大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
对比学习一般是自监督学习的一种方式
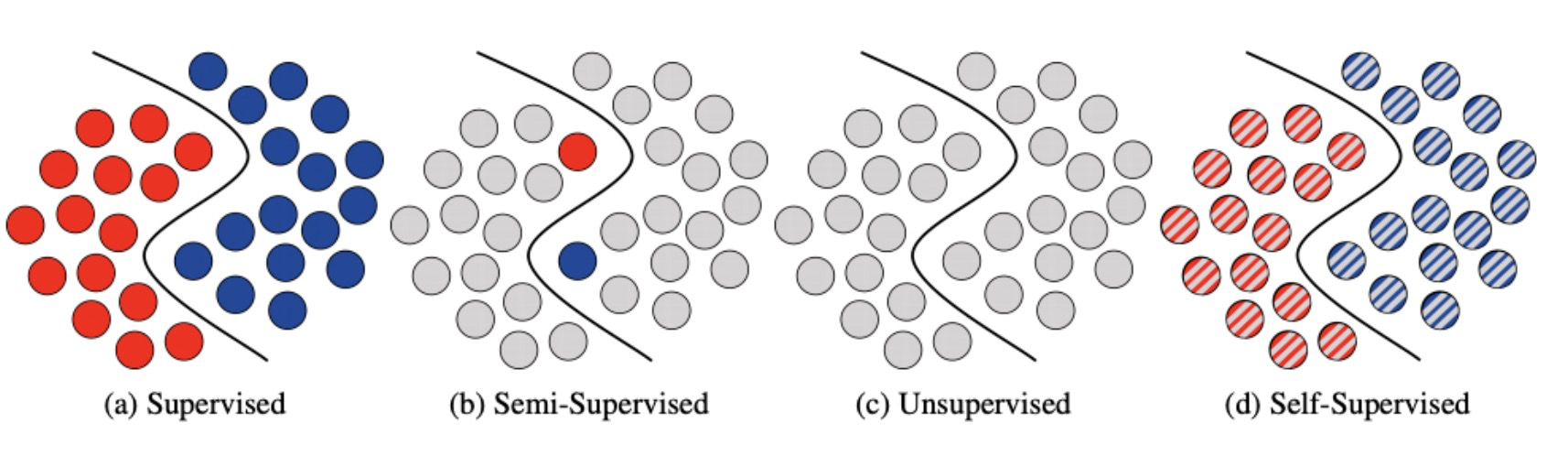

什么是自监督学习
自监督学习主要是利用辅助任务(pretext)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。(也就是说自监督学习的监督信息不是人工标注的,而是算法在大规模无监督数据中自动构造监督信息,来进行监督学习或训练。因此,大多数时候,我们称之为无监督预训练方法或无监督学习方法,严格上讲,他应该叫自监督学习)。
原文作者:自编码器个人认为可以算作无监督学习,也可以算作自监督学习,个人更倾向于后者。不过原文作者把自编码器看作是无监督学习方法,并将其与自监督学习方法相区分,具体区别如上文所示:自编码器,可能仅仅是做了维度的降低而已,我们希望学习的目的不仅仅是维度更低,还可以包含更多的语义特征,让模型懂的输入究竟是什么,从而帮助下游任务。而自监督学习最主要的目的就是学习到更丰富的语义表征。
对于自监督学习来说,存在三个挑战:
- 对于大量的无标签数据,如何进行表征/表示学习?
- 从数据的本身出发,如何设计有效的辅助任务 pretext?
- 对于自监督学习到的表征,如何来评测它的有效性?
