大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
| Title | Spatial Information Guided Convolution for Real-Time RGBD Semantic Segmentation |
|---|---|
| 标题 | 空间信息引导的卷积用于实时RGBD语义分割 |
| https://arxiv.org/pdf/2004.04534v1.pdf |
摘要
已知3D空间信息对于语义分割任务是有益的。大多数现有方法都将3D空间数据作为附加输入,从而导致双流分割网络分别处理RGB和3D空间信息。该解决方案大大增加了推理时间,并严重限制了其在实时应用中的范围。为了解决这个问题,我们提出了空间信息引导卷积(S-Conv),它允许有效的RGB特征和3D空间信息集成。 S-Conv能够根据3D空间信息推断卷积核的采样偏移量,从而帮助卷积层调整接收场并适应几何变换。 S-Conv还通过生成空间自适应卷积权重将几何信息纳入特征学习过程。感知几何的能力大大增强,而没有太大影响参数的数量和计算成本。我们进一步将S-Conv嵌入到称为空间信息引导卷积网络(SGNet)的语义分割网络中,从而在NYUDv2和SUNRGBD数据集上实现了实时推理和最新性能。
1. 简介
随着3D传感技术的发展,具有空间信息(深度,3D坐标)的RGBD数据可轻松访问。 结果,用于高级场景理解的RGBD语义分割变得非常重要,使自动驾驶[1],SLAM [2]和机器人技术等广泛的应用受益。 由于卷积神经网络(CNN)的有效性和附加的空间信息,最近的进展证明了在室内场景分割任务上的增强性能[3],[4]。 尽管如此,由于环境的复杂性以及考虑空间数据的额外努力,尤其是对于需要实时推理的应用程序,仍然存在着巨大的挑战。
