大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
一.ByteBuffer
ByteBuffer是JDK NIO中提供的Java.nio.Buffer, 在内存中预留指定大小的存储空间来存放临时数据,其他Buffer 的子类有:CharBuffer、DoubleBuffer、FloatBuffer、IntBuffer、LongBuffer 和 ShortBuffer
1. Buffer
ByteBuffer继承Buffer,Buffer中定义的成员变量。


- *
- * @author Mark Reinhold
- * @author JSR-51 Expert Group
- * @since 1.4
- */
- ublic abstract class Buffer {
- // Invariants: mark <= position <= limit <= capacity
- private int mark = –1;
- private int position = 0;
- private int limit;
- private int capacity;
- // Used only by direct buffers
- // NOTE: hoisted here for speed in JNI GetDirectBufferAddress
- long address;
每个Buffer都有以下的属性:
capacity
这个Buffer最多能放多少数据。capacity在buffer被创建的时候指定。
limit
在Buffer上进行的读写操作都不能越过这个下标。当写数据到buffer中时,limit一般和capacity相等,当读数据时,
limit代表buffer中有效数据的长度。
position
读/写操作的当前下标。当使用buffer的相对位置进行读/写操作时,读/写会从这个下标进行,并在操作完成后,
buffer会更新下标的值。
mark
一个临时存放的位置下标。调用mark()会将mark设为当前的position的值,以后调用reset()会将position属性设
置为mark的值。mark的值总是小于等于position的值,如果将position的值设的比mark小,当前的mark值会被抛弃掉。
这些属性总是满足以下条件:
0 <= mark <= position <= limit <= capacity
- import java.nio.ByteBuffer;
- public class ByteBufferTest {
- public static void main(String[] args) {
- //实例初始化
- ByteBuffer buffer = ByteBuffer.allocate(100);
- String value =“Netty”;
- buffer.put(value.getBytes());
- buffer.flip();
- byte[] vArray = new byte[buffer.remaining()];
- buffer.get(vArray);
- System.out.println(new String(vArray));
- }
- }
我们看下调用flip()操作前后的对比
+——————–+———————————————————–+
| Netty | |
+——————–+———————————————————–+
| | |
0 position limit = capacity
ByteBuffer flip()操作之前
+——————–+———————————————————–+
| Netty | |
+——————–+———————————————————–+
| | |
position limit capacity
ByteBuffer flip()操作之后
由于ByteBuffer只有一个position位置指针用户处理读写请求操作,因此每次读写的时候都需要调用flip()和clean()等方法,否则功能将出错。如上图,如果不做flip操作,读取到的将是position到capacity之间的错误内容。当执行flip()操作之后,它的limit被设置为position,position设置为0,capacity不变,由于读取的内容是从position都limit之间,因此它能够正确的读取到之前写入缓冲区的内容。
3.Buffer常用的函数
clear()
把position设为0,把limit设为capacity,一般在把数据写入Buffer前调用。
- public final Buffer clear() {
- position = 0;
- limit = capacity;
- mark = –1;
- return this;
- }
flip()
把limit设为当前position,把position设为0,一般在从Buffer读出数据前调用。
- public final Buffer flip() {
- limit = position;
- position = 0;
- mark = –1;
- return this;
- }
rewind()
把position设为0,limit不变,一般在把数据重写入Buffer前调用。
- public final Buffer rewind() {
- position = 0;
- mark = –1;
- return this;
- }
mark()
设置mark的值,mark=position,做个标记。
reset()
还原标记,把mark的值赋值给position。
4.ByteBuffer实例化
allocate(int capacity)
从堆空间中分配一个容量大小为capacity的byte数组作为缓冲区的byte数据存储器,实现类是HeapByteBuffer 。
