大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
目录
[1] 2015 (ICCV) Unsupervised Learning of Visual Representations Using Videos
[2] 2015 (ICCV) Unsupervised Visual Representation Learning by Context Prediction
[3] 2016 (ECCV) Unsupervised learning of visual representations by solving jigsaw puzzles
[4] 2016 (CVPR) Deepak Pathak et al. Context Encoders: Feature Learning by Inpainting
[5] 2016 (ECCV) A Colorful image colorization
[6] 2017 (CVPR) Split-Brain Autoencoders: Unsupervised Learning by Cross-Channel Prediction
[7] 2018 (ICLR) Unsupervised Representation Learning by Predicting Image Rotations
[8] 2017 (ICCV) Unsupervised Representation Learning by Sorting Sequences
[9] 2018 (Google) (ICRA) Time-Contrastive Networks: Self-Supervised Learning from Video
[10] 2018 (DeepMind) (Arxiv) (CPC) Representation Learning with Contrastive Predictive Coding
[13] 2020 (Hinton) (Arxiv) Big Self-Supervised Models are Strong Semi-Supervised Learners
[14] 2020 (Google) (Arxiv) Supervised Contrastive Learning
[15] 2020 (CVPR) [MoCo] Momentum Contrast for Unsupervised Visual Representation Learning
1. 什么是自监督学习?
实际的场景里通常有海量的无监督数据,而有监督数据却很少。那么能否利用这些海量的无监督数据,用来改进监督学习任务的效果呢?
▲自监督学习(Self-supervised Learning)作为Unsupervised Learning的一个重要分支,给出了很好地解决方案。它的目标是更好地利用无监督数据,提升后续监督学习任务的效果。
其基本思想是:Predicting everything from everything else。
具体方法是 1.首先定义一个Pretext task (辅助任务),即从无监督的数据中,通过巧妙地设计自动构造出有监督(伪标签)数据,学习一个预训练模型。构造有监督(伪标签)数据的方法可以是:假装输入中的一部分不存在,然后基于其余的部分用模型预测缺失的这部分。如果学习的预训练模型能准确预测缺失部分的数据,说明它的表示学习能力很强,能够学习到输入中的高级语义信息、泛化能力比较强。而深度学习的精髓正在于强大的表示学习能力。
2.然后可以将预训练模型,通过简单的Finetune,应用到下游的多个应用场景,能比只使用监督数据训练的模型有更好的效果。
▲通常来说有标签数据越少的场景,自监督学习能带来的提升越大。事实上,在一些论文的实验结果里,在大量无标签数据上自监督学习的模型,不需要finetune,能取得比使用标签数据学得的监督模型更好的效果……
对于有大量标签数据的场景,自监督学习也能进一步提升模型的泛化能力和效果。
▲下图展示了在CV领域自监督学习的标准流程:
在自监督学习中,最重要的问题是:如何定义Pretext task、如何从Pretext task学习预训练模型。
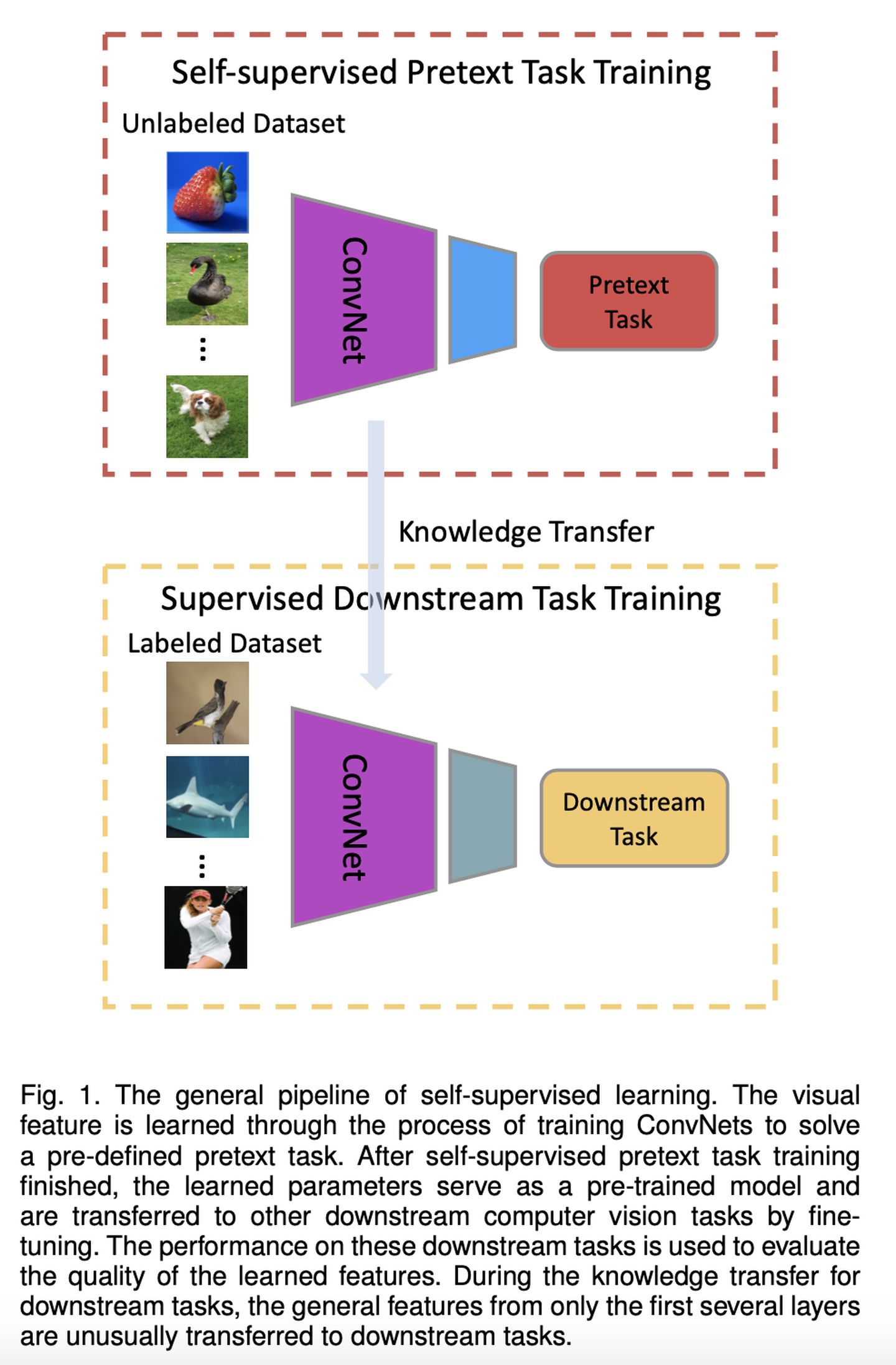

Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey
2. 为什么自监督学习是AI的未来?
