大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
原 文:A Survey of Contrastive Self-Supervised Learning
译 者:Xovee
翻译时间:2020年12月24日
译者注:本文为综述之综述。
对比自监督学习综述
作者:Ashish Jaiswal, Ashwin Ramesh Babu, Mohammad Zaki Zadeh, Debapriya Banerjee, Fillia Makedon
单位:德克萨斯大学阿林顿分校
时间:2020年12月22日
文章目录
摘要
自监督学习(Self-supervised learning)最近获得了很多关注,因为其可以避免对数据集进行大量的标签标注。它可以把自己定义的伪标签当作训练的信号,然后把学习到的表示(representation)用作下游任务里。最近,对比学习被当作自监督学习中一个非常重要的一部分,被广泛运用在计算机视觉、自然语言处理等领域。它的目标是:将一个样本的不同的、增强过的新样本们在嵌入空间中尽可能地近,然后让不同的样本之间尽可能地远。这篇论文提供了一个非常详尽的对比自监督学习综述。我们解释了在对比学习中常用的前置任务(pretext task),以及各种新的对比学习架构。然后我们对不同的方法做了效果对比,包括各种下游任务例如图片分类、目标检测、行为识别等。最后,我们对当前模型的局限性、它们所需要的更多的技术、以及它们未来的发展方向做了总结。
关键词
- 对比学习 contrastive learning
- 自监督学习 self-supervised learning
- 判别学习 discriminative learning
- 图片/视频分类 image/video classification
- 目标检测 object detection
- 无监督学习 unsupervised learning
- 迁移学习 transfer learning
1. 介绍
深度学习从大量数据中自动学习的能力使其在各种领域广泛应用,例如CV和NLP。
但是深度学习也有其瓶颈,就是它需要大量的人工标注的标签。
例如在计算机视觉中,监督模型需要在图片的表示和图片的标签之间建立关联。
传统的监督学习模型极度依赖于大量的有标签数据。
所以研究者们想研究出一种办法,如何利用大量的无标签数据。
所以自监督学习的到了广泛关注,因为它可以从数据自己本身中寻找标签来监督模型的训练。
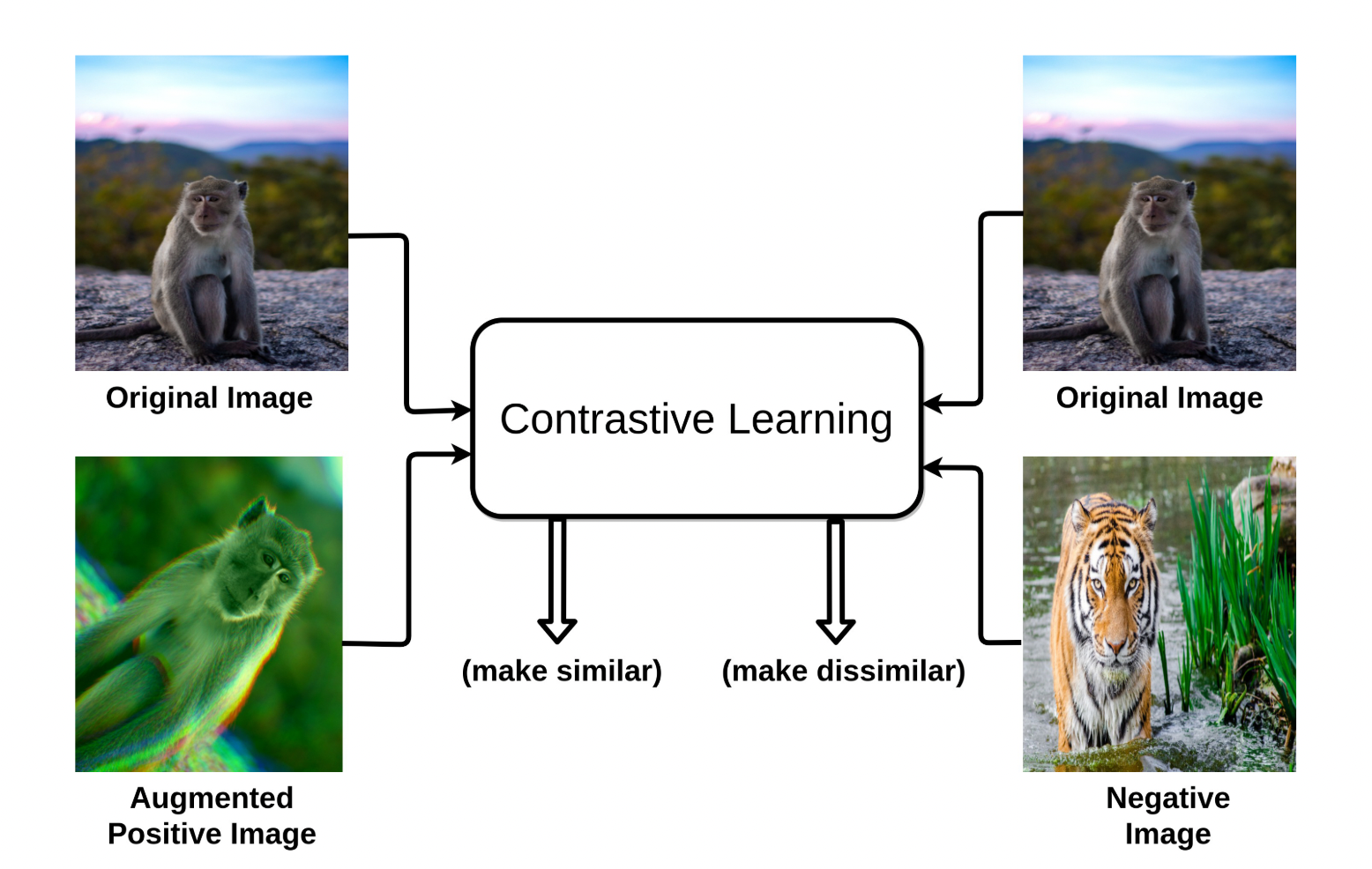

图一:对比学习的直观理解:让原图片和增强的图片变近,让原图片和其他图片变远。
监督学习不仅需要大量的标注数据,它还面临着下面的各种问题:
- 模型的泛化性能
- 伪相关
- 对抗攻击