一种常见方法是将3D空间信息作为网络的附加输入以提取特征,然后将RGB图像的特征[3],[5]-[9]组合起来,如图1(a)所示。 这种方法以显着增加参数数量和计算时间为代价获得了有希望的结果,因此不适合实时任务。 同时,几篇著作[3],[5],[8],[10],[11]将原始空间信息编码为三个通道(HHA),该通道由水平视差,地上高度和范数角组成。但是,从原始数据到HHA的转换也很耗时[8]。
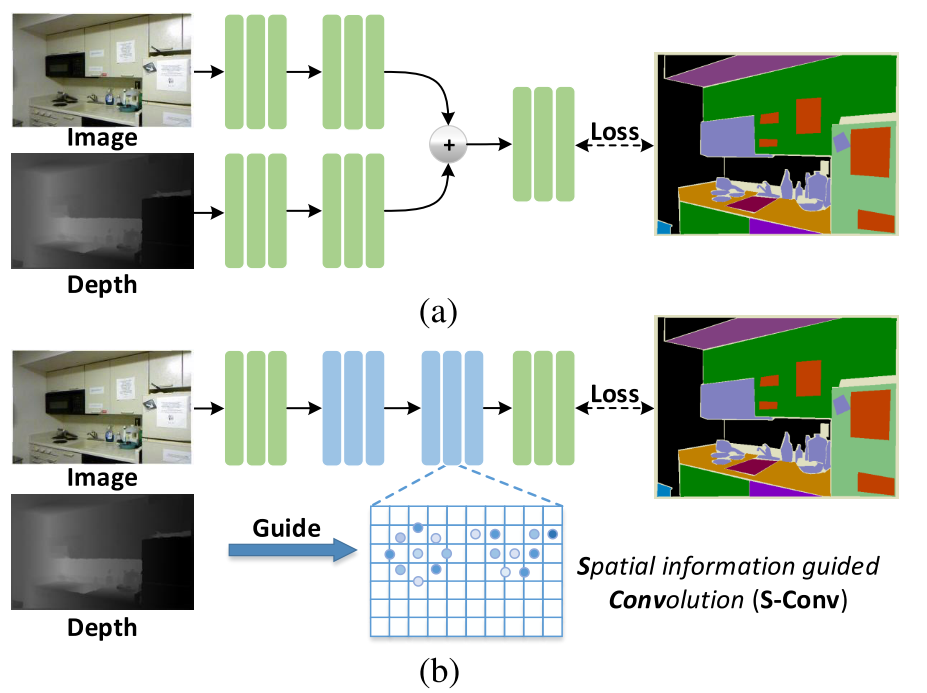

图1:不同方法的网络架构。 (a)传统的双流结构。 (b)SGNet。 可以看出,(a)中的方法由于处理空间信息而大大增加了参数数量和推理时间,因此不太适合实时应用。 我们在(b)中用S-Conv替换卷积,其中卷积的核分布和权重适应于空间信息。 S-Conv只需很少的其他参数和计算就可以极大地增强网络的空间意识,从而可以有效地利用空间信息。
值得注意的是,室内场景更加复杂,其空间关系远胜于室外场景。这就要求网络具有更强的适应能力,以处理几何变换。 然而,由于卷积核的固定结构,上述方法中的二维卷积不能很好地适应空间变换并固有地调节接收场,从而限制了语义分割的准确性。 尽管可以通过修改池操作和先前的数据增强来缓解[12],[13],但仍然需要更好的空间自适应采样机制来进行卷积。
而且,室内场景中物体的颜色和纹理并不总是具有代表性。 相反,几何结构通常在语义分割中起着至关重要的作用。 例如,要识别冰箱和墙壁,由于相似的纹理,几何结构是主要提示。 然而,这种空间信息被RGB数据的2D卷积所忽略。 提出了深度感知卷积[14]来解决这个问题。 它迫使深度与卷积核中心相似的像素具有比其他像素更高的权重。 但是,此先验是手工制作的,可能会导致次优结果。
可以看出,二维卷积的固定结构与变化的空间变换以及分别处理RGB和空间数据的效率瓶颈之间存在矛盾。 为了克服上述限制,我们提出了一种新颖的操作,称为空间信息引导卷积(S-Conv),该操作根据空间信息进行自适应更改(请参见图1(b))。
具体而言,此操作可以生成具有不同采样分布的卷积内核,以适应空间信息,从而增强网络的空间适应性和接收场调节。此外,S-Conv在卷积权重和与其对应像素的基础空间关系之间建立链接,将几何信息纳入卷积权重以更好地捕获场景的空间结构。