Yann Lecun在AAAI 2020的演讲中,指出目前深度学习遇到的挑战:
▲监督学习:深度模型有海量参数,需要大量的label数据,标注成本高、扩展性差,难以应用到无标记或标记数据少的场景。
▲强化学习:agent需要和环境大量的交互尝试,很多实际场景(例如互联网搜索推荐、无人驾驶)中交互成本大、代价高,很难应用。
而人类和动物学习快速的原因:最重要的是观察世界,而不是靠大量的监督、强化学习。

智能的精髓在于预测:我们通过观察世界、理解世界、尝试预测未来,并根据实际结果的反馈信息,来不断调整自己的世界模型,变得越来越有智能。简单来说,无论人还是机器,预测的准确度越高,说明智能越强。
自监督学习的思想就是通过构造任务来提升预训练模型预测能力,即Predicting everything from everything else。具体方法是假装输入中的一部分不存在,然后基于其余的部分用模型预测这个部分,从而学习得到一个能很好地建模输入语义信息的表示学习模型。
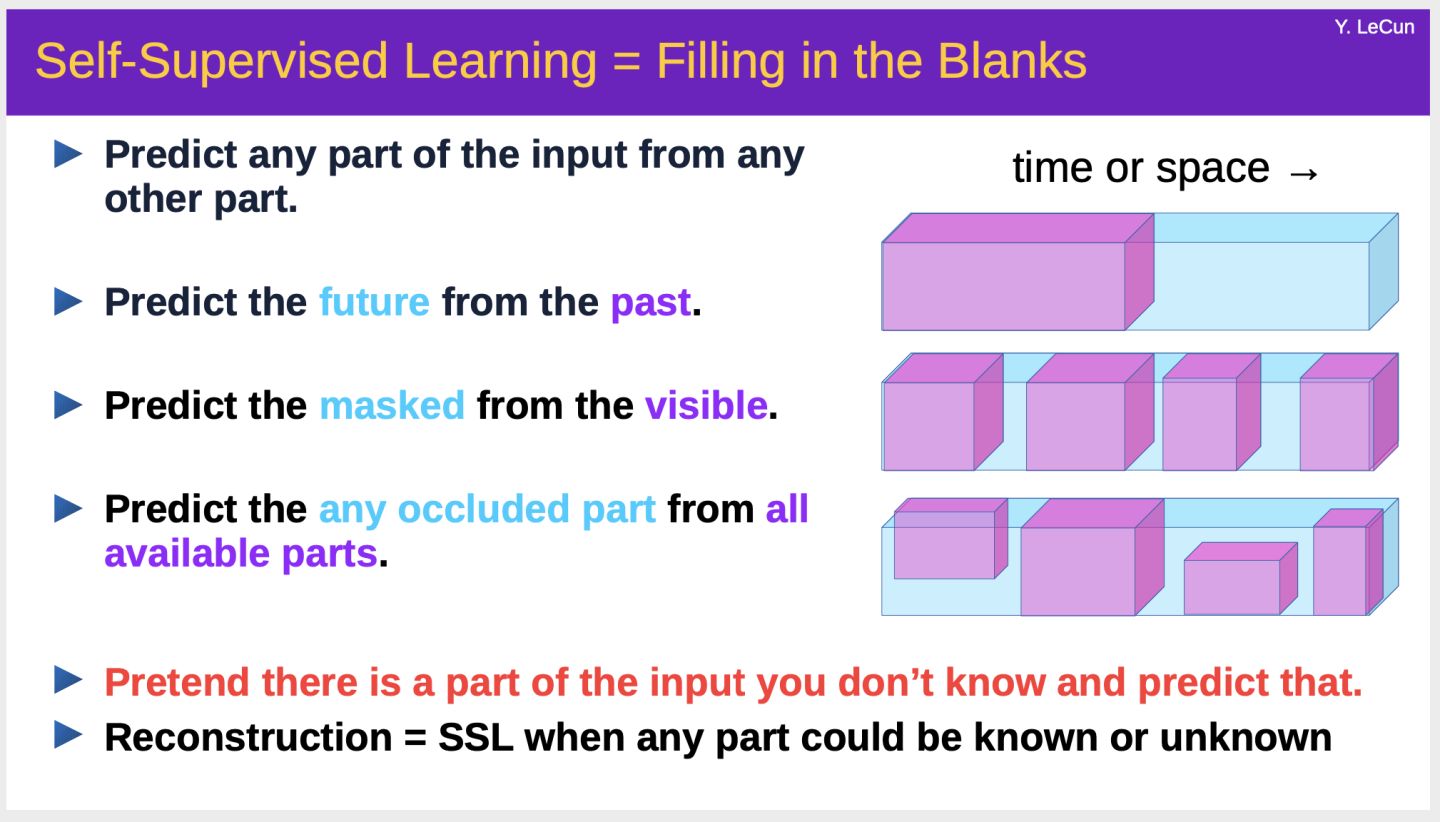
例如,在NLP中,自监督学习Word2Vec、BERT、GPT、GPT2、GPT3等模型,可以很好地应用到语言模型、机器翻译、对话系统等多个任务中。
在CV中,自监督学习SimCLR等模型,可以应用到图像分类、补全等任务。
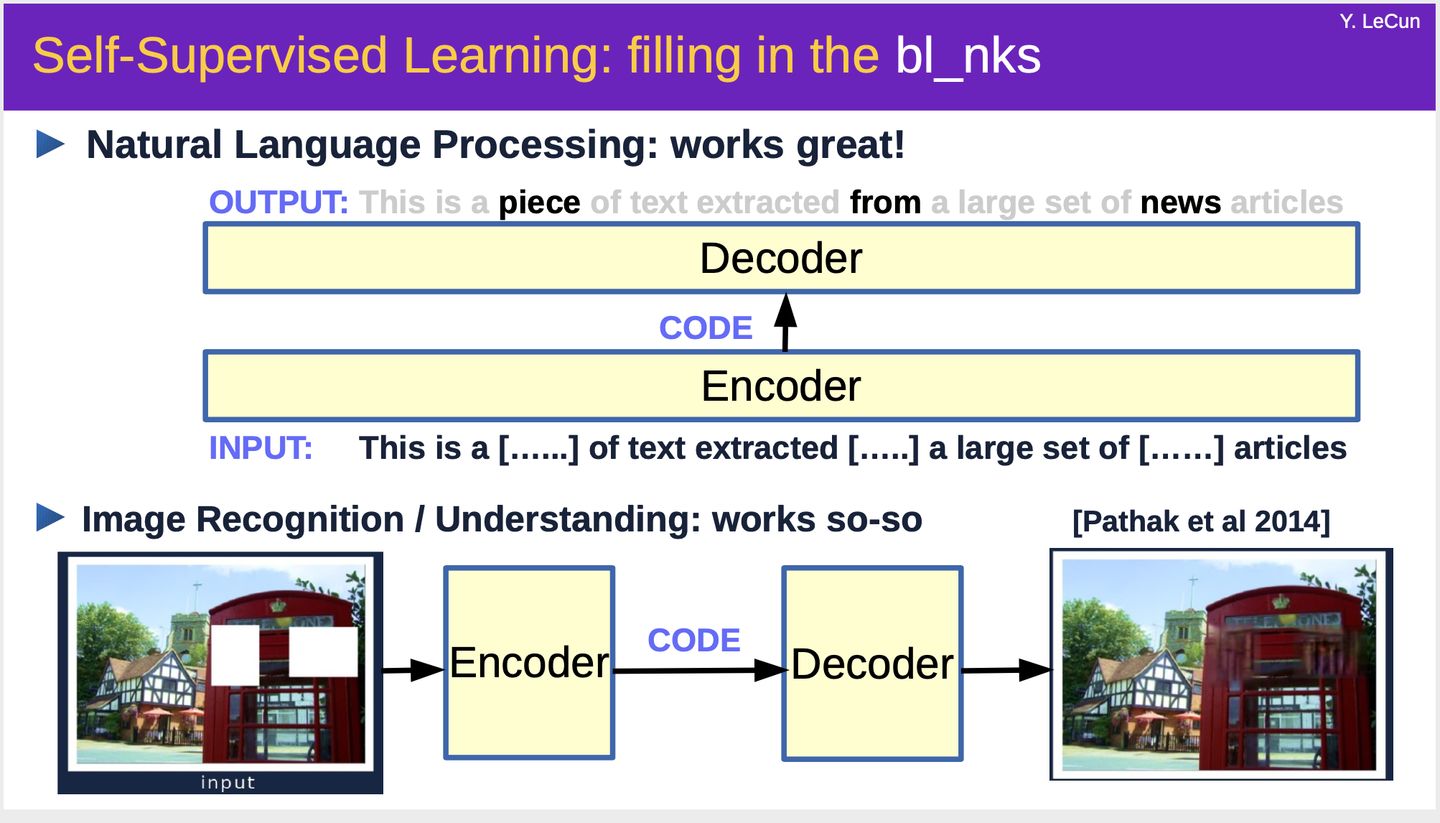
Yann LeCun
关于机器学习的作用,LeCun做了一个形象的比喻,如下图所示:强化学习像蛋糕上的樱桃,监督学习像蛋糕上的糖霜,而自监督学习是蛋糕本身。
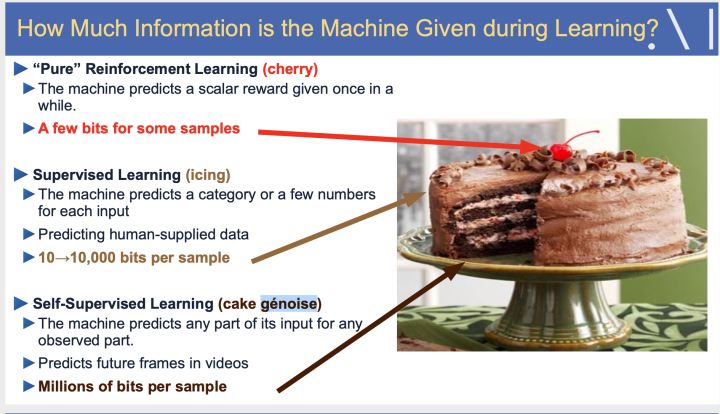
Yann LeCun
通过这个比喻,可以很好的理解自监督学习在人工智能中的重要基石作用。
数据时代,很有前景的人工智能的实现方式是:
- 在底层,首先基于海量的无标签数据,利用自监督学习,学习得到一个强大的通用表示模型。
