大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
文章目录
- 一、eBPF编程接口
- 二、开发方式
- 三、环境搭建
- 四、eBPF实践
-
- 4.1 使用BCC工具
-
- 1. bcc Python Developer Tutorial
-
- lesson1: hello word
- lesson2: sys_sync()
- lesson3: hello_fields
- lesson4: sync_timing
- lesson5: sync_count
- lesson6: disksnoop.py
- lesson7: hello_perf_output
- lesson9: bitehist.py
- lesson10: disklatency.py
- lesson11: vfsreadlat.py
- lesson12: urandomread.py
- Lesson13:disksnoop.py fixed
- lesson14: strlen_count.py
- lesson 15. nodejs_http_server.py
- lesson 16. task_switch.c
- 2. 极客时间习题
- 4.2 linux内核源码自带样例
- 4.3 gobpf库工具的使用
- 4.4 bpftool调试工具的使用
- 4.5 bpftrace工具的使用
- 五、遇到的问题总结
参考资料:
- 《BPF之巅-洞悉linux系统和应用性能》
- https://www.ebpf.top/post/bpf-co-re-btf-libbpf/
- 极客时间《eBPF核心技术与实战》
一、eBPF编程接口
几乎所有编程接口都可见于:内核源代码的include/uapi/linux/bpf.h文件中
1.1 系统调用bpf(2)
详细可见手册: https://man7.org/linux/man-pages/man2/bpf.2.html
基本使用:
int bpf(int cmd, union bpf_attr *attr, unsigned int size);
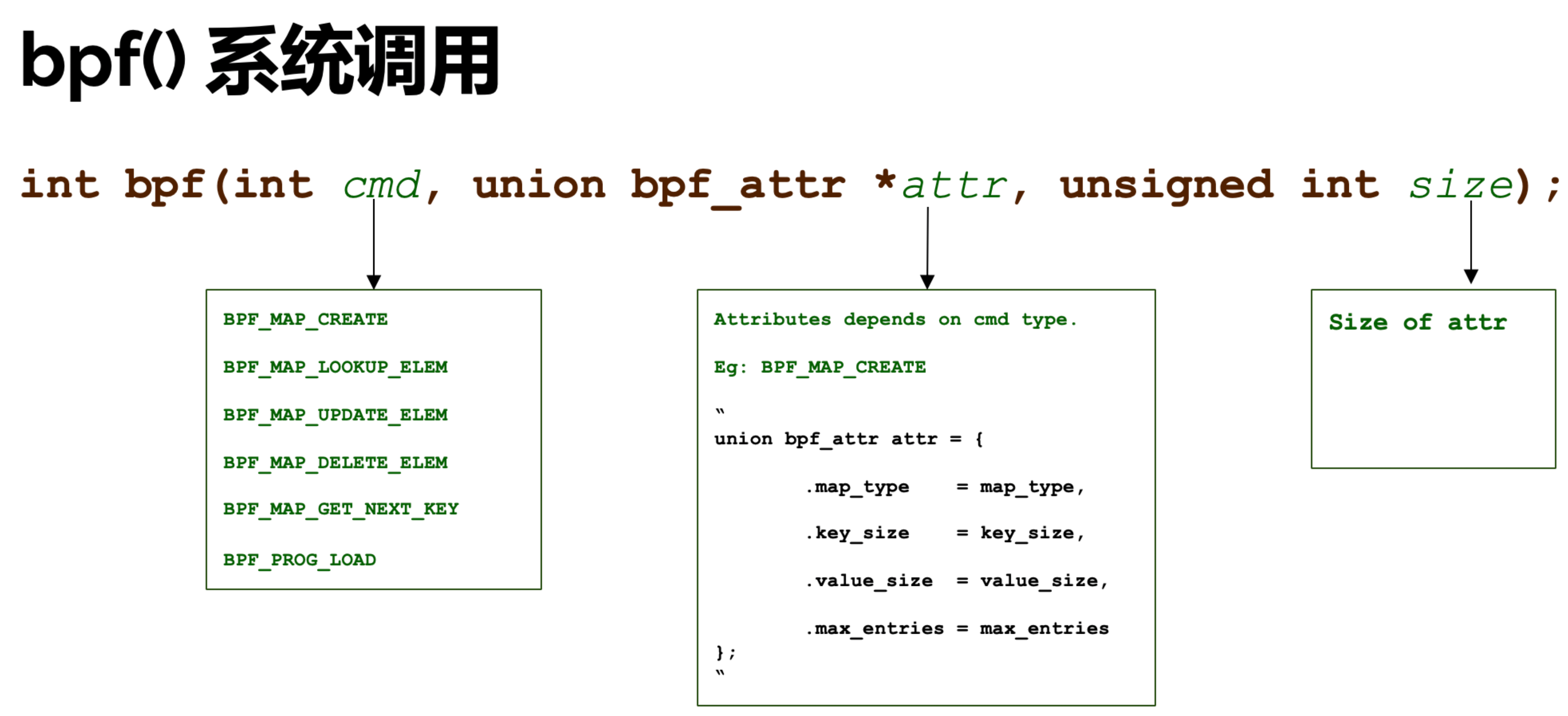

cmd表示不同的类型(例如使用bps()系统调用和BPF_PROG_LOAD命令用于加载程序)bpf_attr union允许在内核和用户空间之间传递数据; 确切的格式取决于cmd参数。size这个参数表示bpf_attr union这个对象以字节为单位的大小
1.2 eBPF的系统调用命令
即上面bpf系统调用中的CMD,其作为第一个参数传递:
-
可以使用命令创建和修改
eBPF maps数据结构,这个数据结构是一个通用键值对数据结构,用于在eBPF程序和内核或用户空间之间通信 -
分类:
-
使用
eBPF程序的命令 -
使用
eBPF maps的命令 -
同时使用
eBPF程序和eBPF maps的命令
-
可以通过strace命令看到具体的系统调用(不建议使用strace,因为会影响性能):

具体

1.3 eBPF的程序类型
程序类型是针对加载eBPF程序的系统调用命令BPF_PROG_LOAD的第二个参数中定义的

BPF_PROG_LOAD加载的程序类型定义了以下四个方面:
- 程序可以附加在哪里即可以挂载的事件类型以及事件的参数
- 验证器允许调用内核哪些辅助函数
- 网络包数据是否可以直接访问
- 作为第一个参数传递给程序的对象类型
实际上,程序类型本质上定义了一个API,通过不同的程序类型区分允许调用的不同函数列表
目前内核支持的eBPF程序类型列表如下所示:
- 用于
BPF追踪的程序类型:BPF_PROG_TYPE_KPROBE: 用于内核动态插桩和用户态插桩(即kprobe和uprobe)BPF_PROG_TYPE_TRACEPOINT: 用于内核静态跟踪点BPF_PROG_TYPE_PERF_EVENT: 用于perl_event,包括PMCBPF_PROG_TYPE_RAW_TRACEPOINT: 用于跟踪点,不处理参数
- 其他:
BPF_PROG_TYPE_SOCKET_FILTER: 用于挂载在网络套接字上用于网络数据包过滤,也是最早的BPF使用场景BPF_PROG_TYPE_SCHED_CLS: 用于网络流量控制分类BPF_PROG_TYPE_SCHED_ACT: 用于网络流量控制动作BPF_PROG_TYPE_XDP: 用于从设备驱动程序接收路径运行的网络数据包过滤,XDP(eXpress Data Path)程序BPF_PROG_TYPE_CGROUP_SKB: 用于控制组的网络数据包过滤BPF_PROG_TYPE_CGROUP_SOCK: 由于控制组的网络包筛选器,它被允许修改套接字选项BPF_PROG_TYPE_LWT_*: 用于轻量级隧道的网络数据包过滤BPF_PROG_TYPE_SOCK_OPS: 用于设置套接字参数的程序BPF_PROG_TYPE_SK_SKB: 用于套接字之间转发数据包的网络包过滤BPF_PROG_CGROUP_DEVICE: 确定是否允许设备操作
1.4 eBPF使用的数据结构(Map映射)
eBPF程序使用的主要数据结构是eBPF map(键值对)数据结构,这是一种通用的数据结构,允许在内核内部或内核与用户空间之间来回传递数据.
使用bpf()系统调用创建和操作map数据结构。成功创建map后,将返回与该map关联的文件描述符。每个map由四个值定义:
- 类型
- 元素的最大个数
- 值大小(以字节为单位)
- 键大小(以字节为单位)
有不同的map类型,每种类型都提供不同的行为和一些权衡:
BPF_MAP_TYPE_HASH: 一种哈希表BPF_MAP_TYPE_ARRAY: 一种为快速查找速度而优化的数组类型, 一般可用于计数器BPF_MAP_TYPE_PROG_ARRAY: 与eBPF程序相对应的一种文件描述符数组;用于实现跳转表和处理特定(网络)包协议的子程序BPF_MAP_TYPE_PERCPU_ARRAY: 一种基于每个cpu单独维护的更快的数组BPF_MAP_TYPE_PERF_EVENT_ARRAY: 存储指向perf_event环形缓冲区数据结构的指针,用于读取和存储perf事件计数器BPF_MAP_TYPE_CGROUP_ARRAY: 存储指向控制组的指针BPF_MAP_TYPE_PERCPU_HASH: 一种基于每个CPU单独维护的更快的哈希表BPF_MAP_TYPE_LRU_HASH: 一种只保留最近使用项的哈希表BPF_MAP_TYPE_LRU_PERCPU_HASH: 一种基于每个CPU的哈希表,只保留最近使用项BPF_MAP_TYPE_LPM_TRIE: 一个匹配最长前缀的字典树数据结构,适用于将IP地址匹配到一个范围BPF_MAP_TYPE_STACK_TRACE: 调用栈存储,使用栈ID索引BPF_MAP_TYPE_ARRAY_OF_MAPS: 一种map-in-map数据结构BPF_MAP_TYPE_HASH_OF_MAPS: 一种map-in-map数据结构BPF_MAP_TYPE_DEVICE_MAP: 用于存储和查找网络设备的引用BPF_MAP_TYPE_SOCKET_MAP: 存储和查找套接字,并允许使用BPF帮助函数进行套接字重定向
可以使用bpf_map_lookup_elem()函数和bpf_map_update_elem()函数从eBPF程序或用户空间程序访问所有map对象
某些map类型,如套接字类型map,它是与那些执行特殊任务的eBPF辅助函数,一起工作

1.5 eBPF辅助函数/BPF API的作用?有哪些?
作用:由于BPF不允许随意调用内核函数,所以为了完成某些任务提供了一些可以调用的辅助函数
详细可见手册: https://man7.org/linux/man-pages/man7/bpf-helpers.7.html
所有的辅助函数在内核源代码的
include/uapi/linux/bpf.h文件,或者见:https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md#
常见辅助函数以及作用理解:
| 函数名 | 作用 |
|---|---|
bpf_probe_read(dst,, size, src) |
1. 因为BPF程序只能访问BPF寄存器和栈空间(通过辅助函数也可以访问map映射表),如果要访问其他内核地址内存,就需要使用此函数(会进行安全性检查并禁止缺页中断的发生); 2. 用于将用户空间内容读取到内核空间中(具体机制和具体体系结构相关,不是所有都支持) |
bpf_map_lookup_elem(map, key) |
在映射表中查找键key, 并且返回它的值(指针) |
bpf_map_update_elem(map, key, value, flags) |
根据key更新对应的value值 |
1.6 eBPF并发控制
linux内核5.1增加了spin lock之后才有了并发控制,所以需要满足内核版本最低要求
目前spin lock还不能在跟踪程序中直接使用;多个线程对映射表map进行查找和更新可能会造成“丢失修改”问题, 所以前端使用映射类型的时候最好使用perl-CPU的哈希和数组映射类型,最小化冲突(这也是BCC和bpftrace前端的做法)
一个具体的计数器例子在于:
- 每个逻辑
CPU独享数据结构映射,避免并行共享数据更新冲突 - 可以先让每个逻辑
CPU上的映射结构更新,然后通过一个对事件计数的映射表将每个CPU对应的映射表值相加得到事件总数
其他方式:
- 互斥相加操作
BPF_XADD - 映射中的映射机制(对整个映射进行原子性的更新)
BPF自旋锁机制,可以通过bpf_spin_lock()和bpf_spin_unlock()实现控制bpf_map_update_elem()对常规的Hash和LRU操作都是原子性的
1.7 eBPF的sysfs接口
eBPF还通过VFS接口暴露BPF程序和BPF映射, 文件位置在于/sys/fs/bpf/
所以可以用pinning模式(类似于daemon程序)的用户态程序,持续运行交互eBPF程序(即时已经运行结束)
当前的Cillium项目就是使用的这种方式,在网络互联方面很常见
1.8 BTF、CO-RE是BPF工具的未来
参考:
- https://www.ebpf.top/post/bpf-co-re-btf-libbpf/
1. 什么是BTF(BPF类型格式)?
起因:
- 对于被跟踪程序的源代码信息了解的很少,编写
BPF工具很困难
解决方案:
BTF(BPF Type Format)是一个元数据格式,将BPF源代码信息编码到调试信息中;目前元数据包括:数据结构、函数信息、源代码/行信息、全局变量信息等
BTF调试信息可以通过随BPF程序一同使用原生Clang编译生成或者通过LLVM JIT生成,这样BPF程序就更容易被加载器(例如libbpf)或者工具(例如bpftool)使用
BPF跟踪工具通常需要在机器上安装内核头文件(一般是linux-headers包), 但是即使是这些头文件也有时不会包含所有的内核结构定义,所以BTF解决了这个问题(对内核头文件的依赖),BTF可以通过对所有数据结构的准确定义
我的理解:
BTF实现了对BPF源程序代码的解释,从而方便调试、避免对内核头文件和Clang的依赖;
未来一个带着BTF信息的Linux内核vmlinux二进制文件,将会是自解释的(不依赖内核)
vmlinux文件: 一种内核文件,是编译出来的最原始的内核文件,没有压缩
例子:使用bpftool工具查看基于BTF编译生成的BPF程序

