大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
前段时间在杭州参加华尔兹,在会场听报告和看Poster的时候,我发现AI领域的论文研究不再跟前几年一样专注于某个特定的任务提出全监督的网络模型(比如语义分割、目标检测和风格迁移等)。因为这些年深度学习的发展使得在数据充足情况下,经典任务的模型已经能达到很好的效果了,但是对于数据和标签匮乏的特定任务,这种监督学习的模型的效果就很受限。
目前CV领域主流的研究一般是结合多任务学习或者基于特定的学习方式,比如域自适应(Domain Adaptation)、自监督学习(Self-supervised)、无监督学习(Unsupervised Learning)以及增量学习(Incremental Learning)等,本文主要来聊一聊自监督学习。
一、什么是自监督学习
在基于深度学习的模型中,我们一般先对数据通过主干网络Backbone来进行特征提取,比如用VGG、Resnet、Mobilenet和Inception等,然后再将提取到的Feature maps送入下游的分类、检测或者分割等任务。Backbone之所以有效是因为我们将其事先在Imagenet等数据集上进行了预训练,所以具有很强的特征提取能力。在这里,一个带标签的大数据集(比如Imagenet)是至关重要的,但如果我们在面临一个没有大量标注数据的新领域新任务时,要如何提升模型的特征提取能力呢?