- public static ByteBuffer allocate(int capacity) {
- if (capacity < 0)
- throw new IllegalArgumentException();
- return new HeapByteBuffer(capacity, capacity);
- }
allocateDirect(int capacity)
非JVM堆栈而是通过操作系统来创建内存块用作缓冲区,它与当前操作系统能够更好的耦合,因此能进一步提高I/O操作速度。但是分配直接缓冲区的系统开销很大,因此只有在缓冲区较大并长期存在,或者需要经常重用时,才使用这种缓冲区,实现类是DirectByteBuffer。
- public static ByteBuffer allocateDirect(int capacity) {
- return new DirectByteBuffer(capacity);
- }
wrap(byte[] array)
这个缓冲区的数据会存放在byte数组中,bytes数组或buff缓冲区任何一方中数据的改动都会影响另一方。其实ByteBuffer底层本来就有一个bytes数组负责来保存buffer缓冲区中的数据,通过allocate方法系统会帮你构造一个byte数组,实现类是HeapByteBuffer 。
wrap(byte[] array, int offset, int length)
在上一个方法的基础上可以指定偏移量和长度,这个offset也就是包装后byteBuffer的position,而length呢就是limit-position的大小,从而我们可以得到limit的位置为length+position(offset),实现类是HeapByteBuffer 。
HeapByteBuffer和DirectByteBuffer的总结:前者是内存的分派和回收速度快,可以被JVM自动回收,缺点是如果进行Socket的I/O读写,需要额外做一次内存拷贝,将堆内存对应的缓存区复制到内核中,性能会有一定程序的下降;后者非堆内存,它在堆外进行内存的分配,相比堆内存,它的分配和回收速度会慢一些,但是它写入或者从Socket Channel中读取时,由于少了一次内存复制,速度比堆内存快。经验表明,最佳实践是在I/O通信线程的读写缓冲区使用DirectByteBuffer,后端业务消息的编码模块使用HeapByteBuffer,这样的组合可以达到性能最优。
二. ByteBuf
先走个小例子
- import io.netty.buffer.ByteBuf;
- import io.netty.buffer.Unpooled;
- public class ByteBufTest {
- public static void main(String[] args) {
- //实例初始化
- ByteBuf buffer = Unpooled.buffer(100);
- String value =“学习ByteBuf”;
- buffer.writeBytes(value.getBytes());
- System.out.println(“获取readerIndex:”+buffer.readerIndex());
- System.out.println(“获取writerIndex:”+buffer.writerIndex());
- byte[] vArray = new byte[buffer.writerIndex()];
- buffer.readBytes(vArray);
- System.out.println(“获取readerIndex:”+buffer.readerIndex());
- System.out.println(“获取writerIndex:”+buffer.writerIndex());
- System.out.println(new String(vArray));
- }
- }
接着看下ByteBuf主要类继承关系

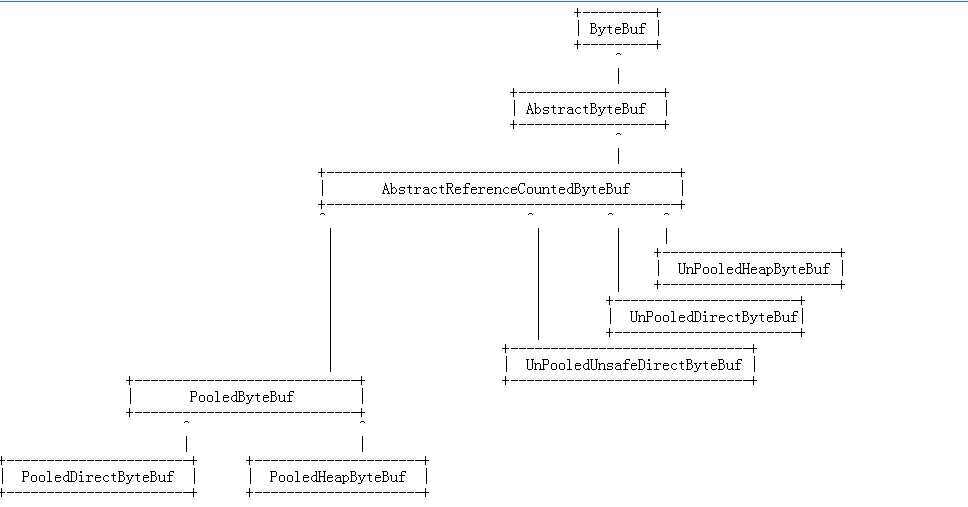
1. AbstractByteBuf
- public abstract class AbstractByteBuf extends ByteBuf {
- static final ResourceLeakDetector<ByteBuf> leakDetector = new ResourceLeakDetector<ByteBuf>(ByteBuf.class);
- int readerIndex; //读索引
- private int writerIndex; //写索引
- private int markedReaderIndex; //,
- private int markedWriterIndex;
- private int maxCapacity;
- private SwappedByteBuf swappedBuf;
在AbstractByteBuf中并没有定义ByteBuf的缓冲区实现,因为AbstractByteBuf并不清楚子类到底是基于堆内存还是直接内存。AbstractByteBuf中定义了读写操作方法,这里主要介绍下写方法,ByteBuf写操作支持自动扩容,ByteBuffer而不支持,我们看下writeByte()具体的源码。
- @Override
- public ByteBuf writeByte(int value) {
- ensureWritable(1);
- setByte(writerIndex++, value);
- return this;
- }
接着调用ensureWritable()方法,是否需要自动扩容。
- @Override
- public ByteBuf ensureWritable(int minWritableBytes) {