2 什么是CO-RE?
一次编译到处运行即CO-RE(Compile Once - Run Everywhere), 也是eBPF最大的改进之一
核心在于:支持将BPF程序编译为字节码,保存后分发到其他机器执行, 这样可以避免要求运行环境安装BPF编译器(LLVM和Clang)
核心挑战:
- 不同操作系统内核数据结构的编译量不同,需要根据不同底层重写访问偏移量(也就意味着要重新编译)
- 不可见的数据结构成员,这要根据不同内核版本、内核配置选项信息以及用户提供的运行时信息来动态发访问调整
所以,目前集中要解决的就是**BPF字节码的可重定位/替换(避免需要llvm重新编译)**
3. 最小化基础依赖
目前,有许多 BPF(eBPF)初创公司正在构建网络,安全性和性能产品(并且更多未浮出水面的),但是要求客户安装 LLVM,Clang 和内核头文件依赖(可能消耗超过100 MB的存储空间)是一个额外的负担
BTF和CO-RE的目标就是:
BPF 工具现在可以是一个轻量的ELF二进制文件, 其中包含了预编译的BPF字节码,它可以在任何具有 BTF 的内核上运行,而不是要求客户安装各种重量级(且脆弱)的依赖项
例如:(重写的opensnoop)
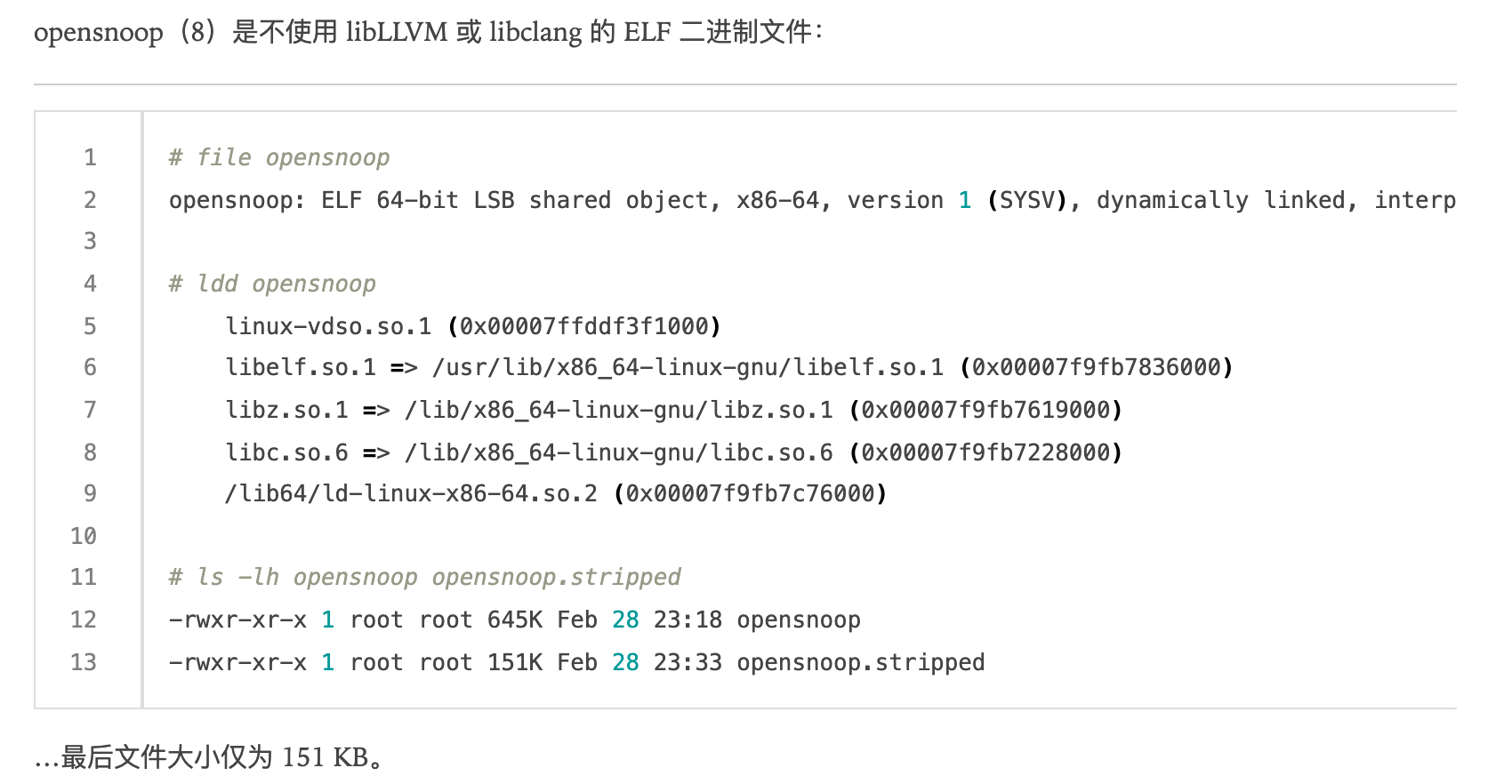
实现原理:
BTF提供类型信息,以便可以根据需要查询结构偏移量和其他详细信息(无需再重新遍历内核结构)CO-RE记录需要重写 BPF 程序的哪些部分以及如何重写
注:
- 新的 BPF 二进制文件仅在设置了此内核配置选项后才可用
CONFIG_DEBUG_INFO_BTF = y;Ubuntu 20.10已经将此配置选项设置为默认选项,所有其他发行版都应遵循- 现在,随着我们转向带有
BTF和CO-RE的libbpf C,已经不赞成使用 BCC Python 中的性能工具
1.9 BPF程序编写限制
- 只能调用在
API中定义的BPF辅助函数 - 受限的循环,禁止无限循环(可能会导致整个系统死锁)
- BPF栈的大小 <
MAX_BPF_STACK=512 (可以转移到映射存储空间) - BPF程序总指令数量 <
100万 (最初是4096, 对于非特权执行的BPF程序上限也是4096)
二、开发方式
2.1 手动执行每一步
手动的具体步骤包括哪些?
简单的总结为:
- 使用C语言开发一个
eBPF程序 - 借助
LLVM将eBPF程序编译为BPF字节码 - 通过
bpf系统调用将BPF字节码提交给内核 - 内核验证并运行
BPF字节码,并把相关的状态保存到BPF映射map中 - 用户程序通过
BPF查询BPF字节码的运行状态
一些细节:
以下来自*《A thorough introduction to eBPF》*
在最开始的开发中,必须通过手工编写eBPF汇编代码,并使用内核的bpf_asm汇编程序来生成BPF字节码,现在只需要使用LLVM Clang编译器增加了对eBPF后端的支持,现在可以将C语言写的程序通过LLVM Clang编译器,编译成字节码。然后可以使用bpf()系统调用函数和BPF_PROG_LOAD命令,直接加载包含这个字节码的对象文件
通过使用Clang编译器,配合-march=bpf参数,您就可以用C语言编写自己的eBPF程序了。在内核代码的 samples/bpf/ 目录下有很多eBPF程序的示例,它们的文件名称大部分都具有「_kern.c」的后缀。Clang编译出来的目标文件(eBPF字节码),需要由在本机运行的一个程序进行加载(这些示例的文件名称中通常具有「_user.c」)
kern.c和user.c分别对应内核态和用户态的eBPF使用
为了更容易地编写eBPF程序,内核提供了libbpf库,其中包括用于加载程序、创建和操作eBPF对象的帮助函数。举个例子,一个eBPF程序和使用libbpf库的用户程序的抽象的工作流程一般像如下这样的:
- 读取eBPF字节码到用户应用程序中的缓冲区,并将其传递给
bpf_load_program()函数 - eBPF程序,当在内核运行时,它将调用
bpf_map_lookup_elem()函数来查找map中的元素,并存储新值给这个元素。 - 用户应用程序调用
bpf_map_lookup_elem()函数来读取eBPF程序存储在内核中的值。
2.2 借助BCC工具
1. bcc出现原因?什么是BCC?
-
出现原因:
对于在生产环境机器或者客户机上工作的工程师来说,从内核源代码中编译程序并链接到
eBPF库是比较困难的(避免手动的繁琐流程) -
BCC是什么:
BPF Compiler Conllection, 一个BPF编译器集合,包括用于编写、编译和加载eBPF程序的工具链,以及用于调试和诊断性能问题的示例程序和久经考验的工具,并向上提供了高级语言支持Python、C++等
代码仓库:https://github.com/iovisor/bcc
工具大全(部分是BCC提供的):
2. 借助BCC开发的优势
-
支持高级语言接口
BCC支持高级语言进行编程(Python和Lua)例如,开发人员可以将eBPF map类比为Python字典,并可以直接访问映射内容,这是通过使用BPF帮助函数,它在内部实现这个功能。 -
错误提示
BCC调用LLVM Clang编译器,这个编译器具有BPF后端,可以将C代码转换成eBPF字节码。然后,BCC负责使用bpf()系统调用函数,将eBPF字节码加载到内核中如果加载失败,例如内核验证器检查失败,则BCC提供有关加载失败原因的提示,如,“提示:如果在没有首先检查指针是否为空的情况下,从map查找中取消引用指针值,可能就会出现**
The 'map_value_or_null'**”。这是创建BCC的另一个动机——因为很难写出明显正确的BPF程序;当你犯了错误时,BCC会通知你
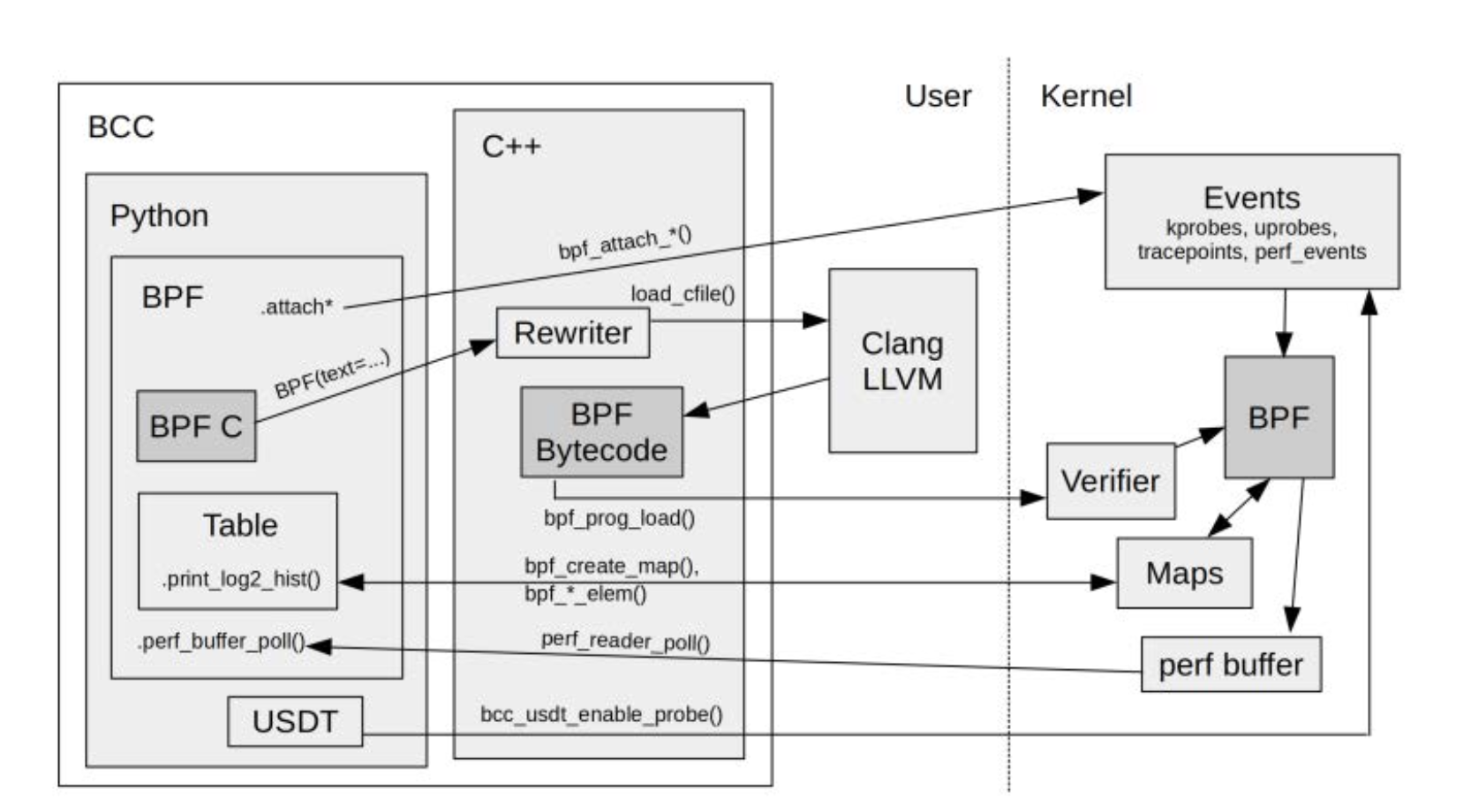
3. bcc基本架构
2.3 使用bpftrace
1. bpftrace是什么?
bpftrace是一个基于BPF和BCC的高级性能探测工具,它提供了/封装了一个高级的编程语言环境,可以方便的让我们去实现对某些性能探测任务
2. bpftrace的架构?
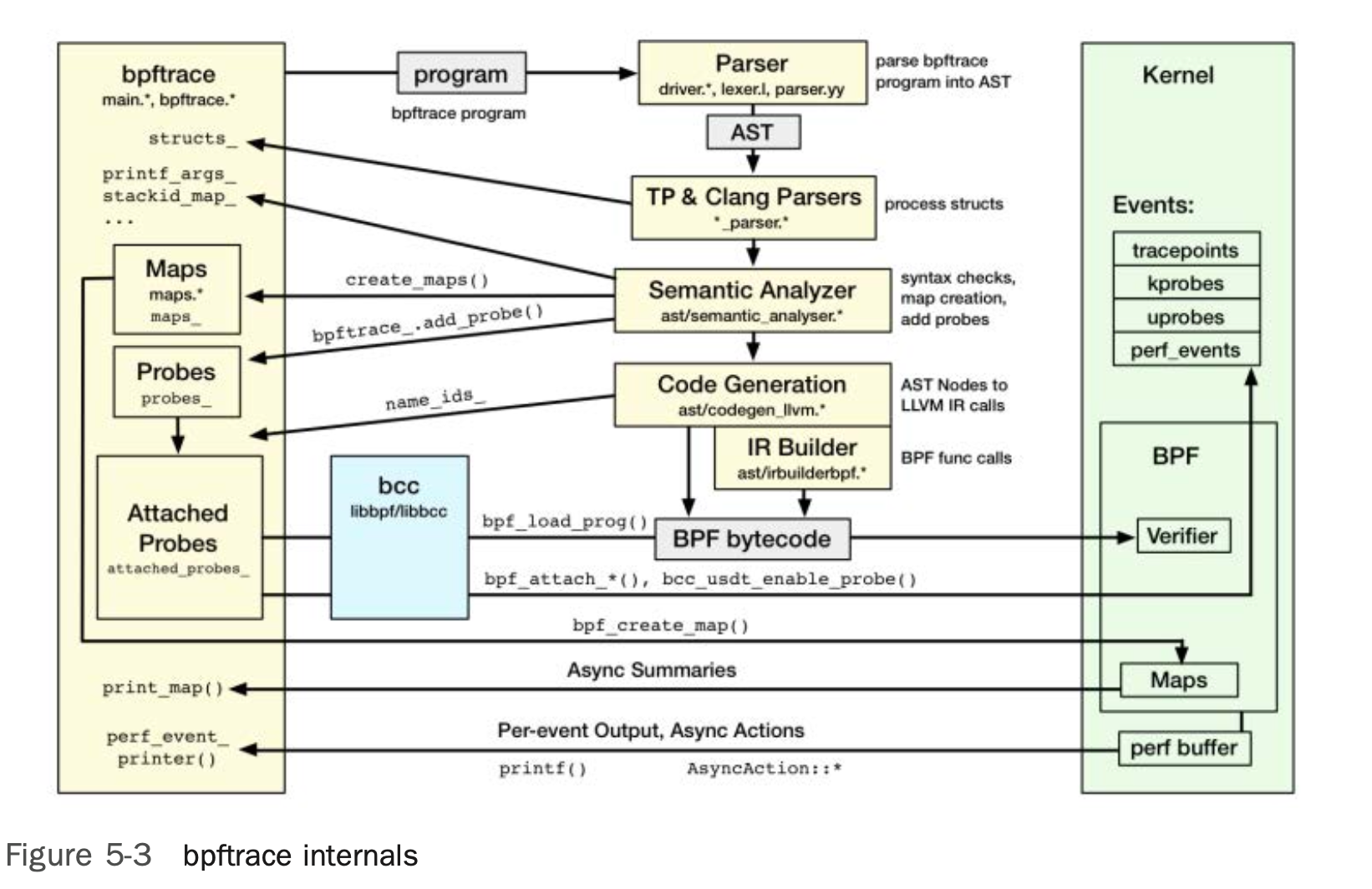
- 上层抽象语言最终还是会通过
llvm编译为最终的BPF字节码 - 底层还是需要依赖
libbcc和libbpf两个库实现探针的插桩、程序的加载等功能
所以核心底层依赖与BCC基本相同,只不过上层封装后编写更加方便
三、环境搭建
1. linux环境搭建
最好使用最新版本的内核才能够使用大部分的功能,可以通过vagrant创建一个linux虚拟机
sudo apt-get install virtualbox vagrant
vagrant init ubuntu/impish64
vagrant up
vagrant ssh # 连接到虚拟机
uanme -a
lsb_release -a
如果嫌麻烦可以用大佬已经做好的docker镜像,一步到位不用担心环境(bcc也在):
https://github.com/Jun10ng/ebpf-docker-for-desktop
2. bcc环境搭建
前提:a Linux kernel version 4.1 or newer is required 此外,内核应该已经编译并设置了以下标志
CONFIG_BPF=y
CONFIG_BPF_SYSCALL=y
# [optional, for tc filters]
CONFIG_NET_CLS_BPF=m
# [optional, for tc actions]
CONFIG_NET_ACT_BPF=m
CONFIG_BPF_JIT=y
# [for Linux kernel versions 4.1 through 4.6]
CONFIG_HAVE_BPF_JIT=y
# [for Linux kernel versions 4.7 and later]
CONFIG_HAVE_EBPF_JIT=y
# [optional, for kprobes]
CONFIG_BPF_EVENTS=y
# Need kernel headers through /sys/kernel/kheaders.tar.xz
CONFIG_IKHEADERS=y
可以从/proc/config.gz or /boot/config-<kernel-version>中查看自己主机内核的配置是否适配
(我的文件在vim /boot/config-4.15.0-48-generic , 注意除非重新编译,否则此文件不能更改)
最简单的方式:包管理器安装
# 第一种方式:包安装
sudo apt-get install bpfcc-tools linux-headers-$(uname -r)
比较复杂的方式(不建议):
# 第二种方式:源码安装(包括下面的安装和编译)
# Trusty (14.04 LTS) and older
VER=trusty
echo "deb http://llvm.org/apt/$VER/ llvm-toolchain-$VER-3.7 main deb-src http://llvm.org/apt/$VER/ llvm-toolchain-$VER-3.7 main" | \
sudo tee /etc/apt/sources.list.d/llvm.list
wget -O - http://llvm.org/apt/llvm-snapshot.gpg.key | sudo apt-key add -
sudo apt-get update
# For Bionic (18.04 LTS)
sudo apt-get -y install bison build-essential cmake flex git libedit-dev \
libllvm6.0 llvm-6.0-dev libclang-6.0-dev python zlib1g-dev libelf-dev libfl-dev python3-distutils
# For Eoan (19.10) or Focal (20.04.1 LTS)
sudo apt install -y bison build-essential cmake flex git libedit-dev \
libllvm7 llvm-7-dev libclang-7-dev python zlib1g-dev libelf-dev libfl-dev python3-distutils
# For Hirsute (21.04) or Impish (21.10)
sudo apt install -y bison build-essential cmake flex git libedit-dev libllvm11 llvm-11-dev libclang-11-dev python zlib1g-dev libelf-dev libfl-dev python3-distutils
# For other versions
sudo apt-get -y install bison build-essential cmake flex git libedit-dev \
libllvm3.7 llvm-3.7-dev libclang-3.7-dev python zlib1g-dev libelf-dev python3-distutils
# For Lua support
sudo apt-get -y install luajit luajit-5.1-dev
安装和编译bcc
git clone https://github.com/iovisor/bcc.git
mkdir bcc/build; cd bcc/build
cmake .. # 注意使用的llvm环境是哪一个
make
sudo make install
cmake -DPYTHON_CMD=python3 .. # build python3 binding 绑定到python3而不是python2
pushd src/python/
make
# 安装到/usr/lib/python3/dist-packages/下
sudo make install
popd # 返回栈顶目录
3. bpftrace的安装
Ubuntu packages:
sudo apt-get install -y bpftrace
其他环境安装方式见:
https://github.com/iovisor/bpftrace/blob/master/INSTALL.md
四、eBPF实践
4.1 使用BCC工具
1. bcc Python Developer Tutorial
来源:
- https://github.com/iovisor/bcc/blob/master/docs/tutorial_bcc_python_developer.md
lesson1: hello word
#!/usr/bin/python
# Copyright (c) PLUMgrid, Inc.
# Licensed under the Apache License, Version 2.0 (the "License")
# run in project examples directory with:
# sudo ./hello_world.py"
# see trace_fields.py for a longer example
from bcc import BPF
# This may not work for 4.17 on x64, you need replace kprobe__sys_clone with kprobe____x64_sys_clone
BPF(text='int kprobe__sys_clone(void *ctx) { bpf_trace_printk("Hello, World!\\n"); return 0; }').trace_print()
解释:
-
bpf_trace_printk是一个BPF的辅助函数, 其作用是打印输出,由于运行在内核中,所以打印输出并不是标准输出,而是内核调试文件/sys/kernel/debug/tracing/trace_pipe注意:
- 这里用这个辅助函数只是为了快速演示,因为使用有限制:最多3个参数,1个
%s, 此外trace_pipe是全局共享的,所以不建议使用,可能会有并发问题 - 最好使用
BPF_PERF_OUTPUT()
- 这里用这个辅助函数只是为了快速演示,因为使用有限制:最多3个参数,1个
-
kprobe__sys_clone: 使用kprobes探针的快速写法,如果eBPF的C程序以kprobe__开头则其余部分被视为要检测的内核函数名称,在这就是sys_clone -
BPF(text=“xxx”):表示传入要执行的eBPF源代码, 并依托BPF模块编译为字节码 -
trace_print():读取内核文件/sys/kernel/debug/tracing/trace_pipe到标准输出
运行sudo ././helloword.py 或者sudo /usr/bin/python3 ./helloword.py
效果:一旦内核中发生了clone, 就打印Hello World!
输出解释:
systemd-xxx:是进程的名字-PID[001]: 表示CPU编号……:表示一系列选项182.317265:表示时间戳do_sys_open: 表示函数名
lesson2: sys_sync()
Write a program that traces the sys_sync() kernel function. Print "sys_sync() called" when it runs. Test by runningsyncin another session while tracing. The hello_world.py program has everything you need for this.
#!/usr/bin/python3
from bcc import BPF
prog=''' int kprobe__sys_sync(void *ctx) { bpf_trace_printk("sys_sync() called\\n"); return 0; } '''
BPF(text=prog).trace_print()
运行:

lesson3: hello_fields
重点:
- 自己手动插桩(动态插桩),而不是调用封装好的函数
- 利用
bcc封装好的函数获取到被插桩的系统调用名称
#!/usr/bin/python3
from bcc import BPF
prog = ''' int hello(void *ctx) { bpf_trace_printk("hello world\\n"); return 0; } '''
b = BPF(text=prog)
# get_syscall_fnname: 根据输入的名称获取系统调用的全名, For example, given "clone" the helper would return "sys_clone" or "__x64_sys_clone".
b.attach_kprobe(event=b.get_syscall_fnname("clone"), fn_name="hello")
# header
print("%-18s %-16s %-6s %s" % ("TIME(s)", "COMM", "PID", "MESSAGE"))
# 循环获取输出
while(1):
try:
# 从 trace_pipe 返回一组固定的字段。与 trace_print() 类似
(task, pid, cpu, flags, timestamp, msg) = b.trace_fields()
except ValueError:
continue
print("%-18.9f %-16s %-6d %s" % (timestamp, task, pid, msg))
注意点:
-
使用
prog静态变量的方式有利于后面替换字符串实现一些特殊修改 -
hello: 这次创建一个普通的c语言程序名而不是借助kprobe__开头,BPF程序中声明的所有C函数都应在探针上执行,因此它们都需要将pt_reg* ctx作为第一个参数。**如果你需要在
C代码中定义一些不会在探针上执行的辅助函数,则需要将它们定义为静态内联,以便编译器内联。**有时您还需要为其添加_always_inline函数属性。例如:
static inline __attribute__((always_inline)) int my_help(a int) { return 0; }_always_inline会让编译器无论如何都会进行内联编译
-
fn_name="hello":用于指定在插桩处执行我们定义的函数,这里就是hello
输出
lesson4: sync_timing
系统管理员会在系统重启之前在控制台输入三次
sync即sync;sync;sync来实现同步(因为sync是异步的)用途:计算调用
do_sync函数的速度即时间,如果<1s那么打印出来
#!/usr/bin/python3
from bcc import BPF
prog = ''' #include <uapi/linux/ptrace.h> // 创建一个Hash映射数据结构 BPF_HASH(last); int do_trace(struct pt_regs *ctx) { u64 ts, *tsp, delta, key = 0; // 读取当前hash中最新的数据 tsp = last.lookup(&key); // 判断是否需要计算时间差 if (tsp != NULL) { delta = bpf_ktime_get_ns() - *tsp; if (delta < 1000000000) { // 如果<1s,那么输出 bpf_trace_printk("%d\\n", delta / 1000000); } // 删除掉原本的最新数据 last.delete(&key); } // 更新hash,获取当前时间 ts = bpf_ktime_get_ns(); last.update(&key, &ts); return 0; } '''
b = BPF(text=prog)
b.attach_kprobe(event=b.get_syscall_fnname("sync"), fn_name="do_trace")
print("Tracing for quick sync's... Ctrl-C to end")
start = 0
while(1):
try:
(task, pid, cpu, flags, ts, msg) = b.trace_fields()
except ValueError:
continue
if start == 0 :
start = ts
ts = ts - start
print("At time %.2f s: multiple syncs detected, last %s ms ago" % (ts, msg))
重点:
-
BPF_HASH(last): 创建一个hash结构的BPF映射对象, 名字为last, 因为没有指定更多的参数,所以默认是u64的键和值的类型 -
key = 0: 因为只存储一对k/v, 所以这里的key设置为0 -
tsp != NULL: 注意一定要判断从映射中取出的值是否为空再使用它,因为当不存在时就会返回NULL -
last.delete(&key): 删除这个key, This is currently required because of a kernel bug in.update()(fixed in 4.8.10).bug的意思是当使用bpf_map_update_elem()更新映射元素的时候,原本会有一个预分配(pre-allocated)的机制,此时如果满了,那么就会出现问题;这个问题在之后被修复了,但是为了适配更低内核,可能这样写是友好的。
运行:
在另一个中断输入sync;sync;sync
将打印第二个和第三个sync的输出:

lesson5: sync_count
修改
sync_timing.py程序(前一课)以存储所有内核同步系统调用(快速和慢速)的计数,并将其与输出一起打印。这个计数可以通过向现有散列添加一个新的键索引来记录在BPF程序中。
#!/usr/bin/python3
from bcc import BPF
prog = ''' #include <uapi/linux/ptrace.h> // 创建一个array用于计数 BPF_ARRAY(counts, u64, 1); int do_sync(struct pt_regs *ctx) { u64 *now = 0; int index = 0; // +1 counts.increment(index); now = counts.lookup(&index); if (now != NULL) { bpf_trace_printk("%d\\n", *now); } return 0; } '''
b = BPF(text=prog)
b.attach_kprobe(event=b.get_syscall_fnname("sync"), fn_name="do_sync")
while(1):
try:
(task, pid, cpu, flags, ts, msg) = b.trace_fields()
except ValueError:
continue
print("At time %.2f s: count sync is %s\n" % (ts, msg))
重点:
BPF_ARRAY的使用总结:https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md#3-bpf_array
运行:
在另一个终端输入sync;sync;sync
lesson6: disksnoop.py
Browse the examples/tracing/disksnoop.py program to see what is new. Here is some sample output:
# ./disksnoop.py
TIME(s) T BYTES LAT(ms)
16458043.436012 W 4096 3.13
16458043.437326 W 4096 4.44
16458044.126545 R 4096 42.82
16458044.129872 R 4096 3.24
[...]
Code:
[...]
REQ_WRITE = 1 # from include/linux/blk_types.h
# load BPF program
b = BPF(text=""" #include <uapi/linux/ptrace.h> #include <linux/blkdev.h> BPF_HASH(start, struct request *); void trace_start(struct pt_regs *ctx, struct request *req) { // stash start timestamp by request ptr // 获取开始的时间 u64 ts = bpf_ktime_get_ns(); start.update(&req, &ts); } void trace_completion(struct pt_regs *ctx, struct request *req) { u64 *tsp, delta; // 获取之前的时间 tsp = start.lookup(&req); if (tsp != 0) { // 计算时间差值 delta = bpf_ktime_get_ns() - *tsp; bpf_trace_printk("%d %x %d\\n", req->__data_len, req->cmd_flags, delta / 1000); start.delete(&req); } } """)
# 分别对三个系统调用进行插桩
b.attach_kprobe(event="blk_start_request", fn_name="trace_start")
b.attach_kprobe(event="blk_mq_start_request", fn_name="trace_start")
b.attach_kprobe(event="blk_account_io_done", fn_name="trace_completion")
[...]
重点:
REQ_WRITE: 在Python程序中定义了一个内核常量,因为我们稍后会在那里使用它。如果我们在BPF程序中使用 REQ_WRITE,它应该可以与适当的#include 一起工作(无需定义)trace_start(struct pt_regs *ctx, struct request *req): 参数解释,第一个参数是kprobes函数的参数用于寄存器和BPF上下文,其后的参数是event被插桩函数的实际参数;例如我们将其附加到 blk_start_request(),其中第一个参数是struct request *start.update(&req, &ts): 我们使用指向请求结构的指针(*req)作为哈希中的键,这在trace实现中很常见,具体原因在于保证唯一性-两个req结构体不会有相同的指针地址,这里要使用时间戳标记描述记录磁盘IO请求结构,对于此类事件戳的存储,可以用两种键实现:指向结构体的指针或者线程IDreq->__data_len:这样的结构体引用方式其实bcc会将其重写为bpf_probe_read_kernel(), 如果有一些复杂的引用bcc无法理解(重写),那么需要直接使用bpf_probe_read_kernel()
lesson7: hello_perf_output
目标:不再使用bpf_trace_printk()而使用BPF_PERF_OUTPUT(),这也意味着我们将停止使用 trace_field() 获取成员,如 PID 和时间戳,我们需要直接获取它们。
code:
#!/usr/bin/python3
from multiprocessing import Event
from bcc import BPF
prog = ''' #include <linux/sched.h> // 自定义输出类型 struct data_t { u32 pid; u64 ts; char comm[TASK_COMM_LEN]; }; // 创建perf输出通道,名为event BPF_PERF_OUTPUT(events); int hello(struct pt_regs *ctx) { // 创建对象,借助辅助函数填充数据 struct data_t data = {}; data.pid = bpf_get_current_pid_tgid(); data.ts = bpf_ktime_get_ns(); bpf_get_current_comm(&data.comm, sizeof(data.comm)); // 发送到通道中(给用户态空间) events.perf_submit(ctx, &data, sizeof(data)); return 0; } '''
b = BPF(text=prog)
b.attach_kprobe(event=b.get_syscall_fnname("clone"), fn_name="hello")
# header
print("%-18s %-16s %-6s %s" % ("TIME(s)", "COMM", "PID", "MESSAGE"))
start = 0
# 该函数将处理从事件流中读取事件
def print_event(cpu, data, size):
global start
# 将事件作为 Python 对象获取,从 C 声明中自动生成。
event = b["events"].event(data)
if start == 0:
start = event.ts
time_s = (float(event.ts - start)) / 1000000000
print("%-18.9f %-16s %-6d %s" % (time_s, event.comm, event.pid, "Hello, perf_output!"))
# 设置回调函数
b["events"].open_perf_buffer(print_event)
while 1:
# 阻塞等待事件
b.perf_buffer_poll()
注意点:
struct data_t: 定义了我们传递到用户空间的c结构体bpf_get_current_pid_tgid(): 返回低32位的进程ID(在内核的PID视图中,如果在用户空间中通常表示为线程ID),以及高32位的线程组ID(单进程下的多个线程的此ID是相同的,用户空间通常认为的PID); 通过直接将其设置为u32,我们丢弃了高32位即获取内核进程ID
运行:
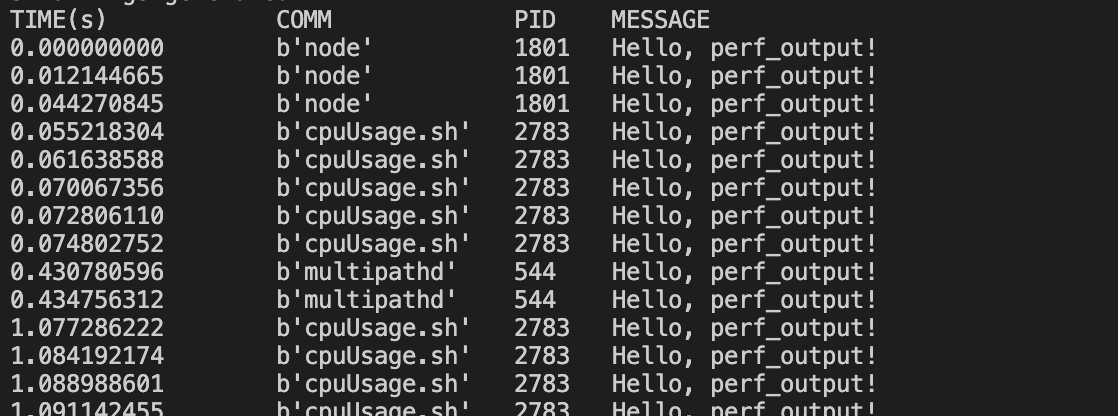
lesson9: bitehist.py
The following tool records a histogram of disk I/O sizes.
code:
#!/usr/bin/python3
from __future__ import print_function
from bcc import BPF
from time import sleep
prog = ''' #include <uapi/linux/ptrace.h> #include <linux/blkdev.h> BPF_HISTOGRAM(dist); int kprobe__blk_account_io_done(struct pt_regs *ctx, struct request *req) { dist.increment(bpf_log2l(req->__data_len / 1024)); return 0; } '''
b = BPF(text=prog)
# header
print("Tracing... Hit Ctrl-C to end.")
# trace until Ctrl-C
try:
sleep(999999)
except KeyboardInterrupt:
print()
# output
b["dist"].print_log2_hist("kbytes")
重点:
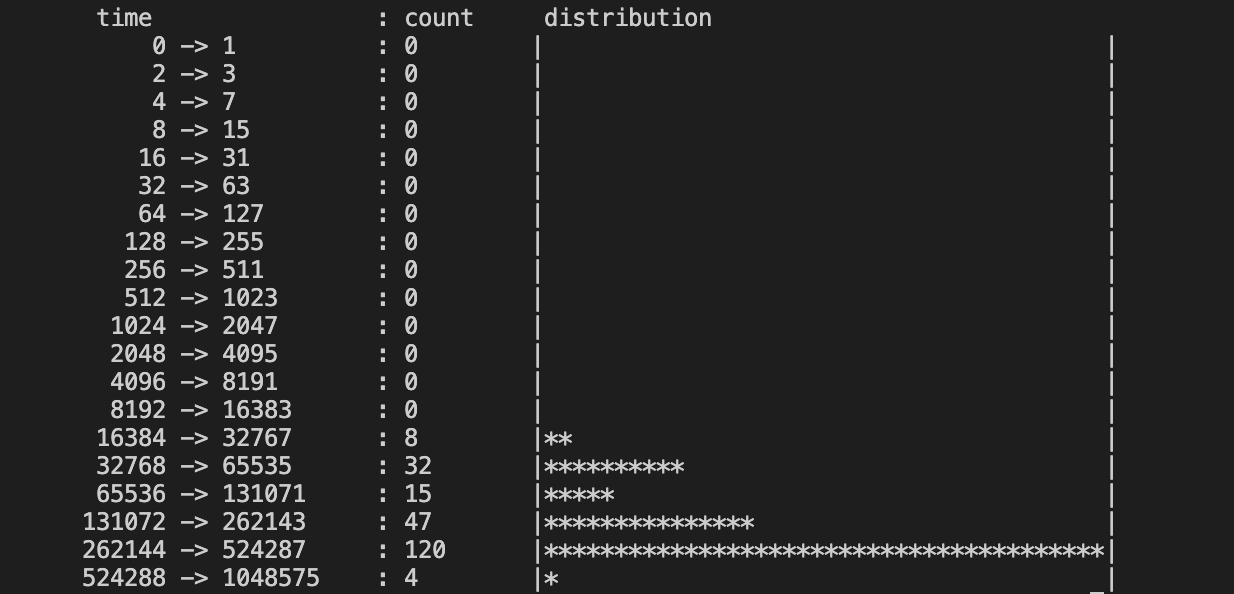
from __future__ import print_function: 在开头加上from __future__ import print_function这句之后,即使在python2.X,使用print就得像python3.X那样加括号使用BPF_HISTOGRAM(dist): 定义一个直方图的BPF映射对象,并将其命名为“dist”dist.increment(): 将作为第一个参数提供的直方图存储桶索引数量递增一个bpf_log2l(): 返回所提供值的log2。这成为我们直方图的索引,因此我们正在构建一个2的幂直方图b["dist"].print_log2_hist("kbytes"): 将“dist”直方图打印为2的幂,列标题为“kbytes”。从内核传输到用户空间的唯一数据是桶数,这使得这很有效。
lesson10: disklatency.py
Write a program that times disk I/O, and prints a histogram of their latency.
code:
#!/usr/bin/python3
from bcc import BPF
from time import sleep
prog = ''' #include <uapi/linux/ptrace.h> #include <linux/blkdev.h> BPF_HISTOGRAM(dist); // 统计直方图 BPF_HASH(start, struct request *); // 记录延迟时间 void trace_start(struct pt_regs *ctx, struct request *req) { u64 ts = bpf_ktime_get_ns(); start.update(&req, &ts); } void trace_completion(struct pt_regs *ctx, struct request *req) { u64 *tsp, delta; tsp = start.lookup(&req); if (tsp != 0) { delta = bpf_ktime_get_ns() - *tsp; // 写入到直方图中 dist.increment(bpf_log2l(delta)); start.delete(&req); } } '''
b = BPF(text=prog)
if BPF.get_kprobe_functions(b'blk_start_request'): # 这里先判断一下是否有此函数
b.attach_kprobe(event="blk_start_request", fn_name="trace_start")
b.attach_kprobe(event="blk_mq_start_request", fn_name="trace_start")
if BPF.get_kprobe_functions(b'__blk_account_io_done'):
b.attach_kprobe(event="__blk_account_io_done", fn_name="trace_completion")
else:
b.attach_kprobe(event="blk_account_io_done", fn_name="trace_completion")
# header
print("Tracing... Hit Ctrl-C to end.")
# trace until Ctrl-C
try:
sleep(999999)
except KeyboardInterrupt:
print()
# output
b["dist"].print_log2_hist("time")
输出:
lesson11: vfsreadlat.py
Browse the code in examples/tracing/vfsreadlat.py and examples/tracing/vfsreadlat.c. Things to learn:
重点:
b = BPF(src_file = "vfsreadlat.c"): 可以用此参数将c语言代码和python分开b.attach_kretprobe(event="vfs_read", fn_name="do_return"): 将BPF C函数do_return()附加到内核函数vfs_read()的返回。这是一个kretprobe:检测函数的返回,而不是它的入口b["dist"].clear(): 清除histogram.
lesson12: urandomread.py
目标:学习使用TRACEPOINT_PROBE
code:
from __future__ import print_function
from bcc import BPF
# load BPF program
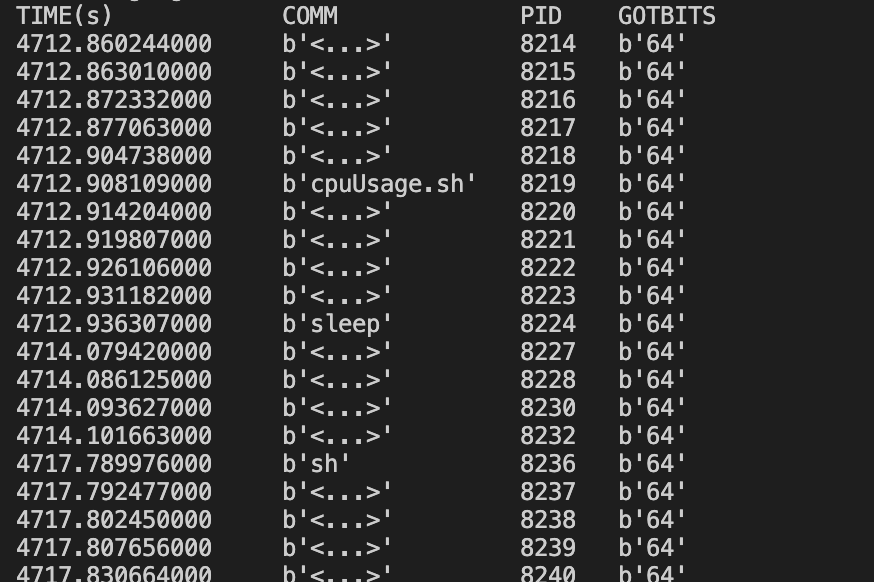
b = BPF(text=""" TRACEPOINT_PROBE(random, urandom_read) { // args is from /sys/kernel/debug/tracing/events/random/urandom_read/format bpf_trace_printk("%d\\n", args->got_bits); return 0; } """)
# header
print("%-18s %-16s %-6s %s" % ("TIME(s)", "COMM", "PID", "GOTBITS"))
# format output
while 1:
try:
(task, pid, cpu, flags, ts, msg) = b.trace_fields()
except ValueError:
continue
print("%-18.9f %-16s %-6d %s" % (ts, task, pid, msg))
重点:
-
TRACEPOINT_PROBE(random, urandom_read): 检测内核跟踪点random:urandom_read。它们具有稳定的API,因此建议尽可能使用而不是kprobes。您可以运行perf list以获取跟踪点列表。Linux >= 4.7需要将BPF程序附加到跟踪点 -
args->got_bits:args自动填充为跟踪点参数的结构, 这个参数可以从/sys/kernel/debug/tracing/events/random/urandom_read/format中看到: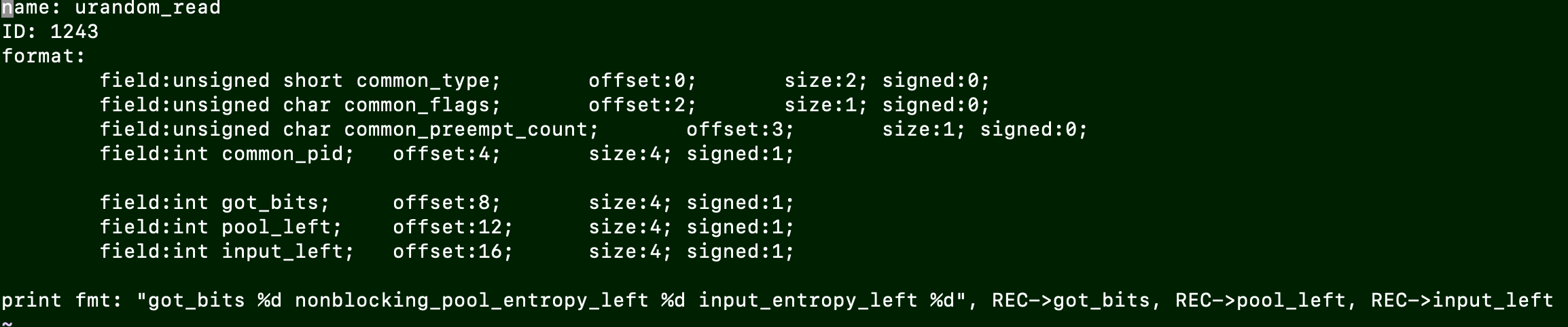
输出:
Lesson13:disksnoop.py fixed
Convert disksnoop.py from a previous lesson to use the
block:block_rq_issueandblock:block_rq_completetracepoints.
#!/usr/bin/python3
from __future__ import print_function
from bcc import BPF
from bcc.utils import printb
REQ_WRITE = 1 # from include/linux/blk_types.h
# load BPF program
b = BPF(text=''' #include <uapi/linux/ptrace.h> #include <linux/blk-mq.h> struct data_t { u64 len; // 大小 char rwbs[8]; // 类型 u64 ts; // 时间戳 }; BPF_HASH(start, u64, struct data_t); TRACEPOINT_PROBE(block, block_rq_issue) { u64 key = 0; struct data_t data = {}; data.ts = bpf_ktime_get_ns(); // args from /sys/kernel/debug/tracing/events/block/block_rq_issue/format bpf_probe_read(&data.rwbs, sizeof(data.rwbs), (void *)args->rwbs); data.len = args->bytes; // 更新存储 start.update(&key, &data); return 0; } TRACEPOINT_PROBE(block, block_rq_complete) { u64 delta, key = 0; struct data_t* datap; datap = start.lookup(&key); if (datap != NULL) { // 计算时间差 delta = bpf_ktime_get_ns() - datap->ts; bpf_trace_printk("%d %x %d\\n", datap->len, datap->rwbs, delta / 1000); start.delete(&key); } return 0; } ''')
# header
print("%-18s %-2s %-7s %8s" % ("TIME(s)", "T", "BYTES", "LAT(ms)"))
# format output
while 1:
try:
(task, pid, cpu, flags, ts, msg) = b.trace_fields()
(bytes_s, bflags_s, us_s) = msg.split()
if int(bflags_s, 16) & REQ_WRITE:
type_s = b"W"
elif bytes_s == "0": # see blk_fill_rwbs() for logic
type_s = b"M"
else:
type_s = b"R"
ms = float(int(us_s, 10)) / 1000
printb(b"%-18.9f %-2s %-7s %8.2f" % (ts, type_s, bytes_s, ms))
except KeyboardInterrupt:
exit()
运行:
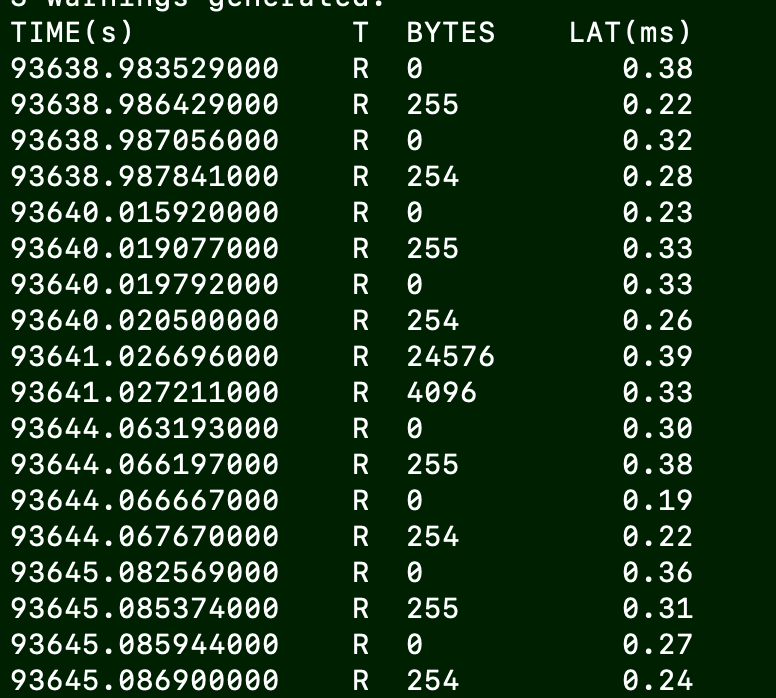
两个format文件分别在:
/sys/kernel/debug/tracing/events/block/block_rq_issue/format/sys/kernel/debug/tracing/events/block/block_rq_complete/format
lesson14: strlen_count.py
该程序检测用户级函数strlen()库函数,并对其字符串参数进行频率计数。示例输出:
code:
# ./strlen_count.py
Tracing strlen()... Hit Ctrl-C to end.
^C COUNT STRING
1 " "
1 "/bin/ls"
1 "."
1 "cpudist.py.1"
1 ".bashrc"
1 "ls --color=auto"
1 "key_t"
[...]
10 "a7:~# "
10 "/root"
12 "LC_ALL"
12 "en_US.UTF-8"
13 "en_US.UTF-8"
20 "~"
70 "#%^,~:-=?+/}"
340 "\x01\x1b]0;root@bgregg-test: ~\x07\x02root@bgregg-test:~# "
这些是此库函数在跟踪时正在处理的各种字符串,以及它们的频率计数。例如,strlen() 在“LC_ALL”上被调用了 12 次
Code is examples/tracing/strlen_count.py:
from __future__ import print_function
from bcc import BPF
from time import sleep
# load BPF program
b = BPF(text=""" #include <uapi/linux/ptrace.h> struct key_t { char c[80]; }; BPF_HASH(counts, struct key_t); int count(struct pt_regs *ctx) { if (!PT_REGS_PARM1(ctx)) return 0; struct key_t key = {}; u64 zero = 0, *val; bpf_probe_read_user(&key.c, sizeof(key.c), (void *)PT_REGS_PARM1(ctx)); // could also use `counts.increment(key)` val = counts.lookup_or_try_init(&key, &zero); if (val) { (*val)++; } return 0; }; """)
b.attach_uprobe(name="c", sym="strlen", fn_name="count")
# header
print("Tracing strlen()... Hit Ctrl-C to end.")
# sleep until Ctrl-C
try:
sleep(99999999)
except KeyboardInterrupt:
pass
# print output
print("%10s %s" % ("COUNT", "STRING"))
counts = b.get_table("counts")
for k, v in sorted(counts.items(), key=lambda counts: counts[1].value):
print("%10d \"%s\"" % (v.value, k.c))
重点:
PT_REGS_PARM1(ctx): 获取strlen()的第一个参数,即字符串b.attach_uprobe(name="c", sym="strlen", fn_name="count"): 附加到库c(如果这是主程序,使用它的路径名),检测用户级函数strlen(),并在执行时调用我们的C函数count()
lesson 15. nodejs_http_server.py
Relevant code from examples/tracing/nodejs_http_server.py:
from __future__ import print_function
from bcc import BPF, USDT
import sys
if len(sys.argv) < 2:
print("USAGE: nodejs_http_server PID")
exit()
pid = sys.argv[1]
debug = 0
# load BPF program
bpf_text = """ #include <uapi/linux/ptrace.h> int do_trace(struct pt_regs *ctx) { uint64_t addr; char path[128]={0}; bpf_usdt_readarg(6, ctx, &addr); bpf_probe_read_user(&path, sizeof(path), (void *)addr); bpf_trace_printk("path:%s\\n", path); return 0; }; """
# enable USDT probe from given PID
u = USDT(pid=int(pid))
# 开启用户态跟踪点
u.enable_probe(probe="http__server__request", fn_name="do_trace")
if debug:
print(u.get_text())
print(bpf_text)
# initialize BPF
b = BPF(text=bpf_text, usdt_contexts=[u])
重点:
bpf_usdt_readarg(6, ctx, &addr): 将USDT探针中参数6的地址读入addrbpf_probe_read_user(&path, sizeof(path), (void *)addr): 将字符串addr指向路径变量path,u = USDT(pid=int(pid)):为给定的PID初始化USDT跟踪。u.enable_probe(probe="http__server__request", fn_name="do_trace"): 将我们的do_trace()BPF C函数附加到Node.jshttp__server__requestUSDT探针b = BPF(text=bpf_text, usdt_contexts=[u]): 需要传入我们的USDT对象u来创建BPF对象
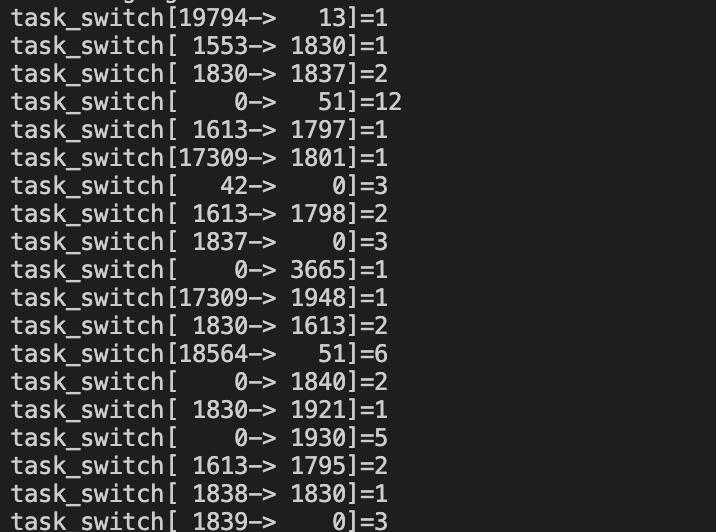
lesson 16. task_switch.c
目标:新旧BPF程序传递参数
内核中的每个任务更改都会调用该程序,并在 BPF 映射中记录新旧 pid。
下面的 C 程序引入了一个新概念:prev 参数。此参数由 BCC 前端特殊处理,以便从 kprobe 基础结构传递的已保存上下文中读取对该变量的访问。从位置1开始的args原型应该与被kprobed的内核函数的原型相匹配。如果这样做,程序将无缝访问函数参数
#include <uapi/linux/ptrace.h>
#include <linux/sched.h>
struct key_t {
u32 prev_pid;
u32 curr_pid;
};
BPF_HASH(stats, struct key_t, u64, 1024);
int count_sched(struct pt_regs *ctx, struct task_struct *prev) {
struct key_t key = {
};
u64 zero = 0, *val;
key.curr_pid = bpf_get_current_pid_tgid();
key.prev_pid = prev->pid; // 从之前的上下文中获取pid
// could also use `stats.increment(key);`
val = stats.lookup_or_try_init(&key, &zero);
if (val) {
(*val)++;
}
return 0;
}
用户空间组件加载上面显示的文件,并将其附加到 finish_task_switch 内核函数, BPF 对象的[]操作符提供对程序中每个 BPF_HASH 的访问权限,允许对驻留在内核中的值进行直通访问。像使用任何其他 python dict 对象一样使用该对象:读取、更新和删除都是允许的。
from bcc import BPF
from time import sleep
b = BPF(src_file="task_switch.c")
b.attach_kprobe(event_re="^finish_task_switch$|^finish_task_switch\.isra\.\d$", fn_name="count_sched")
# generate many schedule events
for i in range(0, 100): sleep(0.01)
for k, v in b["stats"].items():
print("task_switch[%5d->%5d]=%u" % (k.prev_pid, k.curr_pid, v.value))
重点:
- 这里使用正则表达式插桩事件,具体原因见:https://github.com/iovisor/bcc/issues/3293
运行效果:
2. 极客时间习题
1. python + C ebpf 监控打开文件
注意,此Demo需要内核
5.6以上
编写代码hello.c
int hello_world(void *ctx)
{
bpf_trace_printk("Hello, World!\n");
return 0;
}
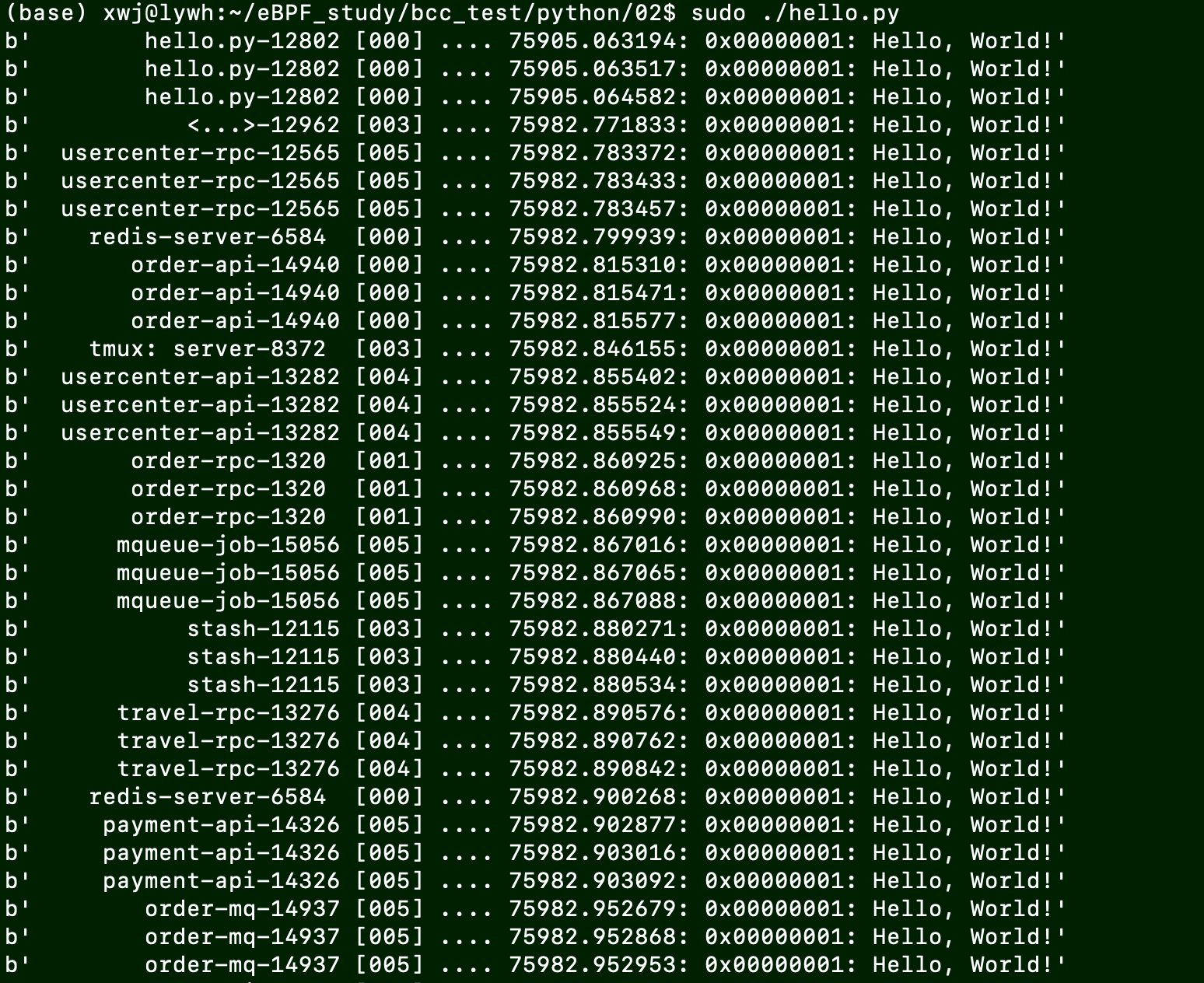
编写代码hello.py
#!/usr/bin/python3
# 1) import bcc library
from bcc import BPF
# 2) load BPF program
b = BPF(src_file="hello.c")
# 3) attach kprobe
b.attach_kprobe(event="do_sys_openat2", fn_name="hello_world")
# 4) read and print /sys/kernel/debug/tracing/trace_pipe
b.trace_print()
测试:
输出的问题:
- 可能不需要某些输出,例如CPU编号等
- 输出格式不够灵活
- 所有的
eBPF程序都会输出到trace_pipe文件,比较混乱
2. 改进程序:使用BPF映射Map
注意,此Demo需要内核
5.6以上
为了解决输出凌乱的问题,我们借助map映射来交互
BCC为了简化和BPF的交互,定义了一系列的库函数和辅助宏定义
比如可以使用BPF_PERF_OUTPUT定义一个Perf事件类型的BPF映射map
https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md#2-bpf_perf_output
// 包含头文件
#include <uapi/linux/openat2.h>
#include <linux/sched.h>
// 定义数据结构
struct data_t {
u32 pid;
u64 ts;
char comm[TASK_COMM_LEN];
char fname[NAME_MAX];
};
// 定义性能事件映射map
BPF_PERF_OUTPUT(events);
然后在eBPF程序中,填充这个数据结构,并调用perf_submit()提交到刚刚定义的性能映射中
// 定义kprobe处理函数
int hello_world(struct pt_regs *ctx, int dfd, const char __user * filename, struct open_how *how)
{
struct data_t data = {
};
// 获取PID和时间
data.pid = bpf_get_current_pid_tgid();
data.ts = bpf_ktime_get_ns();
// 获取进程名
if (bpf_get_current_comm(&data.comm, sizeof(data.comm)) == 0)
{
bpf_probe_read(&data.fname, sizeof(data.fname), (void *)filename);
}
// 提交性能事件
events.perf_submit(ctx, &data, sizeof(data));
return 0;
}
以bpf开头的都是BPF提供的辅助函数,如:
bpf_get_current_pid_tgid: 用于获取进程的pid和tgid(线程组ID,同一个进程下的所有线程都是同一个tgid),该函数返回一个64位的uint值,高32位为线程组tgid,低32为进程的pidbpf_ktime_get_ns: 获取系统从启动以来执行的时间, 单位纳秒bpf_get_current_comm: 获取进程名,并将进程名复制到预定义的缓冲区中bpf_probe_read: 从指定指针处读取固定大小的数据,这里用于读取进程打开的文件名如果理解
hello_world函数的入参?
struct pt_regs *ctx: bcc默认的参数int dfd, const char __user * filename, struct open_how *how:这些参数都是openat2函数的参数所以,编写
eBPF程序的时候都可以在ctx后加入对应系统调用接口的入参即可,在eBPF执行的时候会自动进行参数绑定为什么
data_t的c结构体最后会在python中读取为python对象, 此过程透明?
perf_submit传入的c对象/结构会通过event方法自动转换为python对象(bcc脚本的功劳)
然后在用户态程序借助该map对应的辅助函数open_perf_buffer(),向其中传入一个回调函数处理从perf事件类型的BPF映射中读取到的数据:
from bcc import BPF
# 1) load BPF program
b = BPF(src_file="trace-open.c")
b.attach_kprobe(event="do_sys_openat2", fn_name="hello_world")
# 2) print header
print("%-18s %-16s %-6s %-16s" % ("TIME(s)", "COMM", "PID", "FILE"))
# 3) define the callback for perf event
start = 0
def print_event(cpu, data, size): # cpu, data, size 三个参数都是bbc框架默认使用的
global start
event = b["events"].event(data)
if start == 0:
start = event.ts
time_s = (float(event.ts - start)) / 1000000000
print("%-18.9f %-16s %-6d %-16s" % (time_s, event.comm, event.pid, event.fname))
# 4) loop with callback to print_event
# 定义一个events的Perf事件映射,然后循环读取
b["events"].open_perf_buffer(print_event) # 传入回调函数jie
while 1:
try:
b.perf_buffer_poll()
except KeyboardInterrupt:
exit()
注意:
events要和eBPF程序匹配,只是一个自定义的map名字
perf_buffer_poll是不是一个非阻塞函数?
- 其作用就是对所有的
perf缓冲区buff调用回调函数,然后结束,所以外层要用一个for循环
执行结果:
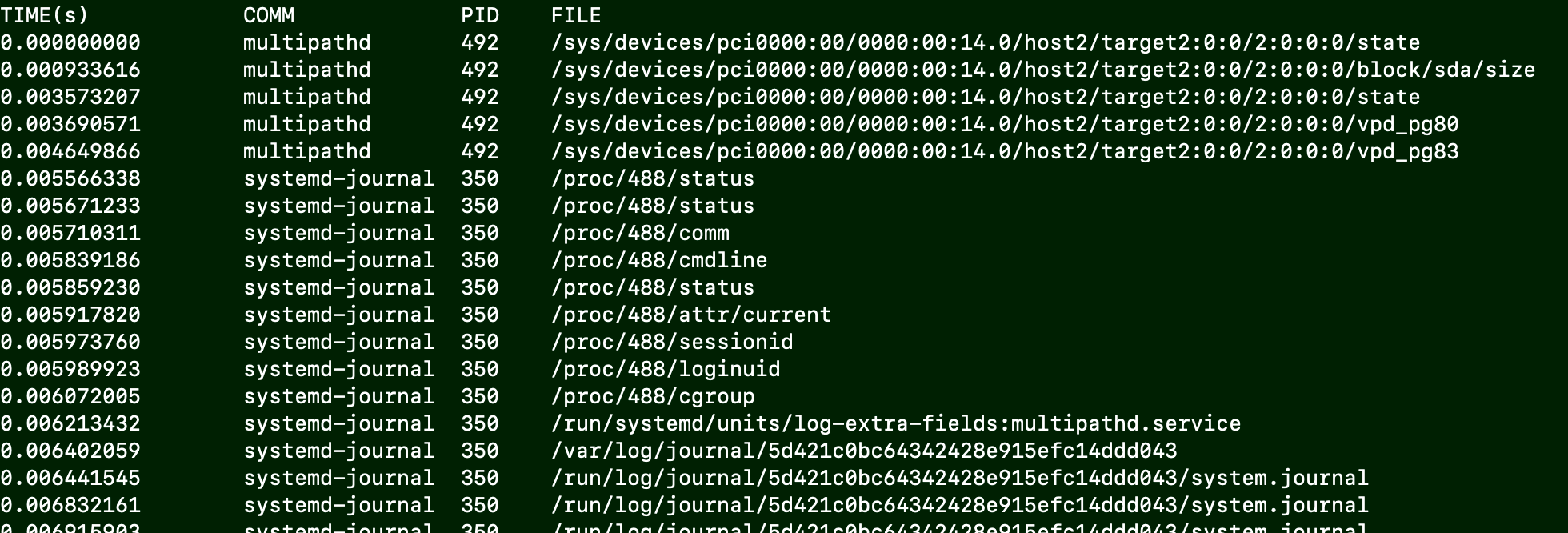
结果较为清晰
流程总结:
- 在
eBPF程序中定义要捕获的对象结构 - 定义
kprobe处理函数,通过bpf提供的辅助函数获取必要信息填充对象结构 - 将填充好的对象结构放入/提交到
map中存储(给用户态程序获取做准备) - 用户态程序通过在
open_perf_buffer传入回调函数并编写逻辑,处理从缓冲区中读取的map中的对象
4.2 linux内核源码自带样例
1. 环境准备
需要先下载对应自己linux内核对应版本的源代码,我这里采用apt仓库维护的方式自己下载(其他方式见:https://davidlovezoe.club/wordpress/archives/988)
# 先搜索
sudo apt-cache search linux-source
linux-source - Linux kernel source with Ubuntu patches
linux-source-4.15.0 - Linux kernel source for version 4.15.0 with Ubuntu patches
linux-source-4.18.0 - Linux kernel source for version 4.18.0 with Ubuntu patches
linux-source-5.0.0 - Linux kernel source for version 5.0.0 with Ubuntu patches
linux-source-5.3.0 - Linux kernel source for version 5.3.0 with Ubuntu patches
# 再安装
sudo apt install linux-source-4.15.0
cd /usr/src/linux-source-4.15.0
sudo tar xjf linux-source-4.15.0.tar.bz2
cd linux-source-4.15.0/
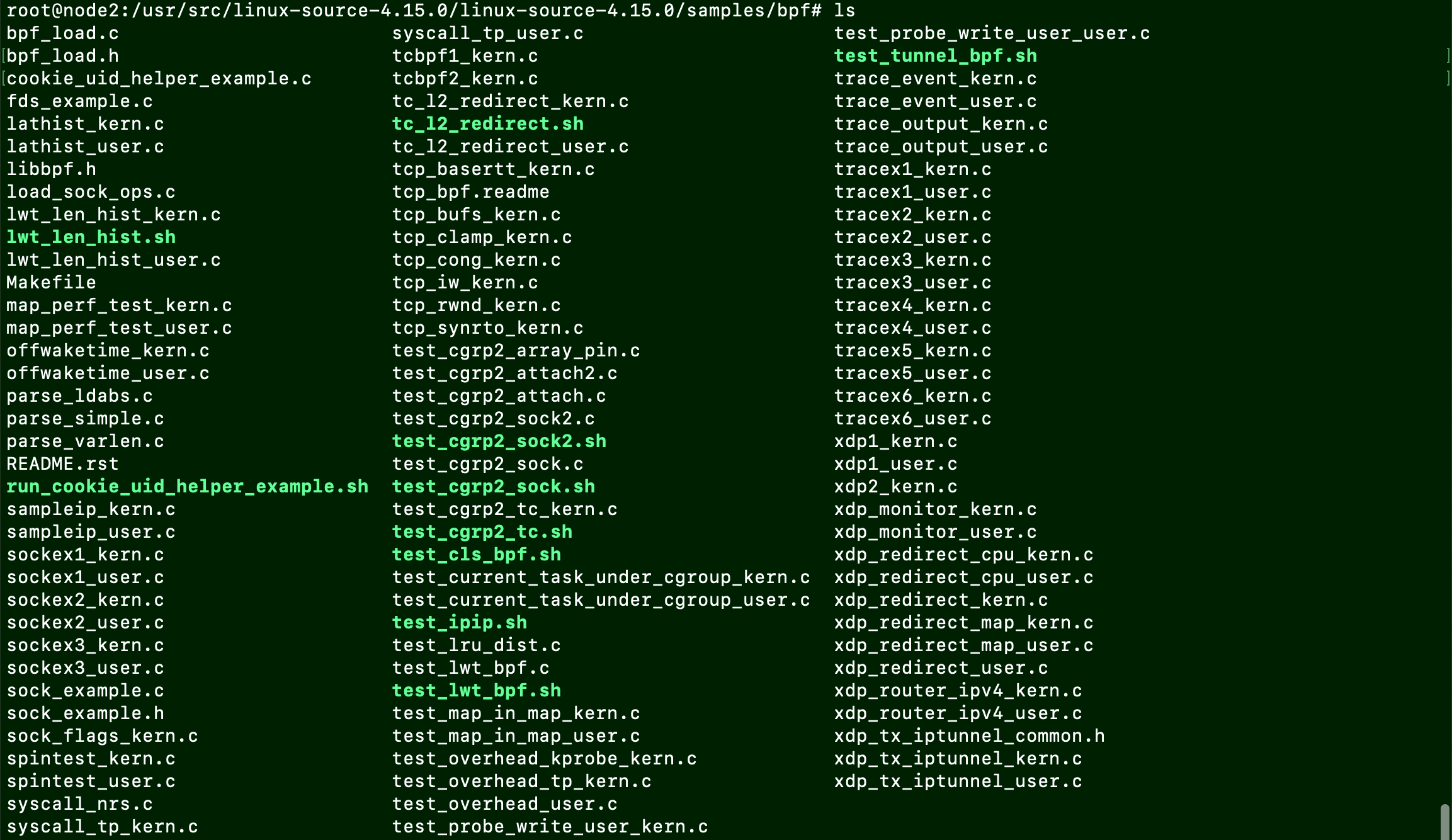
内核中所有的样例就在<根目录>/samples/bpf
2. 开始编译
在真正开始编译工作之前,请确保你的实验环境已经安装
clang和llvm
clang >= version 3.4.0llvm >= version 3.7.1
所谓编译其实就是利用Makefile中写好的命令安装
# 切换到内核源代码根目录
cd linux_sourcecode/
# 生成内核编译时需要的头文件
sudo make headers_install
# 可视化选择你想为内核添加的内核模块,最终生成保存了相关模块信息的.config文件,为执行后面的命令做准备
sudo make menuconfig
# 使用make命令编译samples/bpf/目录下所有bpf示例代码,注意需要加上最后的/符号
sudo make samples/bpf/ # or make M=samples/bpf
3. 执行测试
编译完成的所有样例都可以直接执行尝试:

4.3 gobpf库工具的使用
参考官方样例
bash_line.go:
- https://github.com/iovisor/gobpf/blob/master/examples/bcc/bash_readline/bash_readline.go
1. go bash readline 监控所有/bin/bash命令使用
核心要使用的包就是github.com/iovisor/gobpf/bcc
安装依赖
go get -u "github.com/iovisor/gobpf/bcc"
go get -u "github.com/iovisor/gobpf/pkg/tracepipe"
bash_readline.go
package main
import (
"bytes"
"encoding/binary"
"fmt"
bpf "github.com/iovisor/gobpf/bcc"
"os"
"os/signal"
)
const source string = ` #include <uapi/linux/ptrace.h> struct readline_event_t { u32 pid; char str[80]; } __attribute__((packed)); BPF_PERF_OUTPUT(readline_events); int get_return_value(struct pt_regs *ctx) { struct readline_event_t event = {}; u32 pid; if (!PT_REGS_RC(ctx)) return 0; pid = bpf_get_current_pid_tgid(); event.pid = pid; bpf_probe_read(&event.str, sizeof(event.str), (void *)PT_REGS_RC(ctx)); readline_events.perf_submit(ctx, &event, sizeof(event)); return 0; } `
type readlineEvent struct {
Pid uint32 // 进程号
Str [80]byte // 命令内容
}
func main() {
m := bpf.NewModule(source, []string{
})
defer m.Close()
readlineUretprobe, err := m.LoadUprobe("get_return_value")
if err != nil {
fmt.Fprintf(os.Stderr, "Failed to load get_return_value: %s\n", err)
os.Exit(1)
}
// 埋点在/bin/bash上,最后一个参数是pid,-1表示所有进程
m.AttachUretprobe("/bin/bash", "readline", readlineUretprobe, -1)
if err != nil {
fmt.Fprintf(os.Stderr, "Failed to attach return_value: %s\n", err)
os.Exit(1)
}
// 创建一个BPF table
table := bpf.NewTable(m.TableId("readline_events"), m)
// 接收数据的channel
channel := make(chan []byte)
// 使用table、channel初始化Perf Map
perfMap, err := bpf.InitPerfMap(table, channel, nil)
if err != nil {
fmt.Fprintf(os.Stderr, "Failed to init perf map: %s\n", err)
os.Exit(1)
}
// 创建接收信号的channel
signalChan := make(chan os.Signal, 1)
signal.Notify(signalChan, os.Interrupt, os.Kill) // 接收这些信号
fmt.Printf("%10s\t%s\n", "PID", "COMMAND")
// 协程读取数据并输出
go func() {
var event readlineEvent
for {
data := <-channel
err := binary.Read(bytes.NewBuffer(data), binary.LittleEndian, &event)
if err != nil {
fmt.Printf("failed to decode received data: %s\n", err)
continue
}
// Convert C string (null-terminated) to Go string
comm := string(event.Str[:bytes.IndexByte(event.Str[:], 0)])
fmt.Printf("%10d\t%s\n", event.Pid, comm)
}
}()
// Start to poll the perf map reader and send back event data
perfMap.Start()
<-signalChan
perfMap.Stop()
}
运行sudo -E go run read_line.go
再启动一个终端,输入一些命令,此程序就可以识别到对应的输出:

4.4 bpftool调试工具的使用
要求:Linux内核 > 4.15
此工具源代码位置:tools/bpf/bpftool
作用:展示/查看已经加载的BPF程序并打印它们的指令
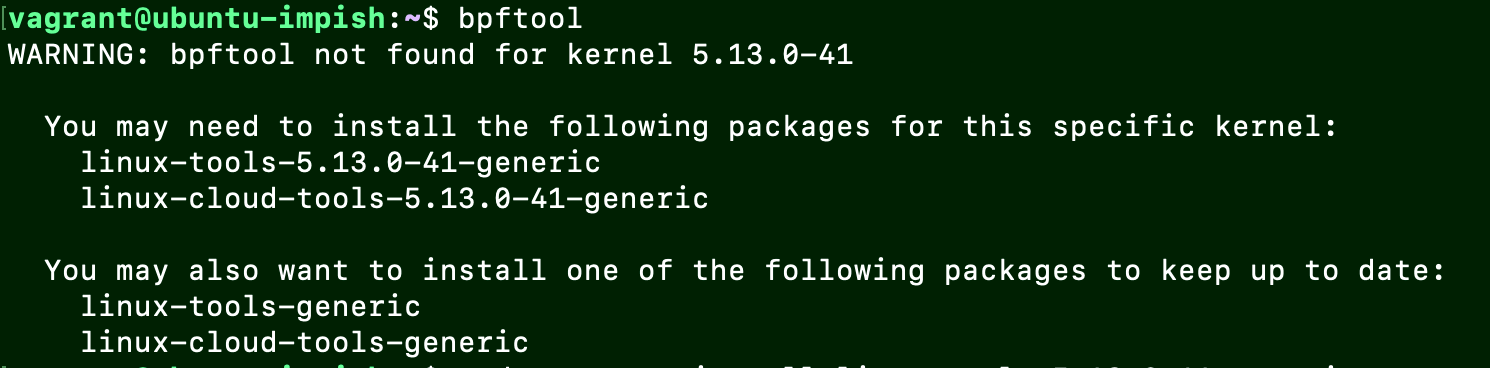
如果没有此工具的话可能要对应内核安装一下:
使用

