大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
1、Scrapy是什么
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理
或存储历史数据等一系列的程序中。
2、scrapy安装
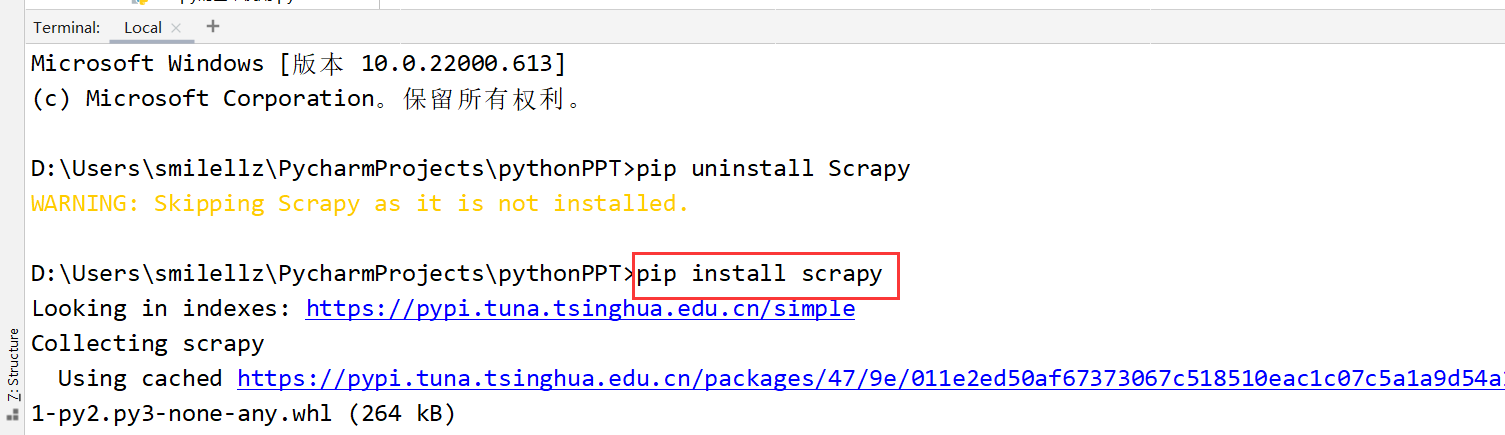

安装过程中出错:
如果安装出现一下错误
building ‘twisted.test.raiser’ extension