- if (minWritableBytes < 0) {
- throw new IllegalArgumentException(String.format(
- “minWritableBytes: %d (expected: >= 0)”, minWritableBytes));
- }
- if (minWritableBytes <= writableBytes()) { //writableBytes()计算可写的容量=“capacity() – writerIndex;”
- return this;
- }
- if (minWritableBytes > maxCapacity – writerIndex) {
- throw new IndexOutOfBoundsException(String.format(
- “writerIndex(%d) + minWritableBytes(%d) exceeds maxCapacity(%d): %s”,
- writerIndex, minWritableBytes, maxCapacity, this));
- }
- // Normalize the current capacity to the power of 2.
- int newCapacity = calculateNewCapacity(writerIndex + minWritableBytes);
- // Adjust to the new capacity.
- capacity(newCapacity);
- return this;
- }
接着继续调用calculateNewCapacity(),计算自动扩容后容量,即满足要求的最小容量,等于writeIndex+minWritableBytes。
- private int calculateNewCapacity(int minNewCapacity) {
- final int maxCapacity = this.maxCapacity;
- final int threshold = 1048576 * 4; // 4 MiB page
- if (minNewCapacity == threshold) {
- return threshold;
- }
- // If over threshold, do not double but just increase by threshold.
- if (minNewCapacity > threshold) {
- int newCapacity = minNewCapacity / threshold * threshold;
- if (newCapacity > maxCapacity – threshold) {
- newCapacity = maxCapacity;
- } else {
- newCapacity += threshold;
- }
- return newCapacity;
- }
- // Not over threshold. Double up to 4 MiB, starting from 64.
- int newCapacity = 64;
- while (newCapacity < minNewCapacity) {
- newCapacity <<= 1;
- }
- return Math.min(newCapacity, maxCapacity);
- }
首先设置门限值为4MB,当需要的新容量正好等于门限值时,使用门限值作为新的缓存区容量,如果新申请的内存容量大于门限值,不能采用倍增的方式扩张内容(防止内存膨胀和浪费),而是采用每次进步4MB的方式来内存扩张,扩张的时候需要对扩张后的内存和最大内存进行对比,如果大于缓存区的最大长度,则使用maxCapacity作为扩容后的缓存区容量。如果扩容后的新容量小于门限值,则以64为计算进行倍增,知道倍增后的结果大于等于需要的值。
重用缓存区,重用已经读取过的缓存区,下面介绍下discardReadBytes()方法的实现进行分析
- @Override
- public ByteBuf discardReadBytes() {
- ensureAccessible();
- if (readerIndex == 0) {
- return this;
- }
- if (readerIndex != writerIndex) {
- //复制数组 System.arraycopy(this,readerIndex, ,array,0,writerIndex – readerIndex)
- setBytes(0, this, readerIndex, writerIndex – readerIndex);
- writerIndex -= readerIndex;
- adjustMarkers(readerIndex);
- readerIndex = 0;
- } else {
- adjustMarkers(readerIndex);
- writerIndex = readerIndex = 0;
- }
- return this;
- }
首先对度索引进行判断,如果为0则说明没有可重用的缓存区,直接返回,如果读索引大于0且读索引不等于写索引,说明缓冲区中既有已经读取过的被丢弃的缓冲区,也有尚未读取的可读取缓存区。调用setBytes(0, this, readerIndex, writerIndex – readerIndex)进行字节数组复制,将尚未读取的字节数组复制到缓冲区的起始位置,然后重新设置读写索引,读索引为0,写索引设置为之前的写索引减去读索引。在设置读写索引的同时,调整markedReaderIndex和markedWriterIndex。
接下来看下初始化分配的ByteBuf的结构图
- *
