大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
目录
根据yolov4文献中提到的cutout数据增广方式,进行扩展阅读。Cutout & Random Erasing
1、Cutout
论文地址:https://arxiv.org/pdf/1708.04552.pdf
代码地址:https://github.com/Dingzixiang/cutout/blob/master/cutout.py
出发点:
文章的出发点除了解决遮挡问题外,还有从dropout上得到启发。众所周知,Dropout随机隐藏一些神经元,最后的网络模型相当于多个模型的集成。类似于dropout的思路,这篇文章将drop用在了输入图片上,并且drop掉连续的区域——即矩形区域。以下是一个简易的样例(灰色部分为drop掉的区域):


方法:
作者首先尝试通过一些可视化技术,发现图片高激活区域,对这些区域进行擦除。但是最后发现这种方法和随机选一个区域遮挡效果差别不大,而且带来了额外的计算量,得不偿失,便舍去。上图为早期的cutout擦除样例图,可以发现这种方法有针对性地擦除重要区域。本文最后采用的擦除方式为:利用固定大小的矩形对图像进行遮挡,在矩形范围内,所有的值都被设置为0,或者其他纯色值。而且擦除矩形区域存在一定概率不完全在原图像中的(文中设置为50%)。

实现代码:
# cutout.py
import numpy as np
import tensorflow as tf
def cutout(img, num_holes=1, length=4):
"""
Args:
img (Tensor): Tensor image of size (H, W, C). input is an image
Returns:
Tensor: Image with n_holes of dimension length x length cut out of it.
"""
h = img.shape[0]
w = img.shape[1]
c = img.shape[2]
mask = np.ones([h, w], np.float32)
for _ in range(num_holes):
y = np.random.randint(h)
x = np.random.randint(w)
y1 = np.clip(max(0, y - length // 2), 0, h)
y2 = np.clip(max(0, y + length // 2), 0, h)
x1 = np.clip(max(0, x - length // 2), 0, w)
x2 = np.clip(max(0, x + length // 2), 0, w)
mask[y1: y2, x1: x2] = 0
mask = tf.expand_dims(mask, 2)
mask_list = []
for _ in range(c):
mask_list.append(mask)
mask = tf.concat(mask_list, axis=2)
img = img * mask
return img
input = tf.get_variable('v1', [1,10,10,3], dtype=tf.float32)
print(input)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(input.get_shape()[0]):
output = cutout(input[i], num_holes=1, length=4)
print(output.eval())效果:
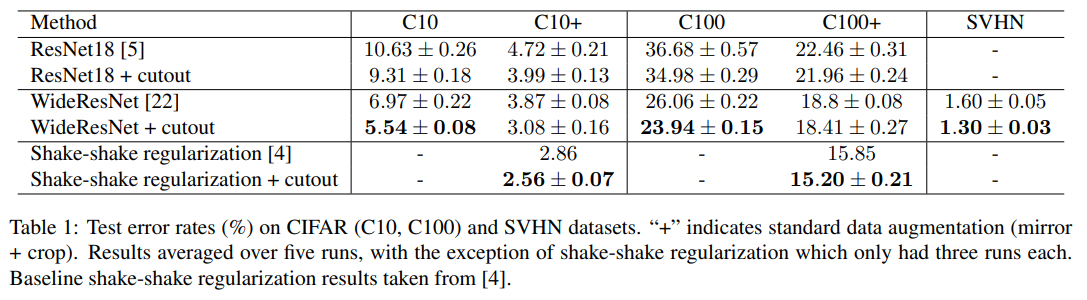
在C10,C10+,C100,C100+,SVHN数据集上的test error rates表现如下(其中C表示CIFAR)。与Random Erasing非常类似,两篇论文发表时间为16NOV2017和29NOV2017,也是因为这个时间点才能同时发表,不然大概率会认为是抄袭。最主要的区别在于在cutout中,擦除矩形区域存在一定概率不完全在原图像中的。而在Random Erasing中,擦除矩形区域一定在原图像内。Cutout变相的实现了任意大小的擦除,以及保留更多重要区域。不过Cutout在更多情况下效果更好。这两种方法在用到自己的任务中,还得进行实验比较,才能得到更好的结果。
2、Random Erasing
论文地址:https://arxiv.org/pdf/1708.04896.pdf
代码地址:https://github.com/zhunzhong07/Random-Erasing
出发点:
为了增强模型泛化能力,常常对原始数据做数据增强处理,常用的方式一般为random cropping,flipping等。但是在现实场景中,遮挡问题一直都是一个难以处理和解决的问题。为了更好的实现对遮挡数据的模拟,利用Random Erasing的方式,将原数据集中一部分保持原样,另外一部分随机擦除一个矩形区域。效果图如下:

方法:
上图是对Random Erasing的一个简单样例,灰色区域表示擦除的部分。具体实现算法为:我们可以简单的解释为:
1) 设立五个超参数,分别表示原数据集中实施Random Erasing的概率P,擦除面积比率的下界sl和上界sh,擦除矩形长宽比的下界r1和上界r2。
2) 首先通过均匀分布得到一个概率P1,如果满足条件,实施擦除。
3) 擦除的过程如下:通过均匀分布取样得到擦除矩形面积,以及长宽值。选择一个满足所有矩形部分都在图像内的左上角坐标,将这个矩形区域都设置为统一的和图像其他区域无关的纯色值。

结果:
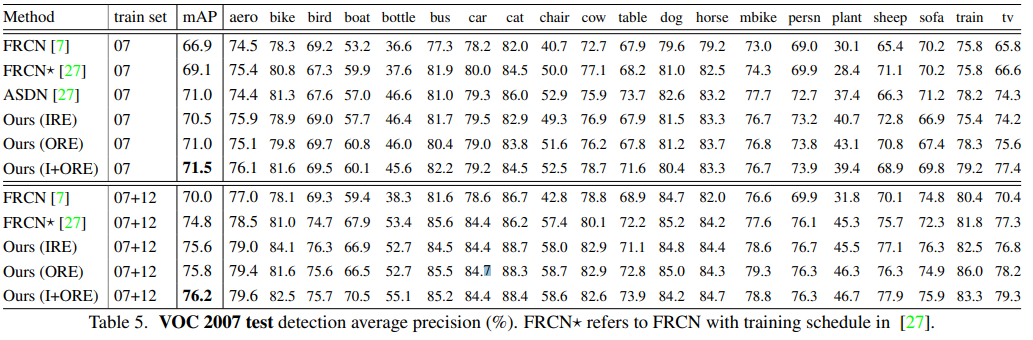
虽然十分简单,但是效果非常惊艳。对处理遮挡问题非常有帮助,是涨分的利器。分类、检测、识别任务上表现出色,下面贴出目标检测上VOC2007数据集测试效果。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/193254.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