提议的S-Conv轻巧但灵活,仅需很少的附加参数和计算成本即可实现显着的性能改进,使其适合于实时应用。我们进行了广泛的实验,以证明S-Conv的有效性和效率。我们首先设计消融研究,并将S-Conv与可变形卷积[12],[13]和深度感知卷积[14]进行比较,展示了S-Conv的优势。我们还通过测试S-Conv对具有深度,HHA和3D坐标的不同类型空间数据的影响,来验证S-Conv在空间变换中的适用性。我们证明,空间信息比可变形卷积使用的RGB特征更适合生成偏移[12],[13]。最后,得益于对空间转换的适应性和感知空间结构的有效性,我们配备S-Conv的网络(称为空间信息制导卷积网络(SGNet))可以通过实时推断获得高质量的结果在NYUDv2 [15]和SUNRGBD [16],[17]数据集。
我们强调以下方面的贡献:
- 我们提出了一种新颖的S-Conv算子,该算子可以自适应地调整感受野,同时有效地适应空间变换,并可以低成本感知复杂的几何图案。
- 基于S-Conv,我们提出了一种新的SGNet,可在NYUDv2 [15]和SUNRGBD [16],[17]数据集上实时实现具有竞争力的RGBD分割性能。
2. 相关工作
2.1 语义分割
卷积神经网络(CNN)的发展使语义分割的最新进展受益匪浅[18],[19]。 FCN [3]是利用CNN进行语义分割的先驱。它导致令人信服的结果,并充当许多任务的基本框架。经过该领域的研究,根据网络体系结构,最近的方法可以分为两类,包括基于扩张卷积的方法[4],[20]和基于编码器-解码器的方法[21] – [24]。
Atrous卷积:标准方法依赖于步幅卷积或池化以减少CNN主干的输出步幅并实现较大的感受野。但是,结果特征图的分辨率降低了[25],许多细节丢失了。一种方法利用扩张卷积通过增强感受野来缓解冲突,同时保持特征图的分辨率[4],[20],[22],[25],[26]。我们在提出的SGNet中使用基于扩张卷积的骨干网。