对于每一类对象,使用
bpftool <对象名> help即可看到详细使用说明
常用命令:
-
sudo bpftool perf: 查看哪些ebpf程序在用perf_event_open()进行挂载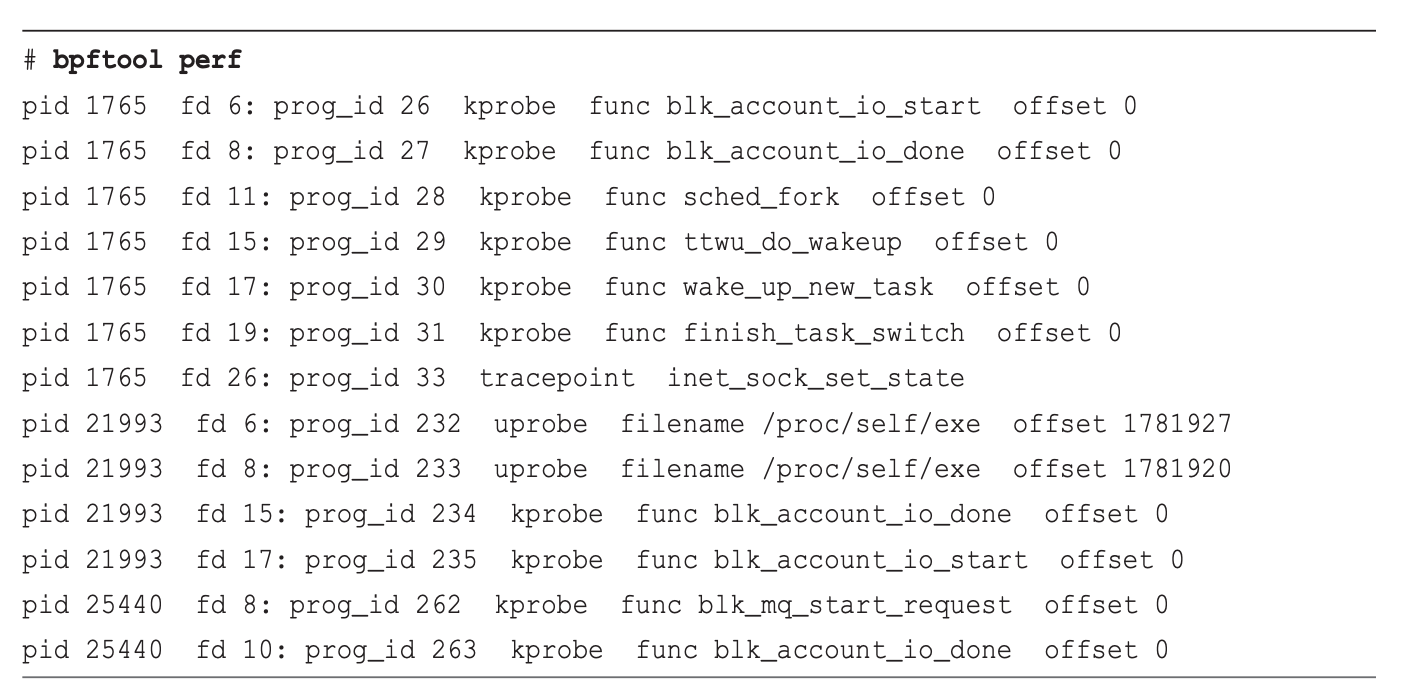
offset: 二进制文件中被插桩对象/函数的偏移量, 可以使用readelf -s bpftrace来验证prog_id:BPF程序的ID -
sudo bpftool prog show: 显示所有加载的BPF程序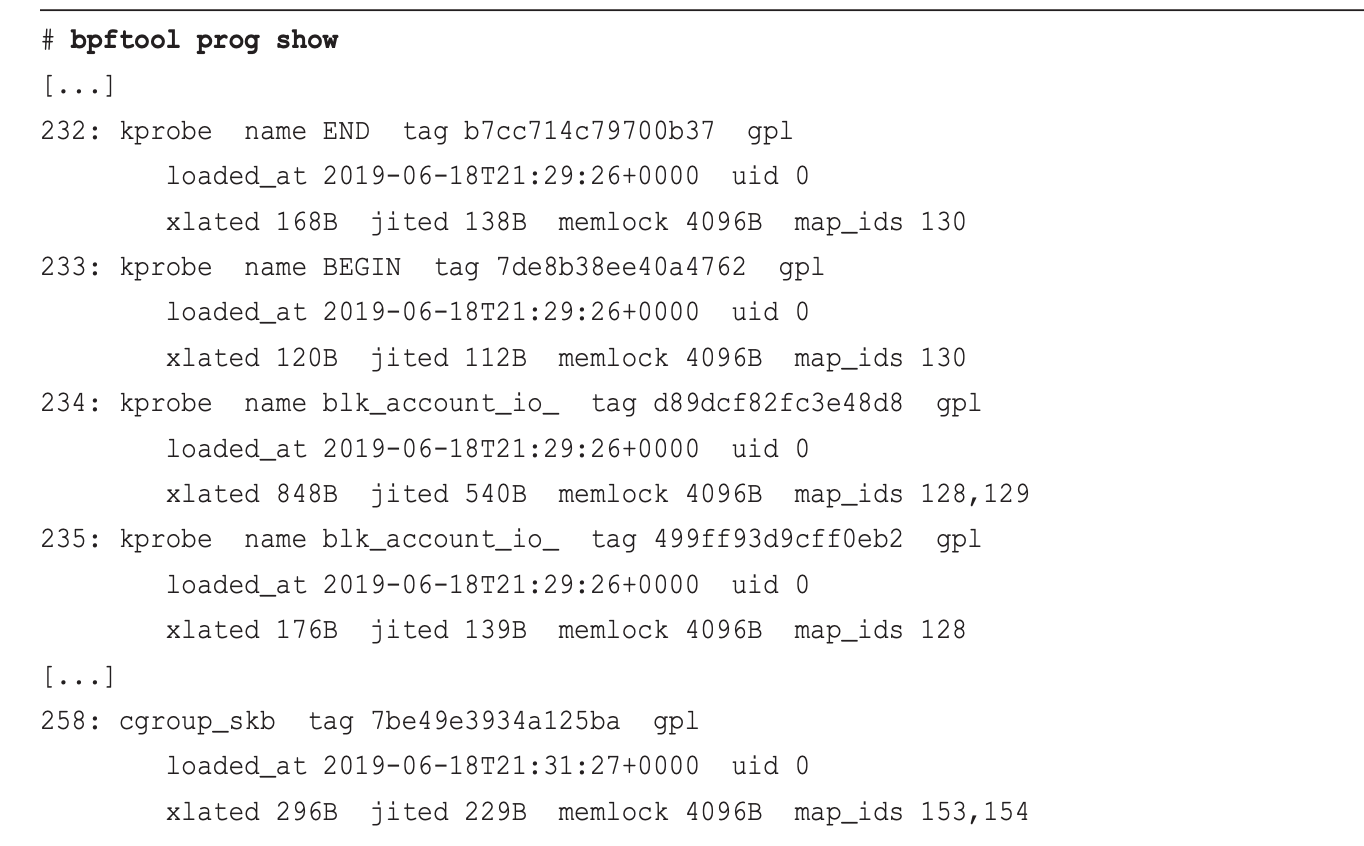
-
sudo bpftool prog dump xlated id <prog_id>: 将某个id的BPF程序指令转换为汇编指令打印出来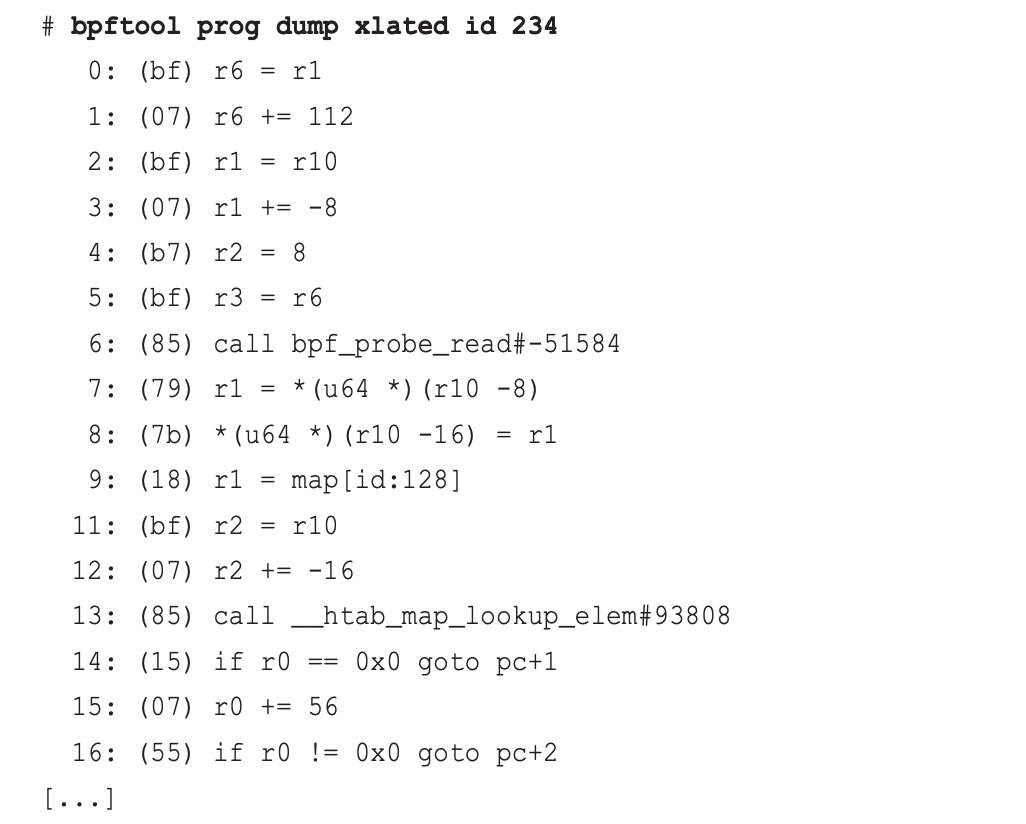
如果基于
BTF编译, 那么输出会包含从BTF中获取的源代码信息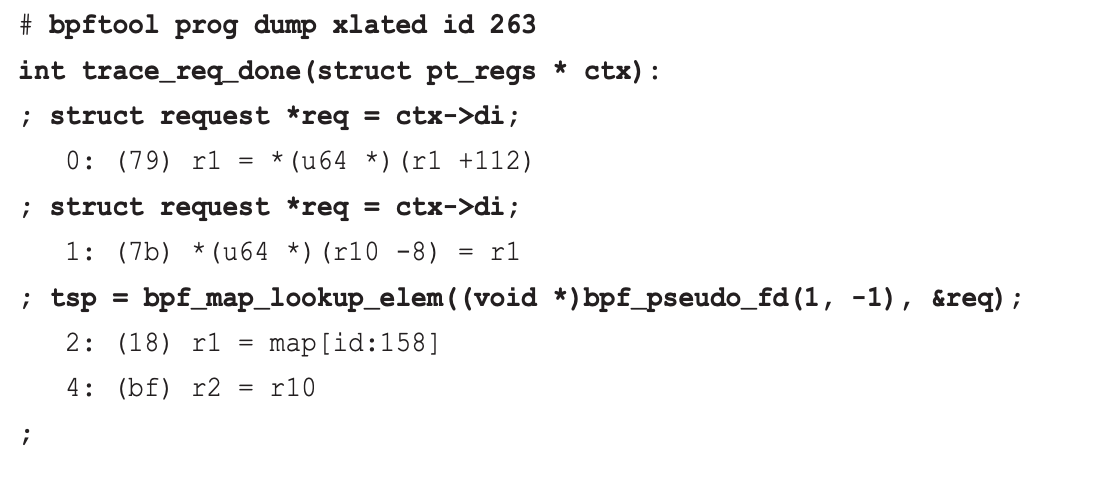
加上
linum会显示源代码文件和行信息;加上opcode会输出包含BPF指令的opcode;加上修饰符visual可以以DOT格式输出控制流信息指出外部可视化软件打开; -
bpftool prog dump jited id <prog_id>: 显示经过JIT编译之后的机器码
-
bpftool btf dump id 5: 可以打印BTF的ID
4.5 bpftrace工具的使用
定位: bpftrace适合创造单行程序和短小脚本进行观测,而BCC则适合编写复杂的工具和守护进程
自己编写一个bpftrace程序
#!/usr/bin/bpftrace
kprobe:vfs_read
{
@start[tid] = nsecs;
}
kretprobe:vfs_read
/@start[tid]/
{
$duration_us = (nsecs - @start[tid]) / 1000;
@us = hist($duration_us);
delete(@start[tid]);
}
基本解释:
bpftrace程序的运行方式有两种:
bpftrace -e xxx: 用于运行单行程序bpftrace file.bt: 用于运行编写好的程序文件,这里上面的第一行就指定了解释器,所以可以添加执行权限后,直接运行此文件,上面就是一个标准的bt程序
bpftrace程序的结构是一系列探针+对应的动作:
probes {
actions }
probes /filter/ {
actions } # 防止可选的过滤表达式
@start[]是一个全局hash映射表(@表示全局的映射表),key为tid,value为对应的时间戳
更多详细的语法见:https://github.com/iovisor/bpftrace/blob/master/docs/reference_guide.md,很简单
五、遇到的问题总结
5.1 环境构建遇到的问题
1. BCC工具编译
错误描述:编译bcc时cmake Warning:
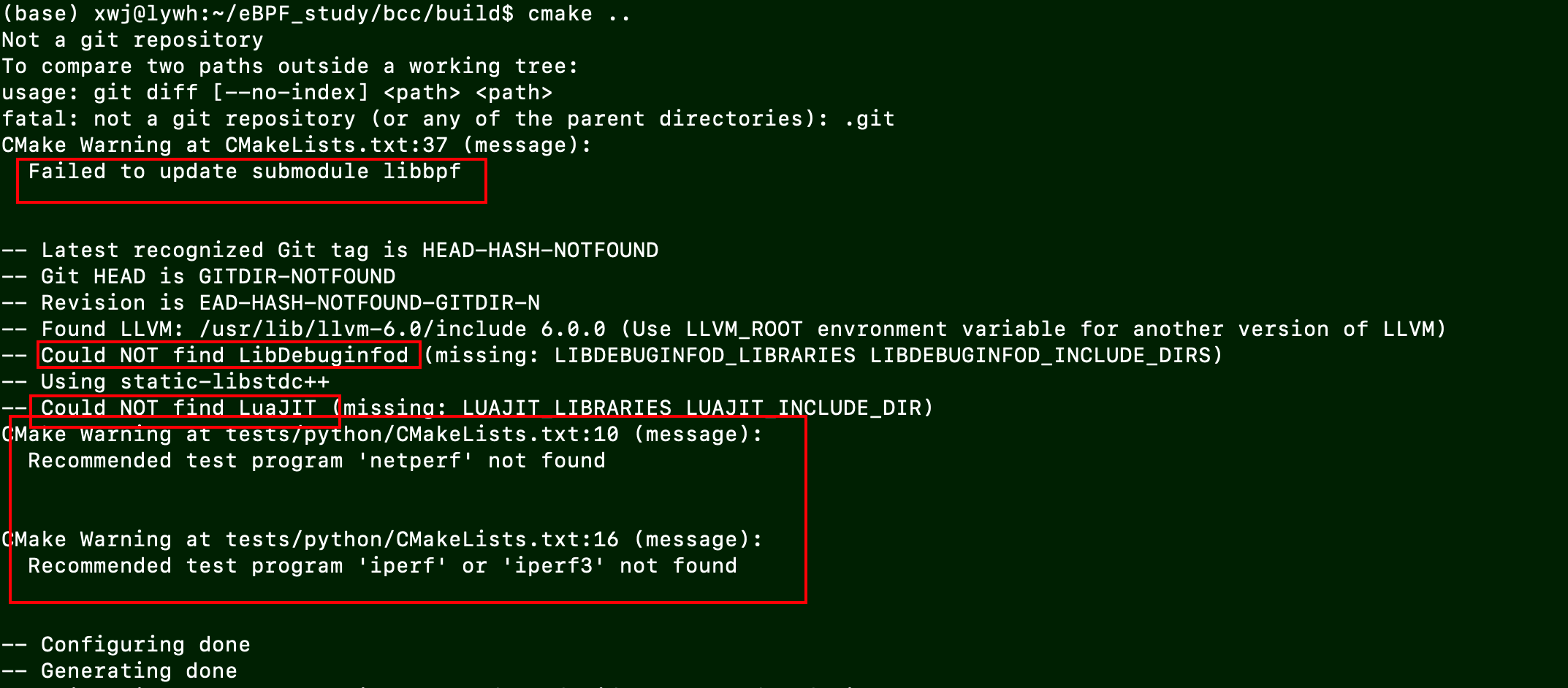
原因:缺少依赖
解决:这些错误其实都不影响后面的编译(可能部分功能会影响,例如debug),同样会构建成功
相关参考
issue:
- https://github.com/iovisor/bcc/issues/3601
- https://github.com/isage/lua-imagick/issues/16
sudo apt install libdebuginfod-dev # 我尝试了并不能直接下载
sudo apt install libluajit-5.1-dev
sudo apt install arping netperf
错误描述:make编译阶段提示getName()函数不带参数,而llvm-6.0版本中的调用却带参数
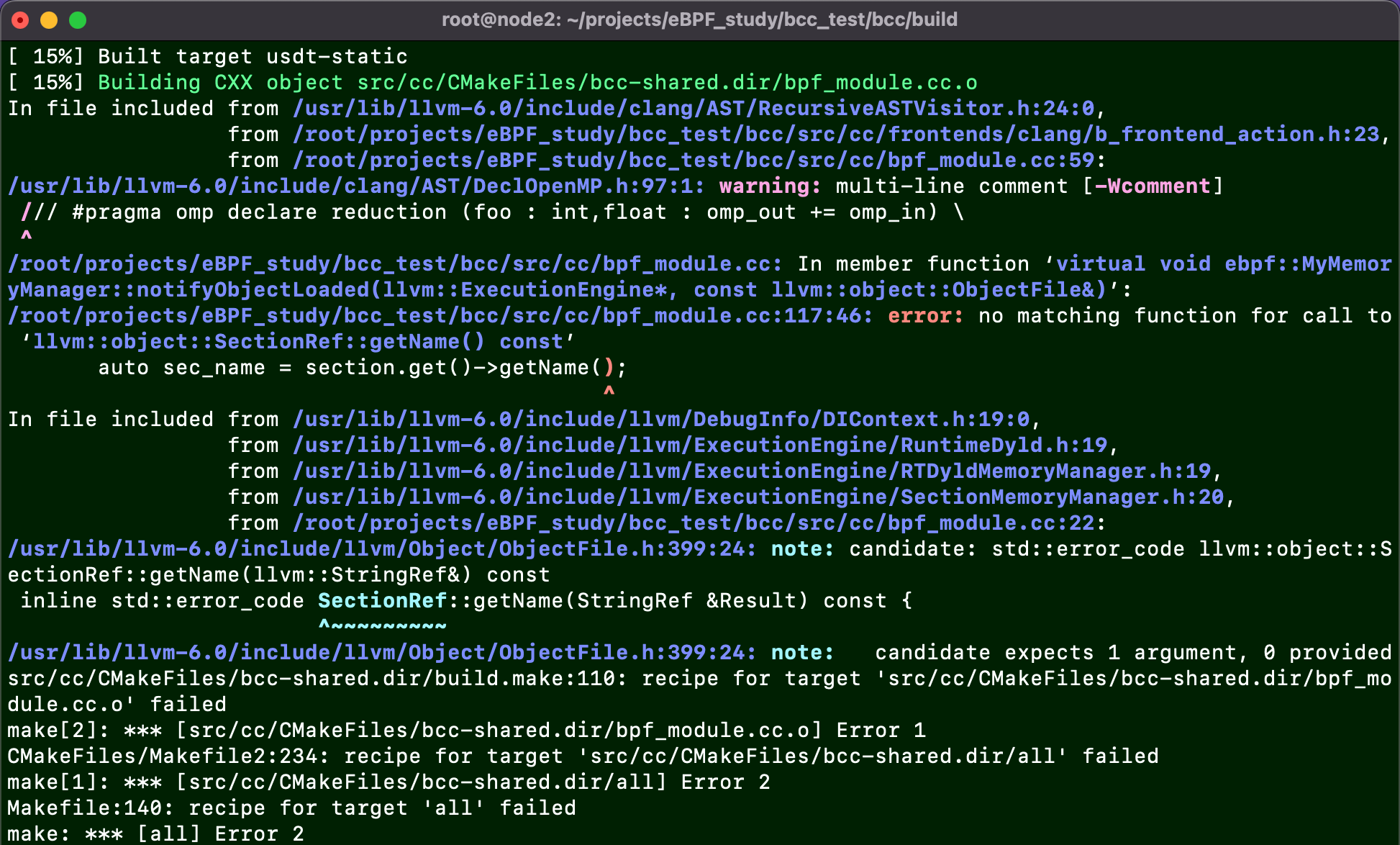
原因:使用的llvm的版本太低了,我的版本是6.0.0