- 在上层,基于监督学习实现具体任务的目标、基于强化学习实现智能控制。
自监督学习的作用在于,可以增强监督学习和强化学习模型的性能、泛化能力、鲁棒性等。
事实上,在CV、NLP等人工智能领域,自监督学习已经开始发挥着至关重要的作用。
3.1 Computer Vision:
CV领域中,自监督学习的Pretext task 可以是预测图片相对位置信息、旋转角度、视频中帧的顺序等。
[1] 2015 (ICCV) Unsupervised Learning of Visual Representations Using Videos
ICCV 2015这篇论文的思想是:视频场景,对物体跟踪,对于一个包含物体o的帧X,包含物体o的另外一个帧 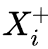 应该比一个随机的帧 和X的相似度更高。
应该比一个随机的帧 和X的相似度更高。
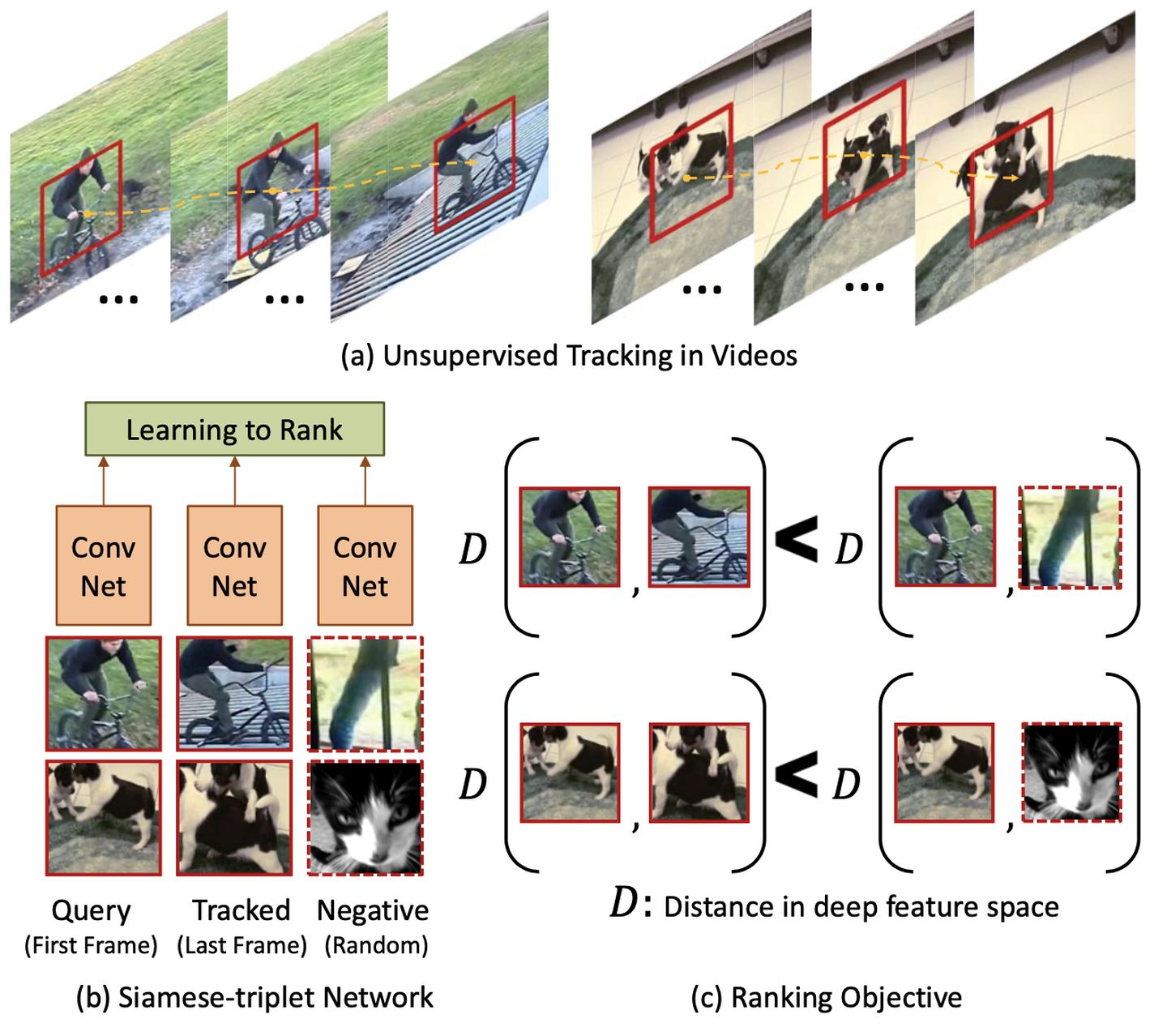
这篇论文里使用CNN作为Encoder, 对于图片X,f代表CNN,f(X)为X新的表示向量,定义两个图片的距离为如下:
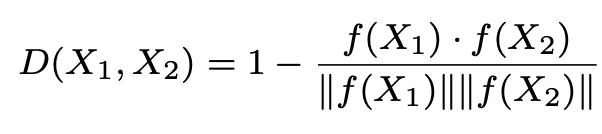
然后就可以基于hinge loss来学习CNN的参数了:
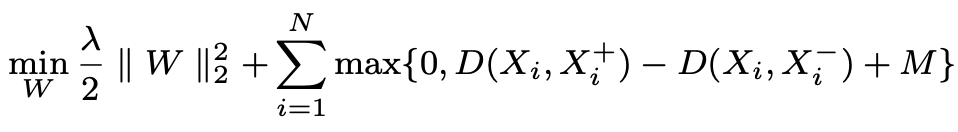
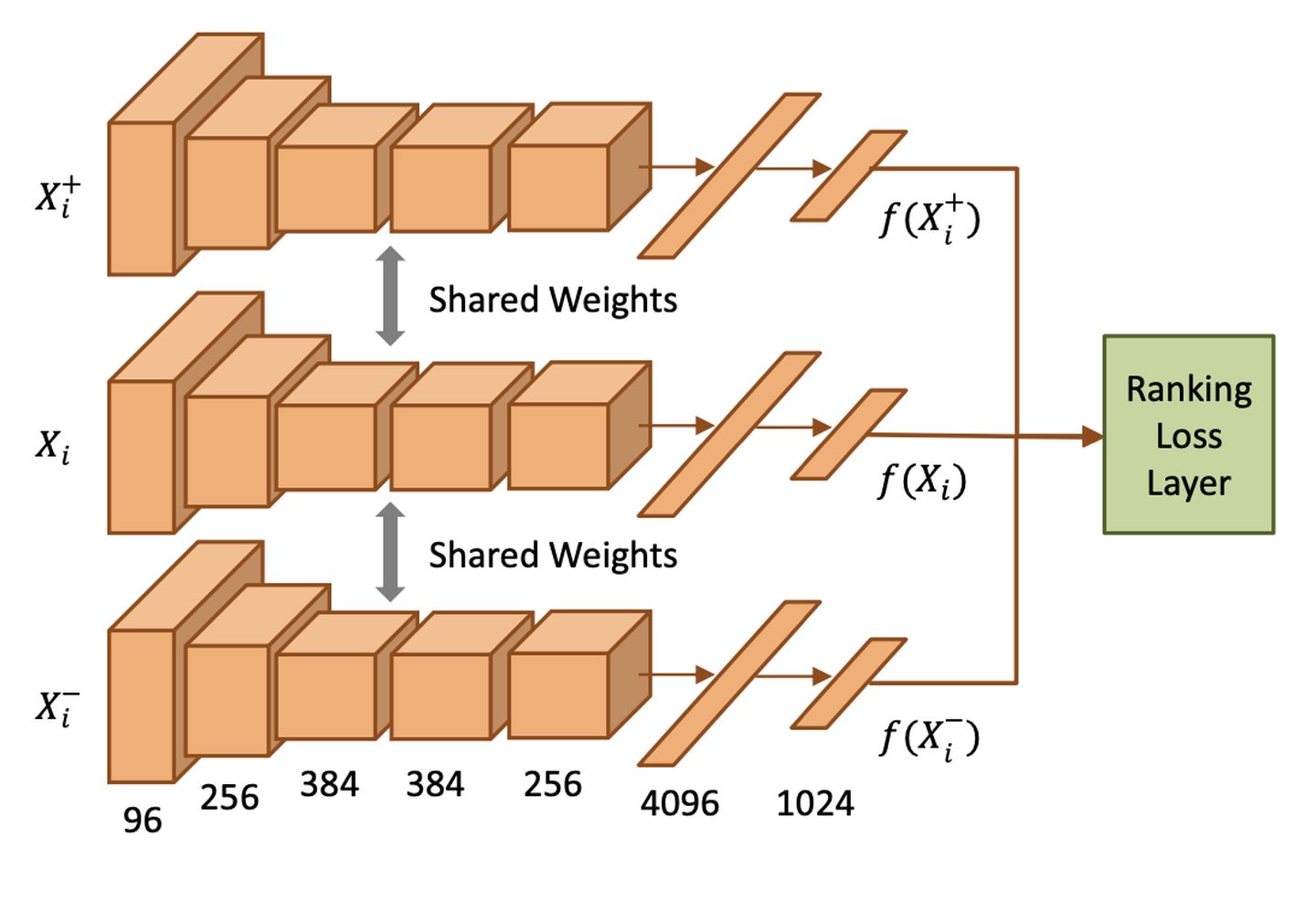
学习完CNN参数,就可以将它作为表示学习器(特征抽取器),应用到后续的其他CV任务了。这篇论文里,作者对比了基于100k无标签的视频无监督预训练CNN,和基于ImageNet千万级的监督数据预训练CNN,在后续的CV任务中取得了很接近的效果。
[2] 2015 (ICCV) Unsupervised Visual Representation Learning by Context Prediction