最近,自监督学习结合了生成模型和对比模型的特点:从大量无标签数据中学习表示。
一种流行的方式是设计各种前置任务(pretext task)来让模型从伪标签中来学习特征。例如图像修复、图像着色、拼图、超分辨率、视频帧预测、视听对应等。这些前置任务被证明可以学习到很好的表示。
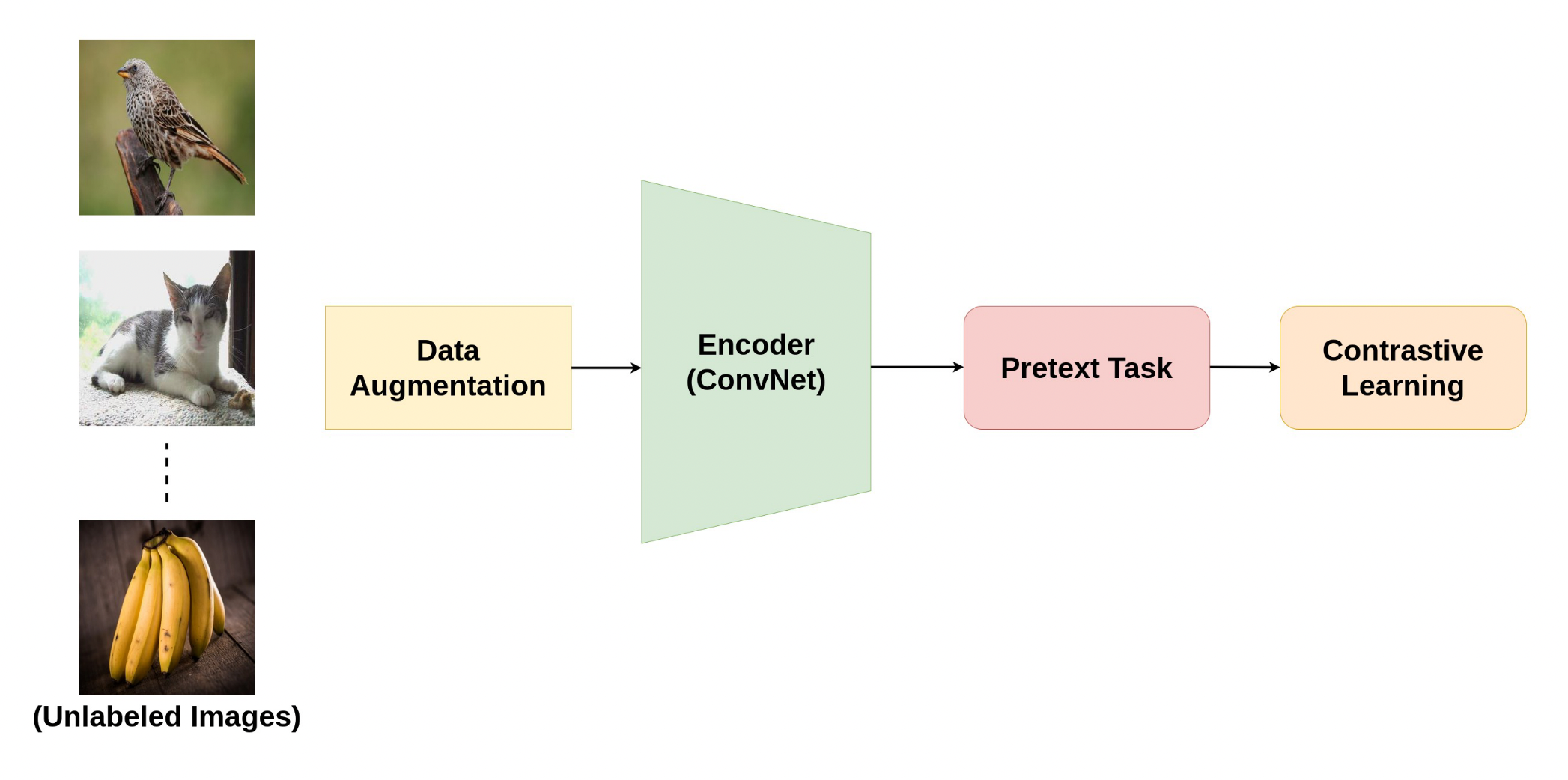
图二:对比自监督学习训练范式
在2014年生成对抗网络(GAN)[3] 推出之后,生成模型得到了很多关注。它之后变成了许多强大的模型的基础,例如 CycleGAN, StyleGAN, PixelRNN, Text2Image, DiscoGAN 等。
这些模型启发研究者去研究自监督学习(不需要标签)。
他们发现基于GAN的模型很复杂,不容易训练,主要是由于下面原因:
- 难以收敛
- 判别器太强大而导致生成器难以生成好的结果
- 判别器和生成器需要同步
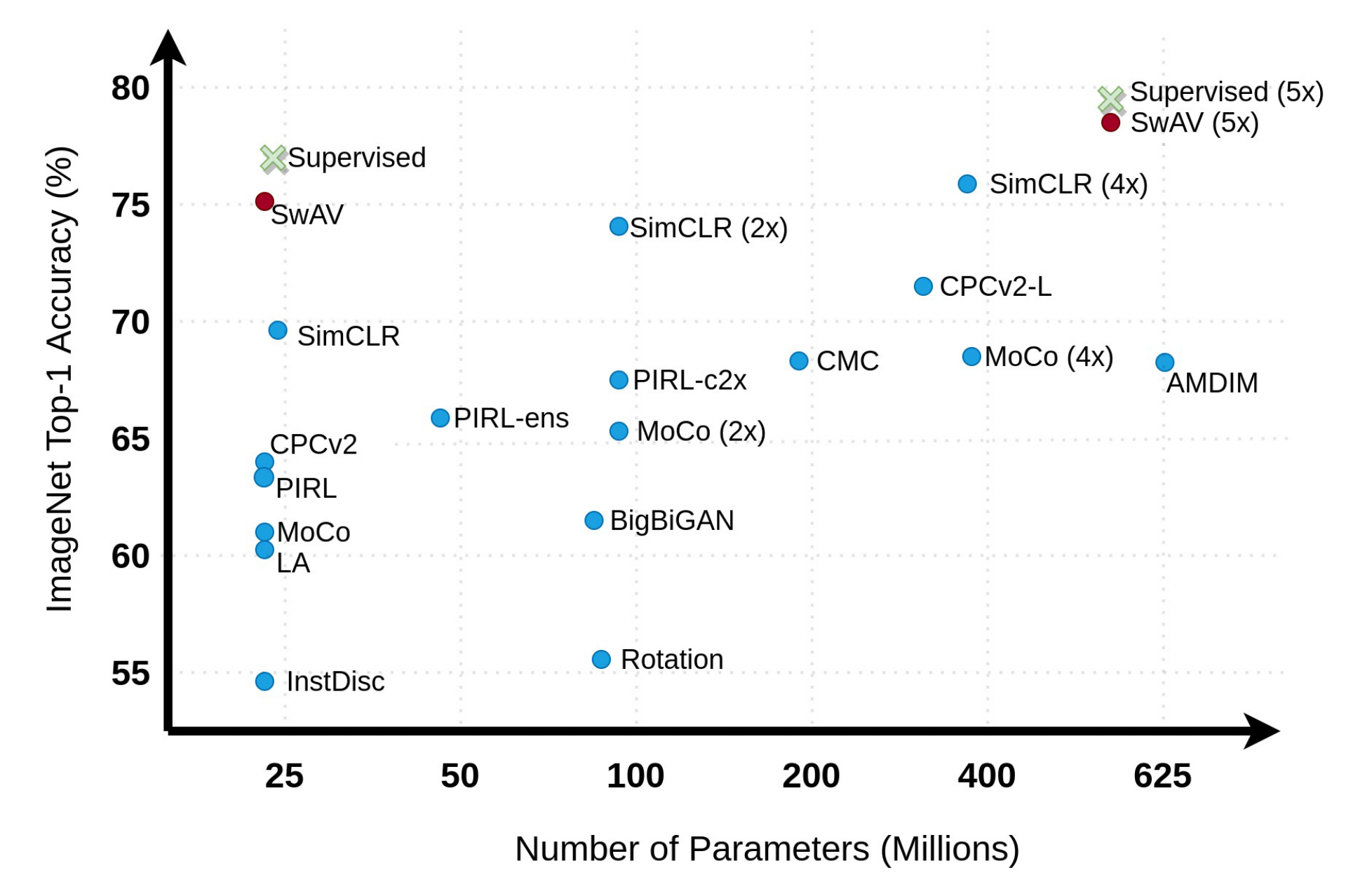
图三:不同的对比学习方法在ImageNet上的效果(TOP1 分类准确率)。
与生成模型不同,对比学习是一种判别模型,它让相似样本变近,不同样本变远(见图一)。
为了达到这一点,一种衡量远近的指标被用来衡量嵌入之间的远近。
如图二所示,对比损失用来训练对比学习模型。一般来说,以图片为例,对比学习把一张图片的增强版本当作一个正例,其余图片当作反例,然后训练一个模型来区分正反例。区分依赖于某种前置任务。
这样做,学习到的表示就可以用到下游任务之中。
2. 前置任务(Pretext Tasks)
前置任务是自监督学习中非常重要的一种策略。它可以用伪标签从数据中学习表示。
伪标签是从数据本身中定义而来的。
这些任务可以应用到各种数据之中,例如图片、视频、语言、信号等。
在对比学习的前置任务之中,原始图片被当作一种anchor,其增强的图片被当作正样本(positive sample),然后其余的图片被当作负样本。
大多数的前置任务可以被分为四类:
- 颜色变换
- 几何变换
- 基于上下文的任务
- 基于交叉模式的任务
具体使用哪种任务取决于具体的问题。
颜色变换

图四:颜色变换前置任务,包括:原图,高四噪声,高斯模糊,颜色失真(jitter)
颜色变换很好理解,不多说了。在这个前置任务中,图片经过变换,它们还是相似的图片,模型需要学会辨别这些经过颜色变换的图片。
几何变换
几何变换也很好理解,不多说了。
原图被当作全局视图(global view),转换过的图片被当作局部试图(local view)。

图五:几何变换,包括:原图,裁剪、旋转、翻转等
基于上下文的
拼图
解决拼图问题是无监督学习中一个非常重要的部分。
在对比学习中,原图被当作anchor,打乱后的图片被当作正样本,其余图片被当作负样本。