编码器-解码器体系结构:另一种方法利用编码器-解码器结构[21]-[24],[27],该结构学习解码器以逐渐恢复预测细节。 DeconvNet [24]使用一系列反卷积层来产生高分辨率的预测。 SegNet [23]通过在编码器中使用池化索引来指导解码器中的恢复过程,可以获得更好的结果。 RefineNet [21]将编码器中的低级特征与解码器融合在一起,以完善预测。尽管此方法可以获得更精确的结果,但需要更长的推理时间。
2.2 RGBD语义分割
如何有效利用额外的几何信息(深度,3D坐标)是RGBD语义分割的关键。许多工作着重于如何从几何中提取更多信息,在[6] – [9],[28]中将其视为附加输入。 [5],[7] – [9],[11]中使用两流网络分别处理RGB图像和几何信息,并将两个结果合并到最后一层。这些方法以使参数和计算成本加倍的代价达到了有希望的结果。 3D CNN或3D KNN图形网络也用于考虑几何信息[29]-[31]。此外,还探索了3D点云[32]-[37]上的各种深度学习方法。但是,这些方法花费大量内存,并且计算量大。另一个流将几何信息合并到显式操作中。程等[38]使用几何信息来建立一个特征亲和力矩阵,用于平均池化和反池化。 Lin等[39]根据几何信息将图像分为不同的分支。 Wang等[14]提出了深度感知的CNN,它在卷积权重中增加了深度先验信息。尽管它通过卷积改进了特征提取,但是先验是手工制作的,但不能从数据中学习。其他方法,例如多任务学习[6],[40]-[44]或时空分析[45],可进一步用于提高分割精度。提出的S-Conv旨在有效地利用空间信息以提高特征提取能力。由于仅使用少量参数,因此可以显着提高效率并提高性能。
3. S-Conv 和 SGNet
在本节中,我们首先详细说明空间信息引导卷积(S-Conv)的细节,它是通过在RGBD场景中引入空间信息到常规的RGB卷积。 然后,我们讨论S-Conv与其他方法之间的关系。 最后,我们描述了空间信息引导卷积网络(SGNet)的网络体系结构,该网络配备了S-Conv用于RGBD语义分割。