ICCV 2015这篇论文里,构造训练数据的方法是:随机从图片采样一个patch,然后从它的邻居里随机采样一个patch,监督标签对应是邻居的位置信息。作者认为,准确地预测两个patch的位置关系,需要模型学会物体整体和部分的关系。
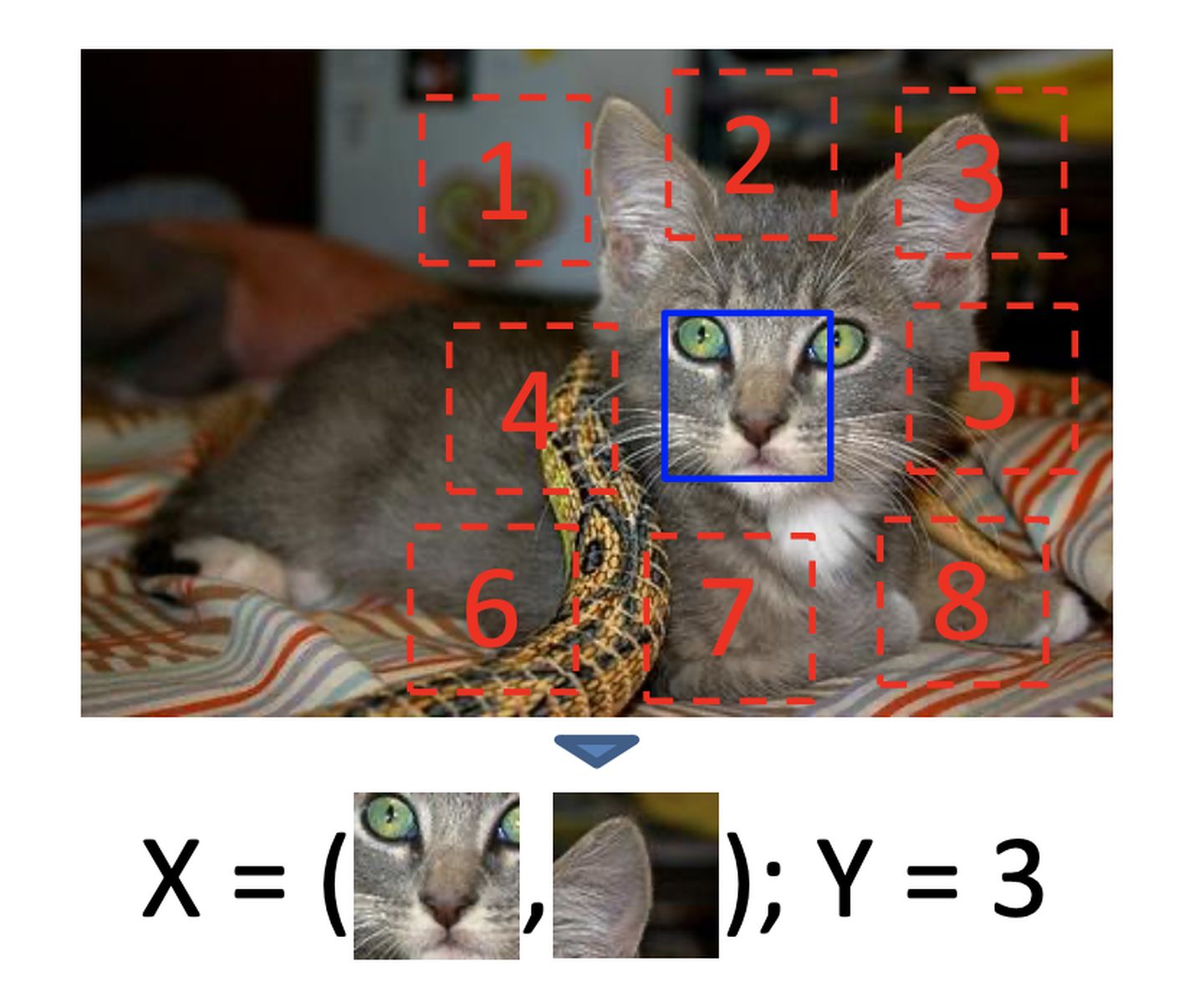
[3] 2016 (ECCV) Unsupervised learning of visual representations by solving jigsaw puzzles
EECV 2016这篇论文里,自监督的方法是:学习解决Jigsaw Puzzles(拼图)问题。随机打乱图片位置,学习恢复拼图,即生成原有图片的顺序。
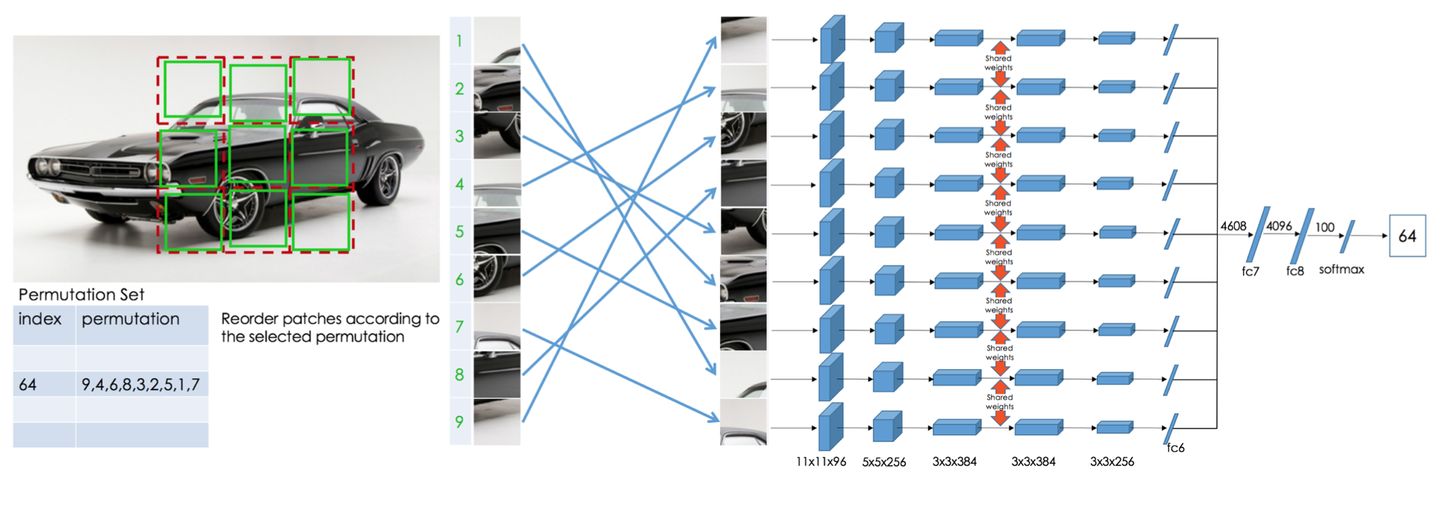
[4] 2016 (CVPR) Deepak Pathak et al. Context Encoders: Feature Learning by Inpainting
CVPR 2016这篇论文里,自监督的方法是:学习恢复图片缺失部分。

[5] 2016 (ECCV) A Colorful image colorization
ECCV 2016这篇论文里,自监督的方法是:由黑白图片生成彩色图片。

[6] 2017 (CVPR) Split-Brain Autoencoders: Unsupervised Learning by Cross-Channel Prediction
CVPR 2017这篇论文里,学习使用输入的一个channel取预测另一个channel。
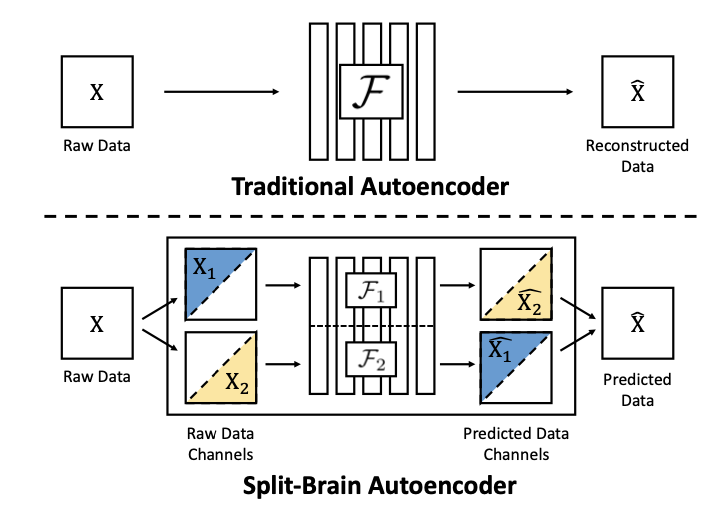

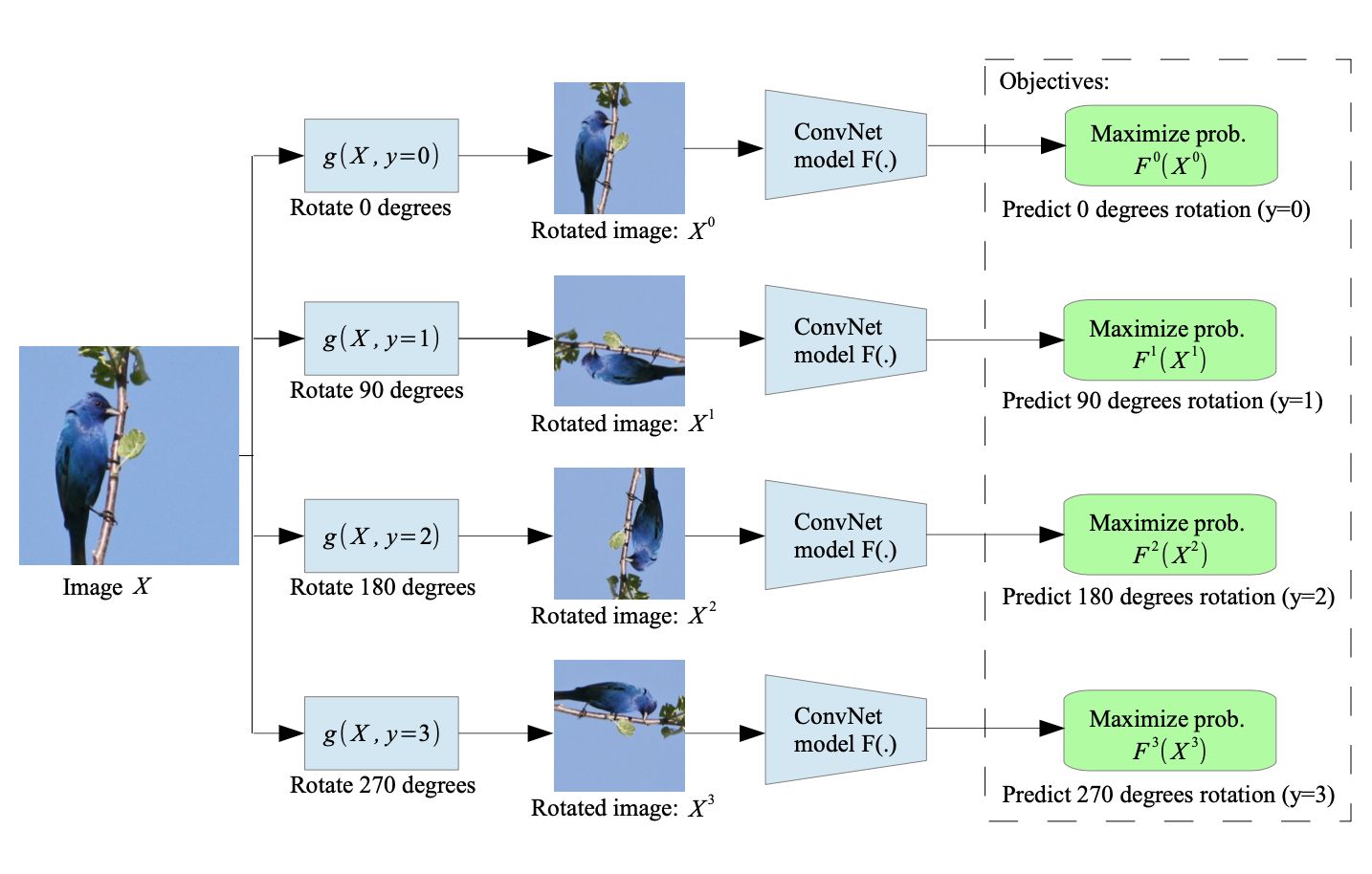
[7] 2018 (ICLR) Unsupervised Representation Learning by Predicting Image Rotations
2018 ICLR这篇论文里,采取的自监督的方法是:预测图片的旋转角度。