- * +——————-+——————+——————+
- * | writable bytes
- * +——————-+——————+——————+
- * | |
- * 0=readerIndex=writerIndex capacity
- *
ByteBuf通过两个位置指针来协助缓冲区的读写操作,读操作使用readerIndex,写操作使用writerIndex。readerIndex和writerIndex的取值一开始都是0,随着数据的写入writerIndex会增加,读取数据会readerIndex增加,但是它不会超出writerIndex。在读取之后,0~readerIndex就视为discard的,调用discardReadBytes()方法,可以释放这部分空间。readerIndex和writerIndex之间的数据是可读的,等价于ByteBuffer position和limit之间的数据。writerIndex和capacity之间的空间是可写的,等价于ByteBuffer limit和capacity之间的可用空间。
写入N个字节后的ByteBuf
- *
- * +——————-+——————+——————+
- * | readable bytes | writable bytes |
- * +——————-+——————+——————+
- * | |
- * 0=readerIndex writerIndex capacity
- *
读取M(<N)个字节之后的ByteBuf
- *
- * +——————-+——————+——————+
- * | discardable bytes | readable bytes | writable bytes |
- * +——————-+——————+——————+
- * | | | |
- * 0 M=readerIndex N=writerIndex capacity
- *
调用discardReadBytes操作之后的ByetBuf
- *
- * +——————-+——————+——————+
- * | readable bytes | writable bytes
- * +——————-+——————+——————+
- * | |
- * 0=readerIndex N-M=writerIndex capacity
- *
调用clear操作之后的ByteBuf
- *
- * +——————-+——————+——————+
- * | writable bytes(more space)
- * +——————-+——————+——————+
- * | |
- * 0=readerIndex=writerIndex capacity
- *
2.AbstractReferenceCountedByteBuf
AbstractReferenceCountedByteBuf继承AbstractByteBuf,从类的名字可以看出该类是对引用进行计数,用于跟踪对象的分配和销毁,做自动内存回收。
- public abstract class AbstractReferenceCountedByteBuf extends AbstractByteBuf {
- private static final AtomicIntegerFieldUpdater<AbstractReferenceCountedByteBuf> refCntUpdater =
- AtomicIntegerFieldUpdater.newUpdater(AbstractReferenceCountedByteBuf.class, “refCnt”);
- private static final long REFCNT_FIELD_OFFSET;
- static {
- long refCntFieldOffset = –1;
- try {
- if (PlatformDependent.hasUnsafe()) {
- refCntFieldOffset = PlatformDependent.objectFieldOffset(
- AbstractReferenceCountedByteBuf.class.getDeclaredField(“refCnt”));
- }
- } catch (Throwable t) {
- // Ignored
- }
- REFCNT_FIELD_OFFSET = refCntFieldOffset;
- }
- @SuppressWarnings(“FieldMayBeFinal”)
- private volatile int refCnt = 1;
首先看到第一个字段refCntUpdater ,它是AtomicIntegerFieldUpdater类型变量,通过原子方式对成员变量进行更新等操作,以实现线程安全,消除锁。第二个字段是REFCNT_FIELD_OFFSET,它用于标识refCnt字段在AbstractReferenceCountedByteBuf 中内存地址,该地址的获取是JDK实现强相关的,如果是SUN的JDK,它通过sun.misc.Unsafe的objectFieldOffset接口获得的,ByteBuf的实现之类UnpooledUnsafeDirectByteBuf和PooledUnsafeDirectByteBuf会使用这个偏移量。最后定义一个volatile修饰的refCnt字段用于跟踪对象的引用次数,使用volatile是为了解决多线程并发的可见性问题。
对象引用计数器,每次调用一次retain,引用计数器就会加一,由于可能存在多线程并发调用的场景,所以他的累计操作必须是线程安全的,看下具体的实现细节。
- @Override
- public ByteBuf retain(int increment) {
- if (increment <= 0) {
