大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
抓取网站的代码实现很多,如果考虑到抓取下载大量内容,scrapy框架无疑是一个很好 的工具。下面简单列出安装过程。PS:一定要按照Python的版本下载,要不然安装的时候会提醒找不到Python。
1.安装Python
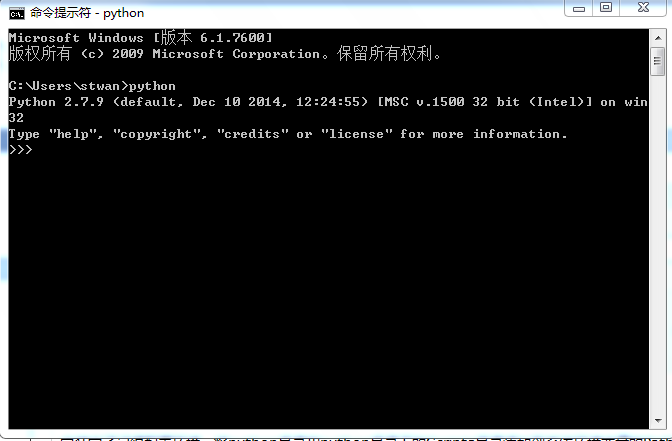
安装完了记得配置环境,将python目录和python目录下的Scripts目录添加到系统环境变量的Path里(在python2.7以后版本中,安装过程中会有个选项:添加到python到path,勾选即可)。在cmd中输入python如果出现版本信息说明配置完毕(如下面截图)。python下载地址:https://www.python.org/downloads/。

2.安装setuptools 或者 pip
ubuntu linux: sudo apt-get install python-pip
解压后进入文件夹执行:python setup.py install
3.安装lxml
lxml是一种使用 Python 编写的库,可以迅速、灵活地处理 XML。选择对应的Python版本安装。;
安装命令:pip install lxml
验证是否安装成功:>>>import lxml
4.安装zope.interface,安装命令:
pip install zope.interface
5.安装Twisted
Twisted是用Python实现的基于事件驱动的网络引擎框架,安装命令:
pip install twisted
6.安装pyOpenSSL
pyOpenSSL是Python的OpenSSL接口,安装命令:
pip install pyopenssl
8.安装Scrapy
easy_install scrapy
或者:pip install scrapy
9.测试是否scrapy可用:
scrapy bench
安装完成,开始使用吧!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/192647.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