3.1 空间信息引导卷积
为了完整起见,我们首先回顾一下传统的卷积运算。 我们使用 A i ( j ) , A ∈ R c × h × w A_i(j), A \in R^{c\times h \times w } Ai(j),A∈Rc×h×w来表示张量,其中 i i i是对应于第一维的索引,而 j ∈ R 2 j \in R^2 j∈R2指示第二维和第三维的两个索引。
对于输入特征图 X ∈ R c × h × w X∈R^{c×h×w} X∈Rc×h×w。为了简单起见,我们在2D中对其进行描述,因此 X ∈ R 1 × h × w X∈R^{1×h×w} X∈R1×h×w。注意,扩展到3D情况很简单。常规卷积输入X得到Y是通过如下公式计算的:
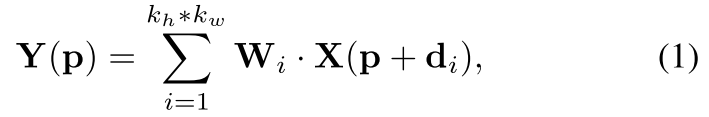
其中 W ∈ R k h ∗ k w W∈R^{k_h ∗ k_w} W∈Rkh∗kw是卷积核, p ∈ R 2 p∈R_2 p∈R2是二维卷积中心, d ∈ R k h ∗ k w × 2 d∈R^{k_h ∗ k_w×2} d∈Rkh∗kw×2表示 p p p周围的卷积核分布。对于3×3卷积:
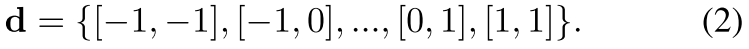
从上面的方程式中,我们可以看到 W 和 d W和d W和d是固定的,这意味着卷积是与图像内容无关的。而我们希望通过使用自适应卷积核能够有效地包含3D空间信息。
我们首先根据空间信息生成偏移,然后使用与给定偏移对应的空间信息生成新的空间自适应权重。我们的S-Conv需要两个输入,一种是与常规卷积相同的特征图 X X X,另一个是空间信息 S ∈ R c ′ × h × w S∈R^{c’×h×w} S∈Rc′×h×w。实际上, S S S可以是 H H A ( c ′ = 3 ) HHA(c’ = 3) HHA(c′=3), 3 D 坐 标 ( c ′ = 3 3D坐标(c’ = 3 3D坐标(c′=3)或深度 ( c ′ = 1 ) (c’ = 1) (c′=1)。将深度编码为3D坐标和HHA的方法与[31]相同。注意,输入的空间信息不包括在特征图中。