- throw new IllegalArgumentException(“increment: “ + increment + ” (expected: > 0)”);
- }
- for (;;) {
- int refCnt = this.refCnt;
- if (refCnt == 0) {
- throw new IllegalReferenceCountException(0, increment);
- }
- if (refCnt > Integer.MAX_VALUE – increment) {
- throw new IllegalReferenceCountException(refCnt, increment);
- }
- if (refCntUpdater.compareAndSet(this, refCnt, refCnt + increment)) {
- break;
- }
- }
- return this;
- }
通过自旋对引用计数器进行加一操作,由于引用计数器的初始值为1,如果申请和释放操作能保证正确使用,则它的最小值为1。当被释放和被申请的次数相等时,就调用回收方法回收当前的ByteBuf对象。通过compareAndSet进行原子更新,它会使用自己获取的值和期望值进行对比,一样则修改,否则进行自旋,继续尝试直到成功(compareAndSet是操作系统层面提供的原子操作,称为CAS)。释放引用计数器的代码和对象引用计数器类似,释放引用计数器的每次减一,当refCnt==1时意味着申请和释放相等,说明对象引用已经不可达,该对象需要被释放和回收。回收则是通过调用子类的deallocate方法来释放ByteBuf对象。
看下UnpooledHeapByteBuf中deallocate的实现
- @Override
- protected void deallocate() {
- array = null;
- }
看下UnpooledUnsafeDirectByteBuf和UnpooledDirectByteBuf的deallocate实现细节
- @Override
- protected void deallocate() {
- ByteBuffer buffer = this.buffer;
- if (buffer == null) {
- return;
- }
- this.buffer = null;
- if (!doNotFree) {
- freeDirect(buffer);
- }
- }
再看freeDirect
- protected void freeDirect(ByteBuffer buffer) {
- PlatformDependent.freeDirectBuffer(buffer);
- }
再看freeDirectBuffer
- /**
- * Try to deallocate the specified direct {@link ByteBuffer}. Please note this method does nothing if
- * the current platform does not support this operation or the specified buffer is not a direct buffer.
- */
- public static void freeDirectBuffer(ByteBuffer buffer) {
- if (buffer.isDirect()) {
- if (hasUnsafe()) {
- PlatformDependent0.freeDirectBufferUnsafe(buffer);
- } else {
- PlatformDependent0.freeDirectBuffer(buffer);
- }
- }
- }
PlatformDependent0.freeDirectBufferUnsafe(buffer)实现细节
- static void freeDirectBufferUnsafe(ByteBuffer buffer) {
- Cleaner cleaner;
- try {
- cleaner = (Cleaner) getObject(buffer, CLEANER_FIELD_OFFSET);
- if (cleaner == null) {
- throw new IllegalArgumentException(
- “attempted to deallocate the buffer which was allocated via JNIEnv->NewDirectByteBuffer()”);
- }
- cleaner.clean();
- } catch (Throwable t) {
- // Nothing we can do here.
- }
- }
PlatformDependent0.freeDirectBuffer(buffer)实现细节
- static void freeDirectBuffer(ByteBuffer buffer) {
- if (CLEANER_FIELD == null) {
- return;
- }
- try {
- Cleaner cleaner = (Cleaner) CLEANER_FIELD.get(buffer);
- if (cleaner == null) {
- throw new IllegalArgumentException(
- “attempted to deallocate the buffer which was allocated via JNIEnv->NewDirectByteBuffer()”);
- }
- cleaner.clean();
- } catch (Throwable t) {
- // Nothing we can do here.