图六:解决一个拼图问题被当作学习表示的前置任务。
基于帧的
这个策略一般应用于时序数据,例如传感器的数据或者一系列视频帧。
策略背后的意义是:时间上相近的相似,时间上很远的不相似。
解决这样的前置任务可以让模型学习到一些跟时间有关的表示。
在这里,一个视频中的帧被当作正样本,其余视频被当作负样本。
其余的方法还包括:随机抽样一个长视频中的两个片段,或者对每个视频片段做几何变换。
目标是使用对比损失(contrastive loss)来训练模型,使得来自一个视频的片段在嵌入空间中相近,来自不同视频的片段不相近。
Qian 等人 [20] 提出的一个模型中将两个正样本和其余所有的负样本之间进行对比。
一对正样本是两个增强的来自同一个视频的视频片段。
这样,所有的视频在嵌入空间中都是分割开来的,每个视频占据一个小的嵌入空间。
未来预测
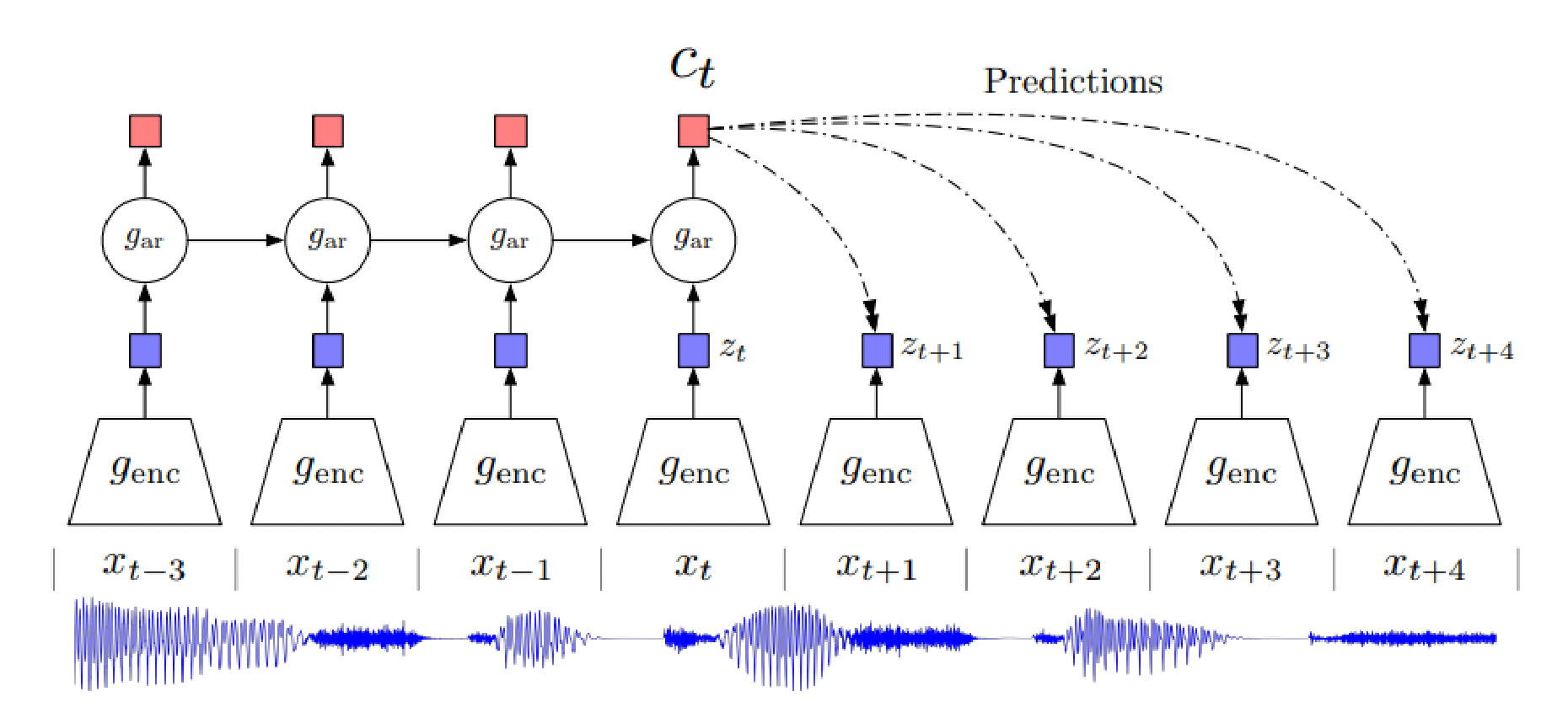
图七:对比预测编码CPC:contrastive predictive coding。图中的例子是音频预测。类似的想法可以用在图片、视频、文本等领域上。
对于时序数据做对比一个最直观的方法是预测将来或者预测缺失的信息。
这个前置任务是基于已有的一系列时间点数据,去预测将来的高阶的信息。
在 [21] [22] 等模型中,高阶数据被压缩在一个低维度的隐藏嵌入空间之中。强大的序列模型被当作encoder来生成一个基于上下文的 C t C_t Ct,然后用 C t C_t Ct来预测未来的信息。其中蕴含的意义是最大化两者之间的互信息(Mutual information maximization)。
视图预测 View Prediction (Cross modal-based)
视图预测任务一般用在数据本身拥有多个视图的情况下。
在 [23] 中,anchor和它的正样本图片来自同时发生的视角下,它们在嵌入空间中应当尽可能地近,与来自时间线中其他位置的负样本图片尽可能地远。
在 [24] 中,一个样本的多视角被当作正样本(intra-sampling),其余的inter-sampling当作负样本。
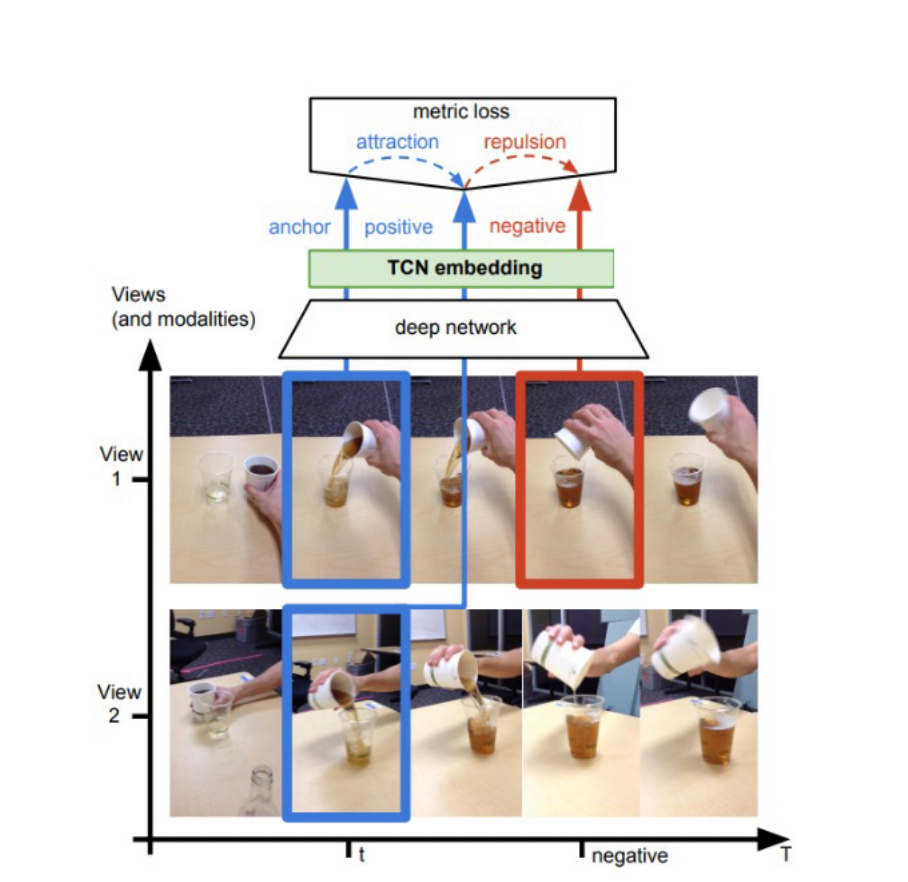
图八:从视频帧序列中学习表示。[23]
确定对的前置任务
选择什么样的前置任务取决于你所要解决的任务。
尽管已经有很多类型的前置任务在对比学习中提出来了,但是选择哪种前置任务依旧没有一个理论支撑。
选择正确的前置任务对表示学习有非常大的帮助。
前置任务的本质是:模型可以学习到数据本身的一些转换(数据转换之后依然被认作是原数据,转换后到数据和原数据处于同一嵌入空间),同时模型可以判别其他不同的数据样本。
但是前置任务本身是一把双刃剑,某个特定的前置任务可能对某些问题有利,对其他问题有害。