作为S-Conv的第一步,我们将输入的空间信息投影到高维特征空间中,可以将其表示为:

其中 ϕ \phi ϕ是空间变换函数, S ′ ∈ R 64 × h × w S’∈R^{64×h×w} S′∈R64×h×w,其维度比S高。
然后,我们将考虑变换后的空间信息 S ′ S’ S′,感知其几何结构,并生成卷积核在不同 p p p处的分布(x和y轴上像素坐标的偏移)。此过程可以表示为:

其中 Δ d ∈ R k h ∗ k w × h ′ × w ′ × 2 , h ′ , w ′ Δd∈R^{k_h ∗ k_w×h’×w’×2},h’, w’ Δd∈Rkh∗kw×h′×w′×2,h′,w′表示卷积后的特征图大小,而 k h , k w k_h,k_w kh,kw是卷积核大小。 η η η是一个非线性函数,可以通过一系列卷积实现。
在使用 Δ d ( p ) Δd(p) Δd(p)为每个可能的 p p p生成核的分布之后,我们通过在几何结构和卷积权重之间建立联系来提高其特征提取能力。更具体地说,我们在平移后对与卷积核相对应的像素的几何信息进行采样:
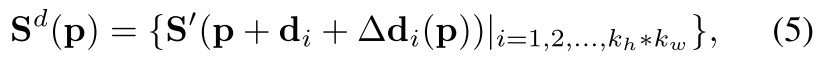
其中 ∆ d ( p ) ∆d(p) ∆d(p)是在 p p p处的卷积核的空间分布。 S d ( p ) ∈ R 64 ∗ k h ∗ k w S^d(p)∈R^{64 ∗ k_h ∗ k_w} Sd(p)∈R64∗kh∗kw是与变换后以 p p p为中心的卷积核特征图相对应的空间信息。
最后,我们根据最终的空间信息生成卷积权重,如下所示:
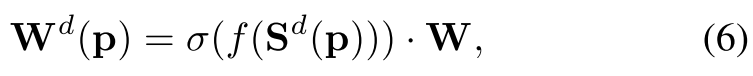