自监督学习的出现回答了这个问题!
自监督学习(Self-supervised learning) 是这两年比较热门的一个研究领域,它旨在对于无标签数据 ,通过设计 辅助任务(Proxy tasks) 来挖掘数据自身的表征特性作为监督信息,来提升模型的特征提取能力(PS:这里获取的监督信息不是指自监督学习所面对的原始任务标签,而是构造的辅助任务标签)。注意这里的两个关键词:无标签数据和辅助信息,这是定义自监督学习的两个关键依据。
既然说到了自监督,我们这里也顺便将几种学习类型进行一个统一介绍:
有监督(Supervised): 监督学习是从给定的带标签训练数据集中学习出一个函数(模型参数),在输入新的测试数据时,可以根据这个函数预测结果;
无监督(Unsupervisedg): 无监督学习是从无标签数据中分析数据本身的规律性等解析特征。无监督学习算法分为两大类:基于概率密度函数估计的方法和基于样本间相似性度量的方法;
半监督习(Semi-supervised): 半监督介于监督学习和无监督之间,即训练集中只有一部分数据有标签,需要通过伪标签生成等方式完成模型训练;
弱监督(Weakly-supervised): 弱监督是指训练数据只有不确切或者不完全的标签信息,比如在目标检测任务中,训练数据只有分类的类别标签,没有包含Bounding box坐标信息。