图九:两张图片的形状差不多。但是,很多低阶的细节是不一样的。在这里使用正确的前置任务是非常重要的。[28]
在 [26] 中,作者专注于选取正确的前置任务的重要性。

图十:一个例子:为什么旋转前置任务有时候表现不好。
3. 架构
对比学习依赖于负样本的数量,来生成好的表示。
它有时候可以看作是一个字典查询任务,字典有时候是整个训练集,有时候是训练集的子集。
有时候对比学习可以根据如何采样负样本来进行分类。
我们将对比学习的架构分为以下四类(见图十一)。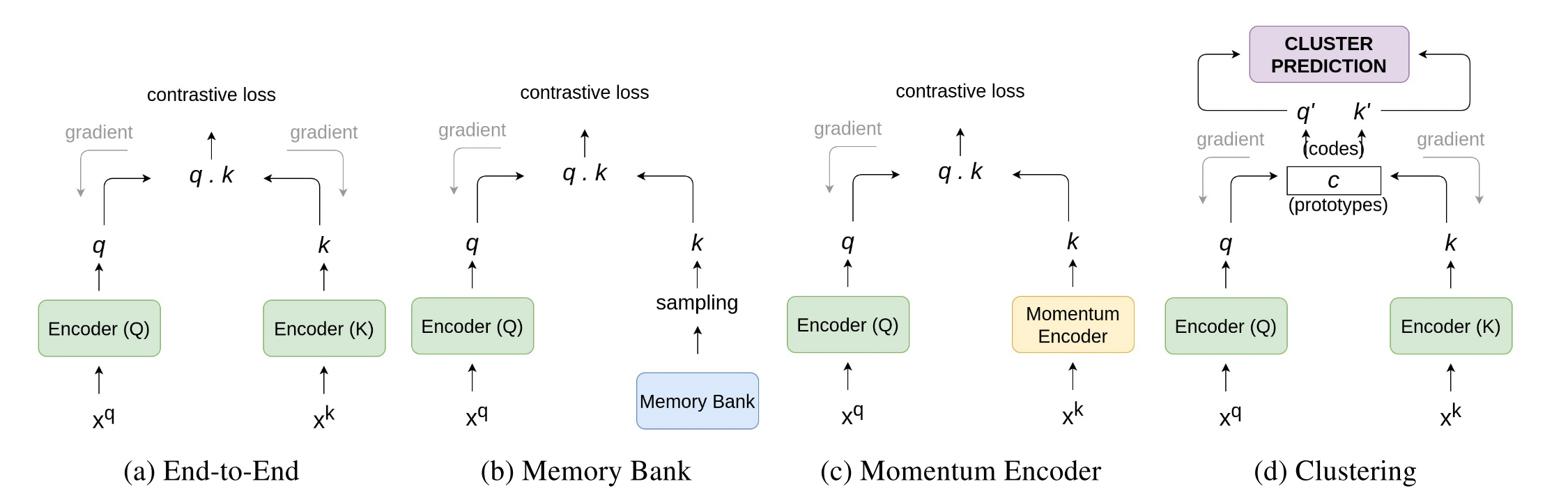
图十一:(a)端到端训练,一个encoder用来生成正样本的表示,一个encoder用来生成负样本的表示;(b)使用一个memory bank来存储和抽取负样本;(c)使用一个momentum encoder当作一个动态的字典查询来处理负样本;(d)额外使用一个聚类机制。
端到端学习
端到端学习是一种复杂的基于梯度的学习系统,其中所有的模块都是可微的。这种架构偏好于大的batch size来存储更多的负样本。除了原图片和其增强的图片,其余的batch中的图片被当作负样本。这种架构包含两个encoder:一个query一个key(见图十一a)。
这两个encoder可以是一样的,也可以是不一样的。
使用一个对比损失,模型会让正样本的表示相近,让负样本和正样本的表示相远。
最近,一种端到端的模型 [15] SimCLR 获得了很大成功。他们使用了非常大的batch size(4096)训练了100个epochs。SimCLR证明了一种简单机制的模型也可以获得非常好的效果。
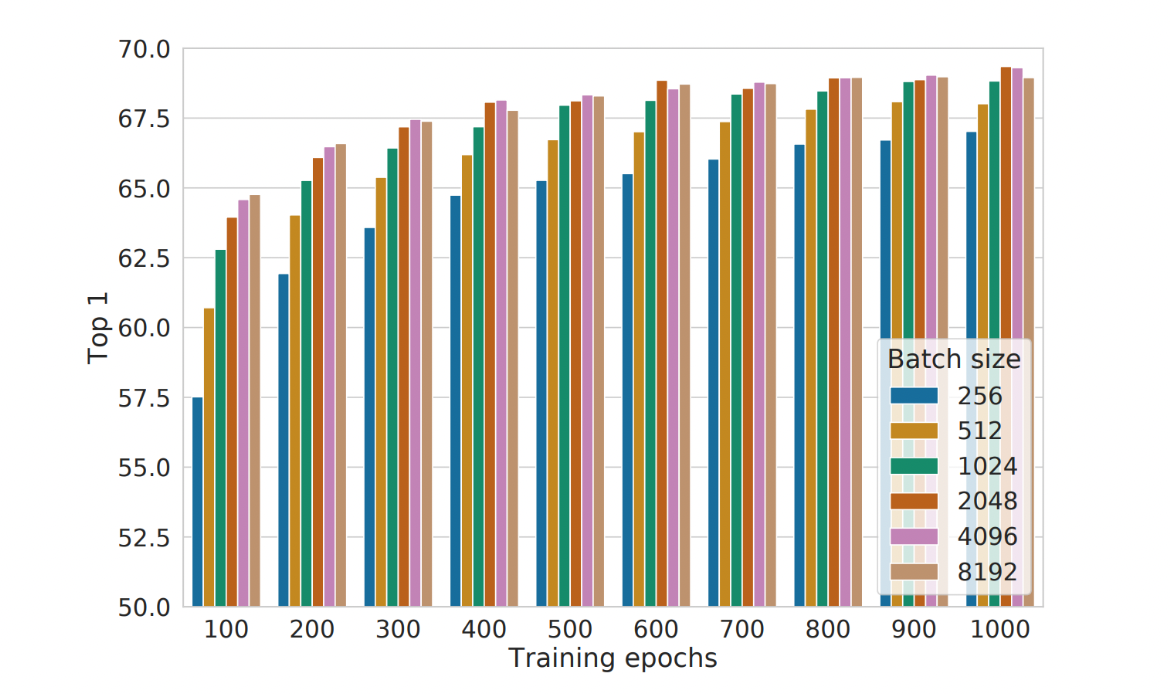
图十二:SimCLR的效果。
另外一种端到端的模型 [21] CPC从高维的时序数据中学习表示,其使用对比损失来预测将来。
端到端学习中的负样本与batch size有关。而batch size的大小受限于GPU/TPU 内存,所以这里有一个计算资源的限制,而且如何优化大batch训练也是一个问题。
使用 Memory Bank
端到端依赖于大的batch(译者:存疑,某些任务可能不需要),所以一种可行的解决方案是使用 memory bank。
Memory bank:的作用是在训练的时候维护大量的负样本表示。所以,创建一个字典来存储和更新这些样本的嵌入。Memory bank M M M 在数据集 D D D 中对每一个样本 I I I 存储一个表示 m I m_I mI。该机制可以更新负样本表示,而无需增大训练的batch size。
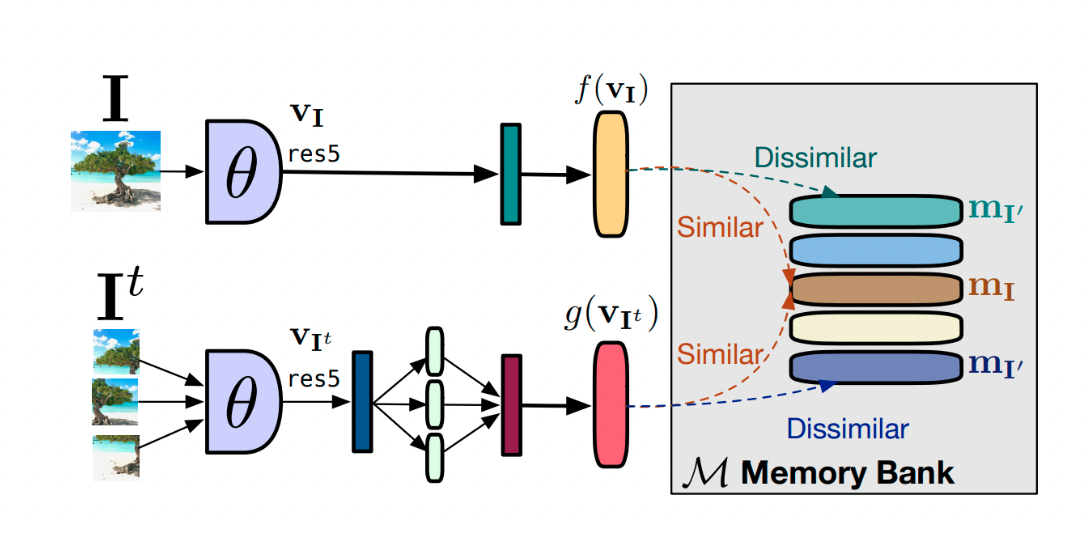
图十三:PIRL中的memory bank。
PIRL [17] 是一种使用了 Memory bank 来学习图像表示的方法。