其中 f f f是一个非线性函数,可以实现为具有非线性激活函数的一系列卷积层, W ∈ R k h ∗ k w W∈R^{k_h ∗ k_w} W∈Rkh∗kw表示卷积权重,可以通过梯度下降算法进行更新。 W d ( p ) ∈ R k h ∗ k w W^d (p) ∈R^{k_h ∗ k_w} Wd(p)∈Rkh∗kw表示以 p p p为中心的卷积的空间自适应权重。
总体而言,我们的广义S-Conv公式为:
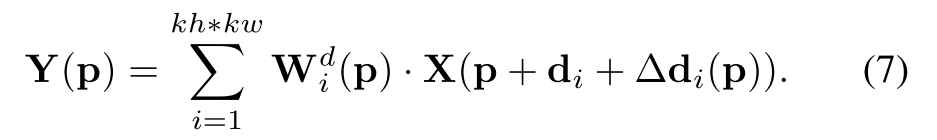
我们可以看到 W i d W^d_i Wid建立了空间信息和卷积权重之间的相关性。此外,卷积核的分布也与通过 Δ d Δd Δd的空间信息有关。请注意, W i d ( p ) W^d_i(p) Wid(p)和 ∆ d i ( p ) ∆d_i(p) ∆di(p)不是常数,这意味着广义卷积适用于不同的 p p p。同样,由于 Δ d Δd Δd通常是分数,因此我们使用双线性插值来计算 X ( p + d i + Δ d i ( p ) ) X(p + d_i +Δd_i(p)) X(p+di+Δdi(p)),如[12],[46]中所示。上面讨论的主要公式如图2所示。
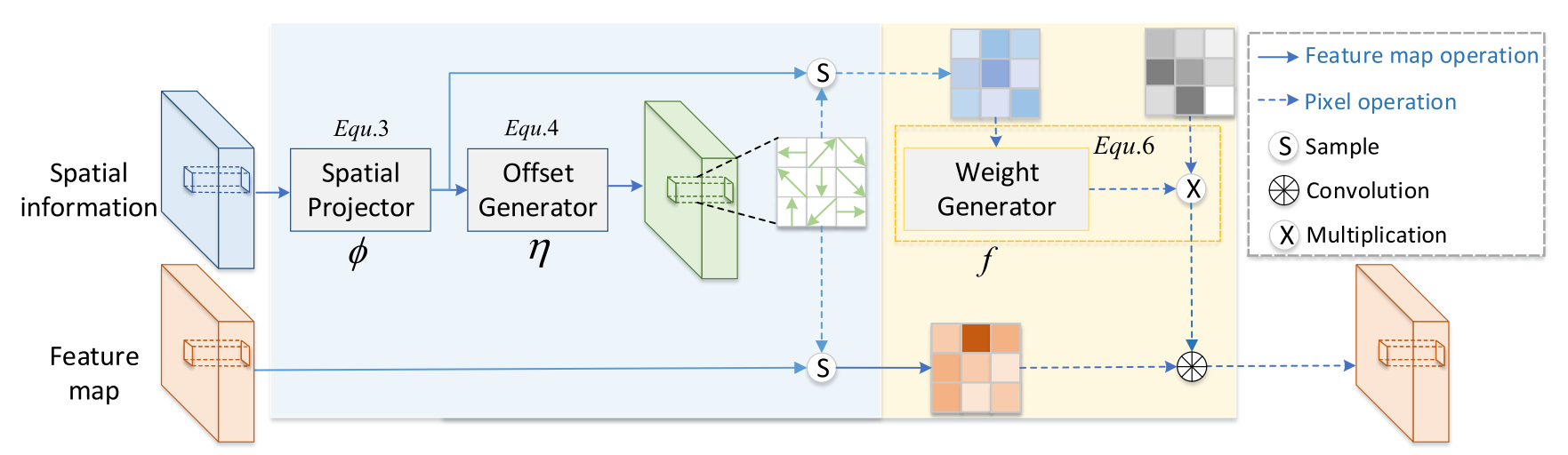
图2:空间信息引导卷积(S-Conv)的图示。
3.2 SGNet架构
我们的语义分割网络SGNet配备了S-Conv,由骨干网和解码器组成。 **SGNet的结构如图4所示。我们使用ResNet101 [51]作为骨干,并用S-Conv替换每层的前两个和最后两个常规卷积。**我们添加了一系列卷积以进一步提取特征,然后使用双线性上采样生成最终的分割概率图,该图对应于SGNet的解码器部分。等式(3)中的 ϕ \phi ϕ实现为三个3×3卷积层,即具有非线性激活函数的 C o n v ( 3 , 64 ) − C o n v ( 64 , 64 ) − C o n v ( 64 , 64 ) Conv(3,64)-Conv(64,64)-Conv(64,64) Conv(3,64)−Conv(64,64)−Conv(64,64)。