对于第三点,评测自监督学习的能力,主要是通过 Pretrain-Fintune 的模式。我们首先回顾下监督学习中的 Pretrain – Finetune 流程:我们首先从大量的有标签数据上进行训练,得到预训练的模型,然后对于新的下游任务(Downstream task),我们将学习到的参数(比如输出层之前的层的参数)进行迁移,在新的有标签任务上进行「微调」,从而得到一个能适应新任务的网络。
自监督的 Pretrain – Finetune 流程:首先从大量的无标签数据中通过 pretext 来训练网络(自动在数据中构造监督信息),得到预训练的模型,然后对于新的下游任务,和监督学习一样,迁移学习到的参数后微调即可。所以自监督学习的能力主要由下游任务的性能来体现。
自监督学习的主要方法
自监督学习的方法主要可以分为 3 类:1. 基于上下文(Context based) 2. 基于时序(Temporal Based)3. 基于对比(Contrastive Based)
从最近的热度来看,目前自监督学习主要集中在第三种,这里我们也重点介绍第三种方法-对比学习,其他方法可以查看https://blog.csdn.net/sdu_hao/article/details/104515917
对比学习
该类方法主要是通过一个辅助任务,构建正负样本,通过比较正负样本的距离差来进行学习。核心思想就是有一个样本anchor,然后构建其正样本pos,负样本neg,然后anchor和pos的相似度远大于anchor和neg的相似度,即
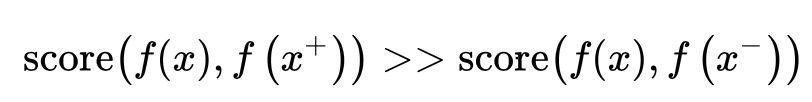
LeCun 2006年提出对比损失(Contrastive Loss):
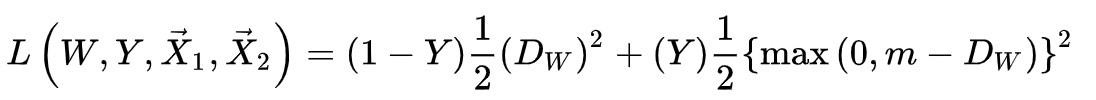
我们常说的Triplet Loss就是一种对比学习,一个样本,有一个正样p和一个负样本n
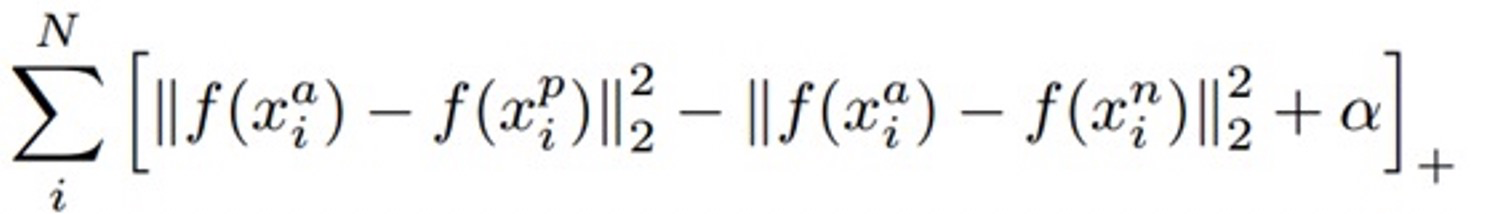
如果一个x样本,构造一个正样x+和多个负样本,则loss函数可以为
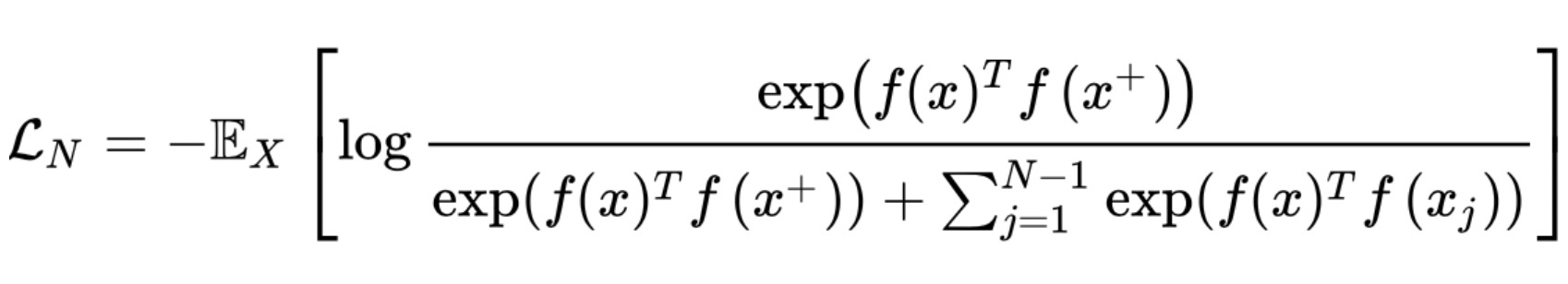
