大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
浅谈 AnalyticDB SQL 优化
前言
数据库性能优化需要从多个方面进行综合考虑。
例如:系统资源是否充足、资源模型的设计(高性能 vs 大存储)、表的设计以及规划、SQL改写和优化等等,本文只要介绍adb sql的优化
ADB计算引擎
ADB目前支持两种计算引擎:COMPUTENODE Local/Merge(简称:Two-Stage)和MPP:
| 两阶段计算引擎 | FULL MPP计算引擎 | |
|---|---|---|
| 约束限制 | 事实表join要求同表组 join条件必须包含一级分区列,不支持非分区列distinct操作 | 对SQL写法基本无特殊要求,按性能考虑的话,按分区列join性能更好 |
| 性能 | 简单场景:单表查询+一级分区列查询 | 全sql场景:简单查询场景性能比两阶段有10%左右的差异 |
| 版本要求 | 所以版本都支持 | 2.4.2及以上版本 (2.6以上版本支持跟全面) |
默认计算引擎切换:
Local/Merge(简称LM):又称两阶段,优点是计算性能很好,并发能力强,缺点是对部分跨一级分区列的计算支持较差。
Full MPP Mode(简称MPP):支持更丰富的函数,SQL语法,数据量计算能力。
默认计算引擎,V2.8 版本之后默认 MPP,之前版本默认LM。可以按DB切换默认引擎
引擎SQL hint:
/+engine=mpp/ select …. From …where …
/+engine=COMPUTENODE/ select …. From …where …
ADB优化器
ADB查询优化器—数百优化规则
基础优化规则
裁剪规则:列裁剪、分区裁剪、子查询裁剪
下推/合并规则:谓词下推、函数下推、聚合下推、Limit下推
去重规则:Project去重、Exchange去重、Sort去重
常量折叠、谓词推导
探测优化规则
Joins:BroadcastHashJoin、RedistributedHashJoin、NestlooplndexJoin
Aggregate:HashAggregate、SingleAggregate
JoinReorder
GroupBy下推、Exchange下推、Sort下推
高级优化规则
CTE
ADB优化器—SQL Rewrite
SQL parser 通过rewrite一些bad SQL,解决SQL导致索引失效问题
表达式变换
优化前:select a,b from tab where b+1=100;
优化后:select a,b from tab where b=99;比较条件组合
优化前1:SELECT * FROM t WHERE a > 3 OR a >= 2;
优化前2:SELECT * FROM t1 WHERE max_adate > '2022-07-22' AND max_adate != '2022-06-01';
优化后1:SELECT * FROM t WHERE a >= 2;
优化后2:SELECT * FROM t1 WHERE max_adate > DATE '2022-07-22';IS NULL OR IS NOT NULL去重
优化前:SELECT * FROM t1 WHERE stat_date is null or stat_date is not null;