根据issue,bcc将逐渐不支持旧版本的llvm,所以现在最好升级到11.0以上(相关issue)
同样的问题issue:https://github.com/iovisor/bcc/issues/3881
解决方法(二选一):
-
升级
llvm的版本(一劳永逸)几种安装方式都行:
参考自:https://zhuanlan.zhihu.com/p/102028114
-
源码安装方式
# 采用源码安装方式 cd /usr/local wget https://github.com/llvm/llvm-project/releases/download/llvmorg-13.0.0/llvm-project-13.0.0.src.tar.xz tar xvf llvm-project-13.0.0.src.tar.xz mv llvm-project-13.0.0.src/ llvm cd llvm mkdir build && cd build # cmake生成编译信息 cmake -G "Unix Makefiles" -DLLVM_ENABLE_PROJECTS="clang;lldb" -DLLVM_TARGETS_TO_BUILD=X86 -DCMAKE_BUILD_TYPE="Release" -DLLVM_INCLUDE_TESTS=OFF -DCMAKE_INSTALL_PREFIX="/usr/local/llvm" ../llvm # 编译 make # 注意:这里会非常慢,耐心等待 # 安装 make install其中因为我的
cmake版本过低,所以要先更新一下cmake
详细见:https://blog.csdn.net/u013925378/article/details/106945800
make编译过程中到这一步就会失败: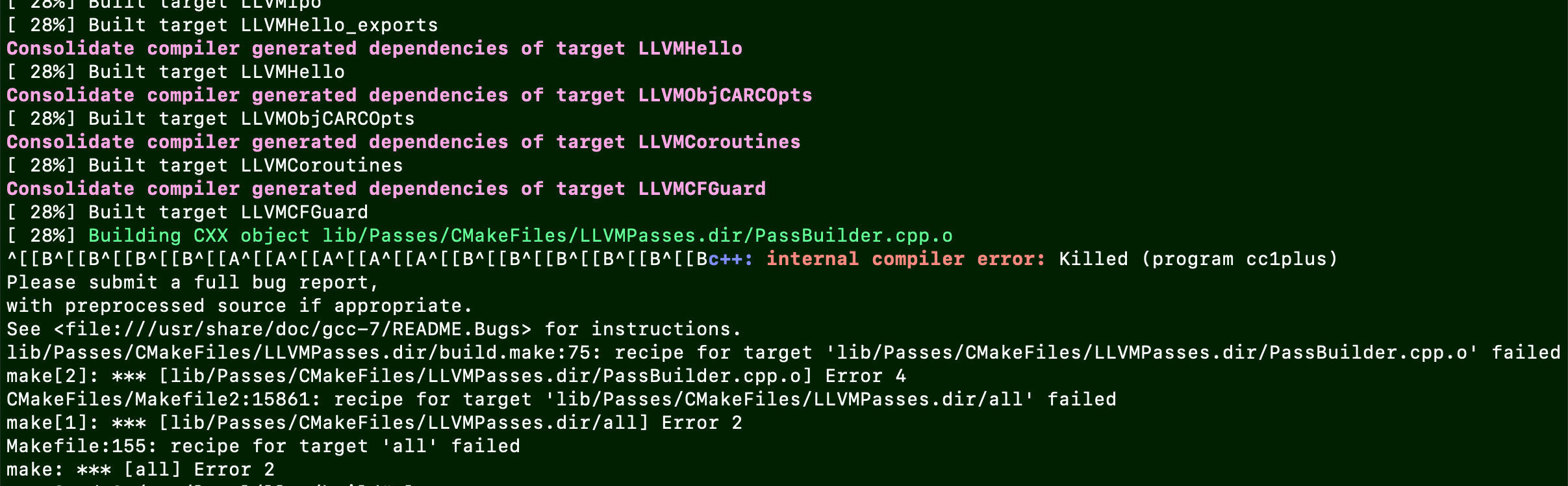
并且会导致我的服务器网络出现问题无法连接,最后被
kill掉现象:这里的编译可能会重启服务器的网卡/网络,因为会导致与服务器的ssh链接断开
原因:目前还未解决,尝试使用第二种方式
-
使用官方脚本安装
wget https://apt.llvm.org/llvm.sh chmod +x llvm.sh # 后面的参数是版本号 sudo ./llvm.sh 11
-
-
download the release 0.24.0, it will compile successfully. (临时解决)
wget https://github.com/iovisor/bcc/releases/download/v0.24.0/bcc-src-with-submodule.tar.gz tar xvf bcc-src-with-submodule.tar.gz mkdir build && cd build cmake .. make sudo make install cmake -DPYTHON_CMD=python3 .. # build python3 binding # 将目录添加到目录堆栈顶,简单理解就是进入这个目录,和popd一起使用 pushd src/python/ make # 安装到/usr/lib/python3/dist-packages/下 sudo make install popd # 返回栈顶目录
问题描述:编译bcc的时候cmake ..失败
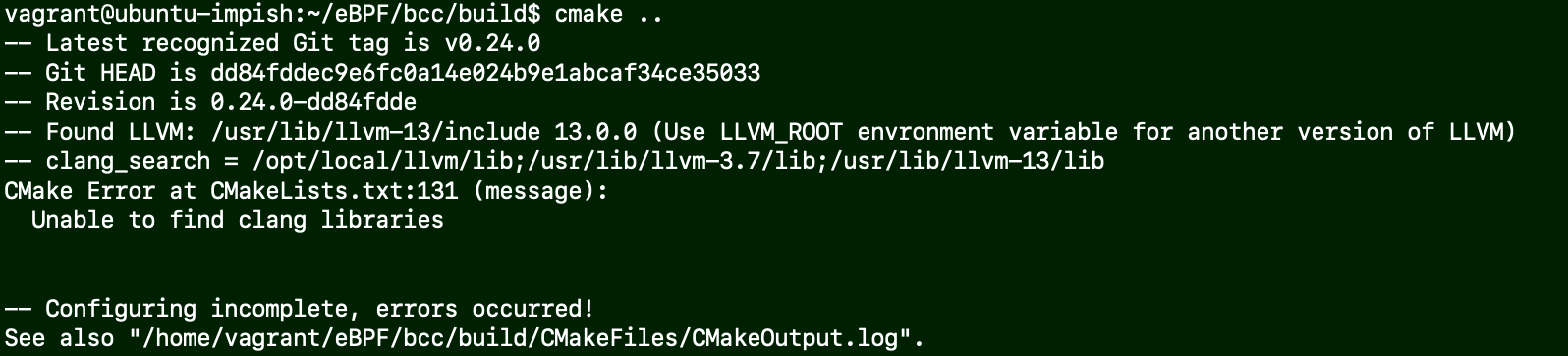
原因:检查ls /usr/lib/llvm-13/lib/下是否有如下所需要的依赖(.a后缀)

如果没有的话安装sudo apt-get install libclang-13-dev (中间的版本号对应你的clang版本)
5.2 bcc demos 遇到的问题
注意默认使用的python源, 检查不要用anaconda3的python3或者是系统默认的python2,否则会报如下错误:
Helloword.py直接执行sudo ./hello_world.py" 执行的python引擎是文件第一行/usr/bin/python, 请确保bcc绑定的python是这个

# 检查
ls -l `which python`
lrwxrwxrwx 1 lywh lywh 9 3月 28 14:28 /home/lywh/anaconda3/bin/python -> python3.9 # 不能用这个
原因:之前bcc安装是安装在系统python3下/usr/lib/python3/dist-packages/bcc,所以会找不到
解决:sudo /usr/bin/python3 ./helloword.py
错误:apt-get update 错误
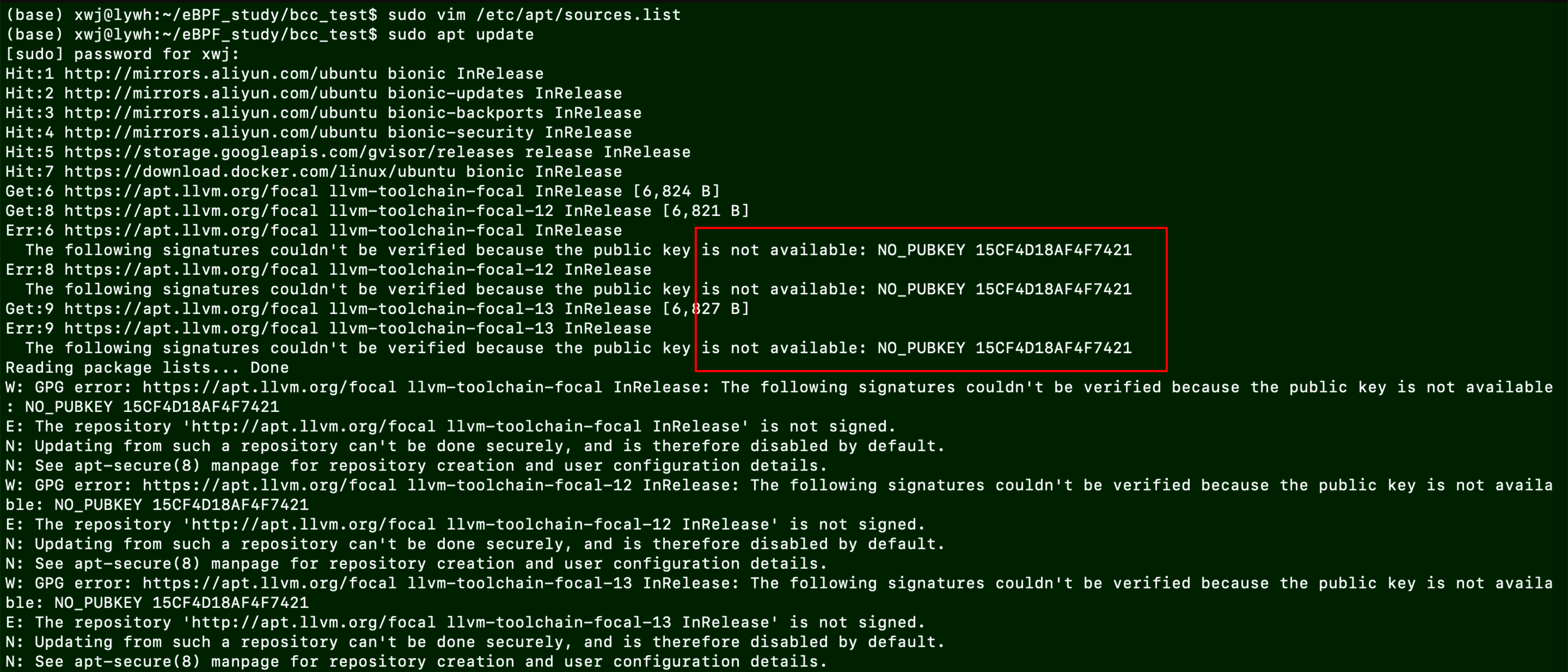
解决:在apt密码管理器中添加NO_PUBKEY
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 15CF4D18AF4F7421
5.3 linux内核源码自带样例遇到的问题
错误描述:编译samples/bpf/出现问题:
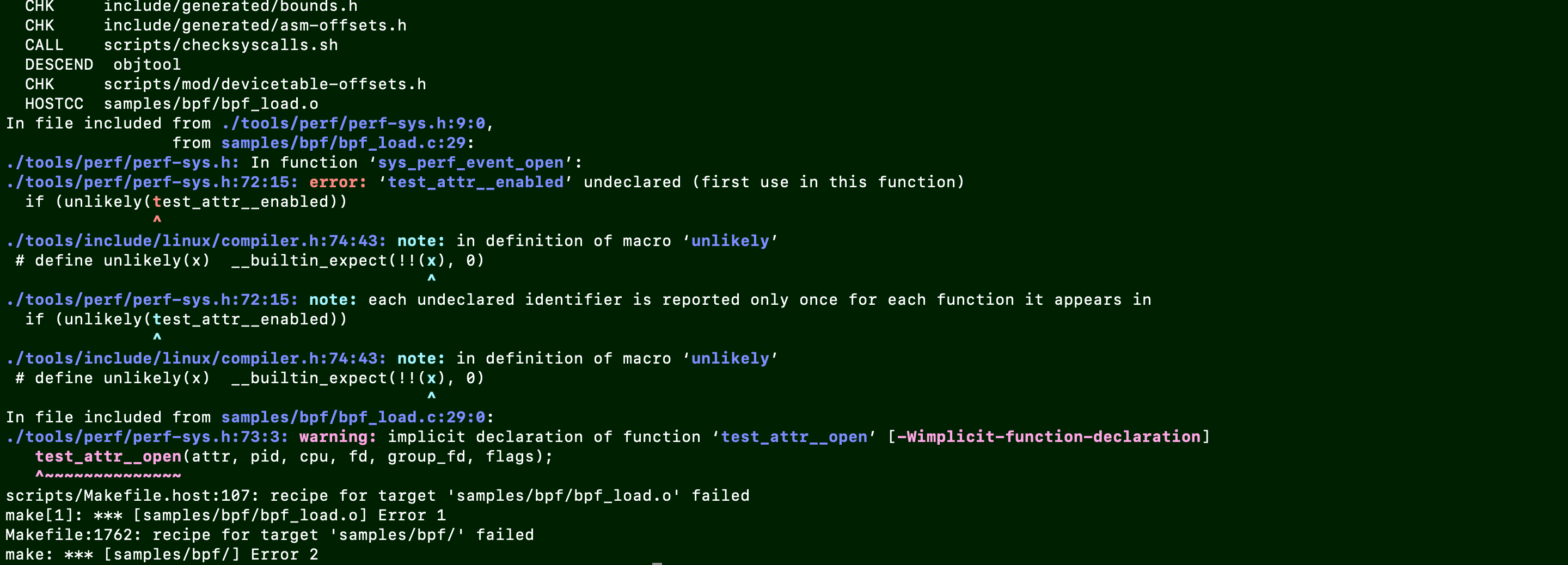
解决方法:因为是测试的代码,所以可以屏蔽掉,https://davidlovezoe.club/wordpress/archives/988
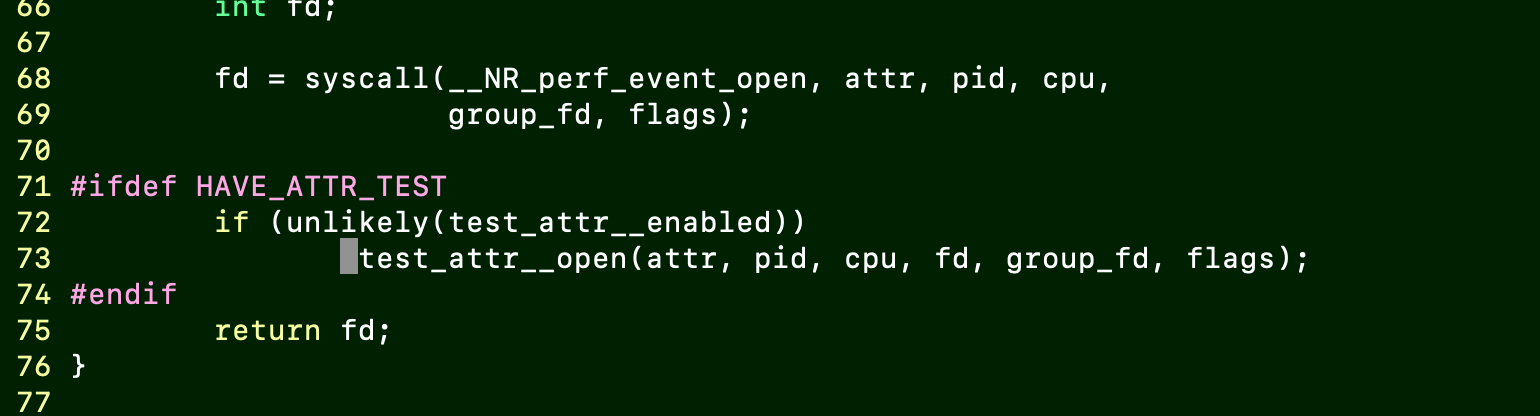
将71行的#ifdef改为#if (注意,谨慎修改)
错误描述:
写Python + C ebpf 监控打开文件demo的时候执行sudo ./hello.py出错:

原因:可能是执行的Python版本用到2.7了
解决:在程序末尾加上;后可以执行,后来删除掉分号后也可以执行了,很诡异
错误描述:

原因:版本内核太低4.15
https://man7.org/linux/man-pages/man2/openat2.2.html#VERSIONS

解决:替换为sys_openat
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/192711.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