error: Microsoft Visual C++ 14.0 is required. Get it with “Microsoft Visual C++
Build Tools”: http://landinghub.visualstudio.com/visual‐cpp‐build‐tools
解决方案:
http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
下载twisted对应版本的whl文件(如我的Twisted‐17.5.0‐cp37‐cp37m‐win_amd64.whl),cp后面是
python版本,amd64代表64位,运行命令:
pip install C:\Users…\Twisted‐17.5.0‐cp37‐cp37m‐win_amd64.whl
pip install scrapy
3、scrapy项目的创建以及运行
3.1scrapy项目的创建
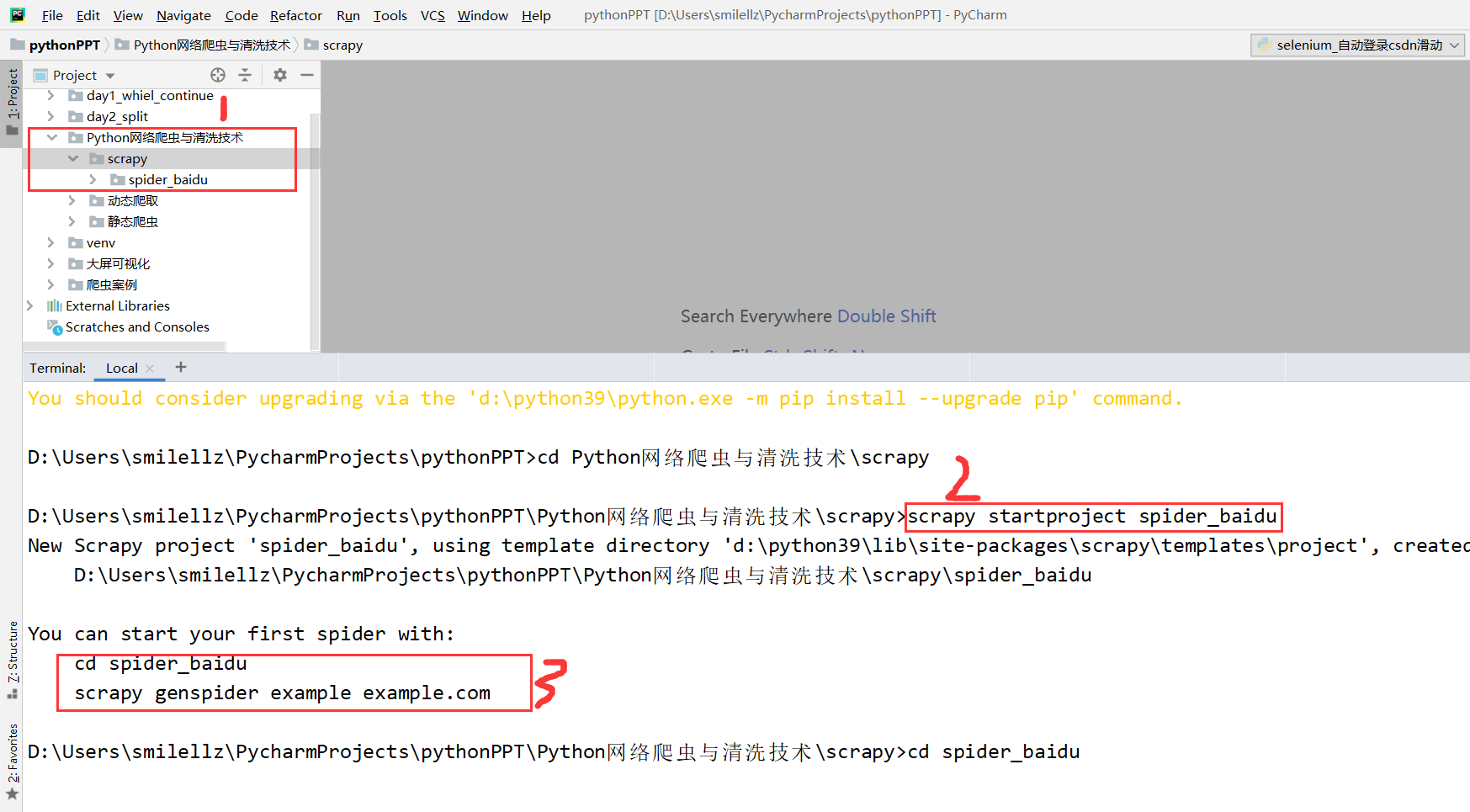
在pycharm终端通过cd命令进入创建项目路径下的文件夹,然后创建一个名为spider_baidu项目(注意:项目名称的定义务必不出现中文)。
创建项目步骤如下图所示:
创建成功后该项目忽然多了5个python文件,如图所示:
You can start your first spider with:
cd spider_baidu
scrapy genspider example example.com
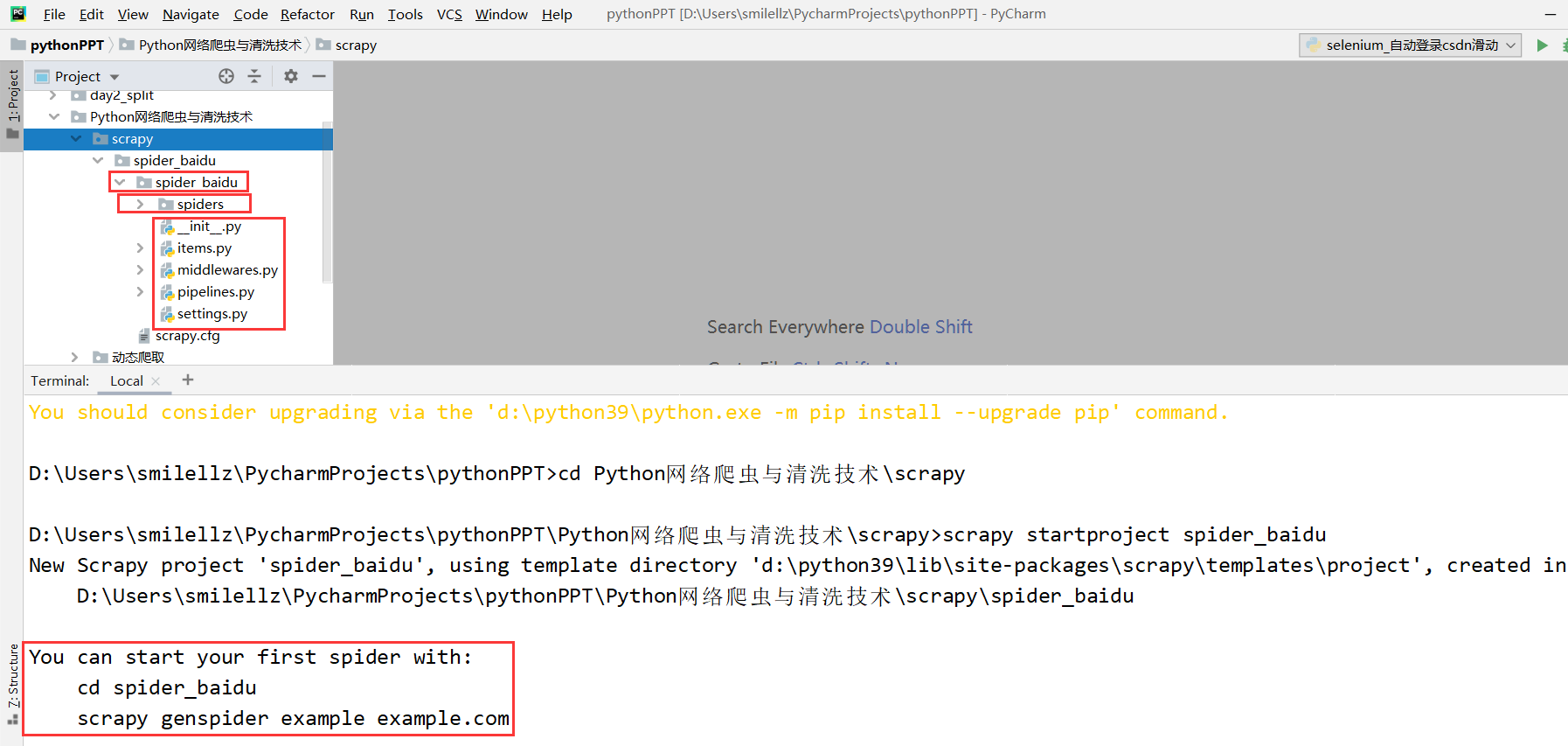
因此该项目(spider_baidu)组成:
spider_baidu
init.py
自定义的爬虫文件.py ‐‐‐》 由我们自己创建,是实现爬虫核心功能的文件
init.py items.py ‐‐‐》定义数据结构的地方,是一个继承自scrapy.Item的类
middlewares.py ‐‐‐》中间件 代理
