法的核心是将字典视为队列而不是静态内存库或小批量的处理。这样可以为动态字典提供丰富的负样本集,同时还将字典大小与小批量大小解耦,从而根据需要使负样本变得更大。
- SimCLR – 核心思想是使用更大的批大小(8192,以获得丰富的负样本集),更强的数据增强(裁剪,颜色失真和高斯模糊),并在相似性匹配之前嵌入的非线性变换,使用更大模型和更长的训练时间。这些都是需要反复试验的显而易见的事情,该论文凭经验表明这有助于明显的提高性能。
但是对比学习也有局限性:
- 需要大量的负样本来学习更好的表示。
- 训练需要大批量或大字典。
- 更高的维度上不能进行缩放。
- 需要某种不对称性来避免常数解。
数据增强的有趣观察
在上面提到的所有方法/算法中,数据增强都起着关键作用。为了训练类似 SSL 模型,通过一组规则(裁剪、移动、旋转、颜色失真、模糊等)增强原始图像来生成正对。然后模型学会忽略这种噪声(例如平移、颜色失真和旋转不变性),以学习与正对(原始图像和增强图像)接近的表示。但是这些模型在图像识别任务上做得很好,但当模型已经学会忽略这些变化时,以相同的表示进行目标检测任务时会获得非常差的效果。这是因为它很难在对象周围放置边界框,因为学习的表示被训练为忽略目标对象的位置和定位。
非对比学习
与对比学习不同,模型仅从正样本中学习,即从图像及其增强视图中学习。
理论上上感觉这应该行不通,因为如果网络只有正例,那么它就学会忽略常量向量的输入和输出(上面提到的模式崩溃),这样损失就会变成0。
而实际上这并没有发生?模型学习到了良好的表示。为什么呢?下面通过描述该领域的一些关键算法来进行说明 :
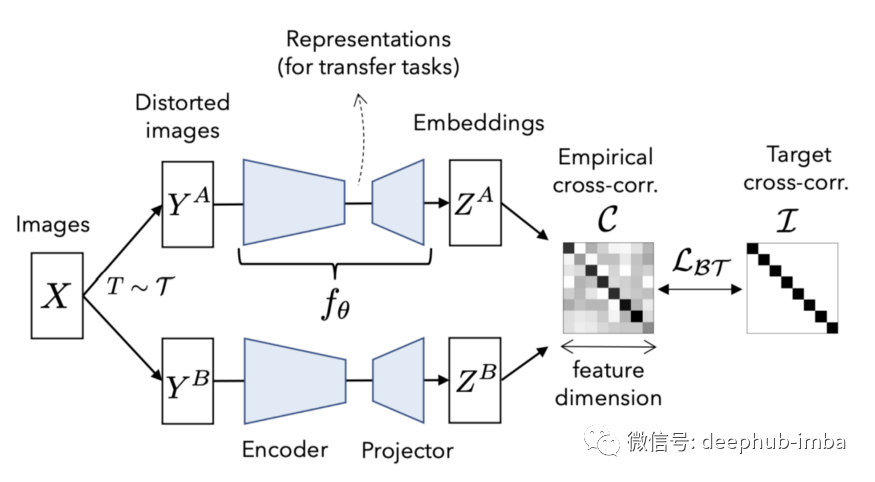
1、BARLOW TWINS:这是一种受神经科学启发的算法,基于 1961 年发表的论文的发现。它仍然使用如上所述的带有增强图像的联合嵌入式架构。但是它核心思想是使图像嵌入输出之间的互相关矩阵尽可能接近单位矩阵。这个简单的想法避免了复杂的解决方案,并获得了 ImageNet 上的 SOTA 性能。并且它在高维度上效果更好,不需要不对称,不需要大批量的数据或内存存储或任何其他启发式方法来使其工作。
下图解释了算法的整体架构。单个图像在增强策略的分布上被处理两次。然后两个图像都通过相同的编码器网络。损失函数的定义方式是将互相矩阵简化为单位矩阵。
损失函数非常直观
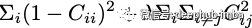
这里 C 是两个图像的嵌入之间的互相关矩阵。在这里没有使用任何负样本!