优化后:SELECT * FROM t1;函数常量折叠
优化前:SELECT * FROM t1 t WHERE comm_week BETWEEN CAST( date_format( date_add('day' , -day_of_week('20180605'), date('20180605')), '%Y%m%d')AS bigint) AND CAST( date_format( date_add('day' , -day_of_week('20180605') , date('20180605')), '%Y%m%d')AS bigint);
优化后:SELECT * FROM t1 t WHERE comm_week BETWEEN 20180602 AND 20180602;内部扫描
no-indexHint,可以使条件通过内部扫描执行
/* +no-index=[table.sl] */
select id,sl from table where id='001' and sl<>999;ADB索引
为提高查询响应速度,满足高性能需求场景,AnalyticDB为每个分区建了下列索引:
倒排索引:
分区表的所有列(适用Bitmap索引的列除外)都建了倒排索引,key为排序的列值,value为对应的RowID list,所以对于任何列进行FILTER(WHERE key=value)或者JOIN查询都非常高效。
同时索引采用pForDelta压缩,拥有高压缩比(1:4~1:32)和解压速度(1GB/s)。
Bitmap索引:
对于值重复率高的列,建立Bitmap索引。
区间树索引:
为了加速范围查询,对于类型为数字的列同时建立了区间树索引。
行列混存的块索引–元数据


元数据:
上面介绍了一个分区的数据存储格式,相应的元数据包括:
分区元数据
列元数据
列Block元数据。
其中分区元数据包含该分区总行数,单个block中的列行数等信息;
列元数据包括该列值类型,整列的MAX/MIN值,NULL值数目,直方图信息,用于加速查询;
列block元数据也包含该列的MAX/MIN/SUM, 总条目数(COUNT)等信息,同样用于加速查询
多维组合索引的优化
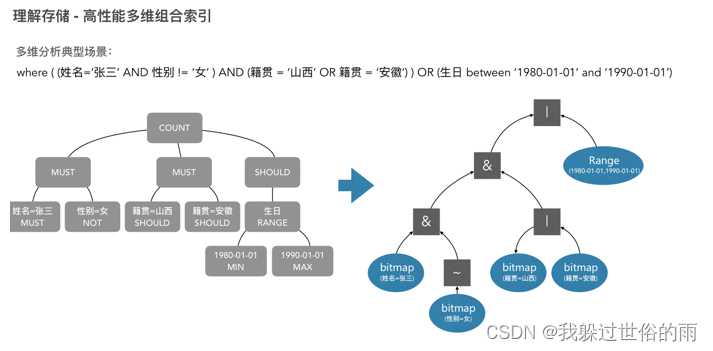
ADB索引设计和使用
ADB默认为表所有列创建索引,无需create index
取消index – disableIndex
参考原则:
只会出现在select子句中,不会在where子句中使用情况
CREATE TABLE f_fskt_orderown (
id varchar COMMENT '',
cu_id varchar COMMENT '',goods_id bigint COMMENT '',
numbers bigint disableIndex true COMMENT '',
total_price double disableIndex true COMMENT '',
order_date bigint COMMENT '',
PRIMARY KEY (order_id,cu_id,order_date)
)
PARTITION BY HASH KEY (id) PARTITION NUM 16
SUBPARTITION BY LIST KEY (order_date)
SUBPARTITION OPTIONS (available_partition_num = 90)