在上述概念中,无监督和自监督学习相似性最大,两者的训练数据都是无标签,但区别在于:自监督学习会通过构造辅助任务来获取监督信息,这个过程中有学习到新的知识;而无监督学习不会从数据中挖掘新任务的标签信息。
二、自监督学习中辅助任务的构造
辅助任务(Proxy tasks)是自监督学习最关键的内容,我们接下来分别介绍自然语言处理NLP和计算机视觉CV两大类任务中的自监督学习辅助任务设计。


1、自然语言处理(NLP)

句子的语序有很强的规律性,所以自然语言处理任务中,语序信息是用来设计辅助任务的关键。常见的辅助任务主要分为以下三类:
a、单词预测(Word prediction)
通过随机删去训练集句子中的单词来构造辅助任务训练集和标签,来训练网络预测被删去的单词,以提升模型对于语序特征的提取能力。

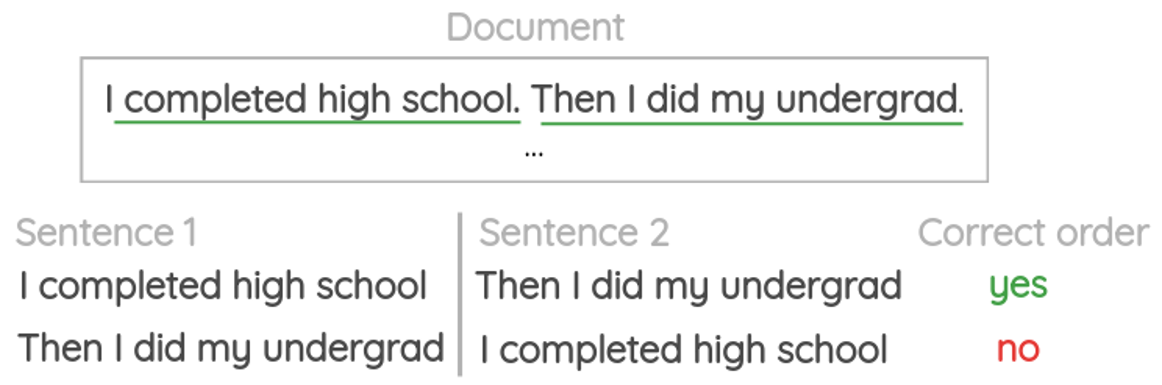
b、句子序列预测(Sentence sequence prediction)
通过随机打乱每段话中的句子顺序来构造辅助任务训练集,来训练网络对句子进行正确的排序,标签为原来正确的句子顺序。
c、词序列预测(Word sequence prediction)
打乱正常语句中的单词顺序,让模型学习组句,标签信息为原来正确的词序。

2、计算机视觉(CV)
我们将计算机视觉任务根据输入信息的不同分为图像任务和视频处理任务,来分别介绍其自监督学习中的辅助任务设计。