但是,在训练的时候维护一个大的memory bank是一个很复杂的任务。这种策略的一个缺点是更新表示的计算复杂度很高。
使用 Momentum Encoder
为了解决 memory bank 的缺点,momentum encoder [14] 被提了出来。这种机制创建了一种特殊的字典,它把字典当作一个队列的keys,当前的batch进入队列,最老的batch退出队列。
Momentum encoder 共享了encoder Q的参数。它不会在每次反向传播后更新,而是依据query encoder的参数来更新:
θ k ← m θ k + ( 1 − m ) θ q \theta_k \leftarrow m\theta_k + (1-m)\theta_q θk←mθk+(1−m)θq
在公式中, m ∈ [ 0 , 1 ) m\in [0, 1) m∈[0,1) 是momentum系数。只有参数 θ q \theta_q θq会被反向传播更新。
Momentum update使得 θ k \theta_k θk缓慢、柔和地依据 θ q \theta_q θq来更新,使得两个encoders的区别并不会很大。
Momentum encoder的优点是不需要训练两个不一样的encoder,而且维护memory bank会比较简单。
特征表示聚类 Clustering Feature Representation
上面介绍的三种架构都是用某种相似度衡量来对比样本,使得相似样本相近,不相似样本变远,从而学习到好的表示。
本节介绍的机制使用两个共享参数的端到端架构,这种架构使用聚类算法来聚类相似样本表示。
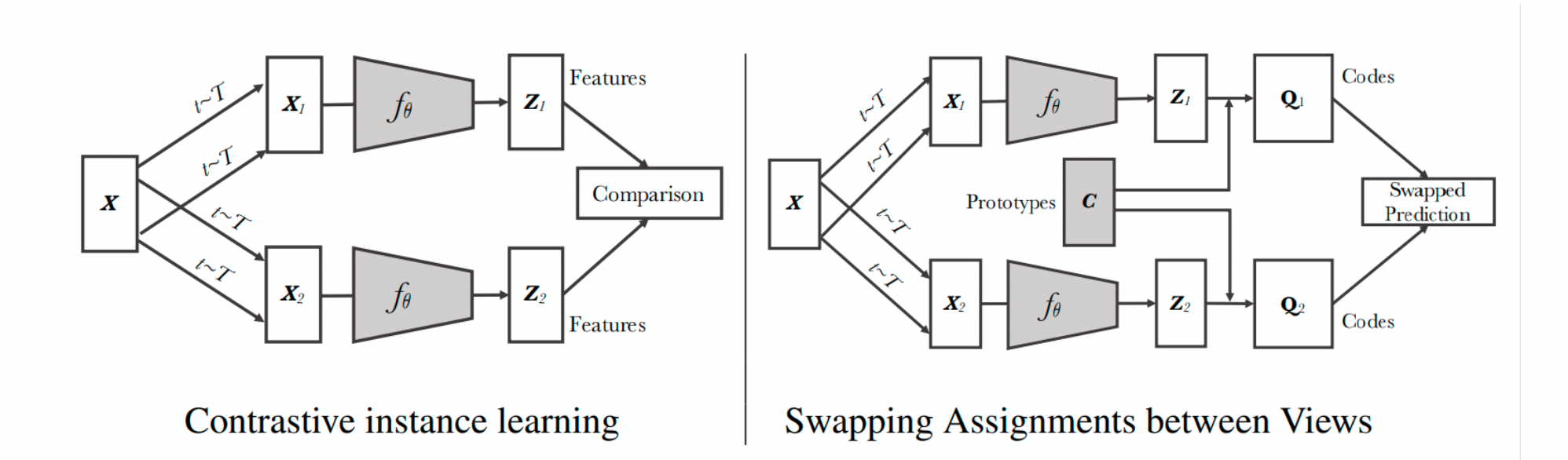
图十四:传统对比样本学习 vs 对比聚类学习[13]
SwAV [13] 使用了聚类方法。其背后的idea在于,在一个嵌入空间中,猫的样本们应该和狗的样本们相近(都是动物),而与房子的样本们相远。
在基于样本的学习中,每个样本被当作一个数据集中的离散类。
离散类在连续的嵌入空间中(相似的样本表示相近)可能会有问题。
例如在一个batch里,正样本是猫,负样本们中也有猫,模型会让正样本的猫和负样本中的猫变远,不利于表示学习。
4. Encoders
在自监督学习中,Encoder非常重要,因为它们把数据样本遍历到隐空间中。

图十五:训练一个Encoder,然后迁移学习到下游任务。
没有一个强大的encoder的话,模型可能难以学到有效的表示,从而执行分类任务。对比学习中的大多数模型都采用了ResNet或其变种。
5. 训练
为了训练一个encoder,需要一个前置任务来利用对比损失来进行反向传播。
对比学习最核心的观点是将相似样本靠近,不相似样本靠远。
所以需要一个相似度衡量指标来衡量两个表示的相近程度。