TABLEGROUP ads_demo
OPTIONS (UPDATETYPE='realtime')
COMMENT '';ADB SQL开发与表分区设计
ADB 的数据分布对查询性能有着直接的影响:
- 数据分布要均匀,避免数据倾斜
- 典型查询要能够基于“一级分区键”
- 多表JOIN要能够基于“一级分区键”
- 利用维度表避免数据在分区键Shuffle
- 利用二级分区和聚簇列减少I/O消耗
本地加速关联—分布式计算local join:
在设计表的一级分区方案务必根据查询SQL的特点来确定,分布式计算平台下,实现多表join关联查询加速,需要优先考虑local join。
ADB对local join有如下前提要求:
1.事实表 join 维度表
维度表记录数尽量不要超过千万,特殊情况极限小于2 千万
事实表 join 维度表,不限制关联条件
2.事实表 join 事实表
join条件必须包含一级分区列
同时要求join的表的一级分区数一致
ADB SQL开发的性能指南
SQL开发原则概况—如何获取更高性能
ADB是一个分布式、列存数据库,极速计算内核设计:实时计算,高QPS
SQL编写原则: 追求简单
大部分情况下性能随 SQL复杂度下降,比如:单表查询 (冗余设计)优于 表关联查询。
SQL优化核心方法:减少IO
索引扫描,尽可能少的列扫描,返回最小量数据量,减少IO同时也减少内存开销。
分布式计算:本地计算&并行计算
大数据计算情况,本地计算避免数据跨节点,充分利用分布式多计算资源的能力。
高QPS:分区裁剪
业务系统要求高QPS,毫秒级RT,请记住一定要将表和SQL设计为分区裁剪模式。
SQL开发规范:
ADB SQL开发规范
- 多表JOIN要能够基于“一级分区键”
- 所有的LEFT JOIN 要放在INNER JOIN之后
- 尽可能添加足够的过滤条件
- 尽量避免子查询导致数据shuffle
- 利用维度表避免数据在分区键Shuffle
- 尽量避免LEFT JOIN
- 避免含有聚合运算的子查询
- 避免在列上添加函数导致索引失效:
索引和扫描选择
默认查询都走索引,但是走索引检索在下面的几种情况下,性能较差。
1.范围查询(或等值查询)筛选能力差
2.不等于条件查询(不包括 not null)
3.中缀或后缀查询,例如 like ‘%abc’ 或 like ‘%abc%’
4.AND 条件中某一条件具有高筛选能力,其他条件走索引性能比扫描性 能差
示例:
select * from table1 where x= 3 and time between 0 and 10000000000 ;对于这条查询 sql ,我们可以认为 x=3 筛选后的结果集肯定是比较小了,因 为是一个精确匹配。如果 select count(*) from table1 where x= 3 出来的结 果比较小的话,time 列再去走索引效果反而差。
所以,对于这种 query,增加 hint no-index:
/*+ no-index=[table1.time]*/ select * from table1 where x= 3 and time between 0 and 9999999999;上述语句表示强制条件 time between 0 and 10000 走扫描。计算引擎首先检 索列 x 的索引,得出满足条件 x=3 的行集合,然后读取每行所对应的 time 列 数据,如果满足 time between 0 and 9999999999,则将该行数据加入返回结果。