part 1: 图像任务
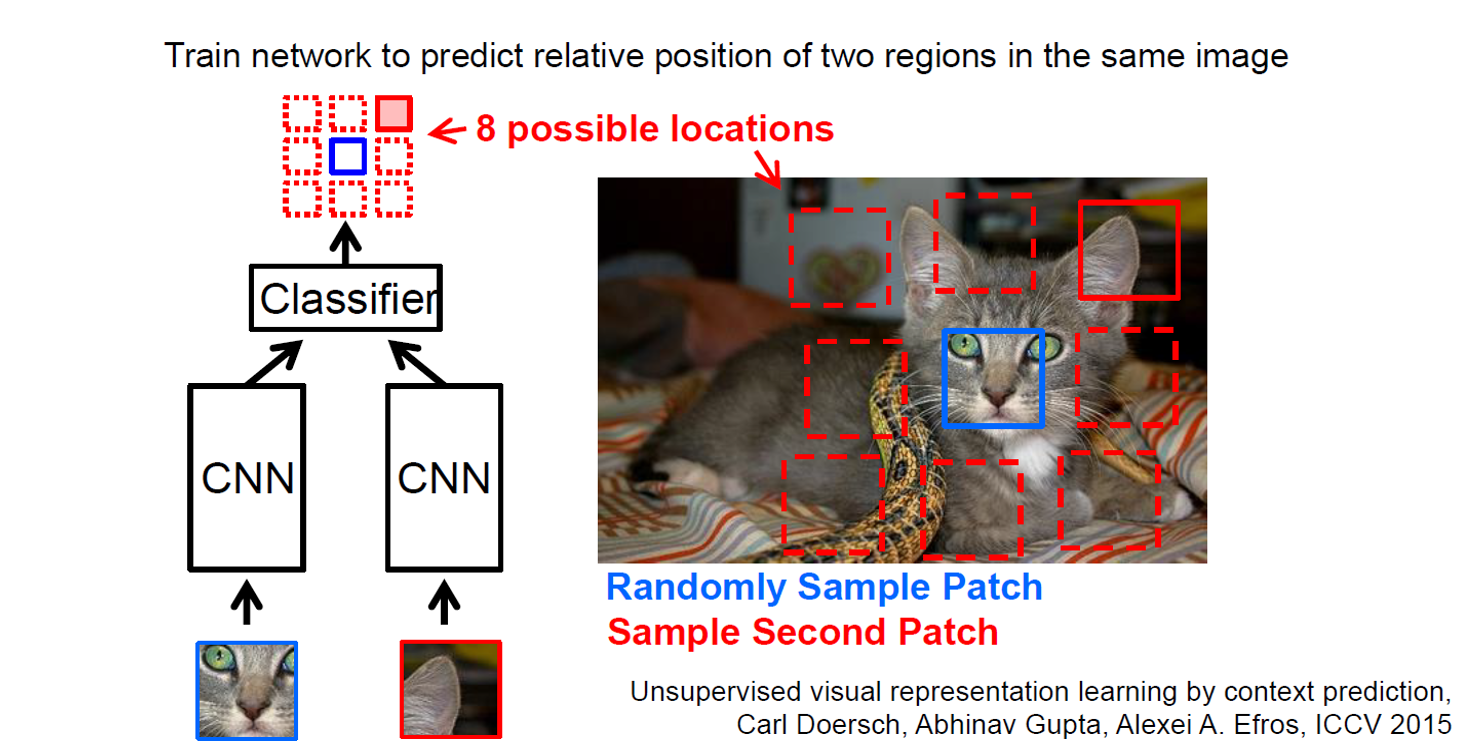
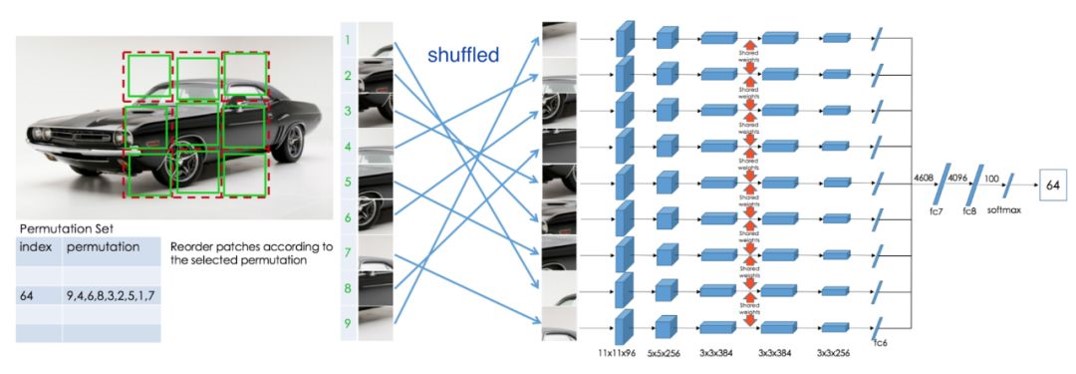
a、图像重组(Jigsaw Puzzles)
将图像分为不同的patch,比如九宫格,然后让网络预测不同patch的相对位置信息。这个过程中可以提高模型的局部特征提取能力以及全局空间信息提取能力。
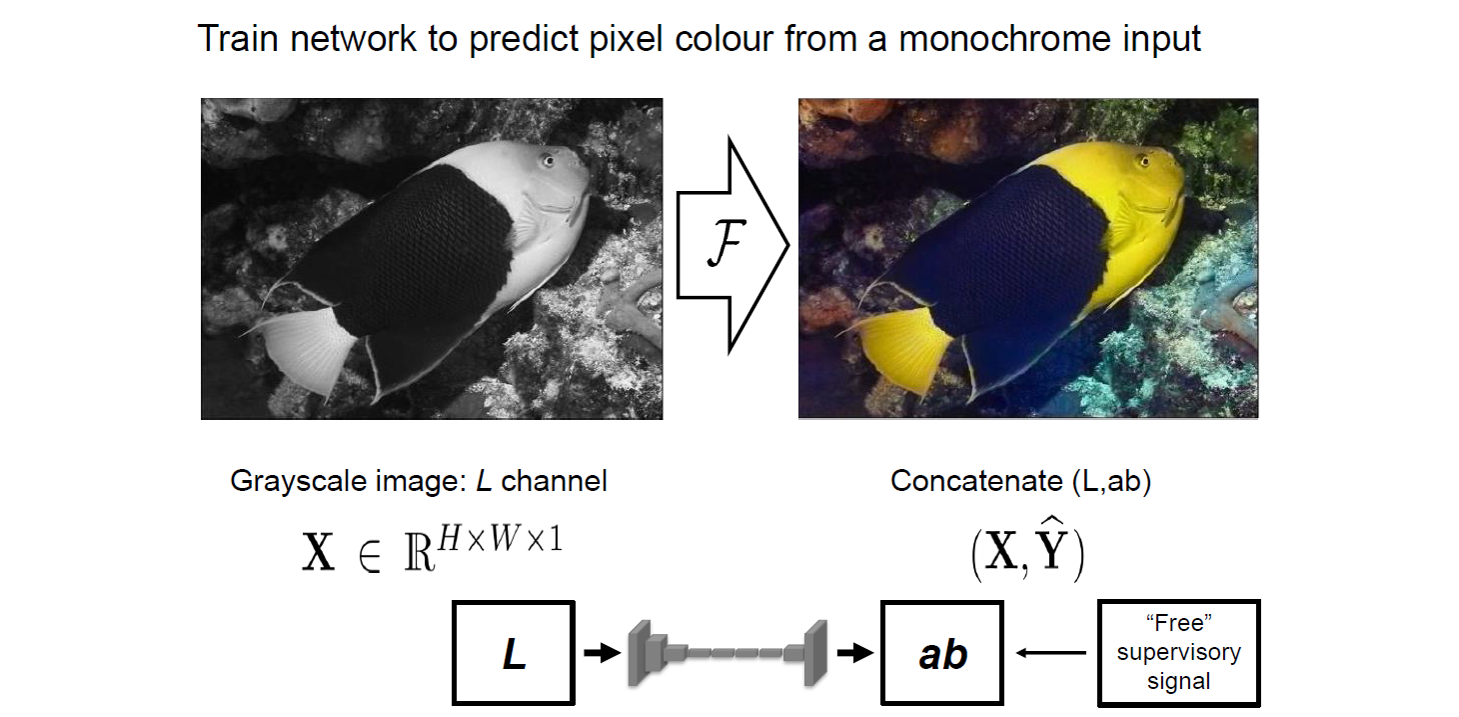
b、图像渲染(Image Colorization)
将原来数据集中的RGB图像进行灰度化处理,然后通过图像色彩恢复任务来训练网络
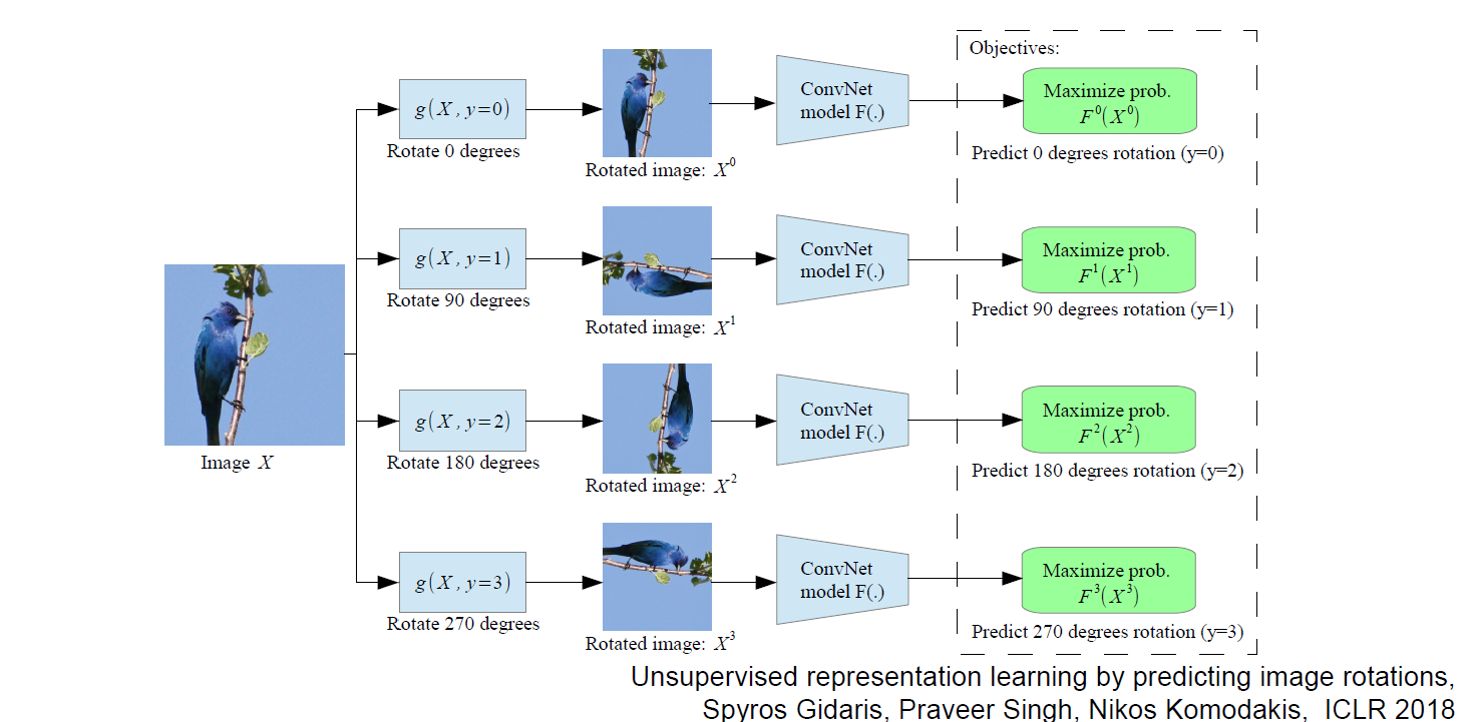
c、图像旋转角度预测(Image Colorization)
将训练集中的图像进行随机旋转,然后通过旋转角回归任务来训练网络
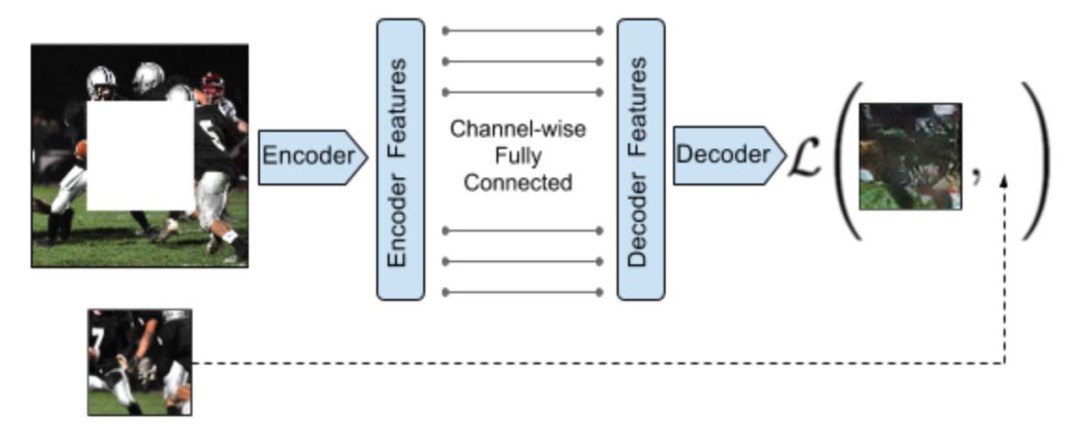
d、图像修复(Image In-painting)
对图像进行随机裁剪,训练网络修复图像

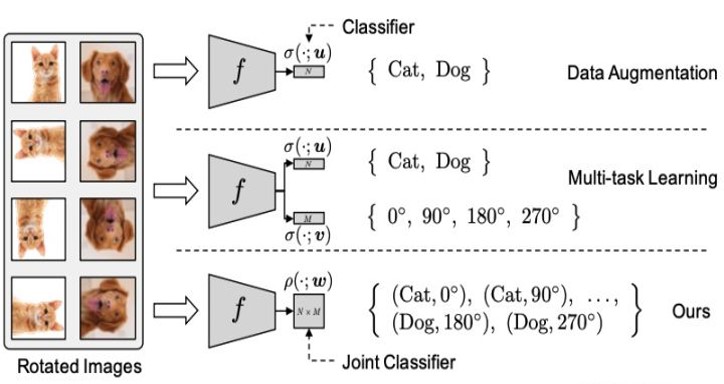
e、多任务学习(Multi-Tasks)
结合上述的几种辅助任务一起对模型进行训练
part2:视频处理任务
视频是一系列图像帧的时间序列,哪些信息可用于设计辅助任务呢?