- }
- }
可以看到UnpooledUnsafeDirectByteBuf和UnpooledDirectByteBuf的deallocate最终都是通过Cleaner类进行堆外的垃圾回收。Cleaner 是PhantomReference(虚引用)的子类。
3. UnpooledHeapByteBuf
UnpooledHeapByteBuf是AbstractReferenceCountedByteBuf的子类,UnpooledHeapByteBuf是基于堆内存进行内存分配的字节码缓存区,它没有基于对象池技术实现,这就意味着每次I/O的读写都会创建一个新的UnpooledHeapByteBuf,频繁进行大块内存的分配和回收对性能造成一定的影响,但是相比堆外内存的申请和释放,它的成本还是会低一些。
看下UnpooledHeapByteBuf的成员变量定义
- public class UnpooledHeapByteBuf extends AbstractReferenceCountedByteBuf {
- private final ByteBufAllocator alloc;
- private byte[] array;
- private ByteBuffer tmpNioBuf;
首先它聚合了一个ByteBufAllocator,用于UnpooledHeapByteBuf的内存分配,紧接着定义了一个byte数组作为缓冲区,最后定义一个ByteBuffer类型的tmpNioBuf变量用于实现Netty ByteBuf到JDK NIO ByteBuffer的转正。
看下UnpooledHeapByteBuf类缓冲区的自动扩展的实现
- @Override
- public ByteBuf capacity(int newCapacity) {
- ensureAccessible();
- if (newCapacity < 0 || newCapacity > maxCapacity()) {
- throw new IllegalArgumentException(“newCapacity: “ + newCapacity);
- }
- int oldCapacity = array.length;
- if (newCapacity > oldCapacity) {
- byte[] newArray = new byte[newCapacity];
- System.arraycopy(array, 0, newArray, 0, array.length);
- setArray(newArray);
- } else if (newCapacity < oldCapacity) {
- byte[] newArray = new byte[newCapacity];
- int readerIndex = readerIndex();
- if (readerIndex < newCapacity) {
- int writerIndex = writerIndex();
- if (writerIndex > newCapacity) {
- writerIndex(writerIndex = newCapacity);
- }
- System.arraycopy(array, readerIndex, newArray, readerIndex, writerIndex – readerIndex);
- } else {
- setIndex(newCapacity, newCapacity);
- }
- setArray(newArray);
- }
- return this;
- }
方法入口首先对新容量进行合法性校验,不通过则抛出IllegalArgumentException,然后判断新的容量是否大于当前的缓冲区容量,如果大于容量则进行动态扩容,通过new byte[newCapacity]创建新的缓冲区字节数组,然后通过System.arraycopy()进行内存复制,将旧的字节数组复制到新创建的字节数组中,最后调用setArray替代旧的字节数组。
如果新的容量小于当前的缓冲区容量,不需要动态扩展,但需要截取当前缓冲区创建一个新的子缓冲区,具体的算法如下:首先判断下读取索引是否小于新的容量值,如果下雨进一步写索引是否大于新的容量,如果大于则将写索引设置为新的容量值。之后通过System.arraycopy将当前可读的字节数组复制到新创建的子缓冲区。如果新的容量值小于读索引,说明没有可读的字节数组需要复制到新创建的缓冲区中。
4.PooledHeapByteBuf
PooledHeapByteBuf比UnpooledHeapByteBuf复杂一点,用到了线程池技术。首先来看看Recycler类。
- /**
- * Light-weight object pool based on a thread-local stack.