SQL开发规范与示例–表关联性能最佳SQL示例
表join:保证:Local Join
一级分区键join
一级分区数一致

SQL开发规范与示例—一级分区裁剪
当要求高QPS查询业务时,需要从表的设计和SQL上利用分区裁剪能力。
SQL开发规范与示例—二级分区裁剪
包含二级分区情况,SQL中增加二级分区条件,减少二级分区扫描

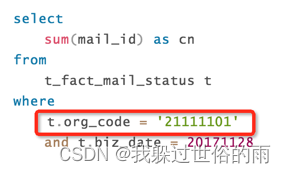
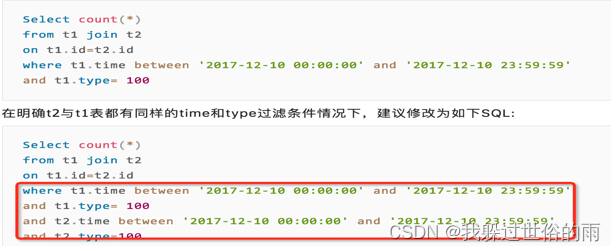
多表关联–尽量的充分的过滤条件
多表关联查询,where条件中,需要显示的写明每一个表的过滤条件。通常我们习惯在传统数据库中,都是通过索引字段关联来快速检索数据。如下SQL:
子查询使用
对于子查询,ADB会首先执行子查询,并将子查询的结果保存在内存中,然后将该子查询作为一个逻辑表,执行条件筛选。由于子查询没有索引,所有条件筛选走扫描。因此如果子查询结果较大时,性能比较差;反之当子查询结果集较小时,扫描性能反而超过索引查询。
对于join查询,由于AnalyticDB默认采用hash join算法,如果其中一张表结果集(条件筛选后)较大时,扫描性能会比索引差很多,因此尽量不要采用子查询。
例如以下SQL:
Select A.id from table1 A join (select table2.id from table2 where table2.y = 6) B on A.id= B.id where A.x=5 ;当满足条件x=5 和y=6的条数较多时,应改成:
Select A.id from table1 A join table2 B on A.id = B.id where B.y = 6 and A.x=5 ;ADB慢SQL的定位和常见原因
SQL问题定位及优化方法导图
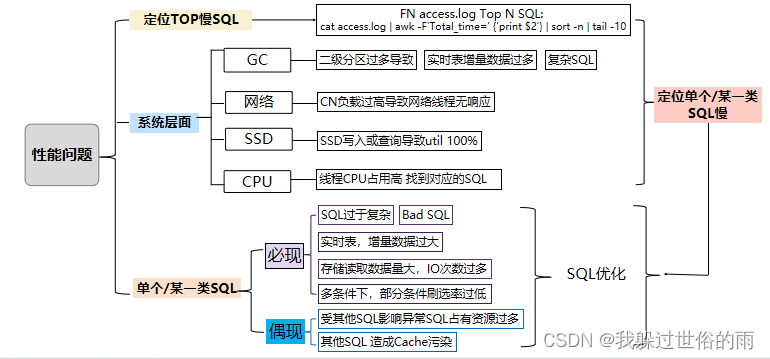
Top N Slow SQL
FN access.log 日志文件,如果多个Fn需要每个FN都搜索下
cat access.log | awk -F’Total_time=’ {‘print $2’} | sort -n | tail -10
获取FN 日志步骤
- who am i获取当前FN的IP:port 或者通过 gallardo ui找到FN
- 登录FN,su admin
- netstat -ntpld ${port}
输出: tcp 0 0 0.0.0.0:9999 0.0.0.0:* LISTEN 205213/java - pwdx ${进程ID} 如205213 返回FN进程的路径
- cd ${进程路径}/logs
性能问题定位 — 系统 — GC
grep stop gc.log |grep -v “ed:0” 短时间内有大量超过1s的GC
| 问题排查&原因 | 解决方案 |
|---|---|
| 二级分区数过多导致GC cd ${workdir}/tmp/; tree -L 5 | wc -l 如果结果超过10000,则表明二级分区数过多 |
缩减二级分区个数,或者二级分区周期调整为周/月 扩容 |