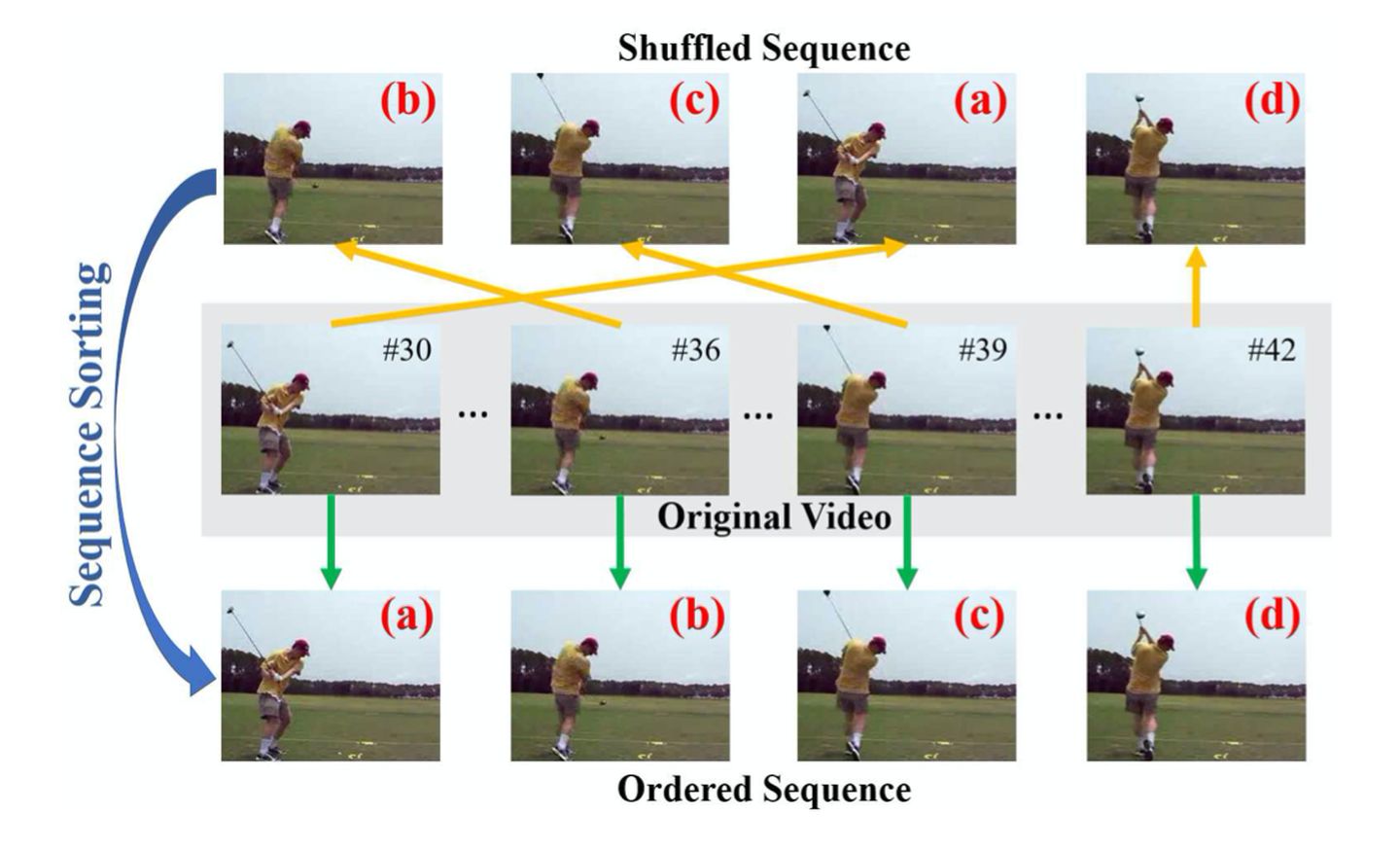
[8] 2017 (ICCV) Unsupervised Representation Learning by Sorting Sequences
ICCV 2017 这篇论文里,采取的自监督的方法是:随机打乱视频帧,然后学习对它们排序。
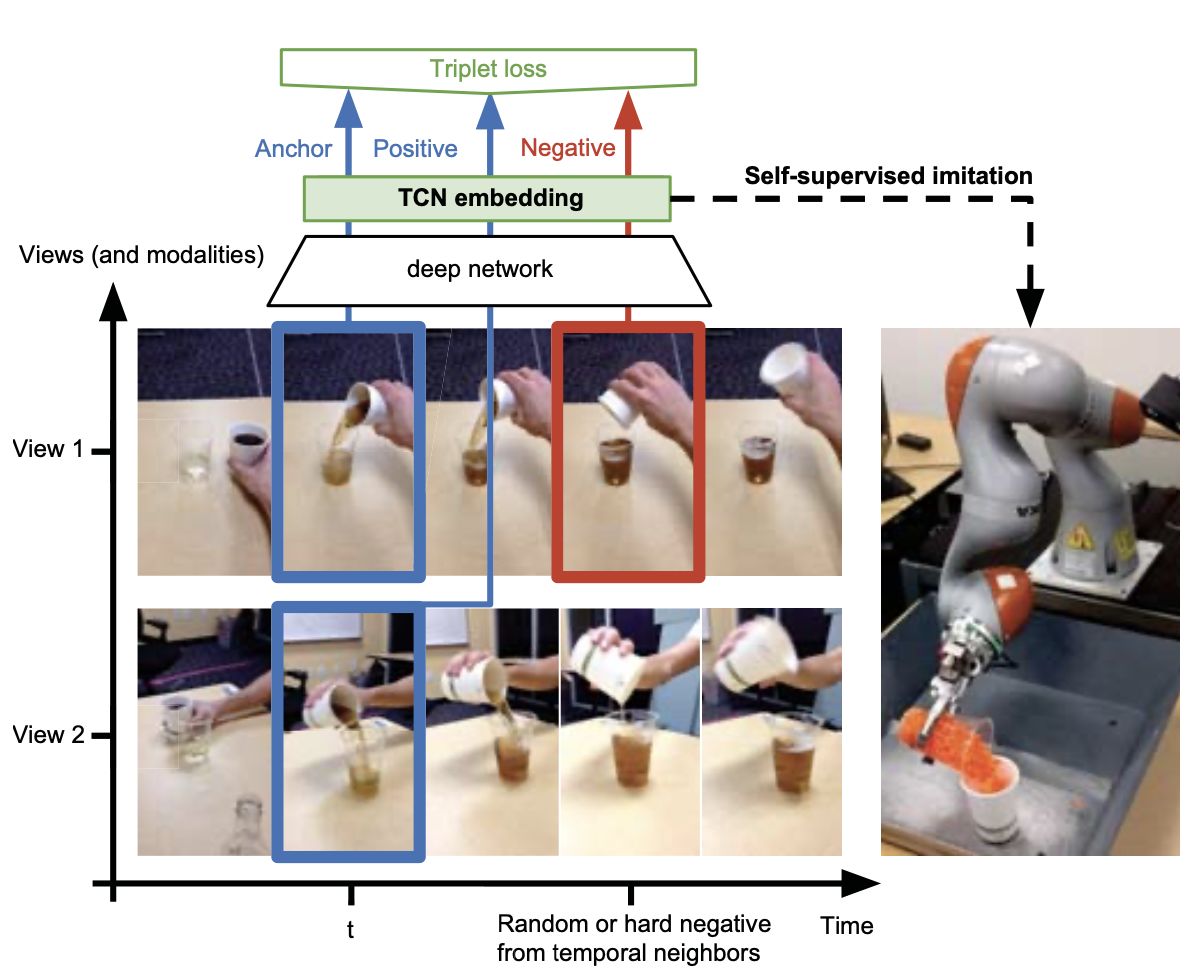
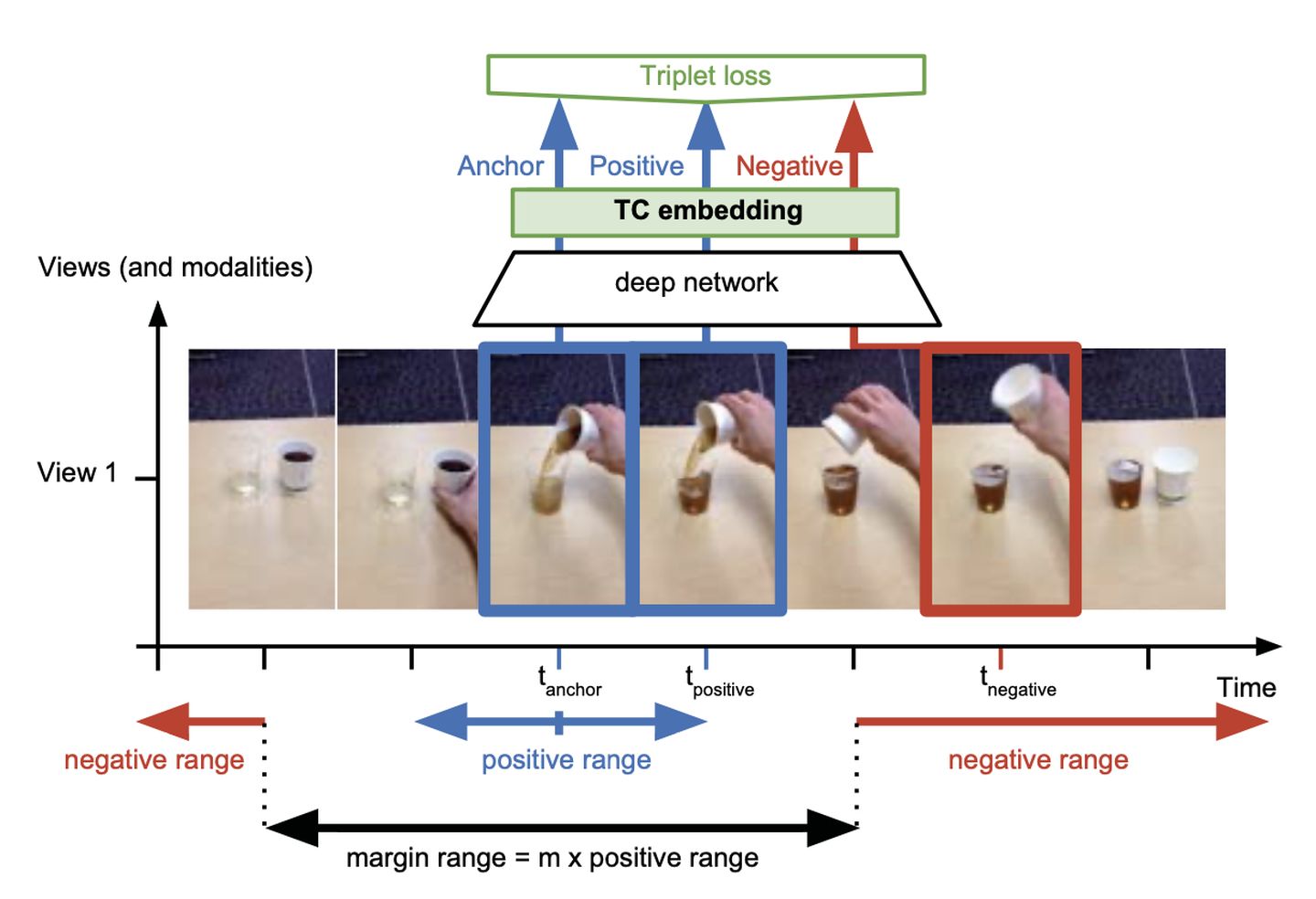
[9] 2018 (Google) (ICRA) Time-Contrastive Networks: Self-Supervised Learning from Video
ICRA 2018这篇论文里,采取的自监督的方法是:从视频里取一帧,然后选临近的帧作为正例,随机的离得远的帧作为负例,来学习DNN网络,然后结合强化学习,应用到机器人控制。
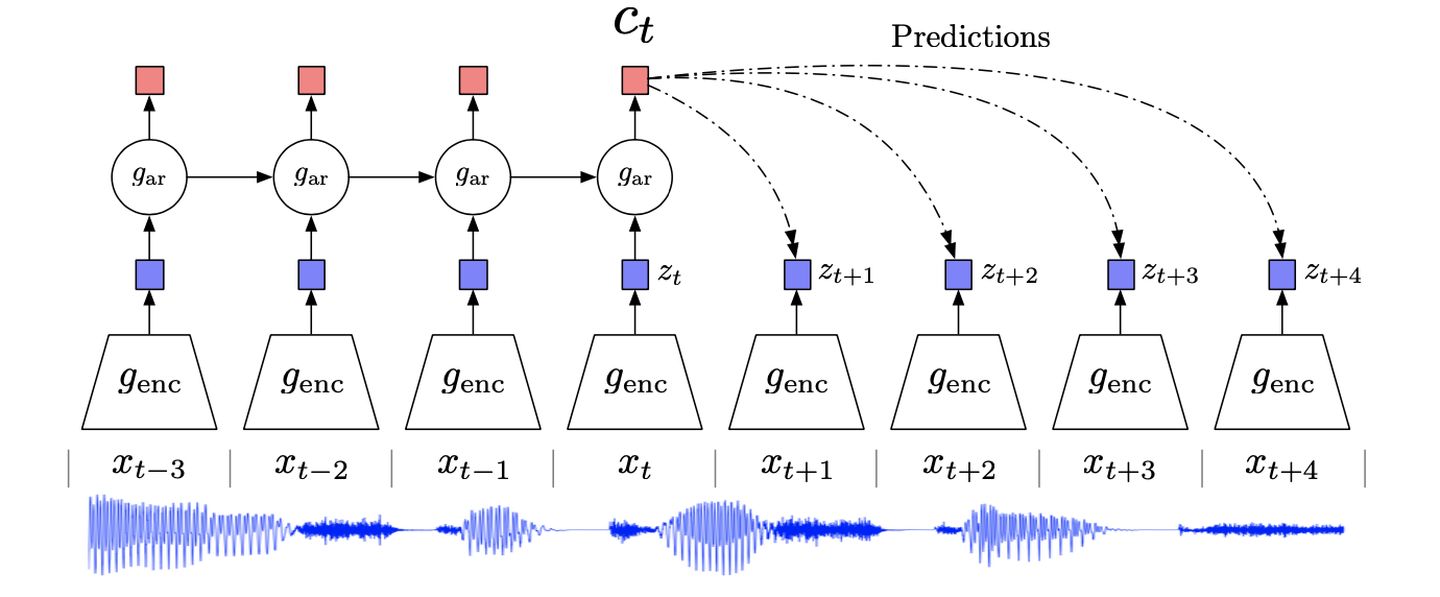
[10] 2018 (DeepMind) (Arxiv) (CPC) Representation Learning with Contrastive Predictive Coding
2018年DeepMind提出CPC,基本的思想是context信息能用来预测target的原因是,context的high-level表示是自回归依赖的。所以可以对输入x通过编码器encode到high-level表示,然后在high-level表示层学习出 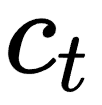 ,用来进行预测。
,用来进行预测。
优化的目标是x和c的Mutual Information最大:
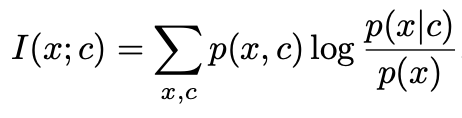
直接通过生成模型用 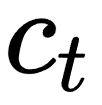 预测未来的 比较困难, 所以作者定义了概率密度来保持 和 的互信息:
