大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
在写论文做数据测试时有用到一个nmi(normalized mutual information)评价聚类的一种方法,不是很清楚,然后上网找了一下资料。
首先在理解nmi前,先说说mutual information这个东西。
我们先举个例子:
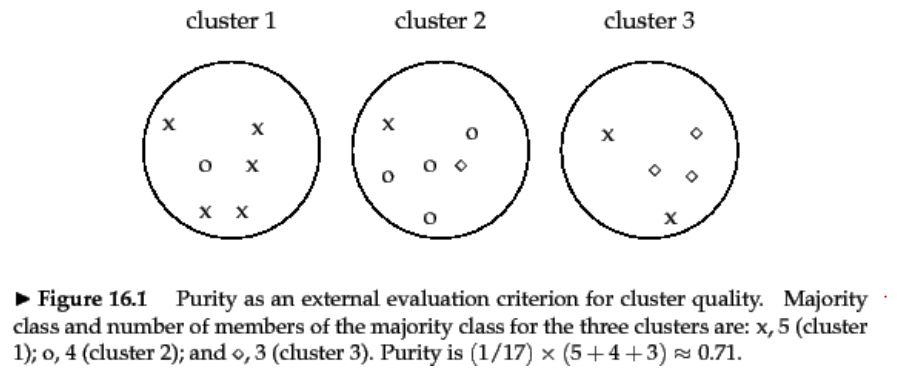

比如说,标准结果是大圆里面的叉叉圈圈点点,上图呢是我们算法聚类出来的结果,那么如何来看我们算法的聚类效果呢,如何计算呢?
我们把上图中的图形用字母来表示出来,集合A是标准的聚类结果,集合B是我们算法的聚类结果,如下:
A:{(aaaaaa),(bbbbbb),(ccccc)}
B:{(aaaaab),(abbbbc),(accca)}
可以按照下列公式来计算:
I ( X , Y ) = ∑ y ∈ Y ∑ x ∈ X p ( x , y ) l o g p ( x , y ) p ( x ) p ( y ) I(X,Y)=\sum_{y\in Y}\sum_{x\in X} p(x,y)log\frac{p(x,y)}{p(x)p(y)} I(X,Y)=∑y∈Y∑x∈Xp(x,y)logp(x)p(y)p(x,y)
分子 p ( x , y ) p(x,y) p(x,y)是 x x x, y y y的联合分布概率
p ( 1 , 1 ) = 5 17 p ( 1 , 2 ) = 1 17 p ( 1 , 3 ) = 0 p(1,1)=\frac{5}{17}\quad p(1,2)=\frac{1}{17}\quad p(1,3)=0 p(1,1)=175p(1,2)=171p(1,3)=0
p ( 2 , 1 ) = 1 17 p ( 2 , 2 ) = 4 17 p ( 2 , 3 ) = 1 17 p(2,1)=\frac{1}{17}\quad p(2,2)=\frac{4}{17}\quad p(2,3)=\frac{1}{17} p(2,1)=171p(2,2)=174p(2,3)=171
p ( 3 , 1 ) = 2 17 p ( 3 , 2 ) = 0 p ( 3 , 3 , ) = 3 17 p(3,1)=\frac{2}{17}\quad p(3,2)=0\quad p(3,3,)=\frac{3}{17} p(3,1)=172p(3,2)=0p(3,3,)=173
p(x)是标准集合中字母占比 p(y)是我们算法所得聚类集合中字母的占比。p(x,y)中我们可以把x看作是聚类的序号,把y看作是聚类中叉叉点点圈圈的标记数。也就是对于p(x,y)我们还考虑了叉叉点点圈圈在某一个范围中(某个聚类)占了总数的比例,所以如果x=y,p(x)也不一定等一p(y),因为x和y两个参数的属性是不一样的。
p ( x ) : p(x): p(x): p ( 1 ) = 6 17 p ( 2 ) = 6 17 p ( 3 ) = 5 17 p(1)=\frac{6}{17}\quad p(2)=\frac{6}{17}\quad p(3)=\frac{5}{17} p(1)=176p(2)=176p(3)=175
p ( y ) : p(y): p(y): p ( 1 ) = 8 17 p ( 2 ) = 5 17 p ( 3 ) = 4 17 p(1)=\frac{8}{17}\quad p(2)=\frac{5}{17}\quad p(3)=\frac{4}{17} p(1)=178p(2)=175p(3)=174
这样就可算出MI(mutual information)的值了
nmi(normalized mutual information)公式如下:
∗ ∗ U ( X , Y ) = 2 I ( X , Y ) H ( X ) + H ( Y ) ∗ ∗ **U(X,Y)=2\frac{I(X,Y)}{H(X)+H(Y)}** ∗∗U(X,Y)=2H(X)+H(Y)I(X,Y)∗∗
其目的是为了让MI的值调整到0到1之间, H ( X ) , H ( Y ) H(X),H(Y) H(X),H(Y)分别为 X , Y X,Y X,Y的熵:
H ( X ) = ∑ i i = n p ( x i ) I ( x i ) = ∑ i i = n l o g b 1 p ( x i ) = − ∑ i i = n p ( x i ) l o g b p ( x i ) H(X)=\sum_i^{i=n} p(x_i)I(x_i)=\sum_i^{i=n}log_b\frac{1}{p(x_i)}=-\sum_i^{i=n}p(x_i)log_bp(x_i) H(X)=∑ii=np(xi)I(xi)=∑ii=nlogbp(xi)1=−∑ii=np(xi)logbp(xi)( b = 2 b=2 b=2)
还有一种理解方法,
NMI(A,B)= 2 I ( A , B ) H ( A ) + H ( B ) 2\frac{I(A,B)}{H(A)+H(B)} 2H(A)+H(B)I(A,B),而 I ( A , B ) I(A,B) I(A,B)是A,B两向量的MI,H(A)是A的信息熵。
I ( A , B ) = H ( A ) − H ( A ∣ B ) = H ( B ) − H ( B ∣ A ) I(A,B)=H(A)-H(A|B)=H(B)-H(B|A) I(A,B)=H(A)−H(A∣B)=H(B)−H(B∣A);直觉上,如果已知了B的情况,A的信息熵相对于H(A|B)相对于H(A)就要小一点,因为不确定因素变小了嘛。即B能提供给A有用的信息,越有用越相近。
I ( A , B ) = H ( A ) + H ( B ) − H ( A , B ) ⩾ 0 I(A,B)=H(A)+H(B)-H(A,B)\geqslant 0 I(A,B)=H(A)+H(B)−H(A,B)⩾0,而且当A=B时,H(A,B)=0,I(A,B)最大。此时
N M I A , B ) = 2 I ( A , B ) H ( A ) + H ( B ) = 2 H ( A ) 2 H ( A ) = 1 NMIA,B)=2\frac{I(A,B)}{H(A)+H(B)}=2\frac{H(A)}{2H(A)}=1 NMIA,B)=2H(A)+H(B)I(A,B)=22H(A)H(A)=1,故 N M I ∈ [ 0 , 1 ] NMI\in[0,1] NMI∈[0,1]
参考:https://nlp.stanford.edu/IR-book/html/htmledition/evaluation-of-clustering-1.html
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/193238.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