| 实时表数据量太多 cd /${workdir}/tmp/ find . -name “922*”|xargs du -sh * |egrep “[0-9]G” 如果有超过1GB的增量数据,则该数据的version(倒数第三层目录)对应时间超过1天,通常表示上次基线合并有问题。否则有可能当天实时增量数据写入过大 |
如果基线合并问题,则需要排查并解决 如果当天写入实时数据过大,需要对大表进行optimize table $table_name 如果系统不能恢复,建议将DB级别配置delayPullRTData设置为60000 (每分钟pull一次实时数据),减少实时数据对系统的压力,如果GC过于严重,基本不能服务,则影响上线,建议重启CN |
| 复杂SQL导致GC CN查询exception.log,是否有异常超时SQL,并判断该SQL计算数据量(如全表group by ,全表order by等操作) egrep -B 2 “mhm=[0-9]{9,}” analysis.log识别是否有消耗内存超过1GB的SQL |
找到问题SQL,并优化SQL |
性能问题定位 — 系统 —网络层面问题
CN CPU负载过高,导致网路线程无响应/超时
查询不稳定
| 问题排查&原因 | 解决方案 |
|---|---|
| FN analysis.log显示某一个或者少数CN节点返回超时或者出错 CN 如下现象:CPU load非常高,并且根据jstack显示load较高的线程为epollwaitnetstat -anp结果中有部分连接的Rec-Q或 Send-Q非常大(超过1000) netstat -anp连接数非常多,或有大量CLOSE_WAIT状态的连接 grep packet log.log有大量超时或者失败的日志 |
临时方案:按副本重启CN及FN 排查CPU负载过高问题并解决 |
性能问题定位 — 系统 —SSD磁盘Util过高
| 问题排查&原因 | 解决方案 |
|---|---|
| tsar -I 1 -l, SSD盘的util接近100% 排查方法:jstack ${pid} |
如果是下载线程导致,则可以减少下载线程数,修改/gloable/config/taskThreadCount为较小值(5) 如果是写入导致的,一般是由于主键无序导致的,建议优化主键,尽量保证有序。同时可以减少实时线程数,配置:/global/config/pullMQThreadCount为较小的值 如果是查询线程,则需优化SQL |
性能问题定位 — 系统 —CPU负载过高
| 问题排查&原因 | 解决方案 |
|---|---|
| 登录CN,jstack ${pid}|grep localnode ,通常对应stack trace的线程名称为当前运行SQL 使用top -Hpxi er ${pid},查看是否存在某写线程一直占有超过50%的CPU,将线程Id转换为16进制(小写),在jstack中查找该值,找到对应的stack,通常线程name为正在运行的SQL |
识别导致CPU过高的SQL,并优化 |
SQL执行开销日志 analysis.log—udf_sys_log
通过 udf_sys_log() 获取CN analysis.log日志
select udf_sys_log() from ( SQL Statement) ;
udf_sys_log()返回信息

FN日志找CN节点
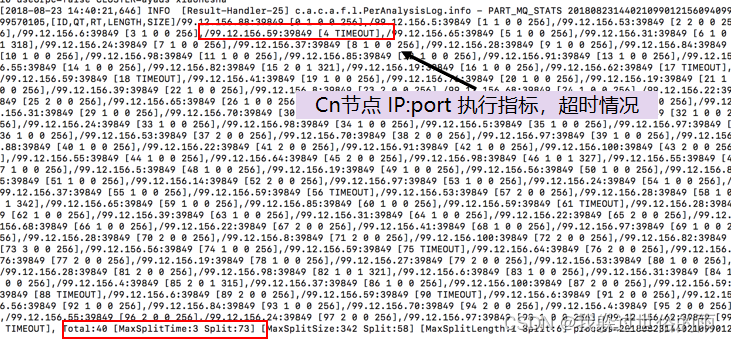
ADB慢SQL优化实例
查询优化 – 索引失效:
避免过滤条件带有针对列的函数计算:
例如:select * from table where year(date_test) >= 2018;
应该改为:select * from table where date_test >= '2018-01-01';避免多表链接时基于函数关联:
例如:select t1.id from t1 inner join t2 on year(t1.birthday) = year(t2.birthday)
应该在t1、t2表中增加yyyy列,改为:select t1.id from t1 inner join t2 on t1.yyyy = t2.yyyy;避免类型转换:
- 应当在表设计之初就要充分考虑类型的统一
- 此类问题经常出现在 date/timestamp/varchar 数据类型的转换
查询优化 – 列的类型选择
原理
- ADB 处理数值类型的性能远好于处理字符串类型
- 建议尽可能使用 数值类型、日期型、时间戳
- 基于标签的查询推荐使用 多值列(multivalue)
常见将字符串转换为数值类型方法
- 包含字符前缀或后缀,例如E12345,E12346等。可以直接去掉前缀或者将前缀映射为数字
- 该列只有少数几个值,例如国家名。可以对每个国家编码,每个国家对应一个唯一数字
主键优化
- 设置主键的原理
- 主键必须包括分区键,二级分区键
- 主键尽可能少,短
- 主键尽可能递增或递减
SQL优化技巧 – localJoin:
原理:
- 使用 localJoin 时,计算可以在节点内完成,避免数据Shuffle
- 通常情况下,localJoin 会大幅提升RT和并发度
在多表关联查询时:
- 要含有 一级分区键 的等值链接
- 或者确保其中的一张表的链接键是一级分区键
- 如果两表链接无法基于一级分区键,可以考虑把其中的一张表转换为维度表
- 驱动表的数据量应当尽量的少
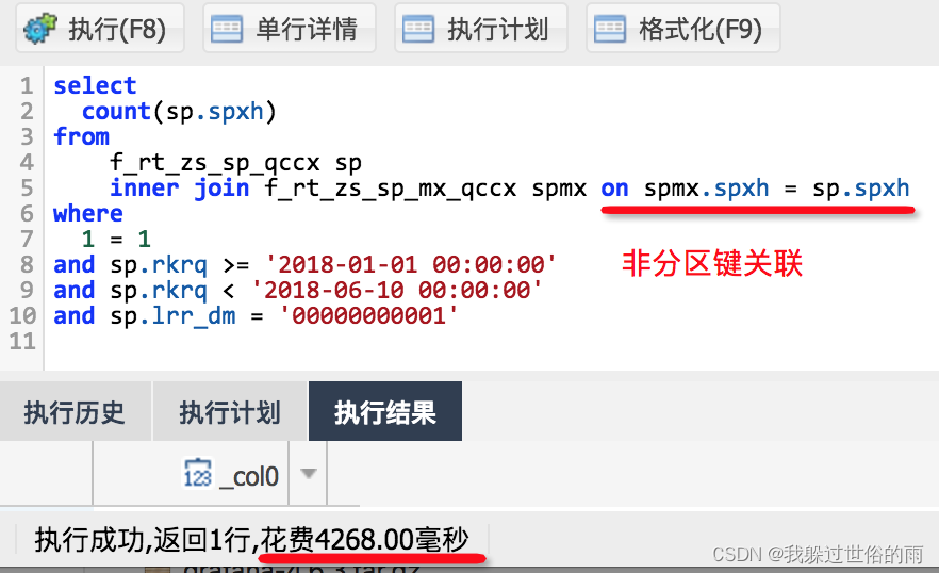
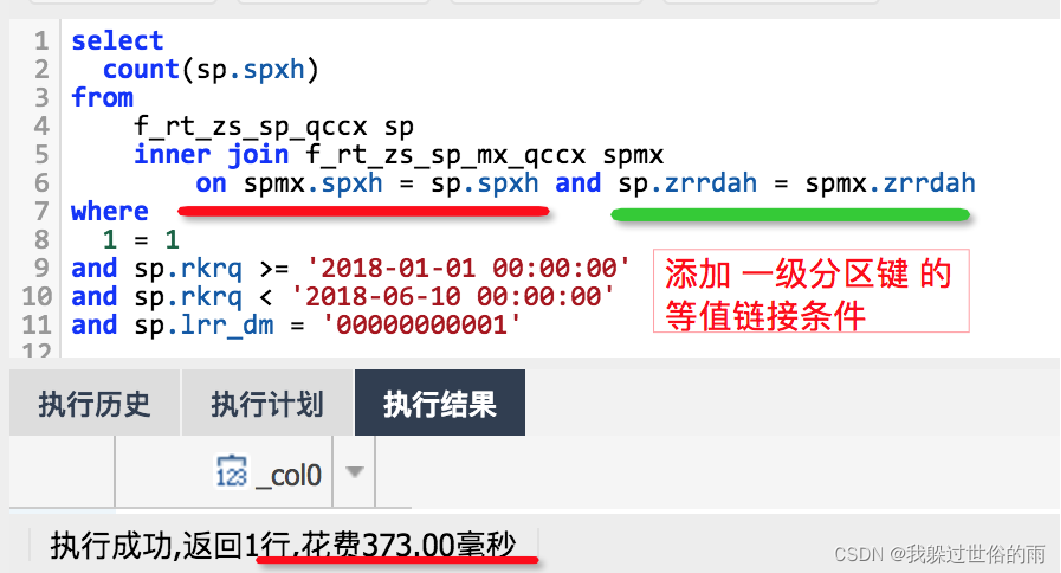
实例:
- 表A 和 表B 链接时 没有基于一级分区键,查询耗时 4.2sec
- 经过业务确认,在增加一级分区键的等值链接后,查询耗时 0.37sec ,性能提升10倍
优化前:
优化后:
SQL优化技巧 – hashJoin:
原理:
- 使用 hashJoin 时,计算在内存中完成,可以充分利用分布式的计算能力
- 通常情况下,hashJoin 更加适合大结果集的运算
在多表关联查询时:
- 要含有 一级分区键 的等值链接
- 或者确保其中的一张表的链接键是一级分区键
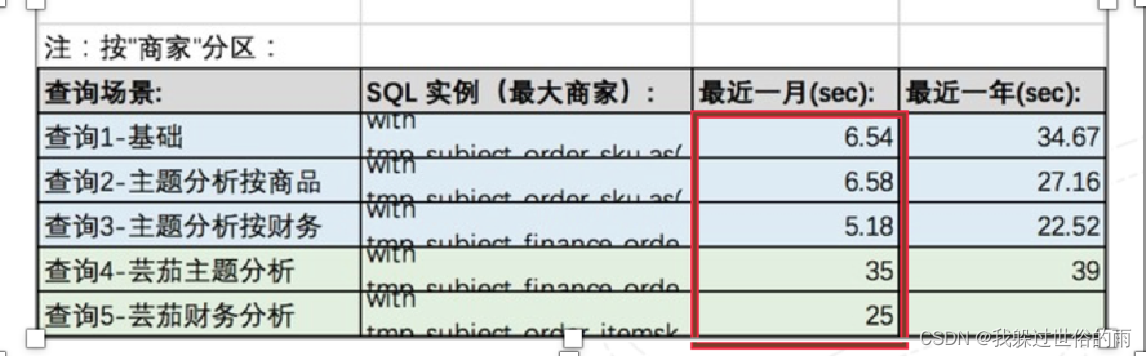
实例:
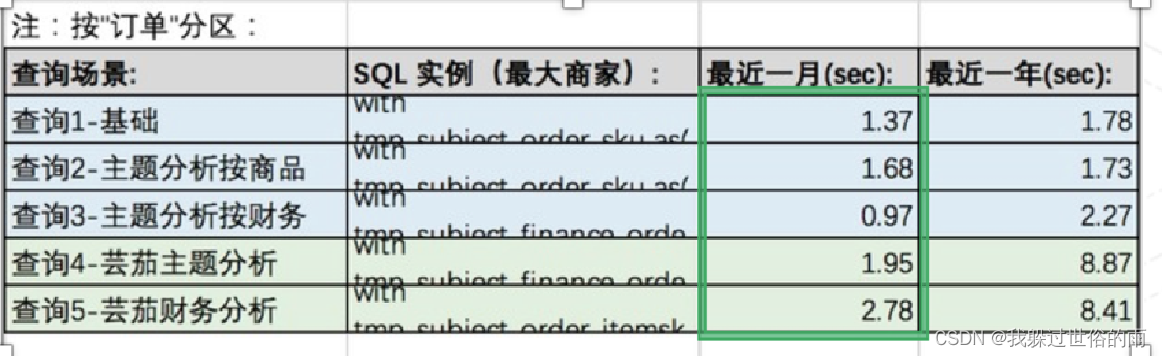
- 测试1:按照“商家ID”做一级分区键,任何基于商家的统计可在单独的分区内完成,但导致分布不均,计算存在热点
- 测试2:按照 “订单ID”做一级分区键,数据分布均匀,但任何基于商家的统计需要在所有节点上进行并行计算
- 测试结果表明:按照“订单ID”查询更快,且数据量越大越明显
谢谢观看!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/192925.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