预测未来的 比较困难, 所以作者定义了概率密度来保持 和 的互信息:
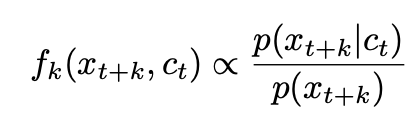
作者采用的公式是:
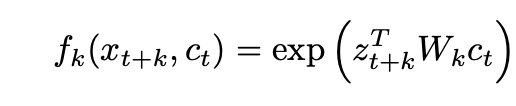
作者使用InfoNCE loss来优化,使Mutual Information最大:
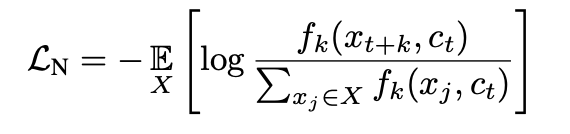
其中X为N个随机sample,包含1个正例和N-1个负例。
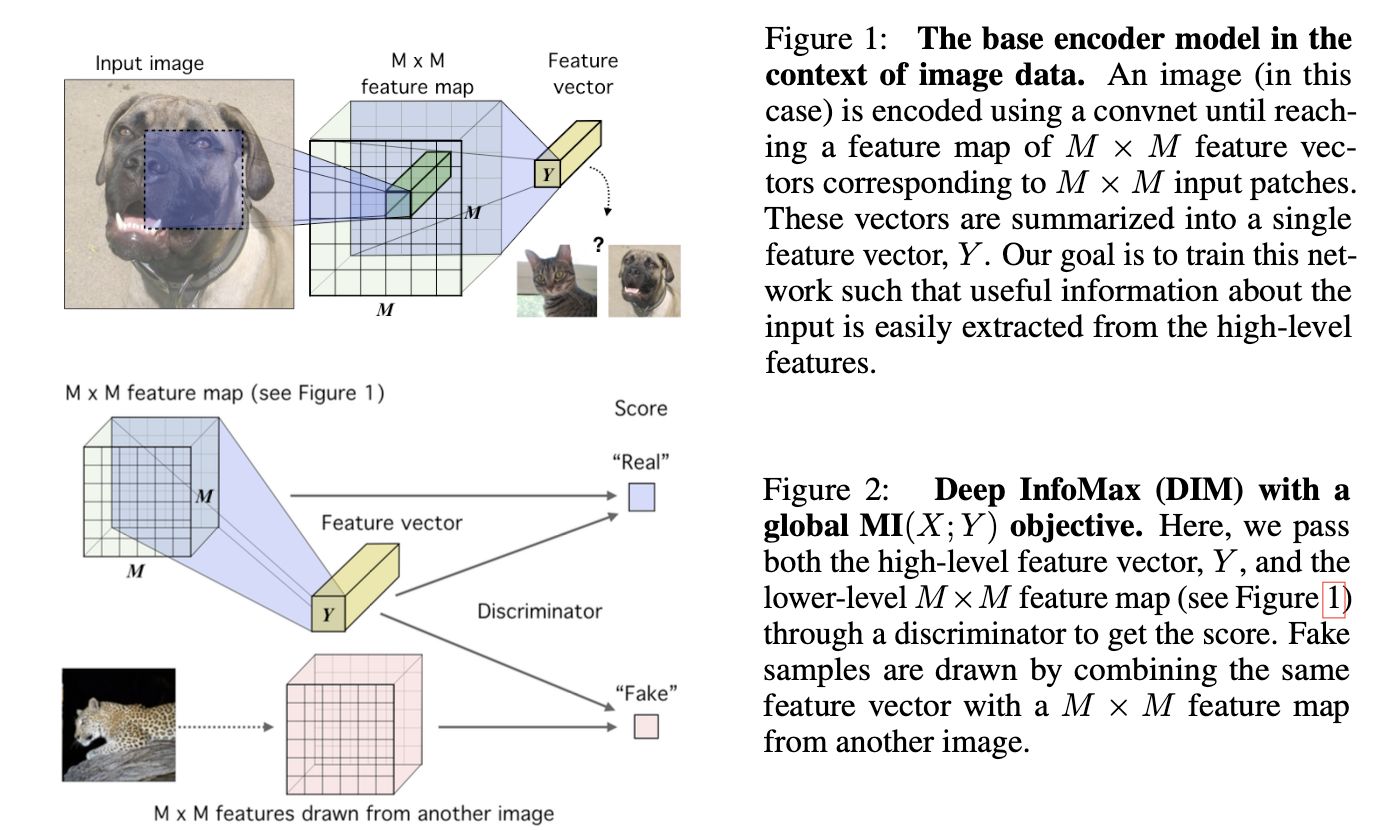
[11] 2019 (ICLR) [DIM] Learning deep representations by mutual information estimation and maximization
[12] 2020 (Hinton) (ICML) [SimCLR] A Simple Framework for Contrastive Learning of Visual Representations
Hinton等人,在这篇论文里提出SimCLR:
对一个输入x,首先通过两次独立的数据增强生成两个样本,然后分别通过编码器,再分别通过投影:
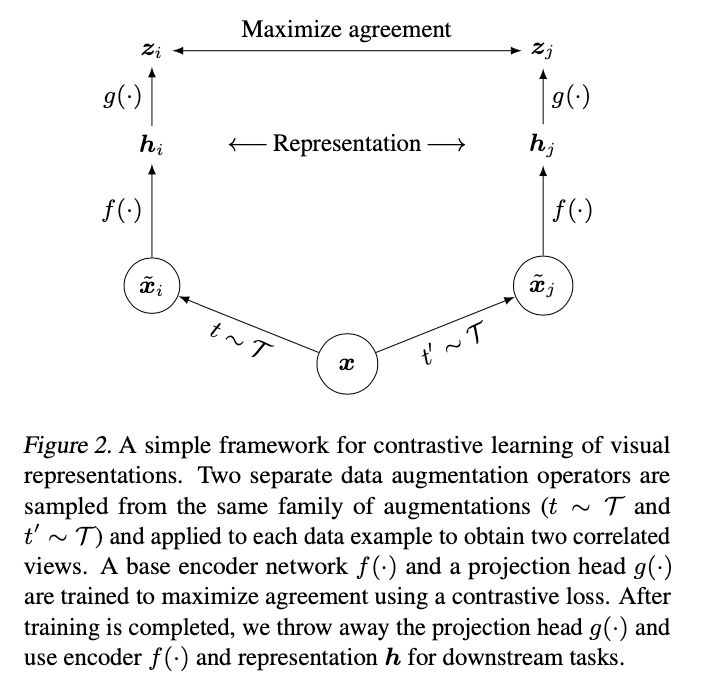
最后在投影空间定义对比loss,其中负样本从batch中的其他图片:
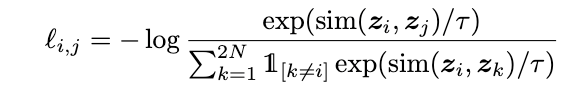
[13] 2020 (Hinton) (Arxiv) Big Self-Supervised Models are Strong Semi-Supervised Learners
