大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
前言
众所周知,hashmap和Arraylist作为java中非常重要的一种数据结构,应用场景非常广泛,这篇文章主要针对HashMap和ArrayList的扩容机制进行分析。
HashMap扩容机制分析
在说HashMap扩容机制之前,有必要简述下HashMap的基本结构。以便各位更加清除的理解HashMap的底层是如何扩容的。HashMap自JDK1.8之后结构采用数组+单链表【单链表长度达到8后结构转化为红黑树】。所以从结构上进行分析,HashMap的最基本结构只有两种。要么是数组元素+单链表,要么是数组元素+红黑树.当然一个HashMap可以有这两个结构同时存在。下面就着重叙述HashMap底层的扩容了。
了解HashMap的读者都知道HashMap的初始化大小是16,至于为什么是16,可以参看我之前的博客。
这里不在叙述。
HashMap如何扩容呢?下面来看看HashMap 底层扩容源码!
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
if (table == null) { // pre-size
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold) // 这个是HashMap对象的阈值,默认是0.75*16.只要put操作进行的时候,一旦HashMap存放的数据的大小超过阈值,就一定会扩容。
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
下面接着来看下JDK1.8扩容方法的源码!
在这里扩容不是直接原来的结构上进行顺序性的增加,而是先计算扩容之后的容量。然后重新建一个容量大小数组,在将原数组的元素按照指定的方式加入到新的数组当中去!
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if (( newCap = oldCap << 1 ) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY) // 这里就是扩容的具体实现。 newCap = oldCap << 1 ,这个步骤对原来的容量扩大一倍!并且如果原来容量不小于16*0.75,则会对新HashMap阈值也扩大一倍!
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e; // 用于存放对象的节点
if ((e = oldTab[j]) != null) { // 获取hashMap的第j个存储位置的节点对象,如果不为空,则清空处理。
oldTab[j] = null;
if (e.next == null) // 如果该节点的下一个节点为空。说明该链表长度为1.
newTab[e.hash & (newCap - 1)] = e; // 将这个节点放入e.hash()&(newCap-1)的存储位置上。
else if (e instanceof TreeNode) //如果该节点是树形节点对象。
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // 这里就是链表结构。
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
//为什么使用do while 因为前面已经进行了多次判断,到这里链表的长度一定是大于1的。因此一定可以获取下一个节点。
do {
next = e.next; //获取下一个节点并存放至 next中
if ((e.hash & oldCap) == 0) { //原来的hash值新增的那个bit还是0,是0的话存储的索引不变
if (loTail == null) // 初始化
loHead = e; //将该节点设为头结点。
else
loTail.next = e;
loTail = e; //将当前节点设为尾节点用于下一次链表链接。
}
else { //原来的hash值新增的那个bit不为0,存储的索引位置为 j+OldCap
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null); //遍历循环值最后一个节点
if (loTail != null) { // 如果临时节点数据还在,清空临时节点
loTail.next = null;
newTab[j] = loHead; // 将这个节点放入新数组的第j个存储位置上。
}
if (hiTail != null) {// 如果临时节点数据还在,清空临时节点
hiTail.next = null;
newTab[j + oldCap] = hiHead; // 将这个节点放在新数组的第j+oldCap的存储位置上。
}
}
}
}
}
return newTab;
}
附上测试代码:
package DataStruct;
import java.util.HashMap;
import java.util.Map;
public class HashMapResize {
/**
* this is A class for the HashMapResize test
*/
static void Resize() {
Map<String, String> hashMap = new HashMap<String, String>();
for(int i=0;i<20;i++) {
hashMap.put(String.valueOf(i),"AAA");
}
}
public static void main(String[] args) {
Resize();
}
}
看图:运行四次之后的结果:
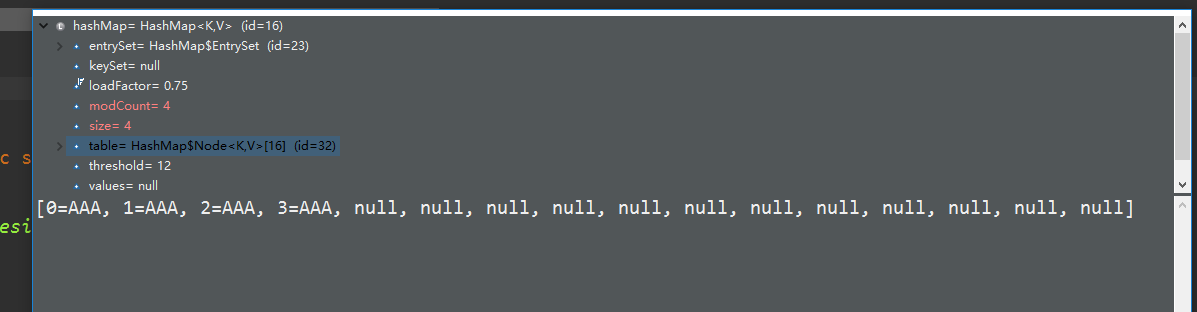
 清晰的看见,这里面的容量就是16.
清晰的看见,这里面的容量就是16.
继续运行size=12.查看结果:
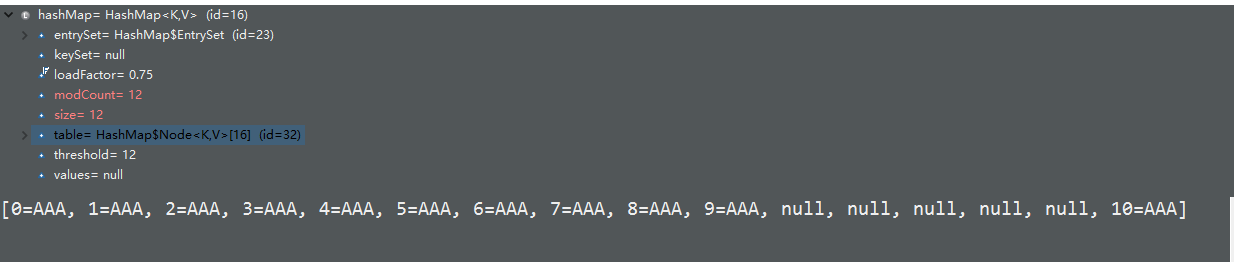
容量还是为16。在运行一次查看结果:
 可以看到容量就变为32了.阈值也翻倍了。
可以看到容量就变为32了.阈值也翻倍了。
ArrayList扩容机制
和这个差不过。扩容的大体思想都是一样的,但是比HashMap简单的多。不过是ArrayList的初始容量为10.
还有扩容的之后的容量是NewLength=OldLength+OldLength>>1;
附上相关源码:
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
这个源码相对简单!读者可以自己看懂!
就写这么多了。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/193307.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