我们知道,时序相邻帧之间具有很强的关联信息,较远帧之间的关联较弱,所以视频帧的时序信息是我们可以用到的一个重要设计依据;此外,视频中的目标物体在不同时序帧中具有一致性,比如色彩、形状等,所以这也可以作为一个辅助任务设计的重要依据。
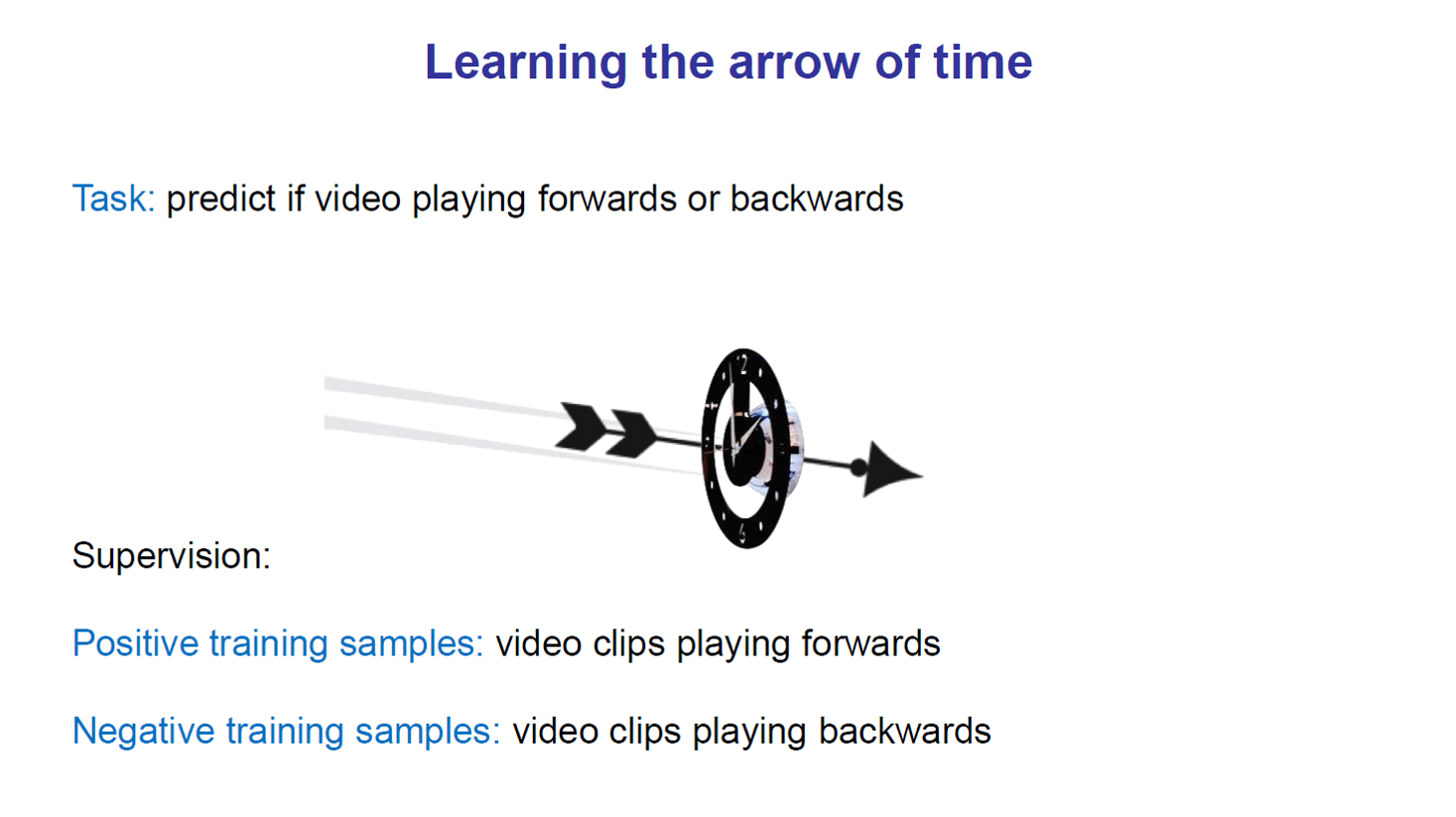
a、基于视频帧的序列信息
这个跟自然语言处理中的语序预测很相似,我们通过随机打乱训练集中视频帧的顺序,来训练网络让其对正确视频时序进行预测
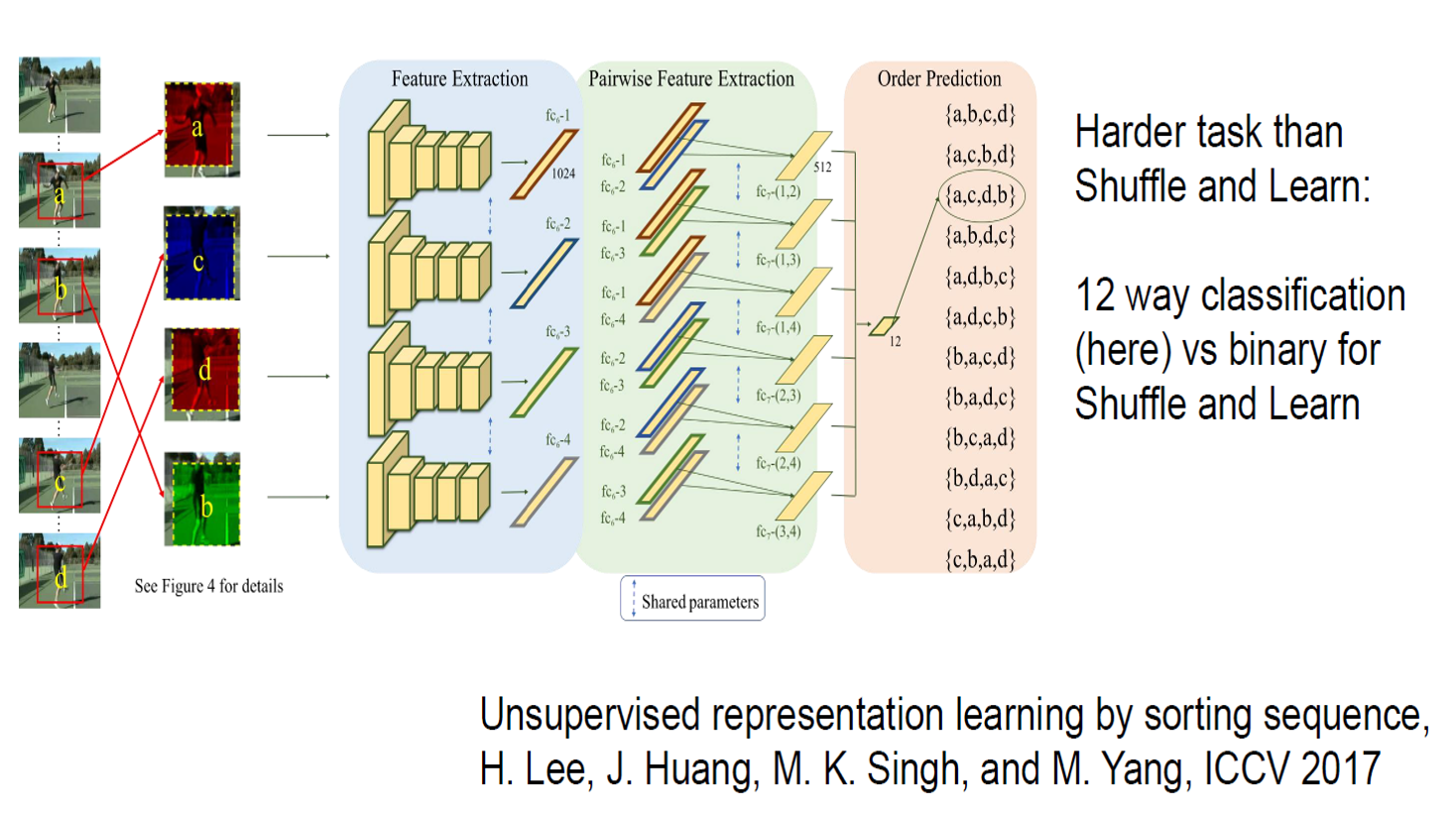
b、基于视频中目标的相似性