Hinton等人在这篇论文里,首先在大量无监督数据上自监督学习task-agnostic的encoder,然后基于少量的label数据finetune,再通过蒸馏技术,利用无监督的标签或有标签数据,学习得到更强的task-specific的encoder,对面向具体任务的迁移学习很有指导意义。
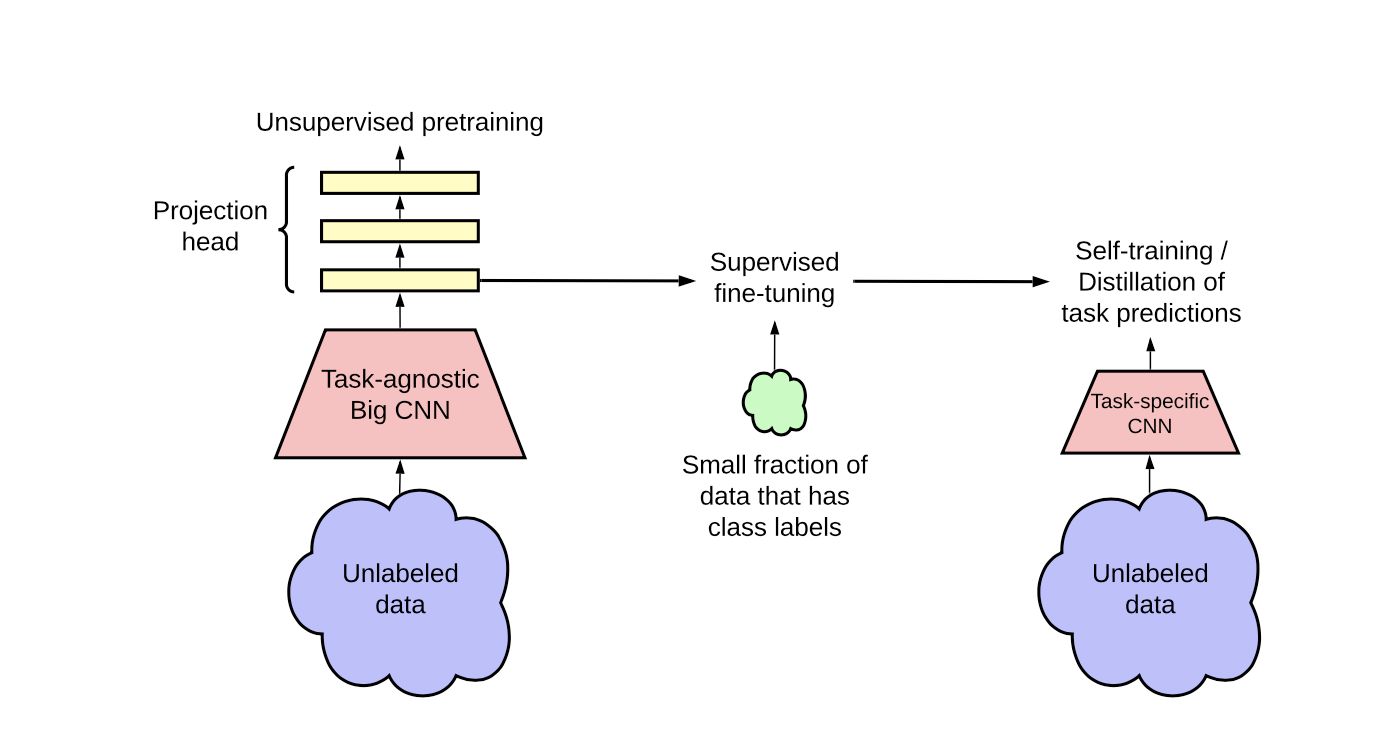
Distillation:
无标签数据:
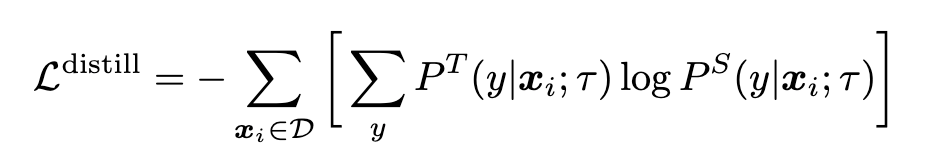
无标签数据+标签数据:
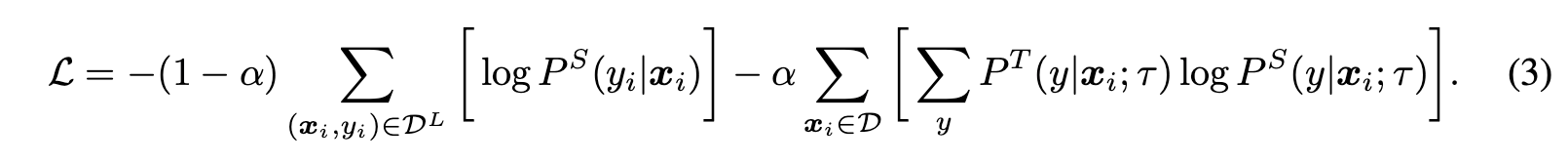
[14] 2020 (Google) (Arxiv) Supervised Contrastive Learning
一般自监督学习,对每个anchor,一般是一个positive, 多个negative。这篇论文里,提出在学习时,使用多个positive和多个negative一起学习。
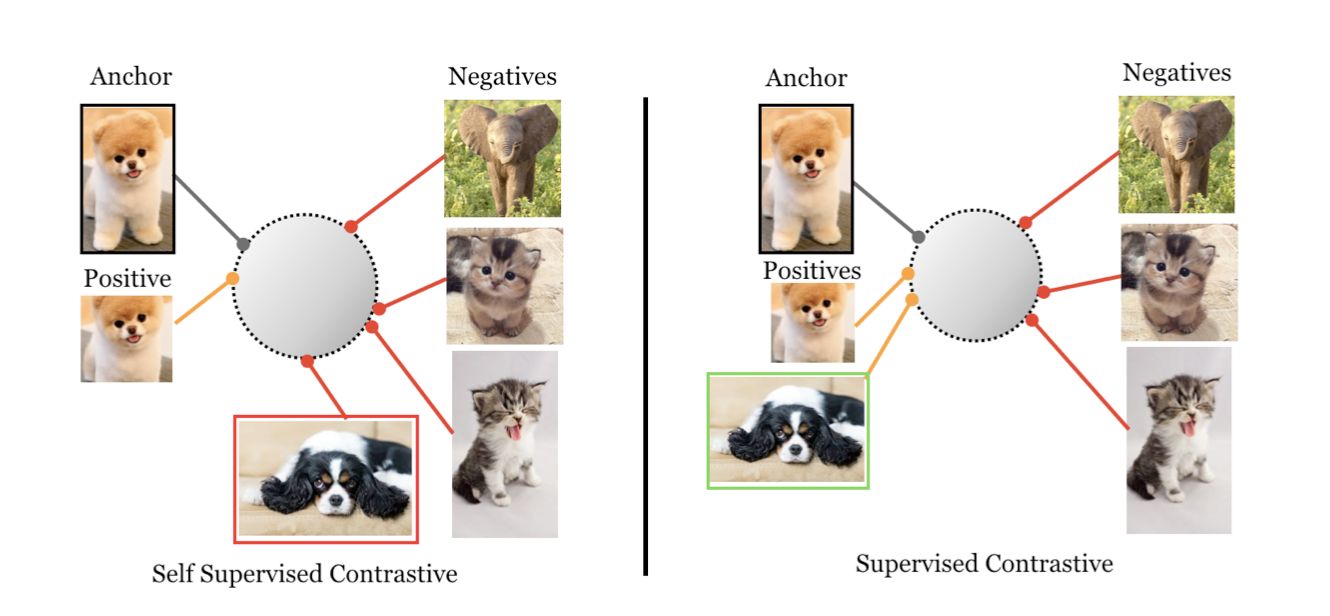
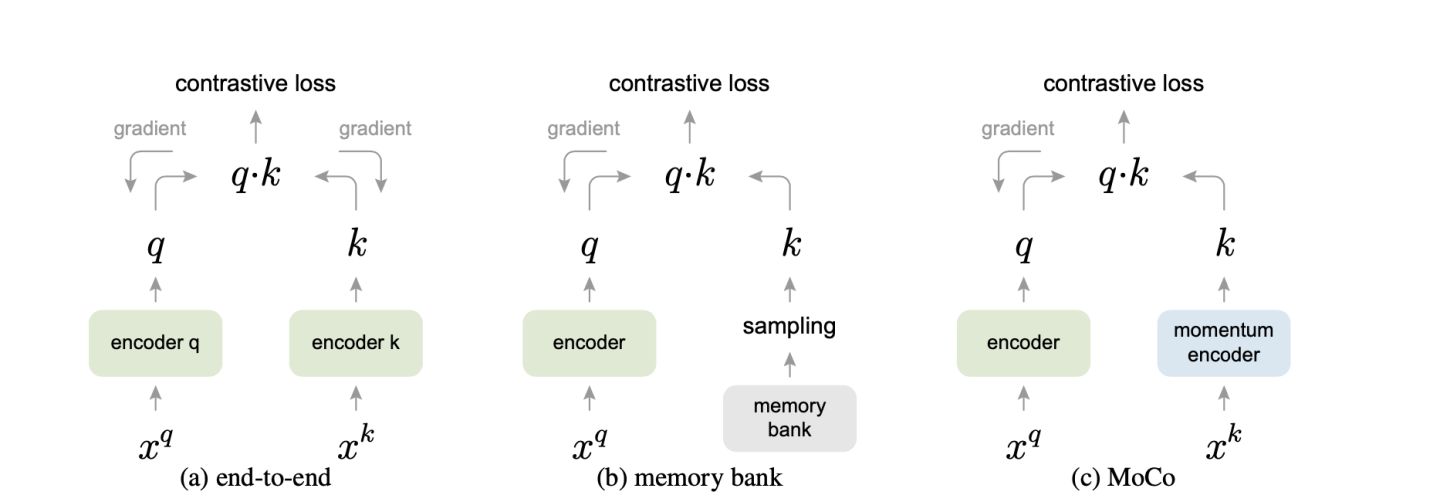
[15] 2020 (CVPR) [MoCo] Momentum Contrast for Unsupervised Visual Representation Learning
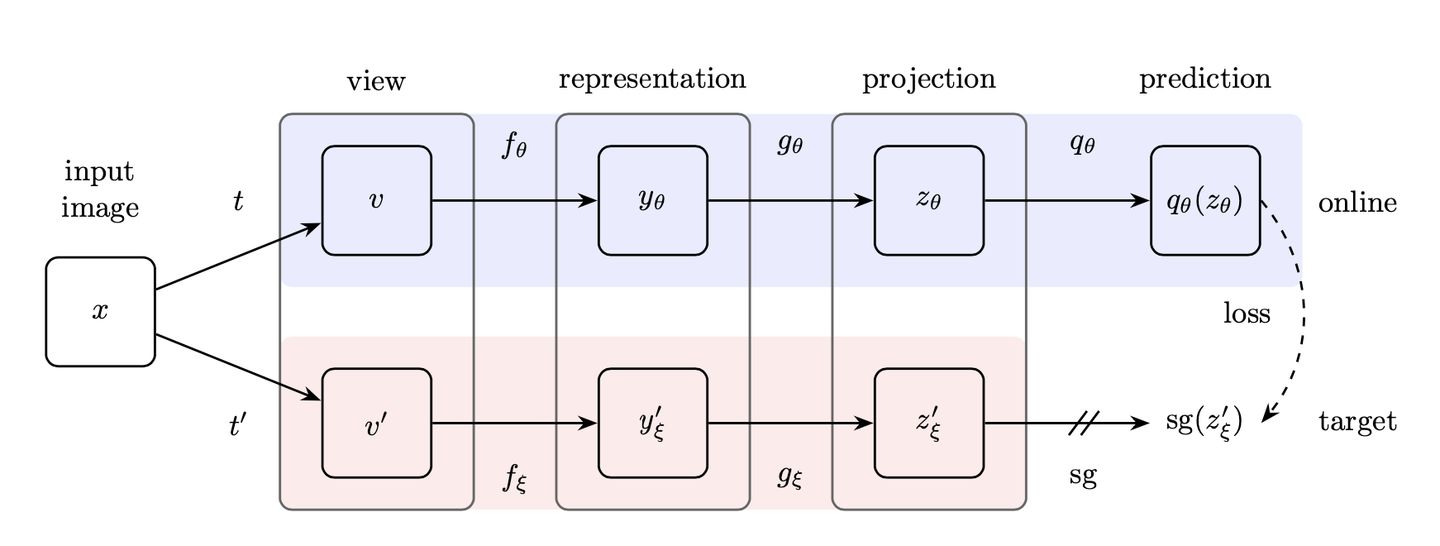
[16] 2020 (DeepMind) (Arxiv) [BYOL] Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
一般自监督学习,需要负样本。这篇论文里,DeepMing的作者提出了BYOL,不需要负样本,也能自监督学习。
3.6 Survey:
自监督学习的综述论文:
[47] 2020 (Arxiv) Self-supervised Learning: Generative or Contrastive.
[48] 2020 (T-PAMI) Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey
3.7 More Materials:
Github:
Facebook: https://github.com/facebookresearch/fair_self_supervision_benchmark
blogs:
https://lilianweng.github.io/lil-log/2019/11/10/self-supervised-learning.html
Talks:
Self-Supervised Learning. Yan Lecun. AAAI 2020. [pdf]
Graph Embeddings, Content Understanding, & Self-Supervised Learning. Yann LeCun. (NYU & FAIR) [pdf]
Self-supervised learning: could machines learn like humans? Yann LeCun @EPFL.
后记:
Self-supervised Learning在CV、NLP、Graph、RL、RecSys等领域已经取得了很awesome的效果。如何更好的挖掘无标签数据中的知识?如何和有监督数据更好地结合学习?仍然都是开放的问题,通过已有的研究工作,我们有充足的理由相信:
Self-supervised Learning is the future of AI!
本文介绍的论文集合:
https://github.com/guyulongcs/Awesome-Self-supervised-Learning-papers
raw article:自监督学习: 人工智能的未来 – 知乎
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/193865.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