即论文CPC里的Info-Nce函数
对比学习常见模型
1. DEEP INFOMAX(DIM)模型: Deep InfoMax: Learning deep representations by mutual information estimation and maximization
DIM 的具体思想是对于隐层的表达,我们可以拥有全局的特征(编码器最终的输出)和局部特征(编码器中间层的特征),模型需要分类全局特征和局部特征是否来自同一图像。所以这里 x 是来自一幅图像的全局特征,正样本是该图像的局部特征,而负样本是其他图像的局部特征。
2. CPC(对比预测编码):Representation Learning with Contrastive Predictive Coding
c_t 代表融合了过去的信息,而正样本就是这段序列 t 时刻后的输入,负样本是从其他序列中随机采样出的样本。CPC的主要思想就是基于过去的信息预测的未来数据,通过采样的方式进行训练。
3. MoCo(动量对比):Momentum Contrast for Unsupervised Visual Representation Learning
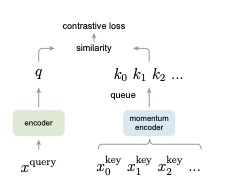
moco的基本思想如图1所示,左边的 x_qurey是我们的查询样本,右边的 x_i_key 是一个字典,里面存储着的是一组数据样本,分别通过不同的编码器网络提取特征,通过最小化特征之间的对比损失函数来进行编码网络的更新。

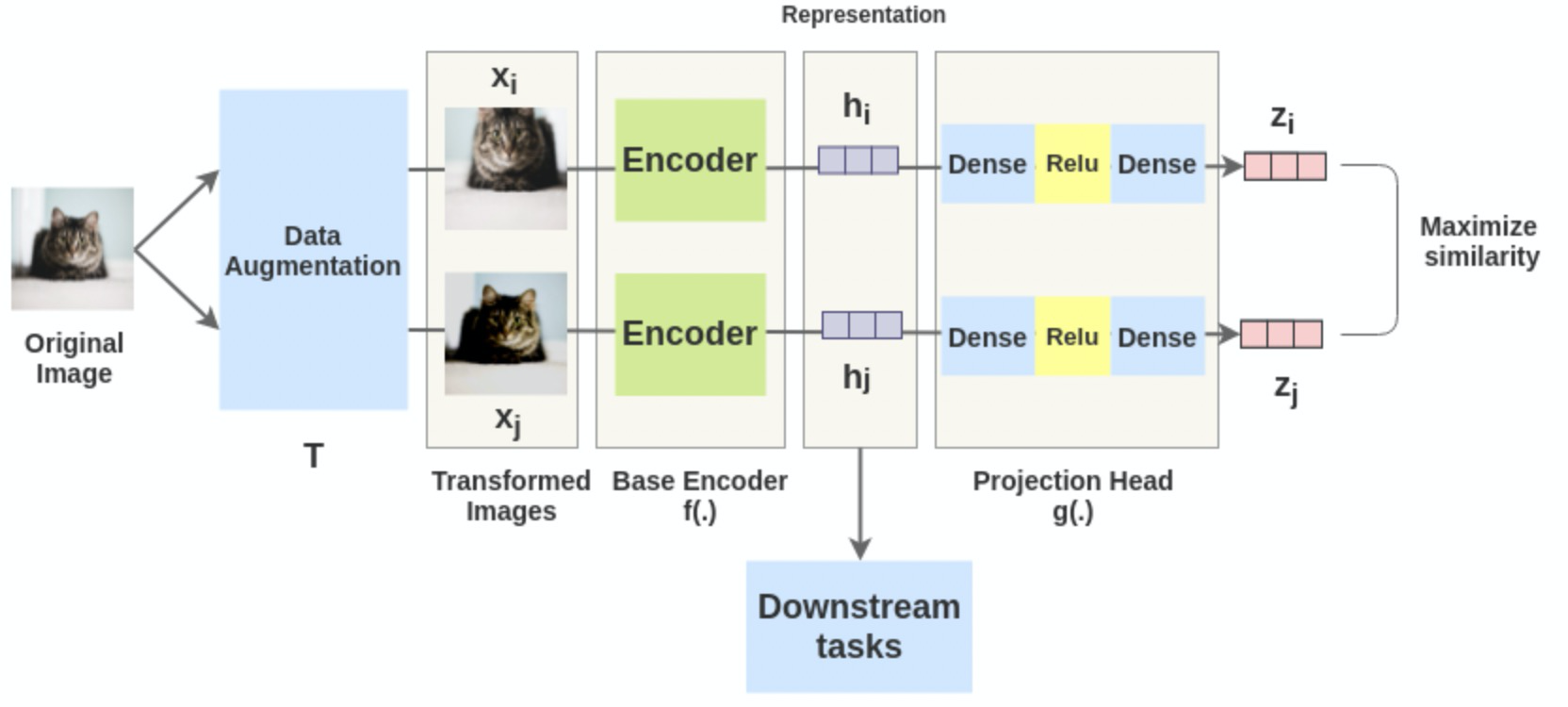
4. SimCLR:SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
SimCLR框架,正如全文所示,非常简单。取一幅图像,对其进行随机变换,得到一对增广图像x_i和x_j。该对中的每个图像都通过编码器以获得图像的表示,然后用一个非线性全连通层来获得图像表示z,其任务是最大化相同图像的z_i和z_j两种表征之间的相似性。