在对比学习中,最常用的指标是cosine similarity。
c o s s i m ( A , B ) = A ⋅ B ∣ ∣ A ∣ ∣ ∣ ∣ B ∣ ∣ cos_sim(A, B) = \frac{A\cdot B}{||A||||B||} cossim(A,B)=∣∣A∣∣∣∣B∣∣A⋅B
Noise Contrastive Estimation (NCE) [38] 函数定义为:
L N C E = − log exp ( s i m ( q , k + ) / τ exp ( s i m ( q , k + ) / τ ) + exp ( s i m ( q , k − ) / τ ) L_{NCE} = -\log \frac{\exp (sim(q, k_+)/\tau}{\exp (sim(q, k_+)/\tau ) + \exp (sim (q, k_{-})/\tau)} LNCE=−logexp(sim(q,k+)/τ)+exp(sim(q,k−)/τ)exp(sim(q,k+)/τ
其中 q q q是原样本, k + k_+ k+是正样本, k − k_- k−是负样本, τ \tau τ是超参数,被称为温度系数。 s i m ( ) sim() sim()可以是任何相似度函数,一般来说是cosine similarity。
如果负样本的数量很多,NCE的一个变种 InfoNCE 定义为:
L I n f o N C E = − log exp ( s i m ( q , k + ) / τ exp ( s i m ( q , k + ) / τ ) + ∑ i = 0 K exp ( s i m ( q , k i ) / τ ) L_{InfoNCE} = -\log \frac{\exp (sim(q, k_+)/\tau}{\exp(sim(q, k_+)/\tau) + \sum_{i=0}^K \exp(sim(q, k_i)/\tau)} LInfoNCE=−logexp(sim(q,k+)/τ)+∑i=0Kexp(sim(q,ki)/τ)exp(sim(q,k+)/τ
k i k_i ki表示负样本。
与其他深度学习模型类似,对比学习应用了许多训练优化算法。训练的过程包括最小化损失函数来学习模型的参数。
常见的优化算法包括 SGD 和 Adam 等。
训练大的 batch 的网络有时需要特殊设计的优化算法,例如 LARS。
6. 下游任务
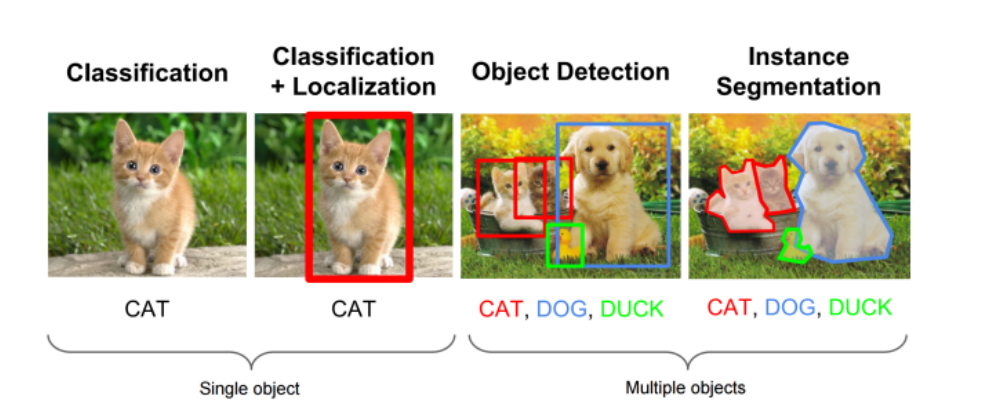
图十六:计算机视觉中的各种下游任务
一般来说,计算机视觉的自监督训练包括两个任务:
- 前置任务
- 下游任务
下游任务聚焦于具体的应用,在优化下游任务的时候,模型利用到了前置任务优化时期所学到的知识。这些任务可以是分类、检测、分割、预测等。图十七提供了一个迁移学习的流程。