- *
- * @param <T> the type of the pooled object
- */
- public abstract class Recycler<T> {
- private final ThreadLocal<Stack<T>> threadLocal = new ThreadLocal<Stack<T>>() {
- @Override
- protected Stack<T> initialValue() {
- return new Stack<T>(Recycler.this, Thread.currentThread());
- }
- };
看注解就知道,Recycler是一个轻量级的线程池实现,通过定义了一个threadLocal,并初始化,看下初始化的详细
- static final class Stack<T> implements Handle<T> {
- private static final int INITIAL_CAPACITY = 256;
- final Recycler<T> parent;
- final Thread thread;
- private T[] elements;
- private int size;
- private final Map<T, Boolean> map = new IdentityHashMap<T, Boolean>(INITIAL_CAPACITY);
- @SuppressWarnings({ “unchecked”, “SuspiciousArrayCast” })
- Stack(Recycler<T> parent, Thread thread) {
- this.parent = parent;
- this.thread = thread;
- elements = newArray(INITIAL_CAPACITY);
- }
Stack中定义了成员变量线程池、当前线程、数组、数字大小、map ,map主要用来验证线程池中是否已经存在。
继续看,PooledByteBuf类继承了AbstractReferenceCountedByteBuf,看下PooledByteBuf中定义的成员变量。
- abstract class PooledByteBuf<T> extends AbstractReferenceCountedByteBuf {
- private final Recycler.Handle<PooledByteBuf<T>> recyclerHandle;
- protected PoolChunk<T> chunk;
- protected long handle;
- protected T memory;
- protected int offset;
- protected int length;
- private int maxLength;
- private ByteBuffer tmpNioBuf;
- @SuppressWarnings(“unchecked”)
- protected PooledByteBuf(Recycler.Handle<? extends PooledByteBuf<T>> recyclerHandle, int maxCapacity) {
- super(maxCapacity);
- this.recyclerHandle = (Handle<PooledByteBuf<T>>) recyclerHandle;
- }
其中chunk主要用来组织和管理内存的分配和释放。
5.ByteBufAllocator
ByteBufAllocator是字节缓冲区分配器,按照Netty的缓冲区实现的不同,共有两者不同的分配器:基于内存池的字节缓冲区分配器和普通的字节缓冲区分配器。接口的继承关系如下。
看下ByteBufAllocator中定义的常用接口
- /**
- * Allocate a {@link ByteBuf}. If it is a direct or heap buffer
- * depends on the actual implementation.
- */
- ByteBuf buffer();
- /**
- * Allocate a {@link ByteBuf} with the given initial capacity.
- * If it is a direct or heap buffer depends on the actual implementation.
- */
- ByteBuf buffer(int initialCapacity);
- /**
- * Allocate a {@link ByteBuf} with the given initial capacity and the given
- * maximal capacity. If it is a direct or heap buffer depends on the actual
- * implementation.
- */
- ByteBuf buffer(int initialCapacity, int maxCapacity);
- /**
- * Allocate a {@link ByteBuf} whose initial capacity is 0, preferably a direct buffer which is suitable for I/O.
- */
- ByteBuf ioBuffer();
- /**
- * Allocate a {@link ByteBuf}, preferably a direct buffer which is suitable for I/O.
- */
- ByteBuf ioBuffer(int initialCapacity);
- /**
- * Allocate a {@link ByteBuf}, preferably a direct buffer which is suitable for I/O.
- */
- ByteBuf ioBuffer(int initialCapacity, int maxCapacity);
- /**
- * Allocate a heap {@link ByteBuf}.
- */
- ByteBuf heapBuffer();
- /**
- * Allocate a heap {@link ByteBuf} with the given initial capacity.
- */
- ByteBuf heapBuffer(int initialCapacity);
- /**
- * Allocate a heap {@link ByteBuf} with the given initial capacity and the given
- * maximal capacity.
- */
- ByteBuf heapBuffer(int initialCapacity, int maxCapacity);
- /**
- * Allocate a direct {@link ByteBuf}.
- */
- ByteBuf directBuffer();
- /**
- * Allocate a direct {@link ByteBuf} with the given initial capacity.
- */
- ByteBuf directBuffer(int initialCapacity);
- /**
- * Allocate a direct {@link ByteBuf} with the given initial capacity and the given
- * maximal capacity.
- */
- ByteBuf directBuffer(int initialCapacity, int maxCapacity);
三.总结下
1.ByteBuffer必须自己长度固定,一旦分配完成,它的容量不能动态扩展和收缩;ByteBuf默认容器大小为256,支持动态扩容,在允许的最大扩容范围内(Integer.MAX_VALUE)。
2.ByteBuffer只有一个标识位置的指针,读写的时候需要手动的调用flip()和rewind()等,否则很容易导致程序处理失败。而ByteBuf有两个标识位置的指针,一个写writerIndex,一个读readerIndex,读写的时候不需要调用额外的方法。
3.NIO的SocketChannel进行网络读写时,操作的对象是JDK标准的java.nio.byteBuffer。由于Netty使用统一的ByteBuf替代JDK原生的java.nio.ByteBuffer,所以ByteBuf中定义了ByteBuffer nioBuffer()方法将ByteBuf转换成ByteBuffer。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/193109.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