第一项,当所有 C_ii 为 1 即相关矩阵的对角元素为 1 时,损失函数中的不变项最小。这使得随着相关性的加强,嵌入对增强处理保持不变。第二项,即冗余缩减项强制非对角线值为 0,即它使嵌入的其他维度去相关。这使得模型在增强处理的同时学习有关样本的非冗余信息。
2、BYOL:这种方法不像 Barlow Twins 那样简单,因为它需要某些启发式方法才可以正常工作。它依赖于两个神经网络(target和 target),并试图从online 中预测target。两个网络中的权重不同。为了在架构中引入不对称性以避免琐碎的常量嵌入,target网络中引入了预测器模块。

本文中没有对BYOL进行像 BARLOW TWINS 清晰和直观的解释,所以如果想了解其详细内容请参考原论文:arxiv 2006.07733
另外还有一种最新的方法 VICReg(arxiv:2105.04906)如果有几乎的话会在后面介绍
总结
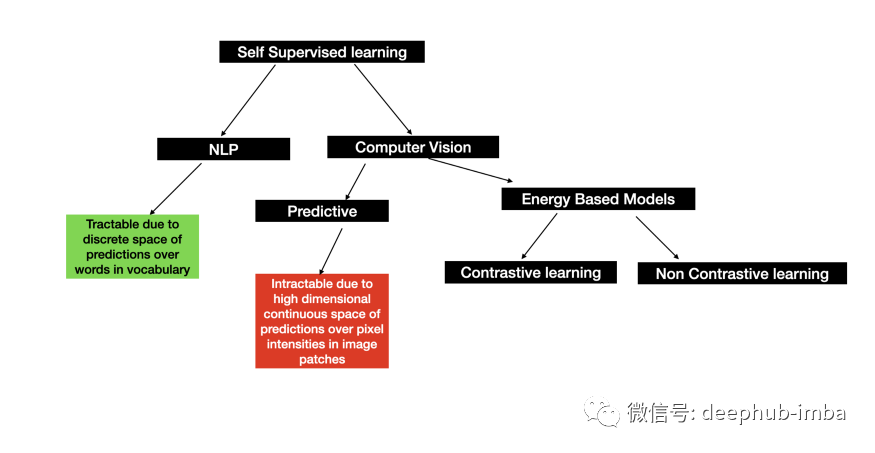
总结整篇文章,下图展示了 SSL 在 NLP 和计算机视觉中的细分。
最后就是引用:
- Lex Friedman interviewing Yann LeCun for 3 hours
- Zbontar, Jure, et al. “Barlow twins: Self-supervised learning via redundancy reduction.” International Conference on Machine Learning. PMLR, 2021.
- Grill, Jean-Bastien, et al. “Bootstrap your own latent-a new approach to self-supervised learning.” Advances in Neural Information Processing Systems 33 (2020): 21271–21284.
- He, Kaiming, et al. “Momentum contrast for unsupervised visual representation learning.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020
- Chen, Ting, et al. “A simple framework for contrastive learning of visual representations.” International conference on machine learning. PMLR, 2020.
- Yann LeCun’s blog on self supervised learning
- Ermolov, Aleksandr, et al. “Whitening for self-supervised representation learning.” International Conference on Machine Learning. PMLR, 2021.
- Chen, Xinlei, and Kaiming He. “Exploring simple siamese representation learning.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
- Caron, Mathilde, et al. “Deep clustering for unsupervised learning of visual features.” Proceedings of the European conference on computer vision (ECCV). 2018.
10.https://www.overfit.cn/post/c6185b513a564c6cb5022abe0bafcbec
作者:Sharad Joshi
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/193927.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