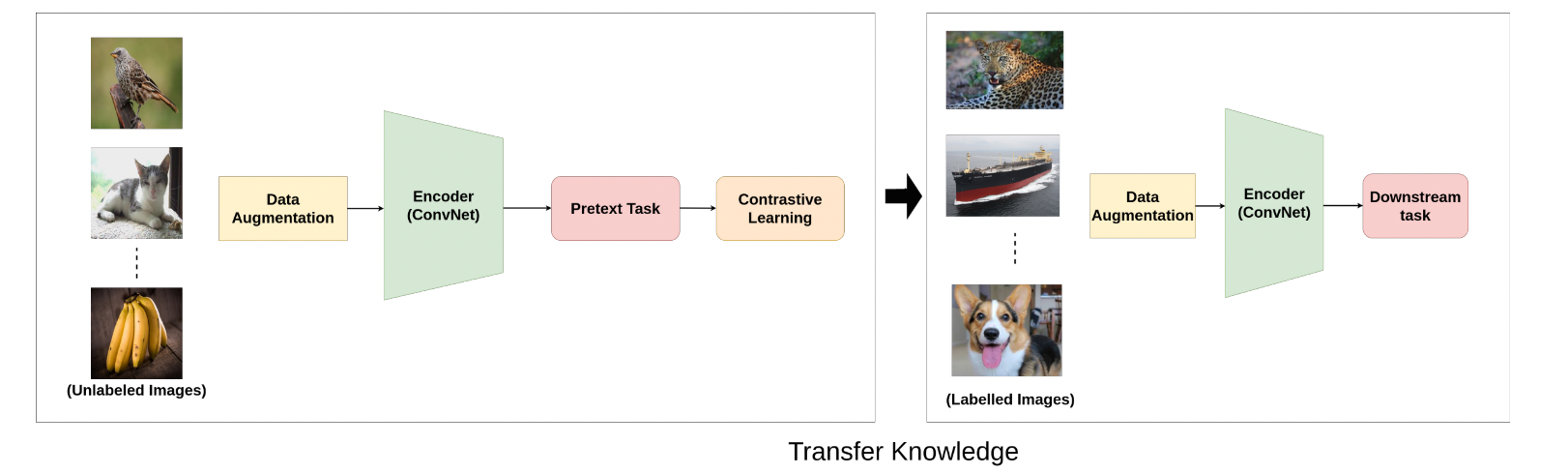
图十七:计算机视觉中的下游任务
为了测试自监督学习中学习到的特征对下游任务的效果,一些方法,例如
- kernel visualization
- feature map visualization
- nearsest-neighbor based approaches
被用来分析前置任务的有效性。
对 Kernels 和 特征图进行可视化
在这里,第一个卷积层的特征的kernels(分别来自于自监督训练和监督训练)被用来做比较。
类似地,不同层的 attention maps 也可以被用来测试模型的有效性。

图十八:AlexNet所训练的 attention map
最近相邻撷取
一般来说,相同类的样本在隐藏空间中的位置应该相近。对一个输入的样本,使用最近相邻方法,可以在数据集中使用 top-K 抽取来分析自监督学习的模型是否有效。
7. 基准
最近,许多自监督学习模型挑战了监督模型的效果。在本章中,我们收集和对比了这些模型的效果,在下游任务上。对于图像分类,我们选择了ImageNet和Places数据集。类似的,对于目标检测,我们选择了Pascal VOC数据集。行为识别和视频分类我们选择了UCF-101,HMDB-51和Kinetics。
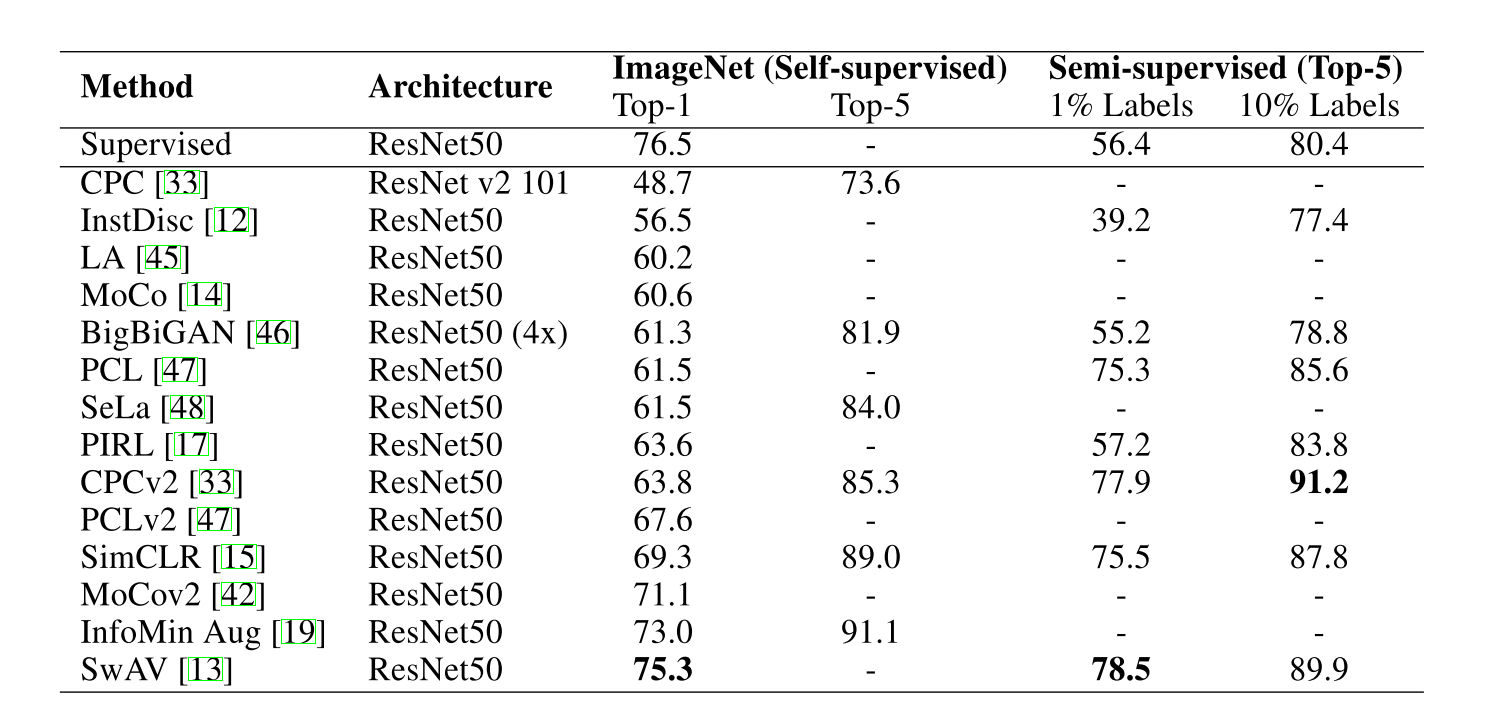
表一:ImageNet
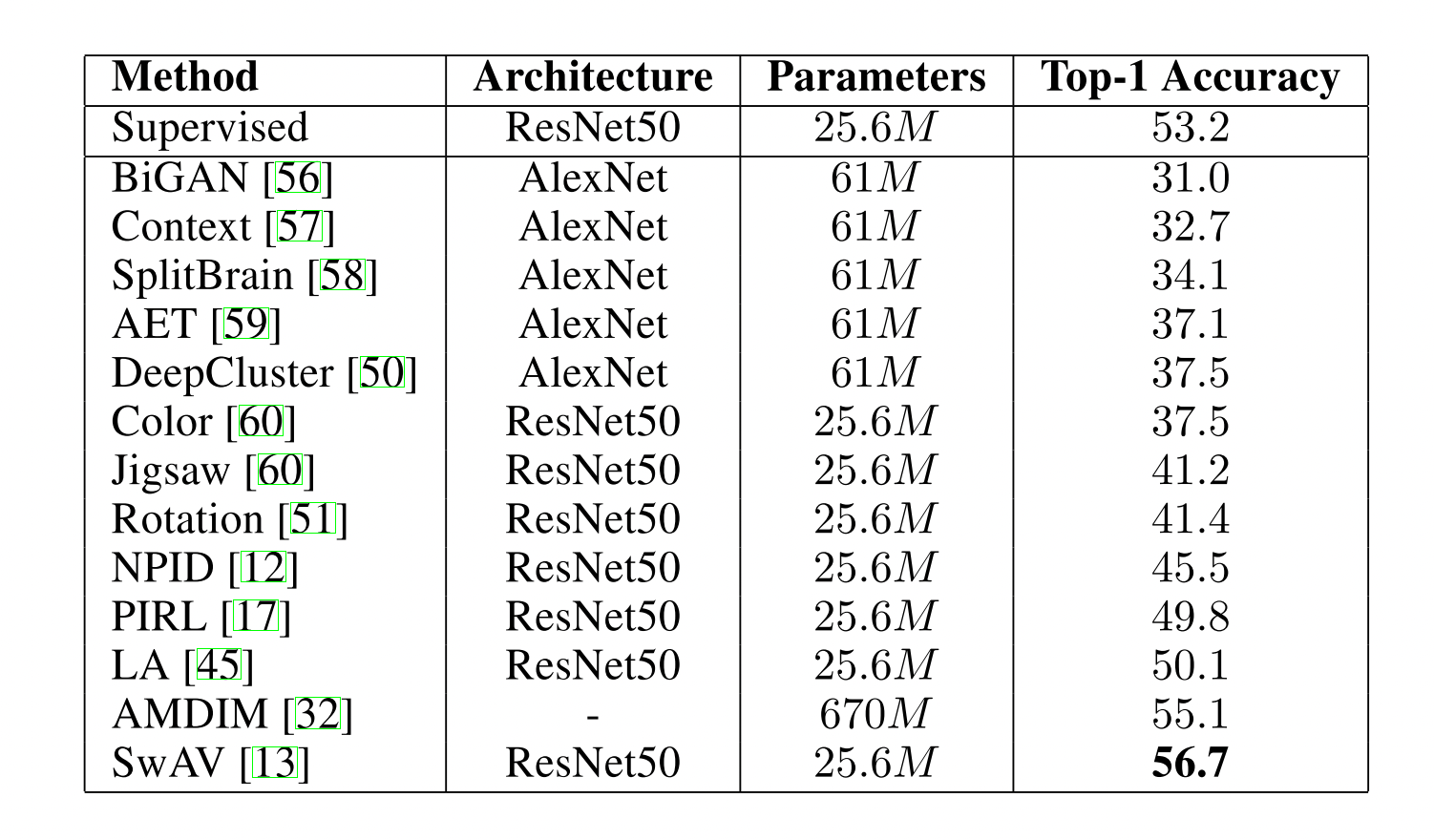
表二:Places 数据集
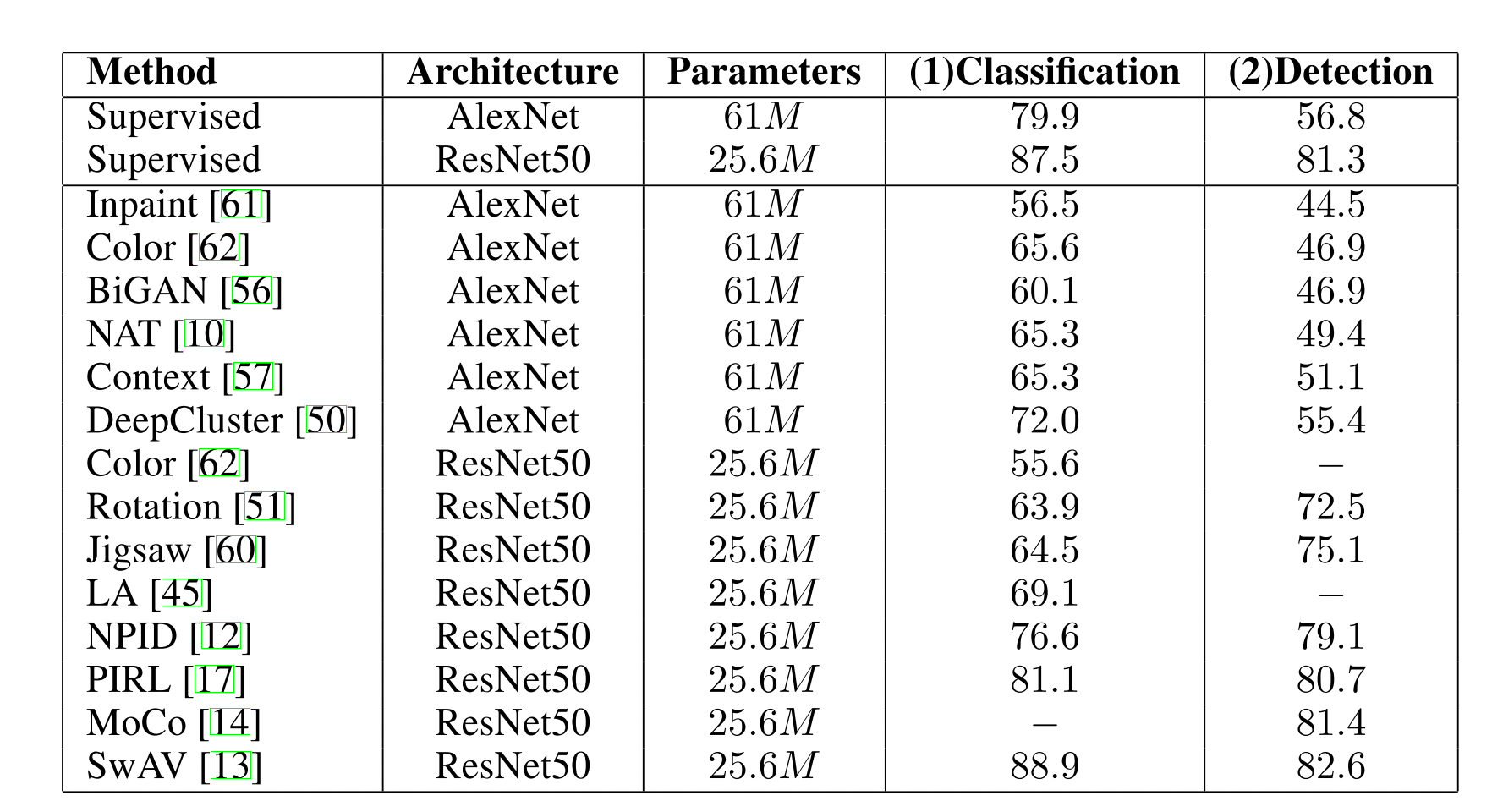
表三:VOC7+12 (a)frozen feature (b)fine-tune
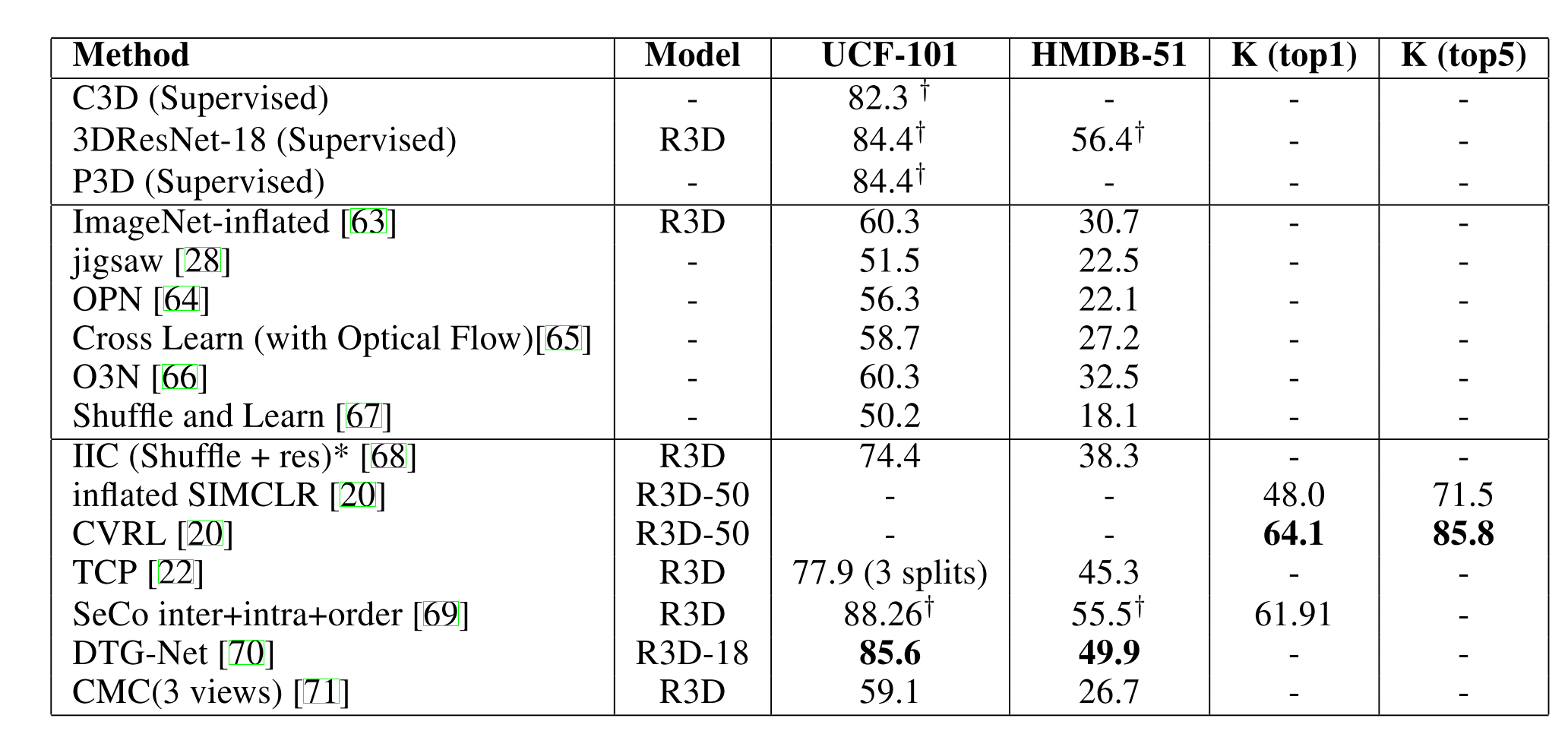
表四:视频分类
不具体解释了。
8. NLP上的对比学习
提供了一些背景知识,略。
9. 讨论和未来方向
尽管实验结果显示对比学习的效果很好,但是它还需要更多的理论论证。
缺少理论支撑
数据增强的选择和前置任务
恰当的负样本采样
数据集偏见
10. 结论
这篇论文总结了各种流行的自监督对比模型。
我们解释了对比学习中不同的模块:
- 如何选择正确的前置任务
- 如何选择学习架构
- 如何在下游任务上优化
基于对比学习的模型获得了非常好的实验效果。
本文最后总结了当前对比学习面临的问题。
Reference
- [3] Ian J Goodfellow et al., Generative adversarial networks, 2014.
- [13] Caron et al., Unsupervised learning of visual features by contrasting cluster assignments, 2020.
- [14] He et al., Momentum contrast for unsupervised visual representation learning, CVPR, 2019.
- [15] Chen et al., A simple framework for contrastive learning of visual representations, ICML, 2020.
- [20] Qian et al., Spatiotemporal contrastive video representation learning, arXiv, 2020.
- [21] Oord et al., Representation learning with contrastive predictive coding, arXiv, 2018.
- [22] Lorre et al., Temporal contrastive pretraining for video action recognition, IEEE Winter Conference on Applications of Computer Vision, 2020.
- [23] Sermanet et al., Time-contrastive networks: Self-supervised learning from video, 2017.
- [24] Tao et al., Self-supervised video representation learning using inter-intra contrastive framework, 2020.
- [26] Yamaguchi et al., Multiple pretext-task for self- supervised learning via mixing multiple image transformations, 2019.
- [28] Noroozi et al., Unsupervised learning of visual representations by solving jigsaw puzzles, ECCV, 2016.
- [38] Gutmann et al., A new estimation principle for unnormalized statistical models, AISTATS, 2020.
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/193851.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