在原文中,作者使用ResNet-50架构作为ConvNet编码器。输出是一个2048维的向量h。
然后,通过取上述计算的对数的负数来计算这一对图像的损失。这个公式就是噪声对比估计(NCE)损失:

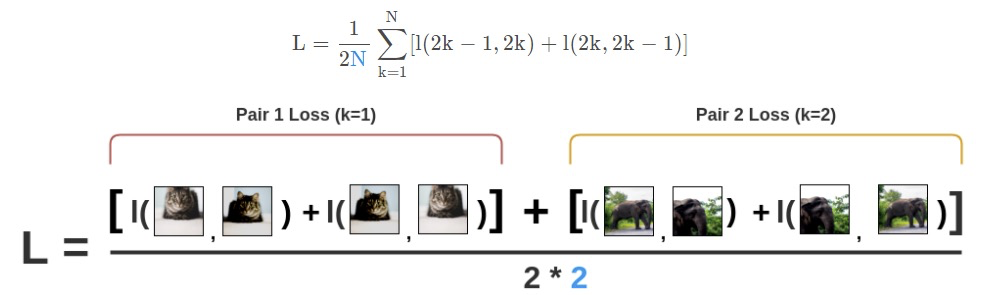
在图像位置互换的情况下,我们再次计算同一对图像的损失。

最后,我们计算Batch size N=2的所有配对的损失并取平均值。
5. CLEAR: Contrastive Learning for Sentence Representation
借鉴SimCLR的思想,在文本表征中饮用对比学习的思路。大概思路如下,原始句子通过数据增强后,输入到transformer encoder中,然后经过映射函数g映射到同一个表示空间。最后的损失约束同SimCLR。
数据增量的四种方式:
Word deletion:即随机删除句子中的某些词,并将这些词使用 [DEL] 进行替换
Span deletion:从 span-level 进行选择和删除,并使用 [DEL] 进行替换,可以认为这种方法是 Word deletion 的一个特例
Reordering:随机从句子中采样出几对词,然后替换他们彼此的位置(已在 BART 中证实有效)
Substitution:随机从句子中选择一些词,然后将其替换为这些词的同义词(使用了一个同义词词典)

针对每个 minibatch,随机选择两种数据增强的方法。经过数据增强之后,两个来自同一个句子的增强句子就认为是正样本,其他所有来自同一个 minibatch 的增强样本就认为是这两个正样本的负样本,这样针对正样本的损失函数就可以构建为:
整个对比方法的损失函数就可以认为是所有正样本对的损失函数之和:
与此同时,作者还保留了原来的 Mask Language Model(MLM)的损失函数,将两个损失函数结合,就得到了整个方法的损失函数。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/193837.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