一般来说,视频相邻帧中目标相似性比较高,相隔较远帧中目标相似性比较低,所以可以训练网络判断不同帧中目标的相似性来提升其特征提取能力
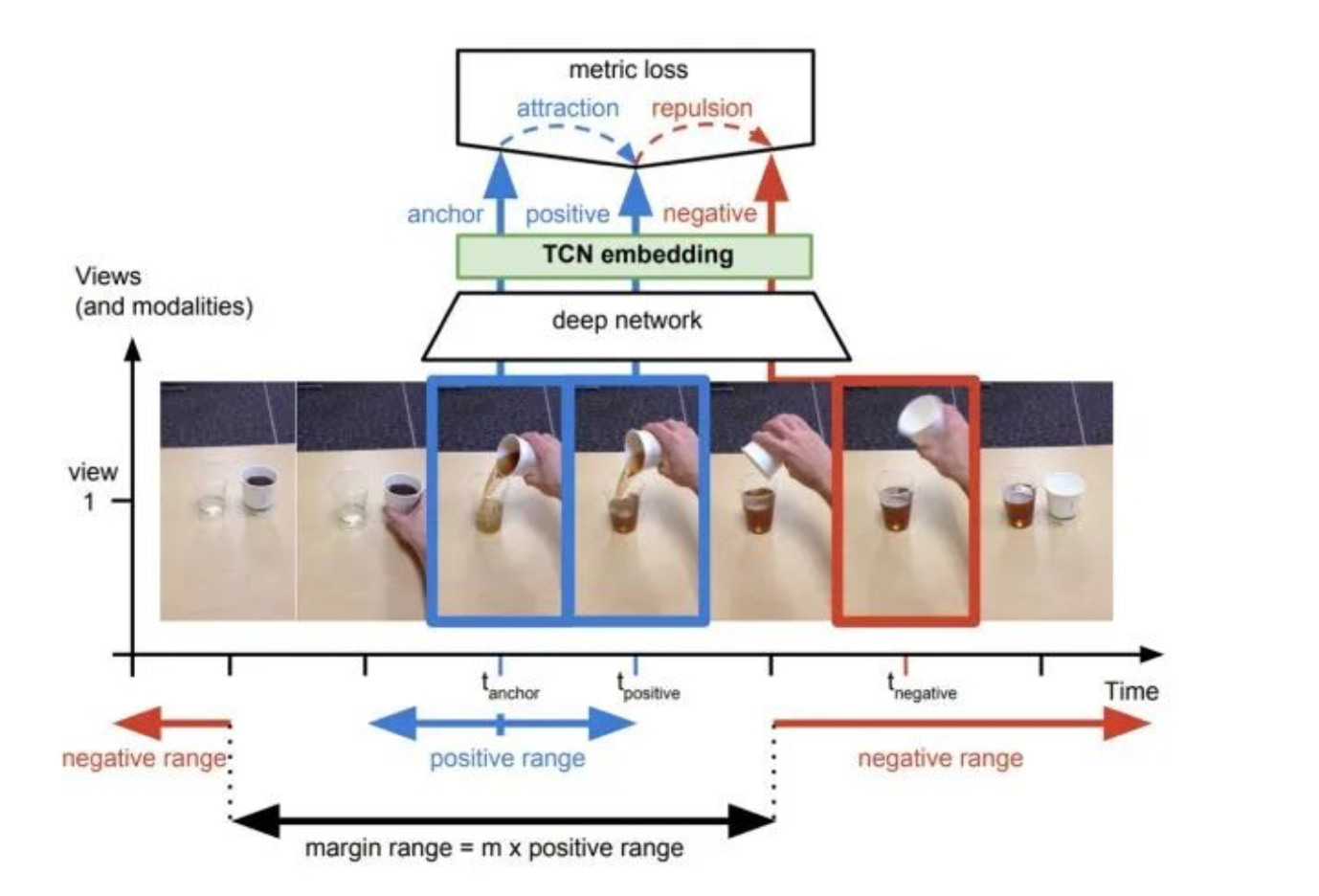
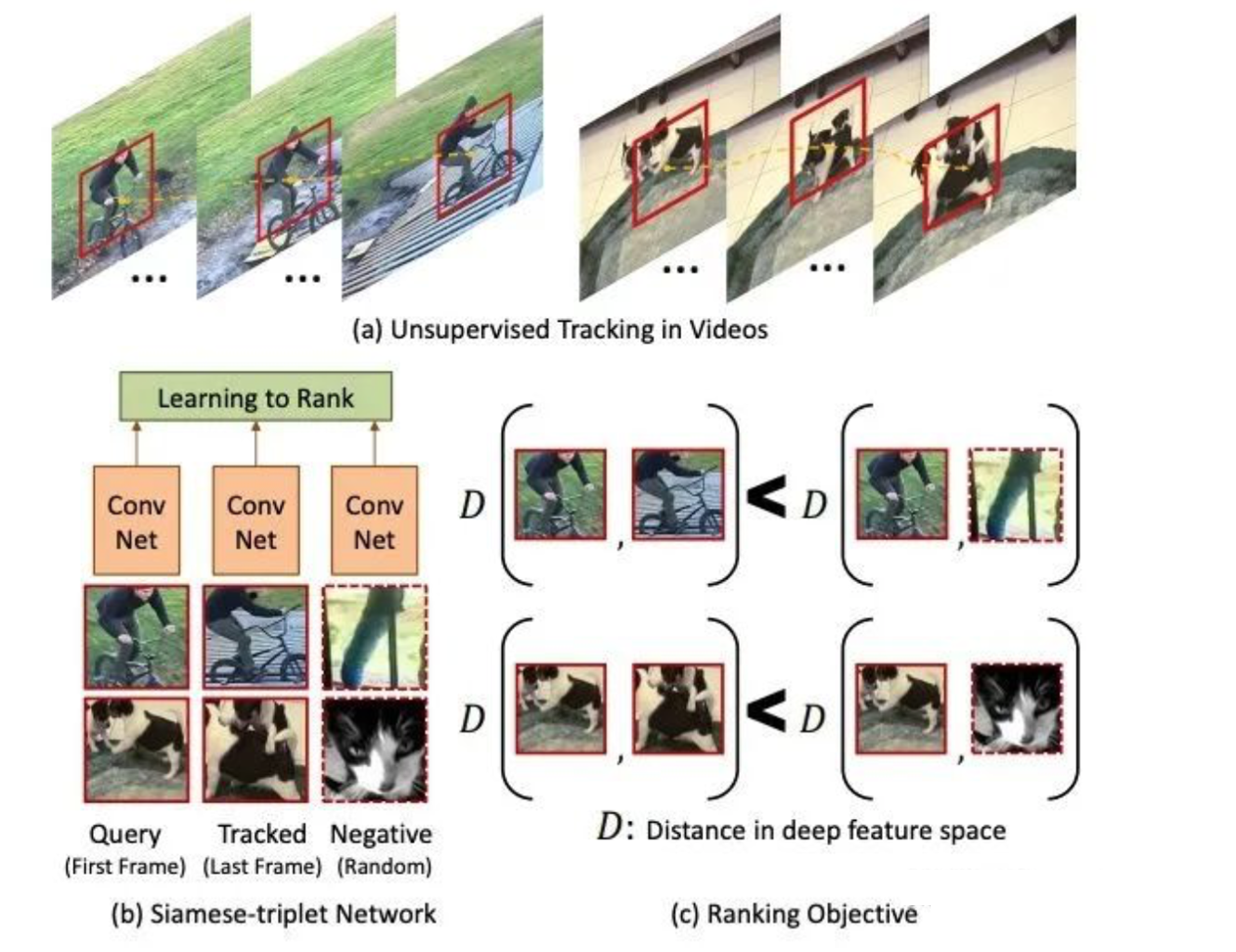
c、基于无监督目标跟踪
视频中同一物体在不同帧的特征应该是相似的,而不同物体的特征是不同的。可以根据无监督模型获得目标跟踪框,然后让网络学习同一目标和不同目标在不同帧中的相似性判别来提升特征提取能力
三、总结
以上介绍的主要为自监督学习中一些比较经典的辅助任务设计,在实际的任务中,如何根据自己的数据特点来设计有效辅助任务是自监督学习的关键,也是其难点。