pipelines.py ‐‐‐》管道文件,里面只有一个类,用于处理下载数据的后续处理默认是300优先级,值越小优先级越高(1‐1000)
settings.py ‐‐‐》配置文件 比如:是否遵守robots协议,User‐Agent定义等
4.创建爬虫文件:
(1)进入到spiders文件夹
cd 目录名字/目录名字/spiders
(2)scrapy genspider 爬虫名字 网页的域名
现以百度网站为例:
eg:scrapy genspider baidu https://www.baidu.com/
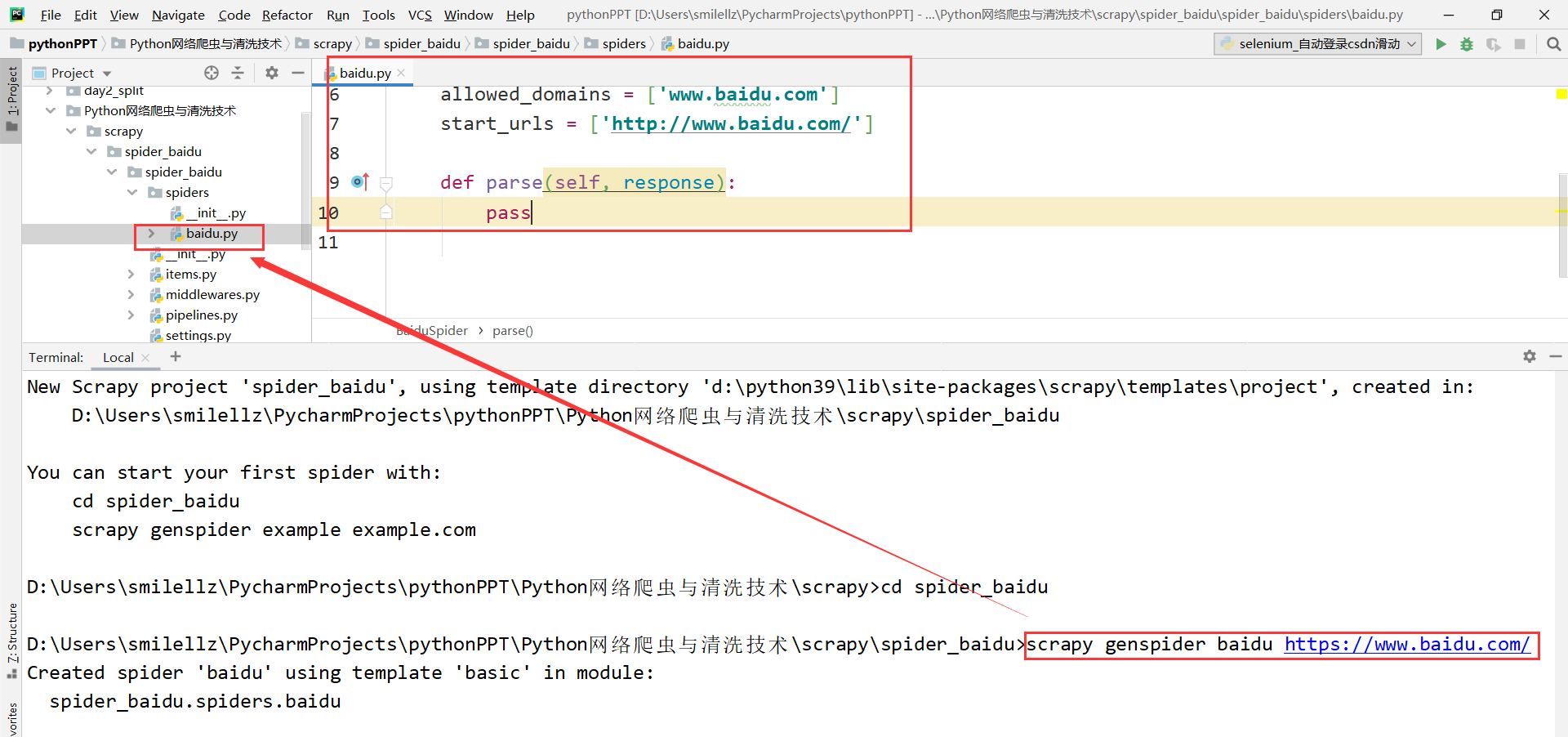