等式(4)中的 η η η和等式(6)中的 f f f分别实现为单个卷积层和两个卷积层。 S-Conv实现是从可变形卷积[12],[13]修改而来的。我们在第3层和第4层之间添加了深度监督以提高网络优化能力,这与PSPNet [27]相同。
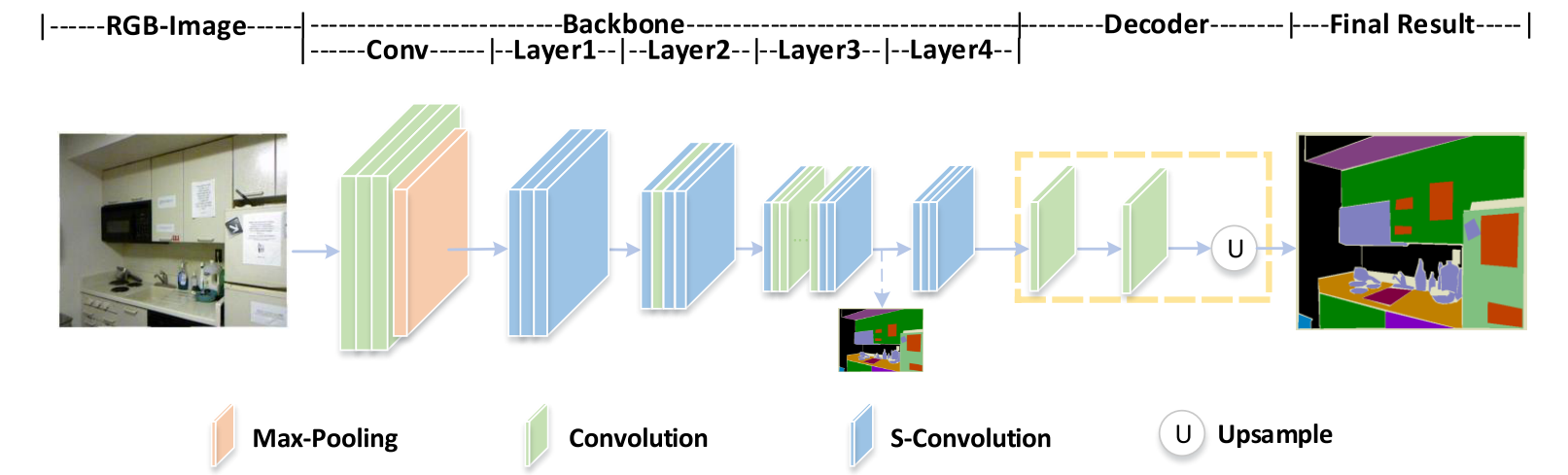
图4:SGNet的网络架构。
4. 实验
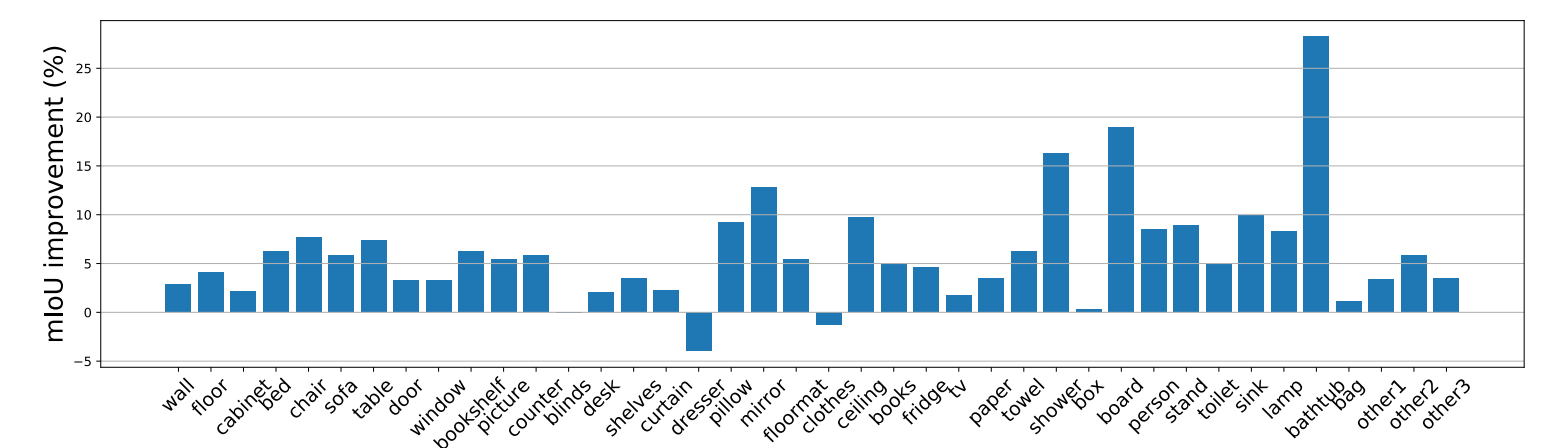
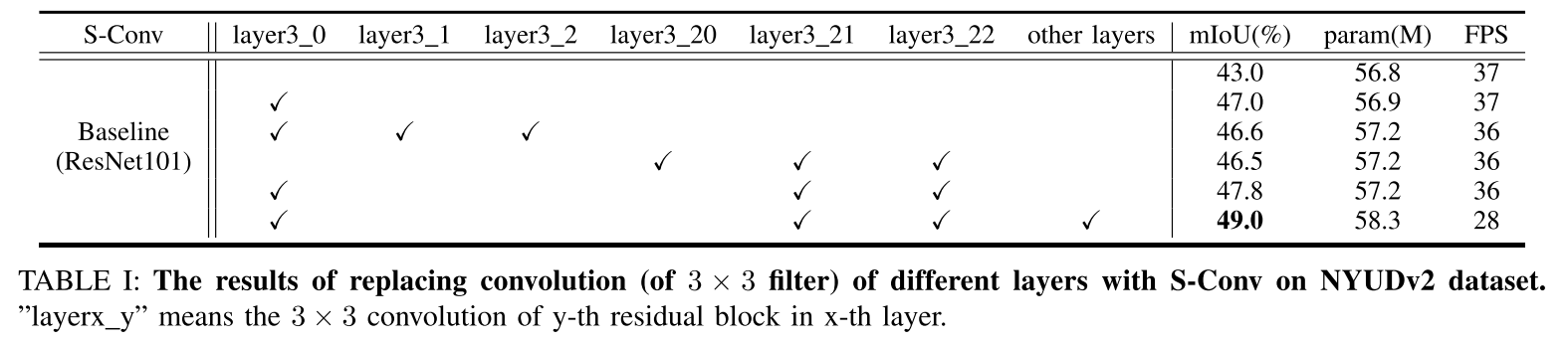
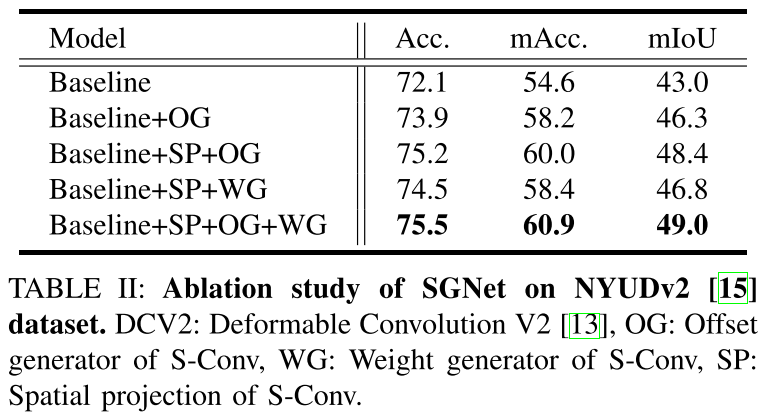
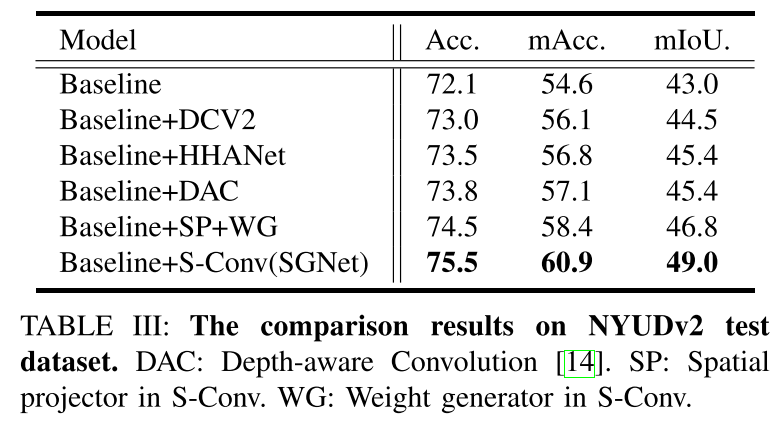
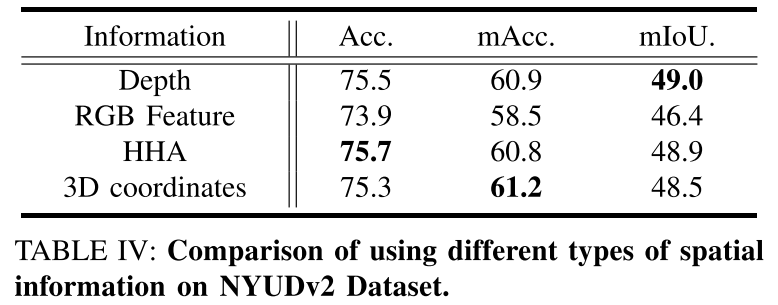
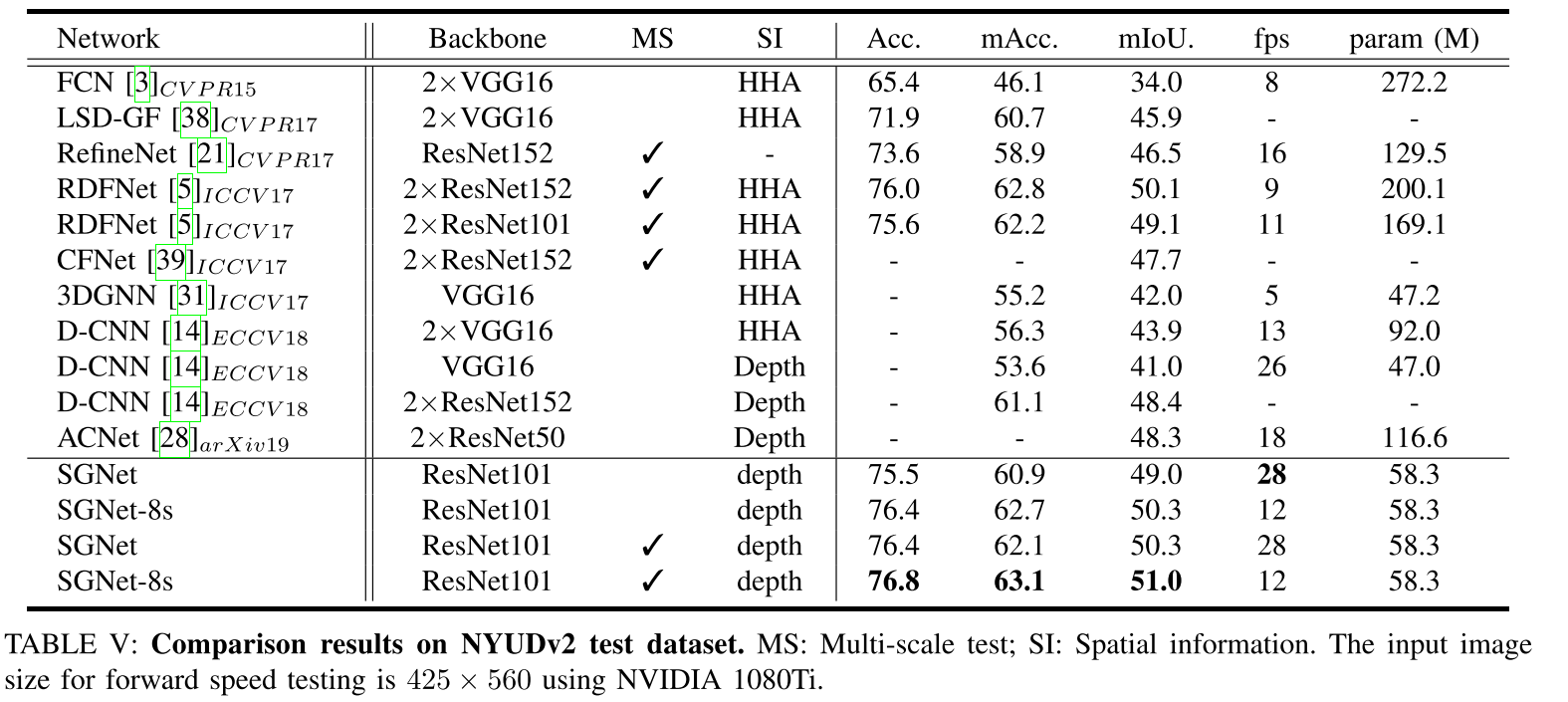
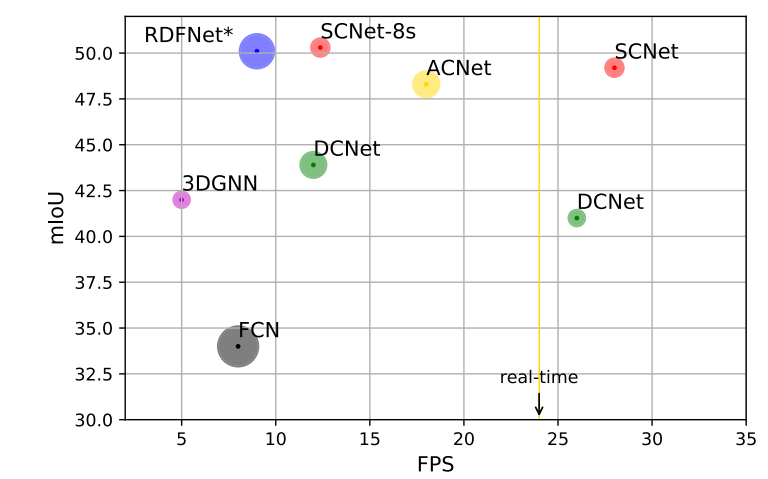
图6:使用NVIDIA 1080Ti在输入图像尺寸为425×560的NYUDv2测试数据集上,FPS,mIoU和不同方法的参数数量。 圆的半径对应于模型的参数数量。 对于标有∗的模型,其mIoU通过多尺度测试获得,其推理时间通过单尺度获得。 DCNet [14]和3DGNN [31]的结果来自[14]。 我们的SGNet可以实现实时推断和竞争性能。 与使用更多参数和多尺度测试的RDFNet相比,输出步幅为8的SGNet-8s可以获得更好的结果。

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/193154.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