在设计自监督辅助任务时,以下三点需要考虑:
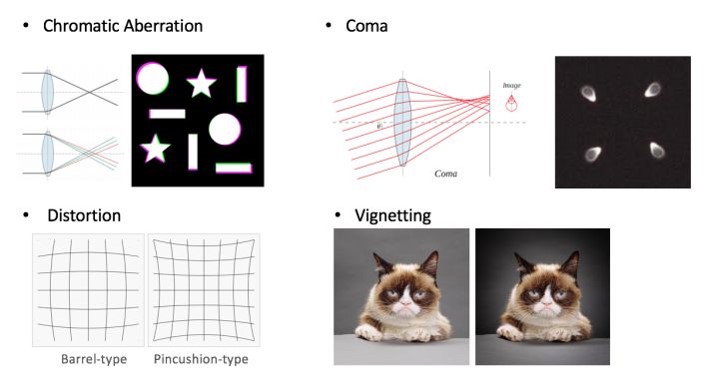
1、Shotcuts: 根据自己的数据和任务特点设计辅助任务,常常有事半功倍的效果。比如对于镜头检测任务来说,获取成像色差、镜头畸变以及暗角等信息来构造辅助任务是比较有效的
2、辅助任务的复杂度选择: 之前人们的实验结果表明,辅助任务并不是越复杂越有效,比如图像重组任务中,最优的patch数为9,patch太多会导致每个patch特征过少,并且相邻patch间的差异性不大,导致模型的学习效果并不好

3、模糊性: 模糊性是指设计的辅助任务的标签必须是唯一确定的,不然会给网络学习引入噪声,影响模型性能。比如在动作预测中,这个半蹲的动作就具有二义性,因为其下个状态有可能是蹲下,也有可能是正在站起,标签不具有唯一性

参考文献
[1] 自监督学习(Self-supervised Learning)
[2] EEML summer school–self-supervised learning_Zisserman
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/193794.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