spider文件目录下出现baidu.py文件,点击后可以看到自动生成内容:
baidu.py爬虫文件的基本组成:
继承scrapy.Spider类
name = ‘baidu’ ‐‐‐》 运行爬虫文件时使用的名字
allowed_domains ‐‐‐》 爬虫允许的域名,在爬取的时候,如果不是此域名之下的url,会被过滤掉
start_urls ‐‐‐》 声明了爬虫的起始地址,可以写多个url,一般是一个
parse(self, response) ‐‐‐》解析数据的回调函数
5.运行爬虫文件:
scrapy crawl 爬虫名称
eg:scrapy crawl baidu
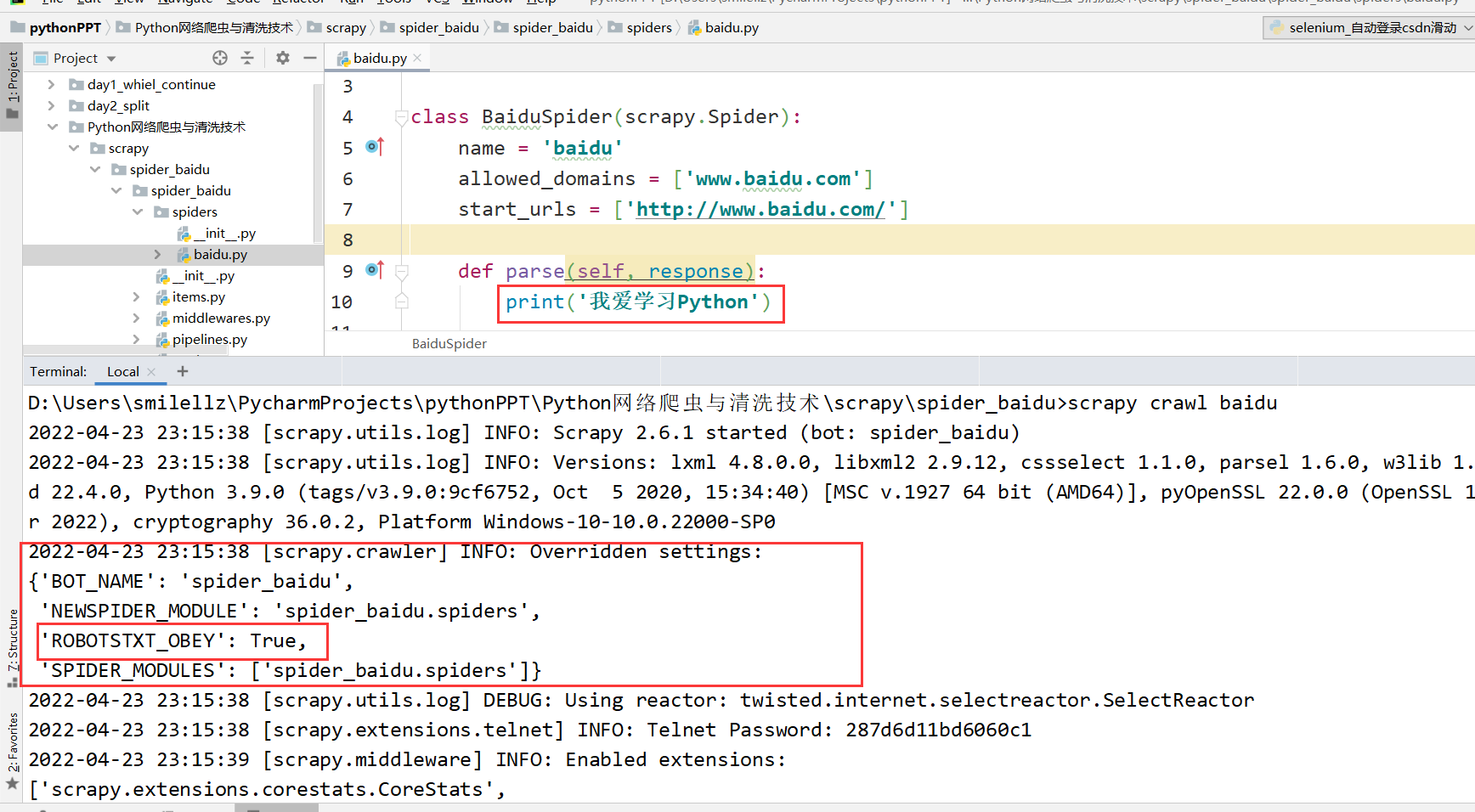
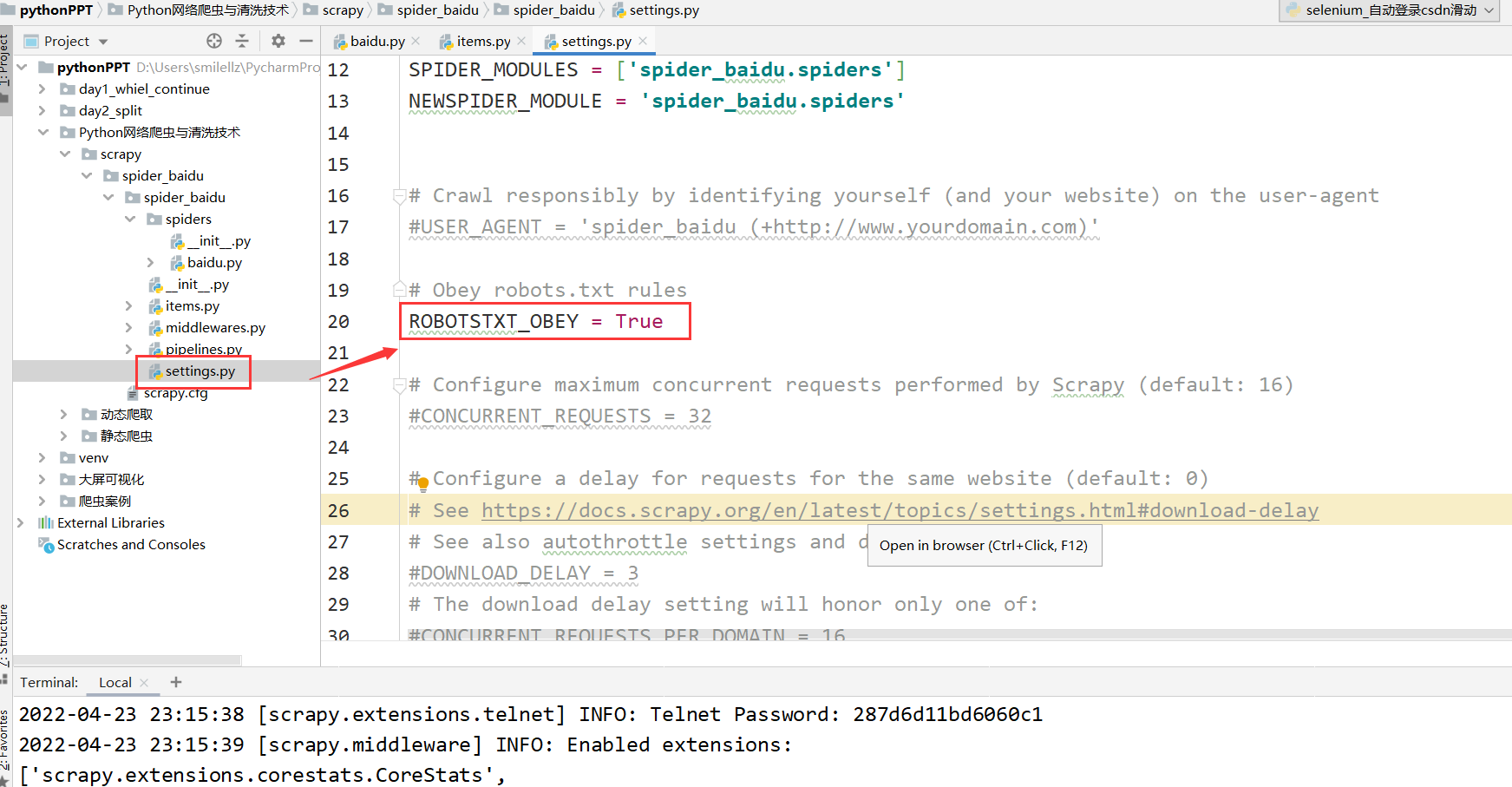
以上出现报错,只需在settings.py文件把ROBOTSTXT_OBEY = True注释掉再运行即可
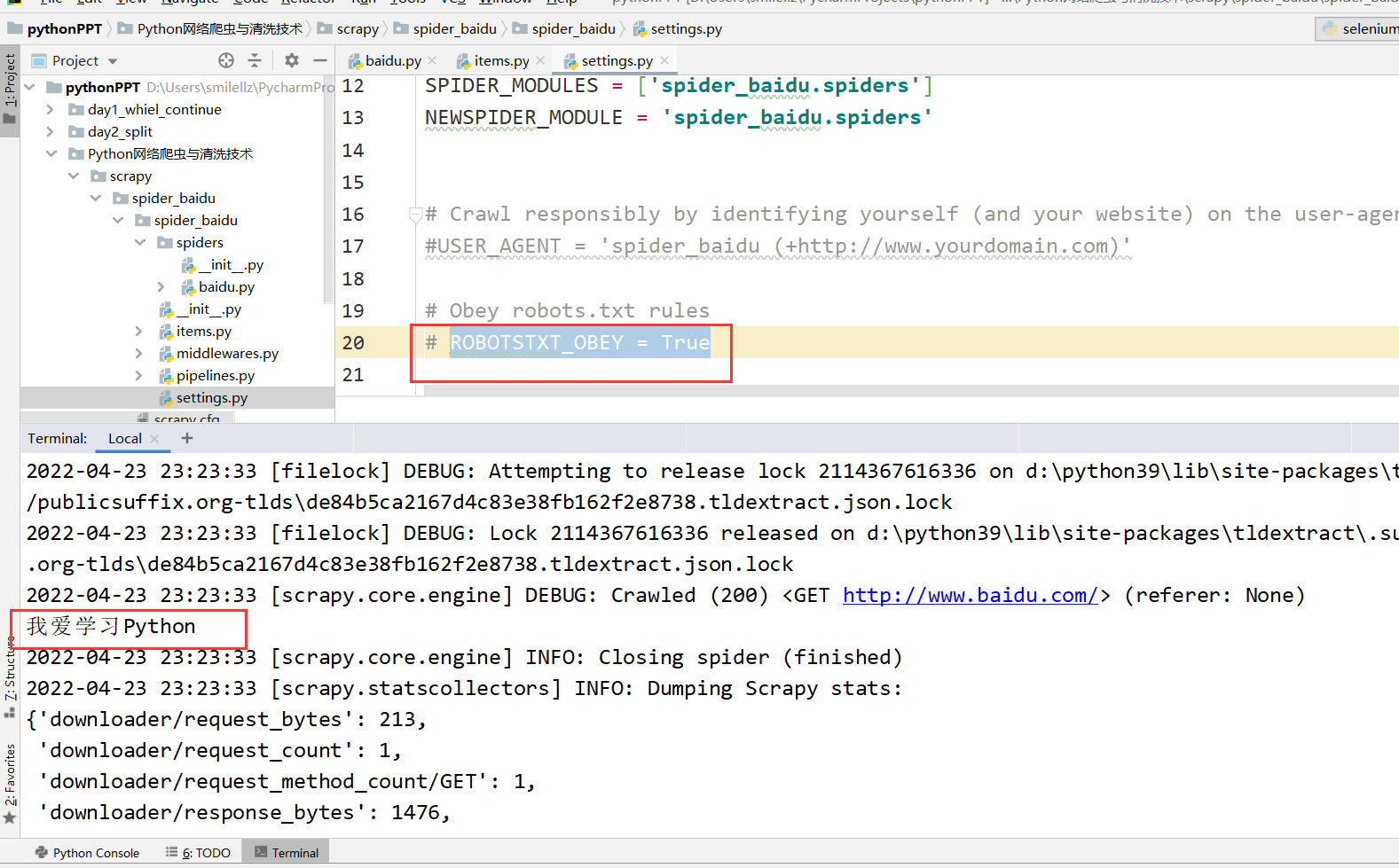
再运行之后,如下图所示:
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/193742.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
